dqn推荐系统_推荐系统遇上深度学习(四十)使用RNN做基于会话的推荐
好啦,是时候继续我们推荐系统的学习了,从本篇开始,我们来一起了解一下Session-Based Recommendation。今天,我们介绍的文章题目为《SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS》,通过循环神经网络来进行会话推荐。论文下载地址为:http://arxiv.org/abs/1511.06939。
另外,本文代码的地址为:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-SessionBasedRNN-Demo
参考的Python2版本代码地址为:https://github.com/Songweiping/GRU4Rec_TensorFlow
先来理解一下Session-Based Recommendation的定义。它的中文翻译是基于会话的推荐,我们可以理解为从进入一个app直到退出这一过程中,根据你的行为变化所发生的推荐;也可以理解为根据你较短时间内的行为序列发生的推荐,这时session不一定是从进入app到离开,比如airbnb的论文中,只要前后两次的点击不超过30min,都算做同一个session。
1、模型介绍
1.1 背景介绍
在本文出现之前(2016年),基于会话的推荐方法,主要有基于物品的协同过滤和基于马尔可夫决策过程的方法。
基于物品的协同过滤,需要维护一张物品的相似度矩阵,当用户在一个session中点击了某一个物品时,基于相似度矩阵得到相似的物品推荐给用户。这种方法简单有效,并被广泛应用,但是这种方法只把用户上一次的点击考虑进去,而没有把前面多次的点击都考虑进去(论文里这么说,不过我认为可以按比例混合多次点击的推荐结果吧)。
基于马尔可夫决策过程的推荐方法,也就是强化学习方法,其主要学习的是状态转移概率,即点击了物品A之后,下一次点击的物品是B的概率,并基于这个状态转移概率进行推荐。这样的缺陷主要是随着物品的增加,建模所有的可能的点击序列是十分困难的(可能论文年代比较久远,现在的话我们应该可以使用DQN等方法了)。
1.2 基于RNN的会话推荐
回到正题,文中提出使用基于RNN的方法来进行基于会话的推荐,其结构图如下:
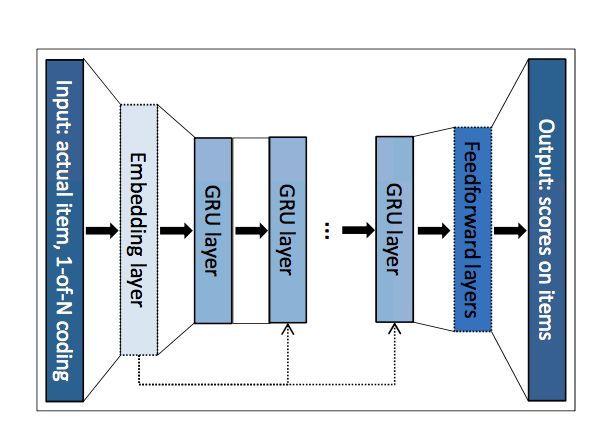
模型的结构很简单,对于一个Session中的点击序列x=[x1,x2,x3...xr-1,xr],依次将x1、x2,...,xr-1输入到模型中,预测下一个被点击的是哪一个Item。
首先,序列中的每一个物品xt被转换为one-hot,随后转换成其对应的embedding,经过N层GRU单元后,经过一个全联接层得到下一次每个物品被点击的概率。
值得一提的是,在我参考的代码中,每个物品其实对应了两套embedding,一个是输入层对应的输入embedding,一个是最后计算物品点击概率的embedding,我们可以记为softmax embedding。输入物品xt的输入embedding在经过多层的GRU单元之后,得到了一个输出向量,我们记为w1,对于物品yt,其对应的softmax embedding记为w2,那么点击yt(未softmax之前)的概率,由w1和w2的点乘得到。这里有点attention的味道了,具体大家可以参考给出的代码。
1.3 模型的小trick
为了提高训练的效率,文章采用两种策略来加快简化训练代价,分别为:
Session-parallel MINI-BATCHES
为了更好的并行计算,论文采用了 mini-batch 的处理,即把不同的session拼接起来,其示意图如下所示:
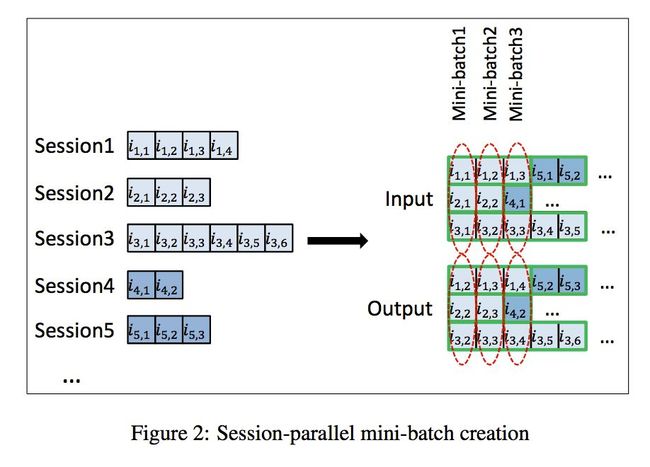
可以看到,Session1的长度为4,Session2的长度为2,Session3的长度为6,Session4的长度为2,Session5的长度为3。假设Batch-Size为3,那么我们首先用前三个Session进行训练,不过当训练到第三个物品时,Session2已经结束了,那么我们便将Session4来接替上,不过这里要注意将GRU中的状态重新初化。
Sampling On the output
物品数量如果过多的话,模型输出的维度过多,计算量会十分庞大,因此在实践中一般采取负采样的方法。论文采用了取巧的方法来减少采样需要的计算量,即选取了同一个batch 中其他 sequence 下一个点击的 item作为负样本,用这些正负样本来训练整个神经网络。
还是如上图所示,当输入是i1,1时,其对应的正样本为i1,2,那么对应的负样本就是i2,2,i3,2。
1.4 Rank Loss
这里,论文提出了两种pair-wise的损失函数,分别为BPR和TOP1。
BPR
BPR损失,对比了正样本和每个负样本的点击概率值,其计算公式如下:

其中,i代表的是正样本,j代表的是负样本,若正样本的点击概率大于负样本的点击概率,这样损失会比较小,若正样本的点击概率小于负样本,损失会比较大。
TOP1
第二个损失函数感觉和第一个损失函数差不多,只不过对负样本的点击概率增加了正则项,同时sigmoid之后没有再取log:
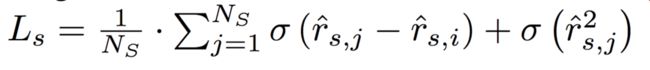
1.5 实验结果
文中将提出的模型与按热度推荐、基于会话的热度推荐、基于物品的协同过滤、BPR-MF等模型进行了对比数据,所选取的两个数据集分别为RecSys Challenge 2015的数据集和Youtube-like OTT video的数据集。评价指标选取了Recall@20和MRR@20,实验结果如下:

随后,在不同数据集上,使用不同损失函数训练模型,评价指标的对比结果为:

可以看到,使用文中提出的两种Rank Loss相较于使用point-wise的交叉熵损失函数,模型的推荐效果有了较大的提升。
1.6 关于损失函数的讨论
好了,最后我们来讨论一下我阅读本文时最为疑虑的地方吧,为什么使用pair-wise的损失函数,要比point-wise的损失函数更好呢?这主要还是看场景吧。比如在电商领域、外卖点餐的时候,我们可能很多东西都喜欢,但是只会挑选一个最喜欢的物品进行点击或者购买。这种情况下并不是一个非黑即白的classification问题,只是说相对于某个物品,我们更喜欢另一个物品,这时候更多的是体现用户对于不同物品的一个相对偏好关系,此时使用pair-wise的损失函数效果可能会好一点。在广告领域,一般情况下用户只会展示一个广告,用户点击了就是点击了,没点击就是没点击,我们可以把它当作非黑即白的classification问题,使用point-wise的损失函数就可以了。
不过还是要提一点,相对于使用point-wise的损失函数,使用pair-wise的损失函数,我们需要采集更多的数据,如果在数据量不是十分充足的情况下,point-wise的损失函数也许是更合适的选择。
以上仅仅是我个人的观点,咱们可以一起讨论,进步!
写在最后
五一小长假要来了,小编准备搞一件大事,期待一下吧
喜欢,别忘关注~
一起来和小编共同进步吧!
如果你喜欢这个文章,点个好看再走呗,您的支持是小编进步的最大的动力!
