文献阅读:Selective-Supervised Contrastive Learning with Noisy Labels
带有噪声标签的选择性监督对比学习——Shikun Li . CPVR 2022
摘要
深度网络有很强的能力将数据嵌入到隐藏表征中并完成后续任务。然而,这些能力主要来自于高质量的标注标签,但收集成本很高。噪声标签更实惠,但会导致表征被破坏,从而导致泛化性能差。
本文提出的选择性监督的对比学习(Sel-CL)扩展了监督对比学习(Sup-CL)。由于 Sup-CL 是以成对的方式进行工作,由噪声标签建立的噪声对 会误导表征学习。为了缓解这个问题,在不知道噪声率的情况下,从有噪声的对中选择有信心的对来进行 Sup-CL。在选择过程中,通过测量学习到的表征和给定标签之间的一致性,首先识别出自信的实例,利用这些例子来建立自信的对。然后,利用建立的自信对中的表征相似性分布,从噪声对中找出更多的自信对。所有获得的自信对最终被用于Sup-CL,以增强表示。
下面是介绍噪声标签影响深度网络的泛化性能的原因。这是因为,在带有噪声标签的数据集的监督下,错误标签的数据在为实例诱导潜在表示时提供了错误的信号。造成下图中不精确的分类边界。损坏的表示会导致后续任务的决策不准确,损害泛化。

贡献
1)我们提出了带噪声标签的选择性监督对比学习,通过有效地选择置信对 进行 Sup-CL 来获得预训练的鲁棒表示。
2)在不知道对的噪声率的情况下,该方法选择由已识别的置信样例构建的对和具有高表征相似度的样例构建的对。它实现了一个好的循环,更好的自信对会产生更好的表征,而更好的表征会识别出更好的自信对。
3)我们在合成和真实世界的噪声数据集上进行了实验,这清楚地证明了我们的方法与最先进的方法相比获得了更好的性能,还提供了全面的消融实验和讨论。
Sel-CL算法
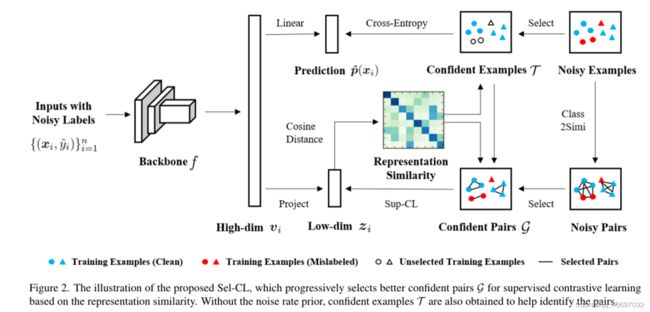 Sel-CL算法图像
Sel-CL算法图像
提出的Sel-CL算法,该算法基于表示相似度逐步选择更好的置信对G进行监督对比学习。在没有先验噪声率的情况下,还得到了置信例T来帮助识别对。我们给定一个带噪声标记的数据集![]() ,其中n是样本大小,
,其中n是样本大小, 是第i个示例的实例,而
是第i个示例的实例,而![]() ∈[C]是对应的噪声标签。
∈[C]是对应的噪声标签。
在没有先验噪声率的情况下,为了帮助识别对,在此过程中还得到了置信样例T。所使用的预训练网络由三个部分组成:
(1)将实例映射到高维表示 的 深度编码器f( 卷积神经网络backnone);
的 深度编码器f( 卷积神经网络backnone);
(2)一个分类器头(后跟softmax函数的全连接层),它接收作为输入和输出类预测器![]() ;
;
(3)将映射为低维表示形式 的线性或非线性投影。
的线性或非线性投影。
对比学习
其中A(i)表示不包括i的指标集,通过测量得到的低维表示与给定标签之间的一致性来识别置信实例,我们给定两个低维表示zi和zj
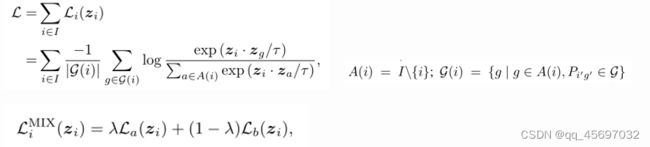
分类学习
算法还采用了一个具有置信实例的分类目标来稳定收敛性,并获得更好的表示效果。对于T的置信实例,分类学习使用
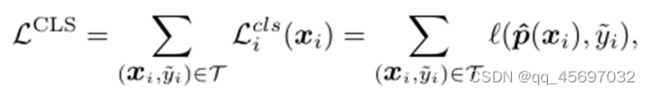
受最近学习相似标签分类器的方法的启发,我们添加了一个学习目标,使用分类器预测直接从相似标签中学习。给定一个小批数据,添加的相似度损失为
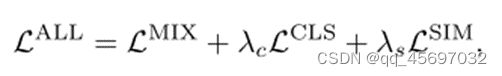
综合上述分析,总损耗为
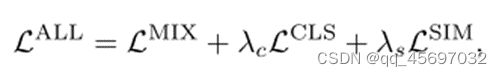 其中
其中![]() 和
和![]() 为损失权重
为损失权重
实验
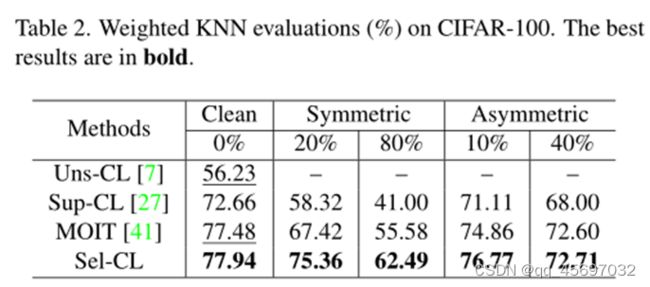
这里选取了部分实验结果,由上图可以看出,当无噪声时,MOIT极大地提高了学习表示的质量。得益于相似性损失的应用,Sel-CL获得了0.46%的质量增益。其次,对于噪声数据集,Sup-CL受到噪声标签的严重影响。尽管MOIT通过Mixup技术和半监督策略提高了鲁棒性,但其性能仍不理想。例如,在对称噪声为80%的情况下,MOIT的加权KNN准确率为55.58%,甚至低于Uns-CL的56.23%。相比之下,我们的Sel-CL通过选择自信对进行监督对比学习,显著缓解了噪声标签的副作用。我们可以看到,在不同的情况下,Sel-CL的性能始终优于基线。
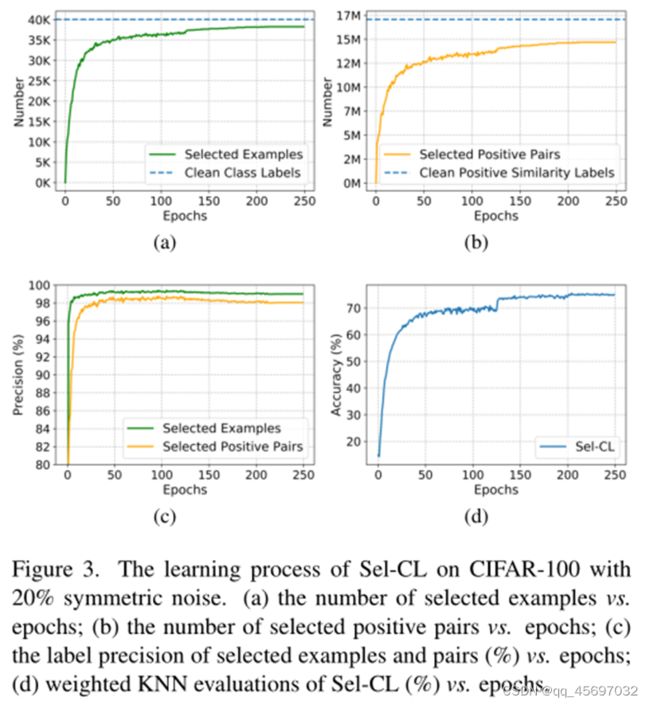
我们还举例说明了所选置信示例和对的数量,所选置信示例和对的标记精度,以及KNN算法等的学习。实验在20%对称噪声下进行。由上图可以看出,自信例/对的选择和表征学习形成了一个良性循环,Sel-CL可以逐步实现有效的选择和改进表征学习。
局限
1) 本工作利用了对比学习,因此我们的方法的性能依赖于足够的数据增强和大量的负样本。需要更大的批处理容量或存储库,这对计算设备的存储提出了更高的要求。
2) KNN算法的使用带来了更大的计算消耗。在这项工作中,我们使用了一些更快的KNN算法来缓解上述问题,这有助于我们的方法在大规模数据集上的应用。
总结
本文提出了一种通过学习鲁棒预训练表示来处理训练数据中噪声标签的新方法——选择性监督对比学习(Sel-CL)。我们利用对比学习的两两特性来更好地增强网络的鲁棒性。在不考虑噪声率的前提下,从噪声对中选择自信对进行监督对比学习。我们通过在多个噪声数据集上的大量实验证明了我们的方法的最新性能。对于未来的工作,我们感兴趣的是将我们的方法扩展到其他任务,如对象检测和文本匹配。
补充
CIFAR-10 数据集:https://blog.csdn.net/qq_46834466/article/details/125194540
CIFAR-100数据集:https://blog.csdn.net/nyist_yangguang/article/details/126077044
论文/Paper:https://arxiv.org/abs/2203.04181
代码/Code:https://github.com/ShikunLi/Sel-CL