论文笔记:Subgraph Retrieval Enhanced Model for Multi-hop Knowledge BaseQuestion Answering
引用格式:Zhang J, Zhang X, Yu J, et al. Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 5773-5784.
源码(写的不太友好):
GitHub - RUCKBReasoning/SubgraphRetrievalKBQA: The pytorch implementation of Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering
0摘要:子图的检索对于KBQA来说至关重要。最近关于知识库问题回答(KBQA)的工作j聚焦在检索子图,以便于更容易的推理。基于嵌入的KBQA所需的子图是至关重要的,因为小的子图可能会排除答案,而大的子图可能会引入更多的噪声。但是,现有的检索器要么是启发式的,要么是与推理交织在一起,导致在部分子图上进行推理,在中间监督缺失的情况下增加了推理偏差。本文提出了一种可训练的、与后续推理过程解耦的子图检索器(SR),使即插即用的框架能够增强任何面向子图的KBQA模型。大量的实验表明,与现有的检索方法相比,SR具有更好的检索性能和质量保证性能。通过弱监督的预训练以及端到端微调,SR在与NSM (He等人,2021年)结合时实现了新的最先进的性能,NSM是一种面向子图的推理机,用于基于嵌入的KBQA方法。
简单来说↑↑,提出了一种子图检索器。
1 前言:
KBQA目前由两种主流方式,一种是基于语义解析(Semantic parsing-based),另一种是基于嵌入(embedding-based),前者严重依赖于中间逻辑形式(如SPARQL)的昂贵注释。后者不是解析问题,而是根据实体与输入问题的相关性直接表示和排序实体。其中,模型首先检索问题相关子图,然后对其进行推理减少推理空间,与在整个KB上推理相比显示出优越性。
简单来说↑↑,两种主流方法中,基于嵌入的方法更好。
子图检索对整体QA性能至关重要,因为小的子图很可能会排除答案,而大的子图可能会引入影响QA性能的噪声。图1(a)显示了不同大小的子图在KBQA两种广泛使用的数据集上的回答覆盖率,即WebQSP (Yih et al., 2016)和CWQ (Talmor and Berant, 2018)。提取完整的多跳主题中心子图,并通过实体的个性化pagerank (PPR) 评分来控制图的大小。还展示了NSM (He等人,2021)在图1(b)中相同大小的子图下的QA性能(Hits@1)。NSM是一种最先进的基于嵌入的模型。可以观察到,尽管较大的子图更可能包含答案,但当子图包含超过5000个节点时,QA性能会急剧下降。

此外,提取完整的多跳子图用于在线QA是低效的。
结果表明,这种启发式检索远不是最优的。为了提高检索性能,PullNet (Sun等人,2019)提出了一种可训练的检索器,但检索和推理过程是交织在一起的。在每个步骤中,基于lstm的检索器选择与问题相关的新关系,而基于gnn的推理器确定新关系的哪些尾部实体应该扩展到子图中。因此,推理机需要对中间部分子图进行推理和训练。由于中间监督通常是不被观察到的,在部分子图上进行推理会增加偏差,最终会影响最终整个子图上的答案推理。
发现问题↑↑:基于嵌入的方法更好,而且子图越大,包含答案的可能性越大。但当前的SOTA 模型,使用的子图检索方法不是最优的,在子图过大的时候性能也会下降。
提出了一种KBQA子图检索增强模型,该模型设计了一种可训练的子图检索器(SR),该子图检索器与后续推理机解耦。SR是一种高效的双编码器,它可以扩展诱导子图的路径,并可以自动停止扩展。之后,任何面向子图的推理机,如GRAFT-Net (Sun等人,2018)或NSM (He等人,2021),都可以用来从子图中微妙地推导出答案。这种可分离的检索和推理确保推理只针对最终的整个子图,而不是中间的部分子图,这使得即插即用的框架能够增强任何面向子图的推理器。
解决问题↑↑:针对子图检索,提出一种在基于嵌入方法中通用的模型。
作者系统地研究了SR的各种训练策略的优势,包括弱监督/无监督的预训练,与推理机的端到端微调。本文从问题中的主题实体中提取到答案的最短路径,而不是ground truth路径,作为预训练的弱监督信号。
当QA配对本身也很稀缺时,为无监督的训练前构建伪(问题、答案、路径)标签。为了通过最终的QA性能进一步教导检索器,支持端到端微调,将答案的可能性作为推理机的反馈注入到子图的先验分布中,以更新检索器。
解决方法↑↑:作者研究了无监督和端到端两种训练策略。对于弱监督,本文抽取最短路径作为监督信号。对于无监督,构建伪标签。
在WebQSP和CWQ上进行了大量的实验。结果显示了四个主要优势:(1)SR与现有的面向子图的推理机相结合,与使用其他检索方法执行的同一推理机相比,取得了显著的收益(+11.3-19.3% Hits@1)。此外,SR与NSM一起为基于嵌入的KBQA模型创建了最新的结果。(2)在答案覆盖率相同的情况下,SR可以得到更小的子图,从而推断出更准确的答案。(3)只有20%弱监督信号的无监督训练前与完全弱监督信号的训练前相当。(4)端对端微调可以提高检索器和推理机的性能。
进步明显↑↑:作者研究了无监督和端到端两种训练策略。对于弱监督,本文抽取最短路径作为监督信号。对于无监督,构建伪标签。
贡献:(1)我们提出了一个可训练的SR,它与后续的推理机解耦,以实现一个即插即用的框架,增强任何面向子图的推理机。(2)我们设计了一种简单而有效的双编码器,其检索和QA结果明显优于现有的检索方法。(3)配备了SR的NSM,通过弱监督的预训练和端到端微调,为基于嵌入的KBQA方法实现了新的SOTA性能。
2 问题定义
KBQA的概率形式化。给定一个问题q和它的一个答案a∈Aq,将KBQA问题形式化为最大化概率分布p(a|G, q).不直接在G上进行推理,而是检索一个子图g⊆G并在g上推断a。由于g是未知的,将它作为一个潜在变量,并将p(a|G, q)重写为

在上式中,目标分布p(a|G, q)由子图检索器pθ(g|q)和答案推理器pφ(a|q, g)联合建模。
子图检索器pθ定义了以问题q为条件的潜在子图g上的先验分布,而答案推理器pφ预测给定子图g和问题q的答案a的可能性。目标是找到最优参数θ和φ,可以最大限度地提高训练数据的对数似然,即:

其中D为整个训练数据。利用该公式,可以通过在检索器采样的子图上先训练检索器pθ,再训练推理器pφ来实现检索器与推理器的解耦。通过绘制样本g (Sachan et al., 2021),可以将式(2)近似为:

其中第一项和第二项分别对推理机和检索器进行优化。具体的推理机可以由任何面向子图的KBQA模型实例化,如基于gnn的GRAT-Net (Sun等人,2018)和NSM (He等人,2021)。
3 Subgraph Retriever (SR)本文提出的方法
检索器需要对任意子图g计算pθ(g|q),这是一个棘手的问题,因为潜在变量g本质上是组合的。为了避免枚举g,本文提出从主题实体中扩展与q相关的top-K路径,然后根据这些路径归纳出子图。
combinatorial 组合最优化又称组合规划,是在给定有限集的所有具备某些特性的子集中,按某种目标找出一个最优子集的一类数学规划。
3.1 扩展路径,expending path
路径扩展从主题实体开始,遵循顺序决策过程。路径被定义为一个关系序列![]() ,因为一个问题通常意味着不包括实体的中间关系。假设在时间t时已检索到一条 部分路径
,因为一个问题通常意味着不包括实体的中间关系。假设在时间t时已检索到一条 部分路径![]() ,则可以通过填充路径上的中间实体,从
,则可以通过填充路径上的中间实体,从![]() 诱导出一棵树,即
诱导出一棵树,即![]() 。每个
。每个![]() 都是一个作为头部实体的实体集,一个关系通常可以派生多个尾部实体。然后从
都是一个作为头部实体的实体集,一个关系通常可以派生多个尾部实体。然后从![]() 的相邻关系并集中选择下一个关系。每个关系r与问题q的相关性由它们embedding的点积来衡量,即
的相邻关系并集中选择下一个关系。每个关系r与问题q的相关性由它们embedding的点积来衡量,即
![]() (4)
(4)
问题和关系由RoBERTa得到embedding,再计算点积。
其中f和h均由RoBERTa实例化(Liu等人,2019年)。具体来说,将“问题”或“关系r的name“输入到RoBERTa中,并将其[CLS]标记作为输出embedding。根据假设:”在不同时间步扩展关系应涉及查询的特定部分“,将原始问题与部分路径![]() 中的历史扩展关系连接起来作为RoBERTa的输入来更新问题的嵌入,即。
中的历史扩展关系连接起来作为RoBERTa的输入来更新问题的嵌入,即。
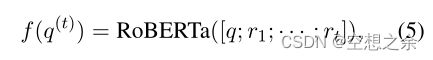
由公式(4)![]() 可以得出,关系r被扩展的概率可以形式化为
可以得出,关系r被扩展的概率可以形式化为
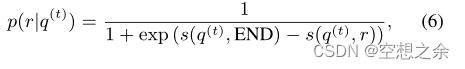
激活函数 : sigmoid
其中END是一个名为“END”的虚拟关系。
得分![]() 表示相关性得分的阈值。如果
表示相关性得分的阈值。如果![]() ,则
,则![]() 大于0.5,否则不大于0.5。选择
大于0.5,否则不大于0.5。选择![]() >0.5的top-1关系。如果关系的概率均不大于0.5,则停止拓展。最后,给出问题的路径的概率可以计算为路径中所有关系的联合分布,即
>0.5的top-1关系。如果关系的概率均不大于0.5,则停止拓展。最后,给出问题的路径的概率可以计算为路径中所有关系的联合分布,即

其中![]() 表示p中的关系数,t=1表示主题实体处的选择,t=
表示p中的关系数,t=1表示主题实体处的选择,t=![]() 表示最后一次none-stop关系选择。
表示最后一次none-stop关系选择。
由于无法保证top-1相关路径是正确的,因此每次执行top-K柱搜索以获得K条路径。从每个主题实体中,得到K条路径,这些路径总共由n个主题实体生成nK条路径。nK路径对应于nK实例化的树。
3.2 诱导子图 ,Inducing Subgraph
 子图检索过程的图示。从每个主题实体展开一条路径,并归纳出相应的树,然后将不同主题实体的树合并成一个统一的子图
子图检索过程的图示。从每个主题实体展开一条路径,并归纳出相应的树,然后将不同主题实体的树合并成一个统一的子图
将top-K树从一个主题实体合并成一个子图,然后将不同子图中的相同实体合并成最终子图。这可以减小子图的大小,即答案推理空间,因为来自不同主题实体的子图可以被视为彼此的约束。具体来说,从n个主题实体的n个子图中,找到相同的实体并将其合并。从这些合并的实体中,在每个子图中追溯到根(即主题实体),并向前追溯到叶子。然后,只保留所有树的跟踪路径上的实体和关系,形成最终的子图。例如,在图2中,给出了一个问题“获得图灵奖的加拿大公民在哪里毕业?”有了两个主题实体“Turing Award”和“Canada”,可以用两条扩展路径(Win,Graduate)和(Citizen,Graduate)来解释它,并将它们所诱导的树合并成一个统一的子图。图中仅显示了top-1路径,以便进行清楚的说明。
4 训练策略
在本节中讨论训练检索器的预训练和端到端微调策略。图3展示了整个框架和训练过程。

4.1 弱监督预训练
由于ground truth子图不容易获得,借助由(q,a)对构造的弱监督信号。具体来说,从问题的每个主题实体中,检索到每个答案的所有最短路径作为监督信号,因为路径比图更容易获得。
因为根据等式(7),最大化路径的对数似然等于 。可以使得路径中所有中间关系的概率最大化。为了实现目标,将一个路径
。可以使得路径中所有中间关系的概率最大化。为了实现目标,将一个路径![]() 分解成|p| + 1个(问题,关系)实例,包括([q],r1),([q;r1],r2),...,([q;R1;R2;;r|p| 1],r | p |),以及一个附加的结束实例([q;R1;R2;;r|p|],END),并优化每个实例的概率。用其他采样关系替换每个时间步的观测关系作为负实例,以优化观测关系的概率。
分解成|p| + 1个(问题,关系)实例,包括([q],r1),([q;r1],r2),...,([q;R1;R2;;r|p| 1],r | p |),以及一个附加的结束实例([q;R1;R2;;r|p|],END),并优化每个实例的概率。用其他采样关系替换每个时间步的观测关系作为负实例,以优化观测关系的概率。
4.2 无监督预训练
当(q,a)对也很少时,以独立于(q,a)对的无监督方式训练检索器。利用NYT数据集,一个用于关系提取的远程监督数据集(Riedel et al .,2010)来构建伪(q,a,p)标签。在这个数据集中,每个实例表示为一个元组(s,(e1,r,e2)),其中s是一个句子,表示句子s中提到的两个实体e1和e2之间的关系r。对于两个实例(s1,(e1,r1,e2))和(s2,(e2,r2,e3)),将e1视为主题实体,将e3视为答案。然后把s1和s2串联成问题,把r1和r2串联成对应的路径来训练检索器。训练目标与弱监督预训练相同。
4.3 端到端微调
端到端训练是联合微调,单独训练的检索器和推理器的替代方法。主要思想是利用 来自推理器的反馈来引导检索器的路径扩展。为了实现这一点,优化后验pθ,φ(g|q,a ),而不是先验pθ(g|q ),因为前者包含额外的似然pφ(a|q,pk ),它准确地反映了来自推理器的反馈。不直接优化后验pθ,φ(g|q,a ),因为g是从nK条路径中导出的,使得不知道哪条路径应该从对整个g计算的似然中接收反馈。相反,通过nK条路径的概率之和来近似p(g|q,a ),并通过贝叶斯规则重写每条路径的后验(Sachan等人,2021年),即:

其中pθ(pk|q)是第k条路径的先验分布,可通过等式估算。(7),而pφ(a|q,pk)是给定第k条路径的答案a的可能性。本质上,pφ(a|q,pk)估计的是第k条路径诱导的单树上的答案a,而不是nK条路径的融合子图。因此,每棵树上的推理可能性可以反映到诱导该树的相应路径上。估算pφ(a|q,pk)的推理机和计算pφ(a|q,g)的推理机是一样的。总之,每个训练实例(q,a,G)的整个目标函数被形式化为:

其中停止梯度操作SG将停止更新参数φ。通过计算由检索器采样的G上的似然度pφ(a|q,G )(不使用来自答案a的信息),推理机与两阶段训练一样被更新。结果,当计算pφ(a|q,G)时,在训练和评估之间没有不匹配,因为G仅依赖于两者的先验。
直观地,训练推理机在给定从nK条最高得分路径导出的子图的情况下提取正确答案。当考虑到来自推理器的反馈时,训练检索器选择集体具有高分数的nK条路径来推断答案。尽管这两个部分被联合训练,但是推理仍然在每个时期对检索到的整个子图执行。在附录中介绍了训练过程。
5 实验
在本节中,进行了大量的实验来评估子图检索(SR)增强模型。我们设计的实验主要回答四个问题:(1)SR在提高问答成绩方面是否有效?(2)SR能否获得更小但质量更高的子图?(3)弱监督和无监督预训练如何影响SR的性能?(4)端到端的微调能提高检索器和推理器的性能吗?
ad-hoc:简单易于实现的
5.1 实验设置
数据集,

基线模型对比,评估指标为Hits@1

5.2 总体问答评估
与上述基于嵌入的模型相比,在两个数据集上都可以观察到明显的性能改善,例如,SR (SR+NSM)注入的NSM在WebQSP上提高了14.2%的Hits@1,在CWQ上提高了11.3%。还证明了SR可以适用于不同的面向子图的推理机。在NSM之外,当向GRAFT-NET注入SR时,它也显著提高了13.9-19.3%的@1命中率。我们没有将SR注入BAMNet,因为模型需要子图中的实体类型,这被SR暂时忽略了。
总结。总体评价表明,在面向子图的推理机之前注入SR,可以有效地提高问答系统的性能,而带有NSM的SR为基于嵌入的KBQA推理创造了一个新的模型。
5.3 检索器评估
检索子图的质量。评估提出的SR是否可以获得更小但更高质量的子图,这不仅通过直接子图大小和答案覆盖率来衡量,还通过最终的问答性能来衡量。为了公平比较,我们将推理器固定为NSM,将检索器改变为SR,即基于的启发式检索(孙等,2018;何等,2021),以及PullNet *一种变体PullNet(孙等,2019)。
PullNet*升级了PullNet,采用相同的SR作为检索器,NSM作为推理器,但训练它们的方式不同于提议的两阶段策略。由于PullNet通过检索器选择关系并通过NSM交互扩展实体,推理器需要在整个子图之外的每一步都在部分子图上训练。在图4中报告了比较结果。
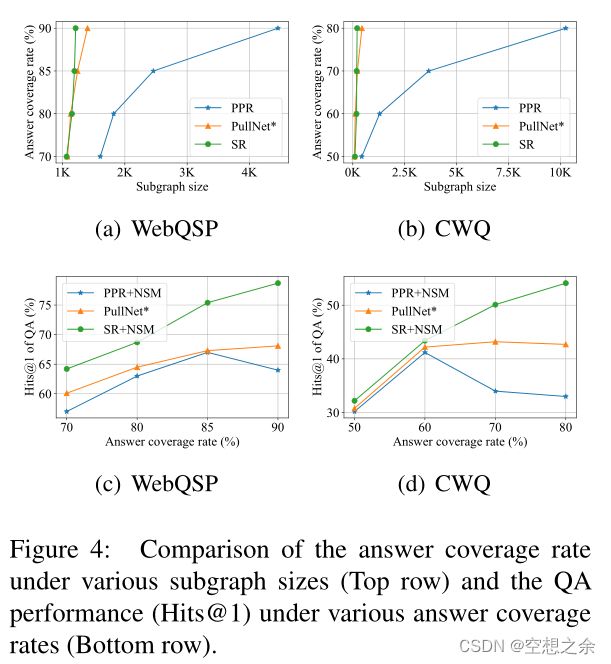
顶行显示了不同大小的子图的答案覆盖率。结果表明,在检索相同大小的子图时,SR的答案覆盖率高于PullNet*,并且显著高于PPR。最下面一行显示了具有不同回答覆盖率的子图上的QA性能(Hits@1)。结果表明,通过对具有相同覆盖率的子图执行相同的NSM,由SR检索的子图可以产生比PPR和PullNet*更高的QA性能。
总结。上述结果表明,SR可以获得更小但质量更高的子图。
5.4 问题更新、路径结束和子图合并的效果。

作者研究了SR中使用的策略的效果,包括问题更新策略(QU)在每个时间步将原始问题与部分扩展的路径连接起来,路径结束策略(PE)学习何时停止扩展路径,以及子图合并策略(GM)从top-nK路径中归纳出一个子图。
表3表明,基于SR,当移除QU (SR w/o QU)时,Hits@1下降3.2-10.2%,当将PE改变为固定路径长度T (SR w/o PE)时,Hits@1下降2.7-8.5%,其中在WebQSP和CWQ上最优T都被设置为3。
表4显示,基于SR+NSM,当去除子图合并策略(SR+NSM w/o GM)但直接取来自不同主题实体的所有子图的并集来归纳子图时,平均子图大小从44.8增加到241.5,QA的Hits@1下降1.4%。我们只给出CWQ的结果,因为WebQSP中的大多数问题只包含一个主题实体,不需要合并操作。
总结。上述结果验证了所设计的QU、PE和GM在SR中的有效性。
5.5 训练策略评估
预训练的效果。作者研究了弱监督和非监督预训练对SR的影响。表3显示了监督训练
(SR w SuperT)和弱监督预训练(SR)的性能,这表明当检索超过10条路径时,SR与SR w SuperT相当甚至更好。
因为主题实体和答案之间的单一基础事实路径是由WebQSP和CWQ提供的,这可能会忽略可以找到多个基础事实路径的情况。有鉴于此,检索多条最短路径作为地面实况的弱监督方式可以提供更丰富的监督信号。
作者进一步改变中弱监督数据的比例{0%,20%,50%,100%},并在图5中给出由前10条路径(即
Hits@10)导出的子图。注意0%意味着SR中使用的RoBERTa没有任何微调。
性能显示出与弱生成数据大小一致的增长,这证明了它的积极效果。
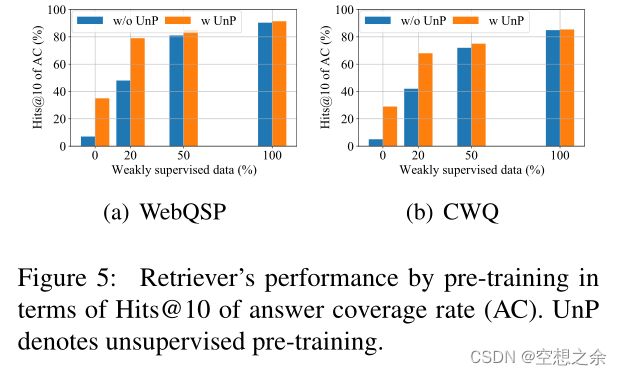
在弱监督预训练之前,作者为无监督预训练创建10万个伪实例(详情参见第5节)。橙色条表示的结果显示,无监督预训练可以将原始SR (0%弱监督数据)显著提高超过20%的Hits@1。在无监督预训练后仅添加20%的弱监督数据就可以获得与100%弱监督数据相当的性能。
总结。上述结果显示了弱监督预训练的有效性。同时,无监督策略可以作为问答配对稀缺时的替代选择。
端到端微调的效果。表3显示SR+NSM w E2E和SR+GN w E2E基于SR提高了0.3-1.6%的检索Hits@10。表2显示SR+NSM w E2E基于SR+NSM提高了0.5-1.6%的QA Hits@ 1,SR+GRAFT-Net wE2E基于SR+GRAFT-Net提高了0.5-1.6%的QAHits @ 1。
总结。上述结果表明,由推理器估计的答案可能性为微调检索器提供了正反馈。随着检索器的改进,推理机也可以通过更新子图来增强。
6 总结
提出了一个子图检索器(SR ),它与后续的KBQA推理机相分离。SR被设计为有效的双编码器,其可以在扩展路径以及确定扩展的停止时更新问题。两个基准测试的实验结果表明,在面向子图的推理机之前注入SR,可以有效提高QA性能。如果通过弱监督预训练以及端到端微调来学习SR,配备有NSM的SR为基于嵌入的KBQA方法创建新的SOTA结果。