深度学习之数据增强
目录
一、导包
二、查看原始数据
三、图像增强相关操作
1.指定target_size后所有图像都变为相同大小
2.角度旋转
3.平移变换
4.缩放
5.channel_shift
6.翻转
四、猫狗训练实战
深度学习中最依赖的就是数据量了,同样一只猫轻松一变数据量就翻倍了,我们需要对数据进行数据增强,以消除训练集过拟合的问题。
一、导包
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
from keras.preprocessing import image#操作图像的工具包,代替了opencv
import keras.backend as K#操作图像的工具包,代替了opencv
import os#操作路径的工具包
import glob#操作路径的工具包
import numpy as np二、查看原始数据
先设置一会图像展示的形式与数量,定义print_result函数,便于一会调用进行展示图片
def print_result(path):
name_list = glob.glob(path)
fig = plt.figure(figsize=(12,16))
for i in range(6):
img = Image.open(name_list[i])
sub_img = fig.add_subplot(341+i)
sub_img.imshow(img) ![]()
range(number)表示展示number个图像,当文件夹中的图片数少于number时,会报错,但不影响展示。
![]()
341表示展示时分成3行4列进行展示,1表示给每行的图片进行标号。
设置路径以便于一会读取想要路径下的文件夹。
img_path = './img/superman/*'
in_path = './img/'
out_path = './output/'
name_list = glob.glob(img_path)
name_list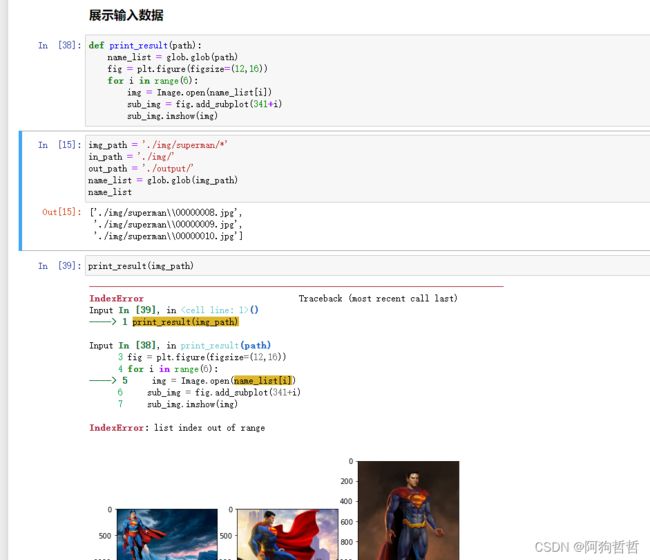
三、图像增强相关操作
1.指定target_size后所有图像都变为相同大小
datagen = image.ImageDataGenerator()
gen_data = datagen.flow_from_directory(in_path, batch_size=1, shuffle=False,
save_to_dir=out_path+'resize',
save_prefix='gen', target_size=(300, 300))
#(300,300)表示缩成300*300的图像
对几张图像做操作,range()就写几,只有执行了下面这句才会生成图像
for i in range(3):
gen_data.next()展示操作后的图像
print_result(out_path+'resize/*')2.角度旋转
datagen = image.ImageDataGenerator(rotation_range=45)
gen = image.ImageDataGenerator()
data = gen.flow_from_directory(in_path, batch_size=1, class_mode=None, shuffle=True, target_size=(224, 224))
#会对in_path下的所有文件夹都进行数据增强的相关任务,这里只对超人文件夹进行了操作
np_data = np.concatenate([data.next() for i in range(data.n)])
datagen.fit(np_data)
gen_data = datagen.flow_from_directory(in_path, batch_size=1, shuffle=False, save_to_dir=out_path+'rotation_range',save_prefix='gen', target_size=(224, 224))
for i in range(3):
gen_data.next()3.平移变换
datagen = image.ImageDataGenerator(width_shift_range=0.3,height_shift_range=0.3)datagen = image.ImageDataGenerator(width_shift_range=-0.3,height_shift_range=0.3)4.缩放
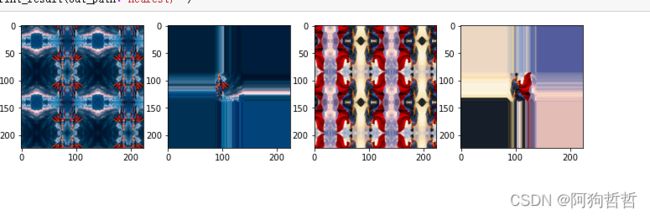
datagen = image.ImageDataGenerator(zoom_range=0.5)缩放导致的图片位置空缺,会用到填充,默认的填充方法好像为constant
### 填充方法
- 'constant': kkkkkkkk|abcd|kkkkkkkk (cval=k)
- 'nearest': aaaaaaaa|abcd|dddddddd
- 'reflect': abcddcba|abcd|dcbaabcd
- 'wrap': abcdabcd|abcd|abcdabcd
zoom_range=[4,4]使图片位于中央的1/4.
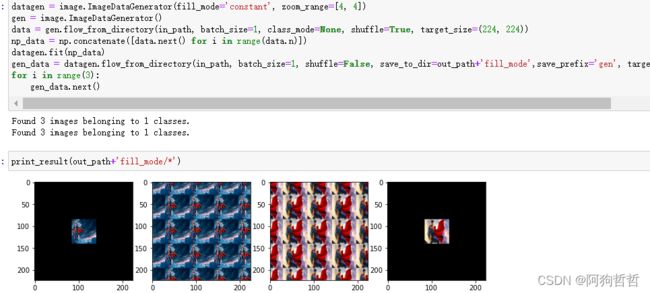
5.channel_shift

肉眼无法分辨有什么变化,但对计算机来说确实发生了变化
datagen = image.ImageDataGenerator(channel_shift_range=15)6.翻转
![]()
对图像的各个像素点重新编排,使所有像素点处于0到1之间
datagen = image.ImageDataGenerator(horizontal_flip=True)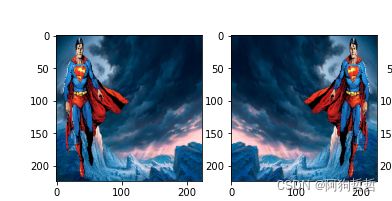
四、猫狗训练实战
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(64, 64),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=20,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100, # 2000 images = batch_size * steps
epochs=100,
validation_data=validation_generator,
validation_steps=50, # 1000 images = batch_size * steps
verbose=2)