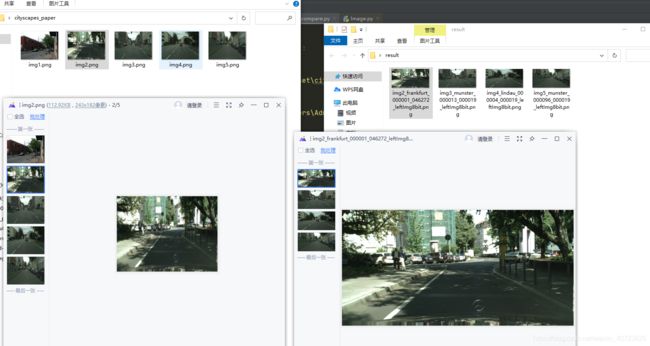
python: 海量图片检索:“以图搜图“
说明:由于很多论文里面的测试图片没有标号,就不能确定它们是Testset数据集中哪几张图片。为了能解决这个问题,需要完成以图片去搜索整个数据集文件目录的任务。
待搜索图:

测试集:
new_similarity_compare.py
# -*- encoding=utf-8 -*-
from image_similarity_function import *
import os
import shutil
# 融合相似度阈值
threshold1 = 0.70
# 最终相似度较高判断阈值
threshold2 = 0.95
# 融合函数计算图片相似度
def calc_image_similarity(img1_path, img2_path):
"""
:param img1_path: filepath+filename
:param img2_path: filepath+filename
:return: 图片最终相似度
"""
similary_ORB = float(ORB_img_similarity(img1_path, img2_path))
similary_phash = float(phash_img_similarity(img1_path, img2_path))
similary_hist = float(calc_similar_by_path(img1_path, img2_path))
# 如果三种算法的相似度最大的那个大于0.7,则相似度取最大,否则,取最小。
max_three_similarity = max(similary_ORB, similary_phash, similary_hist)
min_three_similarity = min(similary_ORB, similary_phash, similary_hist)
if max_three_similarity > threshold1:
result = max_three_similarity
else:
result = min_three_similarity
return round(result, 3)
if __name__ == '__main__':
# 搜索文件夹
filepath = r'D:\Dataset\cityscapes\leftImg8bit\val\frankfurt'
#待查找文件夹
searchpath = r'C:\Users\Administrator\Desktop\cityscapes_paper'
# 相似图片存放路径
newfilepath = r'C:\Users\Administrator\Desktop\result'
for parent, dirnames, filenames in os.walk(searchpath):
for srcfilename in filenames:
img1_path = searchpath +"\\"+ srcfilename
for parent, dirnames, filenames in os.walk(filepath):
for i, filename in enumerate(filenames):
print("{}/{}: {} , {} ".format(i+1, len(filenames), srcfilename,filename))
img2_path = filepath + "\\" + filename
# 比较
kk = calc_image_similarity(img1_path, img2_path)
try:
if kk >= threshold2:
# 将两张照片同时拷贝到指定目录
shutil.copy(img2_path, os.path.join(newfilepath, srcfilename[:-4] + "_" + filename))
except Exception as e:
# print(e)
pass
image_similarity_function.py
# -*- encoding=utf-8 -*-
# 导入包
import cv2
from functools import reduce
from PIL import Image
# 计算两个图片相似度函数ORB算法
def ORB_img_similarity(img1_path, img2_path):
"""
:param img1_path: 图片1路径
:param img2_path: 图片2路径
:return: 图片相似度
"""
try:
# 读取图片
img1 = cv2.imread(img1_path, cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(img2_path, cv2.IMREAD_GRAYSCALE)
# 初始化ORB检测器
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# 提取并计算特征点
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# knn筛选结果
matches = bf.knnMatch(des1, trainDescriptors=des2, k=2)
# 查看最大匹配点数目
good = [m for (m, n) in matches if m.distance < 0.75 * n.distance]
similary = len(good) / len(matches)
return similary
except:
return '0'
# 计算图片的局部哈希值--pHash
def phash(img):
"""
:param img: 图片
:return: 返回图片的局部hash值
"""
img = img.resize((8, 8), Image.ANTIALIAS).convert('L')
avg = reduce(lambda x, y: x + y, img.getdata()) / 64.
hash_value = reduce(lambda x, y: x | (y[1] << y[0]), enumerate(map(lambda i: 0 if i < avg else 1, img.getdata())),
0)
return hash_value
# 计算两个图片相似度函数局部敏感哈希算法
def phash_img_similarity(img1_path, img2_path):
"""
:param img1_path: 图片1路径
:param img2_path: 图片2路径
:return: 图片相似度
"""
# 读取图片
img1 = Image.open(img1_path)
img2 = Image.open(img2_path)
# 计算汉明距离
distance = bin(phash(img1) ^ phash(img2)).count('1')
similary = 1 - distance / max(len(bin(phash(img1))), len(bin(phash(img1))))
return similary
# 直方图计算图片相似度算法
def make_regalur_image(img, size=(256, 256)):
"""我们有必要把所有的图片都统一到特别的规格,在这里我选择是的256x256的分辨率。"""
return img.resize(size).convert('RGB')
def hist_similar(lh, rh):
assert len(lh) == len(rh)
return sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)
def calc_similar(li, ri):
return sum(hist_similar(l.histogram(), r.histogram()) for l, r in zip(split_image(li), split_image(ri))) / 16.0
def calc_similar_by_path(lf, rf):
li, ri = make_regalur_image(Image.open(lf)), make_regalur_image(Image.open(rf))
return calc_similar(li, ri)
def split_image(img, part_size=(64, 64)):
w, h = img.size
pw, ph = part_size
assert w % pw == h % ph == 0
return [img.crop((i, j, i + pw, j + ph)).copy() for i in range(0, w, pw) \
for j in range(0, h, ph)]
结果: