动手学深度学习(二十六)——图像增广(一生二,二生三,三生万物?)
文章目录
-
- 一、图像增广
- 二、常用的图像增广方法
-
- 1. 翻转和裁减
- 2. 颜色改变
- 3. 叠加使用多种数据增广方法
- 三、使用图像增广进行训练
- 四、总结(干活分享)
一、图像增广
定义&解释:
- 通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。
- 随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的范化能力
二、常用的图像增广方法
使用下面这张400x500的图像作为范例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from d2l import torch as d2l
from torch import nn
from PIL import Image
img = Image.open('./data/cat_dog/cat1.jpg')
plt.figure("cat")
plt.title('Initial data')
plt.imshow(img)
plt.show()

大多数图像增广方法都具有一定的随机性。为了便于观察图像增广的效果,我们下面定义辅助函数 apply 。 此函数在输入图像 img 上多次运行图像增广方法 aug 并显示所有结果。
def apply(img,aug,num_rows=2,num_cols=4,scale=1.5):
Y = [aug(img) for _ in range(num_rows*num_cols)]
d2l.show_images(Y,num_rows,num_cols,scale=scale)
1. 翻转和裁减
左右翻转图像通常不会改变对象的类别。这是最早和最广泛使用的图像增广方法之一。上下翻转图像不如左右图像翻转那样常用。但是,至少对于这个示例图像,上下翻转不会妨碍识别。随机裁减]在我们使用的示例图像中,猫位于图像的中间,但并非所有图像都是这样。 池化层可以降低卷积层对目标位置的敏感性。 另外,我们可以通过对图像进行随机裁剪,使物体以不同的比例出现在图像的不同位置。 这也可以降低模型对目标位置的敏感性。
# 左右翻转
apply(img,torchvision.transforms.RandomHorizontalFlip())

# 上下翻转
apply(img,torchvision.transforms.RandomVerticalFlip())

# 随机裁减
shape_aug = torchvision.transforms.RandomResizedCrop(
(200,200),scale=(0.1,1),ratio=(0.5,2),
# (200,200)是图片的大小,scale表示随机裁减为原来的比例,ratio是长宽比
)
apply(img,shape_aug)

2. 颜色改变
另一种增广方法是改变颜色。
我们可以改变图像颜色的四个方面:
- 亮度
- 对比度
- 饱和度
- 色调
# 亮度
apply(img,
torchvision.transforms.ColorJitter(brightness=0.5,contrast=0,
saturation=0,hue=0))

# 对比度
apply(img,
torchvision.transforms.ColorJitter(brightness=0,contrast=0.5,
saturation=0,hue=0))

# 饱和度
apply(img,
torchvision.transforms.ColorJitter(brightness=0,contrast=0,
saturation=0.5,hue=0))

# 色调
apply(img,
torchvision.transforms.ColorJitter(brightness=0,contrast=0,
saturation=0,hue=0.5))

# 混合使用
apply(img,
torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,
saturation=0.5,hue=0.5))

3. 叠加使用多种数据增广方法
augs = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,saturation=0.5,hue=0.5),
torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))
]
)
apply(img,augs)

三、使用图像增广进行训练
# 下载CIFA10数据集测试
all_images = torchvision.datasets.CIFAR10(
train=True,root="./data/",download=True
)
d2l.show_images([all_images[i][0] for i in range(32)] , 4,8,scale=0.8)

# 应用简单的左右翻转,上下翻转
# 生数据格式为(批量大小,通道数量,高度,宽度)
train_augs = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
# torchvision.transforms.RandomVerticalFlip(),
torchvision.transforms.ToTensor()]
)
test_augs = torchvision.transforms.Compose([
# torchvision.transforms.RandomHorizontalFlip(),
# torchvision.transforms.RandomVerticalFlip(),
torchvision.transforms.ToTensor()
]
)
# 加载数据
def load_cifar10(is_train,augs,batch_size):
dataset = torchvision.datasets.CIFAR10(root="./data/",train=is_train,
transform=augs,download=True)
dataLoader = torch.utils.data.DataLoader(
dataset,batch_size=batch_size,shuffle=is_train,num_workers=d2l.get_dataloader_workers()
)
return dataLoader
# 多GPU训练和评估
def train_batch(net, X, y, loss, trainer, devices):
if isinstance(X, list):
# 微调BERT中所需(稍后讨论)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
def train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0]) # 多GPU运行
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch(net, features, labels, loss, trainer,
devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(
epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3], None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
#使用增强之后的数据进行训练模型;
# 获取全部的GPU,使用Adam作为优化算法
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# 模型初始化
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train(net, train_iter, test_iter, loss, trainer, 10, devices)
# 数据增广(左右翻转)
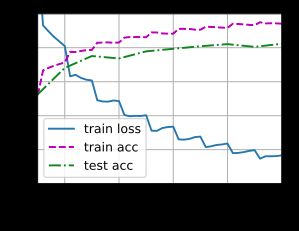
train_with_data_aug(train_augs, test_augs, net)
loss 0.166, train acc 0.942, test acc 0.823
453.4 examples/sec on [device(type='cuda', index=0)]
# 没有数据增广
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
train_with_data_aug(test_augs, test_augs, net)
loss 0.070, train acc 0.975, test acc 0.797
455.5 examples/sec on [device(type='cuda', index=0)]
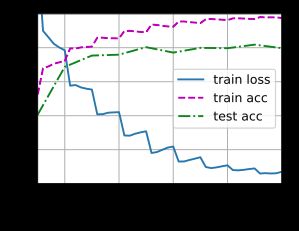
结果对比:
- 使用图像增强,尽管只是简单的左右翻转,我们模型的预测精度还是提高了3%
- 模型过拟合有一定的缓解。
四、总结(干活分享)
- 图像增广基于现有的训练数据生成随机图像,来提高模型的范化能力。
- 为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,而在预测过程中不使用随机操作的图像增广。(训练有,预测无)
- 深度学习框架提供了许多不同的图像增广方法,这些方法可以被同时应用。(多种增强共同使用)
- 图像增广方法收集(这些整理应该够用了,如果有什么特别需求可以留言讨论一下):
(1)知乎上有作者总结自己编写的15种增强方法和代码:
https://zhuanlan.zhihu.com/p/158854758- 翻转
- 裁剪
- 过滤和锐化
- 模糊
- 旋转,平移,剪切,缩放
- 剪下
- 色彩
- 亮度
- 对比
- 均匀和高斯噪声
- 渐变镜头变形
(2)github上找一些高star的成熟代码:
例如: imgaug https://github.com/aleju/imgaug(3)augmentor https://github.com/mdbloice/Augmentor
