2022/2/15 Hand Pose Estimation:综述阅读1
(Hand Pose Estimation:A Survey)2019
手势姿态估计
- 手势姿态估计的基本问题
- 解决手势姿态估计的新进展,尤其是使用深度图或者RGB图像的问题
- 讨论近期论文所提出方法的优缺点
- 解释了手势姿态估计领域的最大的数据集,而且列举了22个其他的数据集
1 Introduction
手势姿态估计的进展越来越快,成果也越来越多,并且制作深度图的RGBD相机已经变得便宜,这降低了制作和使用手持系统的成本。
同时谷歌、微软和Facebook等大型科技公司对增强现实(AR)、虚拟现实(VR)和混合现实(MR)技术作为新型交互式个人电脑的巨大投资,拓宽了这一领域的应用。因此,人机交互(HCI)中一个相对较新的分支被引入研究通过理解用户的手来控制的系统。
很多研究团队使用手势姿态估计的方法制作出了大量有趣的应用:
- 应用在AR,VR,MR中
- 使用手指动作的系统
- 空气中的键盘
- 手语识别
- 使用指尖检测和跟踪来读取手指在空中书写的字母表。
当前的趋势: 近年来,对手指控制系统的兴趣使研究人员更加雄心勃勃,他们放弃了2.5D深度贴图图像,试图通过单个RGB图像估计手的姿势。这种方法是一项更难的任务,需要大量数据进行训练。
2 Hand Pose Estimation Problem
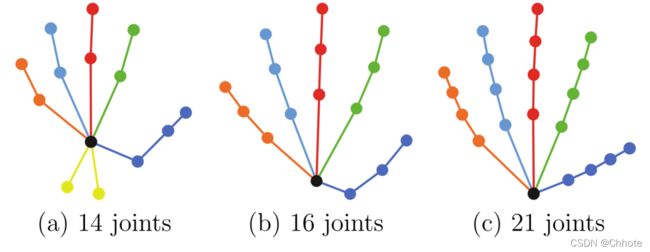
Visualization of modeling hand with 14, 16 and 21 joints as used in NYU [48],ICVL [45], and MSRA [30] datasets. Originally used in [15]
对于不同数据集中用于手部建模的关节数量,目前尚无全球共识。但是21个关节现在是最流行的模型,大多数数据集和预先训练的网络都使用这种模型。
3 Approaches
在使用深度学习解决手势姿态估计之前,人们通常用传统机器学习的方法和其他计算机视觉的方法来解决,其中有一些比较成功的解决方案:Wang等人[51]为用户使用了彩色手套,然后通过使用最近邻,他们找到了图像中每种颜色的位置,从而找到了手的每个特定部位的位置。其中最为成功的是随机森林及其变种,在那个时候,这种方法是最成功的,并在商业产品中取得了成功。
下面主要介绍利用深度学习来解决手势姿态估计的方案,尽管我们可以使用2D或3D CNN将这些方法分为估算2D或3D骨架、基于检测和基于回归的算法,但是我们将它们分为使用深度贴图的方法和使用RGB图像的方法,或者两者兼而有之。我们首先定义两种不同类型的网络,用于解释算法。
Detection-based Methods vs. Regression-based Methods
在基于检测的方法中: 模型会为手部的每个关节生成概率密度图,例如,如果一个网络对手部使用的21个关节模型,对于每个图像,它将生成21个不同的概率密度图作为热图。通过在相应的热图上应用argmax函数,可以找到每个关节的确切位置。

在基于回归的方法中: 基于回归的方法试图直接估计每个关节的位置。也就是说,如果它使用21个关节模型,它应该在最后一层有3×21个神经元来预测每个关节的(x,y,z)坐标。由于高度非线性,训练基于回归的网络需要更多的数据和训练迭代。
但是,由于为每个关节生成3D概率密度函数对于网络来说是一项繁重的任务,因此基于回归的网络用于3D手姿势估计任务
3.1 Depth-based Methods
- Ayan Sinha, Chiho Choi, and Karthik Ramani. Deephand: Robust hand pose estimation by completing a matrix imputed with deep features. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4150–4158, 2016.
Sinha等人使用基于回归的方法,根据深度图找到了手上的21个关节。他们试图独立地找到每个手指的关节位置。为此,他们为每个手指训练了一个单独的网络,使手指上的三个关节回归。请注意,尽管他们使用深度贴图来回归坐标,但他们也使用RGB来隔离手部,并移除手部裁剪帧中包含的所有其他像素。 不像其他的网络一样,Sinha并没有使用一个单独的神经网络来进行手部分割,当然这可能是因为计算能力限制。

- Seungryul Baek, Kwang In Kim, and Tae-Kyun Kim. Augmented skeleton space transfer for depth-based hand pose estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
Baek等人使用生成对抗网络(GAN)[12]通过在深度视差图和3D手姿势模型之间建立一对一关系来估计手姿势。GAN是一个基于之前学习的样本生成新样本的特定CNN。它由一个鉴别器和一个发生器网络组成,它们相互竞争以赢得比赛。鉴别器网络是一种经过训练的分类器,用于检测真假图像。生成器也是一个卷积神经网络,它基于随机初始化生成假图像。这些假图像应该足够好,以欺骗鉴别器作为真实的。
Conditioned GAN[27]是一种特殊的GAN,它可以获得真实图像,并条件生成与该图像类似的图像。
注:发生器不会从随机初始化开始。
- J. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2242–2251, Oct 2017.
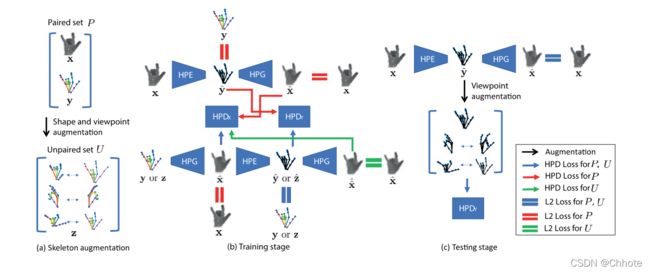
Baek等人的基于GAN的网络架构。在图中,与成对集P和未成对集U的交互分别用红色和绿色表示,蓝色线表示与U和P的交互。
Baek等人使用CyclicGAN,这是一种用于将一个图像从一个域传输到另一个域的GAN。在这项工作中,一个领域是手的深度图,另一个领域是手关节的三维表示。Baek等人在他们的模型中使用了手姿势生成器(HPG)和手姿势鉴别器(HPD)。从上面的解释可以猜到,HPG的工作是根据关节的3D表示生成手。相比之下,他们使用了手姿势估计器(HPE),其工作是根据输入的深度图生成3D手姿势。因此,在训练步骤中,对HPG、HPD和HPE进行了优化,以减少HPE的误差(这是该算法的最终目标),并提高HPE-HPG组合 f E ( f G ) f^{E}(f^{G}) fE(fG) 的一致性:Y→ Y和HPG-HPE组合 f G ( f E ) f^{G}(f^{E}) fG(fE) :X→ X.在测试阶段,该算法在HPG的指导下细化3D模型,以生成最佳3D模型,其对应的深度图与输入深度图非常相似。
- Liuhao Ge, Hui Liang, Junsong Yuan, and Daniel Thalmann. Robust 3d hand pose estimation in single depth images: from single-view cnn to multi-view cnns. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3593–3601, 2016.
Ge等人[9]在基于深度的方法中创造了一种新技术,并且这种技术多次被其他团队和其他研究使用。本文(以及他们的下一篇论文[10])的主要思想是从2.5D图像估计3D图像,然后从这个新的视角估计手的姿势。虽然他们没有提到如何从深度图生成这个3D模型,但从引用的论文中可以理解,他们没有使用机器学习算法来执行这一部分。
正如我们所知,深度贴图只提供手的表面,而不是3D形状。为了估计3D形状,他们将相机固定在3D空间中,并将曲面固定为相机视线中的最远点。因此,对于深度贴图中的每个像素,与距离数成比例,他们应该将该表面的体素放置到相机上。通过这种方法,由这些体素生成的深度图和原始深度图是相同的。在下一步中,他们必须从三个垂直视图渲染这些3D体积;前面、上面和侧面。为此,他们在体素坐标上应用了主成分分析(PCA),并选取了最上面的三个主成分,并在这些平面上渲染了3D形状。他们将这些深度图传递给网络,并得到每个xy、xz和yz平面中每个关节的概率。在他们称之为融合的下一步中,他们通过将概率相乘来混合概率。
3d convolutional neural networks for efficient and robust hand pose estimation from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 1, page 5, 2017
这是Ge等人的另一篇文章
在这篇文章中,Ge等人采用了与上一篇类似的方法,并使用了三种不同的CNN。但是,他们用截断符号距离函数(TSDF)生成了三个3D形状,而不是2D渲染。在TSDF形状中,体素到最近曲面的有符号距离将存储在每个体素中。同样对于融合步骤,他们没有将概率相乘,而是将输出向量串联起来,并使用三个完全连接的层来获得最终结果。他们在MSRA[30]和NYU[48]数据集上测试了他们的方法,与其他方法相比,获得了最佳结果,并且有很好的裕度。

Liuhao Ge, Yujun Cai, Junwu Weng, and Junsong Yuan. Hand pointnet: 3d hand pose estimation using point sets. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
这是Ge等人的又一篇文章
Ge等人[8]将PointNet应用于他们的3D形状估计(HandPointNet)。首先,他们从3D形状中的点进行采样以以固定且较少的点数作为输入。 此外,他们还应用了之前的PCA分析,将手的3D形状朝着主成分旋转。然后,他们运行分层的 PointNet 进行3D手姿势回归。在每一步中,该网络都会对点进行下采样。最后,他们使用全连接层来回归手关节在空间中的确切位置。
在下一篇文章中,Ge等人在[11]中继续采用相同的方法,改变了网络结构。
Liuhao Ge, Zhou Ren, and Junsong Yuan. Point-to-point regression pointnet for 3d hand pose estimation. In The European Conference on Computer Vision (ECCV), September 2018.
因此,他们没有使用多层对点进行下采样,而是使用了类似于编码器-解码器体系结构的体系结构。该结构首先学习全局特征,然后使用这些全局特征生成用于估计关节位置的理想点数。
- Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
Moon等人使用类似的2.5D深度映射到基于三维体素的手形转换器,设计了一个基于检测的体素到体素网络(V2V),根据估计的三维手形直接估计每个手部的位置。由于输入和输出都是3D的,他们使用3D CNN在3D域进行所有卷积和反卷积操作。本文背后的想法是,从一只手的不同角度拍摄的深度贴图具有相同的3D姿势。要通过深度贴图估计手的姿势,需要训练模型,以便为不同的深度贴图输入生成相同的姿势。另一方面,3D点云正好有一个3D手姿势,因此它们的关系是一对一的。因此,我们可以在手的3D点云上训练模型,并通过3D编码器和解码器直接生成3D姿势,而不是拥有一个庞大的数据集来覆盖手的所有形状。
在ResNet[14]的残差块成功用于目标分类后,Moon等人也使用了具有更深层网络的残差块。他们把算法应用于几乎所有著名的基于深度的手数据集,并将它们的方法与绝大多数算法进行比较,得到了与其他算法相比具有高裕度的最佳结果。关于该算法的一个有趣的事实是,它也可以很容易地应用于身体姿势估计问题。他们在ITOP数据集[13](俯视图和前视图)上测试了算法,并报告了结果。下图显示了V2V-PoseNet的体系结构。

3.2 Image-based Methods
尽管使用简单的RGB图像作为输入会使模型具有很好的泛化能力,可以在任何地方使用,但将输入的维数从2.5D降低到2D将使任务变得非常困难。使用RGB图像训练网络所需的数据比使用深度图训练类似网络所需的数据大得多。下面我们将首先讨论基于RGB的网络中使用的一般方法,然后我们将讨论顶级基于图像的算法如何解决注释数据和创建更大数据集的高成本问题。因此,本节中大多数有影响力的研究都提出了自己的数据集。
需要注意的是,基于图像的方法需要首先隔离手(裁剪和调整大小),然后将裁剪后的图像传递给网络以估计姿态。为此,大多数基于图像的网络使用SegNet[1]的变体,其设计用于分割一般图片(例如街道图片)。由于二分类(手或背景)和输入图像的多样性,手分割是一个相对容易的任务比一般的分割问题。因此,用于手部分割的分割网络比普通SegNet重量更轻,因此执行速度更快。在以下论文中,除非提及,否则SegNet的一种变体用于隔离手部,作为预处理步骤。
- Christian Zimmermann and Thomas Brox. Learning to estimate 3d hand pose from single rgb images. In Proceedings of International Conference on Computer Vision (ICCV), volume 10, 2017.
基于RGB的方法的重要工作之一是Zimmermann等人的论文和数据集[60]。在本文中,他们使用四种不同的深度学习流,使用单个RGB图像对手关节进行3D估计。他们首先使用了一个名为HandSegNet的CNN,这是Wei等人[52]的人体探测器的轻量版本,该探测器通过手部数据集进行训练.
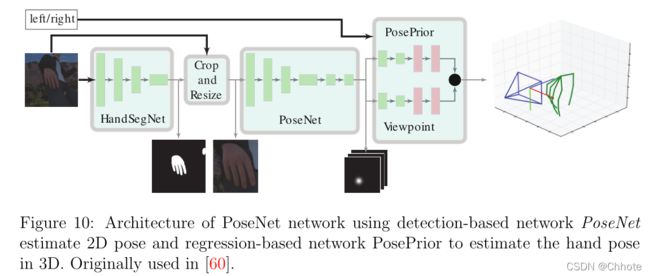
如上图中所示,HandSegNet的输出是一幅显示手部像素的掩模图。根据该图像,对手进行裁剪和调整大小,并将其传递到PoseNet网络。PoseNet是一种基于检测的网络,它为每个手关节生成一个概率密度函数(作为热图)。这些预测是在2D和输入图像的相同坐标上进行的。为了获得3D估计,Zimmerman等人使用了一个名为PosePreor的网络将这些2D预测转换为3D手动估计。该网络是基于回归的网络,预测关节坐标,然后进行归一化。在这一步中,它们将关节的距离标准化,将最远距离视为1,并将其他距离除以该数字。最后,他们找到一个3D旋转矩阵,使得某个旋转的关键点与标准框架的y轴对齐。
如前所述,由于RGB图像包含的信息少于深度视差图,因此基于RGB的网络更难训练,需要更大的数据集。基于图像的方法中最重要的问题是遮挡问题。是指物体或手本身挡住了手的某些部分。以下两篇论文使用了两种不同的创新解决方案来解决这个问题。
- Tomas Simon, Hanbyul Joo, Iain A Matthews, and Yaser Sheikh. Hand keypoint detection in single images using multiview bootstrapping. In CVPR, volume 1, page 2, 2017.
受Wei等人人体姿态估计方法的启发,Simon等人在[37]中使用了多摄像机方法来估算手的姿势。他们使用了卡内基梅隆大学的全景摄影棚[17],在一个球形空间中包含500多个摄像头(480个VGA和30多个HD摄像头)。他们首先使用合成的手数据集训练弱手姿势估计器。在下一步中,他们将一个人放在全景图像的中心,并在所有记录视频的摄像机上应用手姿势估计器。该算法为所有这些视图生成一个(不是非常精确的)姿势估计。它在大多数视图中都有效,但在手被遮挡的视图中效果不太好。

在下一部分中,Simon等人称之为三角测量步骤,他们将2D估计转换为3D估计以评估结果,同时了解所有相机的固有参数及其相对物理位置。为了估计正确的3D姿势,对于每个关节,他们使用RANSAC[6]算法随机选择2D视图并将其转换为3D视图。然后他们保留了大多数观点一致的模型。最后,在反向操作中,他们将3D视图投影到图片上,并对该帧进行注释。事实上,他们没有手动注释数据,而是使用多个视图来注释数据。然后使用这个来自多个视图的带注释的数据集,他们再次训练网络,使其更加准确。他们重复了三次注释和训练模型的过程,因此最终得到了一个非常好且准确的模型和注释手姿势数据集。对于特征提取,他们使用了预先训练过的VGG-19网络[38](高达conv4),该网络产生128个通道的特征。图11显示了Simon等人[37]论文中的三角测量、投影和再培训步骤。
为了克服遮挡问题,尤其是数据集的大小以及逐帧注释手的高成本,Mueller等人[23]使用了一个自动注释的合成数据集。他们使用多个电磁传感器(通常是6个6D传感器)连接到一只手上的运动传感器。这些传感器连接到一个接收器和一个发射器,该接收器和发射器自动生成3D手姿势.
虽然合成数据集很容易生成和标注,但是缺乏真实性和一般性。由于该设备生成的图像是计算机生成的,因此在真实的手部图像上无法很好地工作。为了解决这个问题,他们使用了一种称为GeoConGAN的条件化GAN[27],将计算机生成的图像转换为真实图像。此外,为了在真实图像和计算机生成的图像之间实现更好的一对一关系,他们应用了CyclicGAN[59],该CyclicGAN[59]具有真实到合成GAN(称为real2synth)和合成到真实GAN(称为synth2real)的两部分。每个GAN都有自己的生成器和鉴别器。穆勒等人用两个损失控制了这个过程;首先将合成图像转换为真实图像并计算synth2real损耗,然后再次将结果转换为合成图像并计算real2synth损耗。他们还随机在手后放置一些背景,使图像更逼真。此外,为了在手上创建遮挡,他们人为地将一些对象放在手的前面,以便在数据集中也有一些遮挡的帧。他们使用ResNet[14]体系结构作为特征提取网络,以利用剩余块。图12显示了Mueller等人论文[23]中数据集生成和手姿势估计的不同步骤。

- Adrian Spurr, Jie Song, Seonwook Park, and Otmar Hilliges. Cross-modal deep variational hand pose estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
Spurr等人[40]也使用这个循环概念,在RGB图像和3D手关节姿势之间建立一对一的关系。他们使用GAN和变分自动编码器(V AE)将图像传输到一个潜在空间,然后将其传输到另一个域。有了这个,他们试图将每个RGB手部图像映射到一个3D姿势,并在手部姿势估计任务中使用这个映射。
到目前为止,我们只讨论了使用深度视差图或单个RGB图像的算法。但也有研究使用了RGBD图像(即同时使用RGB图像及其相应的深度视差图)。此外,一些研究人员在训练期间使用RGBD图像,在测试时使用RGB。
- Endri Dibra, Silvan Melchior, Ali Balkis, Thomas Wolf, Cengiz Oztireli, and
Markus Gross. Monocular rgb hand pose inference from unsupervised refinable nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1075–1085, 2018.
Dibra等人在中设计了一个使用RGBD的网络,他们使用一个名为SynthNet的特定网络来估计手的姿势。通过生成的3D形状(整个手的3D形状,而不仅仅是骨骼),他们生成了一个深度图。他们对深度图输入也做了同样的处理。使用上述方法,他们从2.5D深度图生成了一个3D模型,然后根据这些3D模型生成的两个深度图的差异计算算法的损失。
与目前讨论的几乎所有论文不同,Dibra等人没有使用关节模型。在这篇论文中,他们提出了一种新的手部姿势估计方法。在他们的模型中,他们产生了一个手的形状,这在物理上是可能的(考虑到之前所有可能的手姿势)。

还有一些模型同时使用深度视差图和RGB图像。为了使估计更准确,Kazakos等人在[18]中使用了两种不同的深度学习流,用于RGB和深度视差图,称为FuseNet。他们使用两个相同的卷积神经网络来提取RGB和深度图图像的特征。最终预测由两个完全连接的层生成,该层回归每个关节的(x、y、z)坐标。尽管使用了两种不同的流,但它们的结果不如使用其中一种输入的其他方法。图14显示了FuseNet体系结构中的两个不同流。

4 Datasets
- ICVL Hand Dataset
The Imperial College Vision Lab (ICVL) dataset [45] is one of the oldest datasets in hand pose estimation field. It contains 180K annotated depth frames. They used 10 subjects to take 26 different poses. 16-joints model was used in annotating this dataset. - NYU Hand Dataset
New York University (NYU) dataset [48] contains 72,757 frames from a single actor in the train set and 8,252 frames from two different actors in test set. It is an RGBD dataset captured from side view (3rd person view). 36-joints model was used model to annotate this dataset. - HandNet Dataset
HandNet dataset [53] is one of the biggest depth datasets. It is generated using kinematic sensors with 10 different subjects, half male and half female to have different hand sizes in the dataset. It contains 202K frames in the trainning set and 10K frames in the test set. 6-joints model was used to annotate data. - CMU Panoptic Hand Dataset
Carnegie Mellon University (CMU) Panoptic [37] is RGB images which are recorded and annotated in the CMU’s Panoptic studio. It contains both the synthesized and real images with 14,817 frames in 3rd person view which are annotated by 21-joints model in 2D. - BigHand 2.2M Benchmark Hand Dataset
The BigHand 2.2M Benchmark [57] is the biggest hand dataset so far. As we can see from its name it has, 2.2M annotated depth frames which are generated from 10 different subjects using kinematic six 6D electromagnetic sensors. Like all the recent datasets, it uses 21-joints model annotated in 3D. As the whole dataset was annotated with kinematic sensors, no object was held in the hands. - First-Person Hand Action dataset
The First-Person Hand Action dataset (FHAD) [7] is a new dataset introduced by The Imperial College. It contains 105,459 frames of egocentric view of 6 subjects doing 45 different types of activities in the kitchen, in the office or social activities. This dataset was also annotated in 3D, using 21-joints model. - GANerated Hand Dataset
GANerated is a new big dataset for the RGB-based dataset which has interaction with objects that can be helpful in estimating the hand pose under occlusion. It contains 330K frames synthesized hand shapes annotated in 3D using 21 joints model. In this dataset kinematic electromagnetic sensors was used to capture the hand pose. Also a
CycleGAN was utilized to convert these computer generated images to look like real images. Different backgrounds was randomly put behind the hands to make them more similar to real photos. Also artificial objects was put on the hand to produce a hand occlusion.
全部数据集

共勉!!