从sklearn说机器学习
SKlearn简介
scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
SKlearn官网:scikit-learn: machine learning in Python
在工程应用中,用python手写代码来从头实现一个算法的可能性非常低,这样不仅耗时耗力,还不一定能够写出构架清晰,稳定性强的模型。更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。而sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。

sklearn有一个完整而丰富的官网,里面讲解了基于sklearn对所有算法的实现和简单应用。
常用模块
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、 random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
安装SKlearn
安装最新版本
Scikit-learn需要:
•Python(> = 2.7或> = 3.4),
•NumPy(> = 1.8.2),
•SciPy(> = 0.13.3)。
【注意】Scikit-learn 0.20是支持Python 2.7和Python 3.4的最后一个版本。Scikit-learn 0.21将需要Python 3.5或更高版本。
如果你已经安装了numpy和scipy,那么安装scikit-learn的最简单方法就是使用 pip或者canda
pip install -U scikit-learn
conda install scikit-learn
如果你尚未安装NumPy或SciPy,你也可以使用conda或pip安装它们。使用pip时,请确保使用binary wheels,并且不会从源头重新编译NumPy和SciPy,这可能在使用特定配置的操作系统和硬件(例如Raspberry Pi上的Linux)时发生。从源代码构建numpy和scipy可能很复杂(特别是在Windows上),需要仔细配置以确保它们与线性代数例程的优化实现相关联。为了方便,我们可以使用如下所述的第三方发行版本。
发行版本
如果你还没有numpy和scipy的python安装,我们建议你通过包管理器或通过python bundle安装。它们带有numpy,scipy,scikit-learn,matplotlib以及许多其他有用的科学和数据处理库。
可用选项包括:Canopy和Anaconda适用于所有支持的平台
除了用于Windows,Mac OSX和Linux的大量科学python库之外,Canopy和Anaconda都提供了最新版本的scikit-learn。
Anaconda提供scikit-learn作为其免费发行的一部分。
【注意】PIP和conda命令不要混用!!!
要升级或卸载scikit-learn安装了python或者conda你不应该使用PIP命令。
升级scikit-learn:conda update scikit-learn
卸载scikit-learn:conda remove scikit-learn
使用pip install -U scikit-learn安装或者使用pip uninstall scikit-learn卸载可能都没有办法更改有conda命令安装的sklearn。
算法选择
sklearn 实现了很多算法,面对这么多的算法,如何去选择呢?其实选择的主要考虑的就是需要解决的问题以及数据量的大小。sklearn官方提供了一个选择算法的引导图。
这里提供翻译好的中文版本,供大家参考:

sklearn-TfidfVectorizer彻底说清楚
在做文本分类之前,一定会涉及文本的向量化表示。sklearn提供的是传统的词袋模型,但是相信到现在为止也会有很多人不知道到底sklearn的TfidfVectorizer是怎么算的向量值。这里把它彻底说清楚。首先,列几个常见的困惑。
-
TfidfVectorizer对所使用模型有没有限制?
不是的。TfidfVectorizer并不适用朴素贝叶斯算法。原因是sklearn只是把朴素贝叶斯用矩阵的形式进行计算,因此,在使用朴素贝叶斯时,可以说并不涉及文本的向量空间模型,在sklearn中需要用CountVectorizer将文本词语计数表示为矩阵的形式。而文本的VSM空间模型(词袋模型)主要是为了那些线性类算法而说的,因此CountVectorizer当然适用线性模型,TfidfVectorizer对词项用idf值进行改进,也就是考虑了词项在文档间的分布,也适用于线性模型,同时由于通常线性模型要求输入向量的模为1,因此TfidfVectorizer默认行向量是单位化后的。
-
训练集与测试集的比例会不会影响tfidf值的计算?
会影响。但是影响的是词项的idf值计算,sklearn的TfidfVectorizer默认输入文本矩阵每行表示一篇文本,不同文本中相同词项的tf值不同,因此tf值与词项所在文本有关。而idf值与输入矩阵的行数(也就是训练集文本数)和包含词项的文本数有关,因此idf值与训练集的大小是有关系的。下边的式子是tf-idf计算式:
tf-idf(t,d)=tf(t,d)*idf(t)
idf(t)=
![]()
转存失败重新上传取消
平滑版 idf(t)=
![]()
转存失败重新上传取消
tf(t,d)是tf值,表示某一篇文本d中,词项t的频度,从式子可以看出tf值由词项和文本共同决定
idf(t)是词项t的idf值计算式,nd表示训练集文本数,df(d,t)表示包含词项t的文档总数,因此idf值与训练集文本总数和包含词项t的文本数有关。
-
idf值是对词项权重的一种改进。
idf值对频次表示的文本向量进行了改进,它不仅考虑了文本中词项的频次,同时考虑了词项在一般文本上的出现频率,词项总是在一般的文本中出现,表示它可提供的分类信息较少,比如虚词 “的”、“地”、“得”等。
-
逆文档频率并没有考虑类词项在类别间的分布。
对得。idf值只是考虑了词项在所有文本间的分布特性,这里并不涉及类别,因此TfidfVectorizer的输入也不需要提供类别信息。
-
TfidfVectorizer提供了基于频次的特征选择。
TfidfVectorizer在构建词汇表(特征词表)时考虑了词语文档频次,可以通过设置min_df和max_df来实现通过文档频次进行特征选择。
-
测试集包含一条文本和包好多条文本对于VSM向量值有影响?
没有影响。在TfidfVectorizer中通过fit_transform或fit来实现,词汇表建立,以及词汇表中词项的idf值计算,当然fit_transform更进一步将输入的训练集转换成了VSM矩阵形式。TfidfVectorizer的transform函数用于对测试文本进行向量化表示。表示的过程中用到训练得到的词汇表以及词项的idf值,而tf值由测试文本自身决定,因此一篇和多篇对于单篇文本向量表示没有影响。
上边问题有的是我不确定的,有的是看到有的群里边别人问的然后很多都是乱回答的。下边来看一下具体示例来验证一下
我们还是用我们的那个分类的示例语料

训练,构建词汇表以及idf值,这里同时生成训练集的VSM矩阵
# 导入TfidfVectorizer In [2]: from sklearn.feature_extraction.text import TfidfVectorizer # 实例化tf实例 In [3]: tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None) # 输入训练集矩阵,每行表示一个文本 In [4]: train = ["Chinese Beijing Chinese", ...: "Chinese Chinese Shanghai", ...: "Chinese Macao", ...: "Tokyo Japan Chinese"] ...: # 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式 In [6]: tv_fit = tv.fit_transform(train) # 查看一下构建的词汇表 In [10]: tv.get_feature_names() Out[10]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo'] # 查看输入文本列表的VSM矩阵 In [8]: tv_fit.toarray() Out[8]: array([[1.91629073, 2. , 0. , 0. , 0. , 0. ], [0. , 2. , 0. , 0. , 1.91629073, 0. ], [0. , 1. , 0. , 1.91629073, 0. , 0. ], [0. , 1. , 1.91629073, 0. , 0. , 1.91629073]])
手动计算一下第一篇文本的Beijing和Chinese两个词语的tf-idf值
# 词语beijing的在第1篇文本中的频次为.0,tf(beijing,d1)=1.0 # 词语beijing只在第1篇文本中出现过df(d,beijing)=1,nd=4, # 代入平滑版的tf-idf计算式得到1.9 In [13]: 1.0*(1+log((4+1)/(1+1))) Out[13]: 1.916290731874155 # 词语chinese的在第1篇文本中的频次为2.0,tf(chinese,d1)=2.0 # 词语chinese只在4篇文本中都出现过df(d,beijing)=4,nd=4, # 代入平滑版的tf-idf计算式得到2.0 In [14]: 2.0*(1+log(4/4)) Out[14]: 2.0
上边得到的矩阵就可以喂到后续的线性分类模型中进行训练了,注意要带每篇文本的类别标记呦。
下边看一下测试文本的表示
In [15]: test = ["Chinese Chinese Chinese Tokyo Japan"] In [16]: test_fit = tv.transform(test) In [19]: tv.get_feature_names() Out[19]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo'] In [18]: test_fit.toarray() Out[18]: array([[0. , 3. , 1.91629073, 0. , 0. , 1.91629073]])
手动计算一下Chinese和Japan这两个词项的tf-idf值
# chinese词项在测试文本中出现了3次,因此tf(chinese,t)=3 # 从训练集知道chinese在4篇文本中都出现,因此df(d,beijing)=4,nd=4 # 计算得到tf-idf值 In [22]: 3.0*(1+log((1+4)/(1+4))) Out[22]: 3.0 # japan词项在测试文本中出现了1次,因此tf(japan,t)=1 # 从训练集知道japan仅在第4篇文本中出现,因此df(d,japan)=1,nd=4 # 计算得到文本的tf-idf值 In [21]: 1.0*(1+log((1+4)/(1+1))) Out[21]: 1.916290731874155
到这里已经把sklearn的TfidfVectorizer说清楚了,这里其实我们应该想到,对于短文本来说,tfidf值中的tf部分大部分只能取0和1,数值区别的地方在于idf值,而对于同一个词项来说idf值不管在什么测试文本上都是一样的,它只是相当于给每个特征词赋予了一个权值,这个权值会减小那些常见词语,提高不太常见的词语。对于短文本来说tf值失去了频次意义,因此tf-idf值表示的VSM退化成one-hot表示+idf值。曾经看到有人问为啥SVM下效果不如朴素贝叶斯,因为朴素贝叶斯根本就牵扯文本的VSM表示,朴素贝叶斯计算的是P(word|Ci)即在某个类别下词语word出现的概率,当然这就比one-hot表示文本给予更多的信息,SVM利用向量空间的最优超平面来分类,如果不同类别文本之间本身就相距不远的化,这种超平面也就找不到,当然效果就不好,矛盾的地方就在于没有人能知道多于3维特征的实例在x维空间中是个什么样子,当然也就不知道效果到底好不好了。写到这里才意识到,似乎没有一本书一篇文章把从文本到SVM输入讲明白的,然后就在那儿一顿推公式。其实如果仅保留了各类目的核心关键词,对于一句短文本同时含有两种类目关键词时,SVM恐怕也是没辙的,最致命的缺陷其实不是模型,而是VSM的TF频次在短文本上失效,机器不能再通过频次来确定短文本的主题,这么说来,那么词嵌入技术也是无法表示文本主题的。
Tf-Idf详解及应用
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
为什么要用TF-IDF?因为计算机只能识别数字,对于一个一个的单词,计算机是看不懂的,更别说是一句话,或是一篇文章,而TF-IDF就是用来将文本转换成计算机看得懂的语言,或者说是机器学习或深度学习模型能够进行学习训练的数据集。
首先看一下一个文本经过TF-IDF转换后得到的是什么?(后文附代码)
arr=train_text_vector.toarray() # transform to array shape
![]()
shape of Tf-Idf matrix
这是在做一次文本分类项目时的结果,其中6100是样本个数,每一个样本是一句话(一个字符串),总样本数为9283个,这9283个样本包括了训练集和预测集,可以看作是一个总的语料库,经过9283个样本的训练(fit),将该训练器运用到6100个样本上,将其转换(transform)为对应的文本矩阵,即图中看到的6100x21864大小的矩阵,也就是说经过TF-IDF的转换,每一个样本可以被表示成1x21864的向量,这就是我们想要的结果(这里没有降维,可以去掉一些平凡词或者特殊词),它可以变成计算机看得懂的语言。
了解了TF-IDF是干什么的之后,接下来说说它的算法原理以及实现代码。其实TF-IDF的算法原理很简单。 TF是term frequency的缩写,指的是某一个给定的词语在该文件(注意这里的该文件与后面所有文本的区别)中出现的次数,这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。 而IDF逆向文件频率 (inverse document frequency, IDF)反应了一个词在所有文本(整个文档)中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如一些专业的名词如“Machine Learning”。这样的词IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。 如果单单以TF或者IDF来计算一个词的重要程度都是片面的,因此TF-IDF综合了TF和IDF两者的优点,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。上述引用总结就是,一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章,越能与其它文章区分开来。 TF-IDF的计算方法十分简单 TF的计算公式如下:
![]()
转存失败重新上传取消其中是在某一文本中词条w出现的次数,是该文本总词条数。
IDF的计算公式:
![]()
转存失败重新上传取消其中是语料库的文档总数,是包含词条的文档数,分母加一是为了避免未出现在任何文档中从而导致分母为的情况。 TF-IDF的就是将TF和IDF相乘 从以上计算公式便可以看出,某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
接下来看看代码实现,用一个简单的语料库(只有两个文本)来模拟 TfidfTransformer是把TF矩阵转成TF-IDF矩阵,所以需要先词频统计CountVectorizer,转换成TF-IDF矩阵
from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer # corpus 模拟语料库 corpus=["second third document", "second second document"] tfvectorizer=CountVectorizer() count_vector=tfvectorizer.fit_transform(corpus) # Tf 矩阵 transformer = TfidfTransformer() # 转换Tf矩阵 tfidf = transformer.fit_transform(count_vector) # 将TF转换成Tf-Idf arr=tfidf.toarray()
结果如下,那么这两个文件就可以分别用这两个向量来表示了

TF-IDF
以上是先计算了TF然后再转换成了TF-IDF,也有一步到位的方法
# TF-IDF一步到位 # 训练整个语料库 from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer(max_df=0.5,min_df=0.0003) # 可以不加参数,这里加参数是为了降维 # ============================================================================= # all_text_vector = tfidf.fit_transform(all_text) #when fit transform to vector # ============================================================================= tfidf.fit(corpus) # use vectorizer to fit the corpus corpus_vector=tfidf.transform(corpus).toarray() # print(corpus_vector)
整个项目源代码
import pandas as pd
from string import punctuation
import re
def cleandata(data):
clean=[]
# 英文标点符号+中文标点符号
punc = punctuation + u'.,;《》?!""''@#¥%…&×()——+【】{};;●,。&~、|\s::'
for line in data:
line = re.sub(r"[{}]+".format(punc)," ",line)
clean.append(line)
clean=pd.DataFrame(clean)
return clean
# clean predict data
predata=pd.read_csv('test.csv') #
pre_clean=[]
pre_clean=cleandata(predata['review'])
# clean train data
traindata=pd.read_csv('train.csv',lineterminator='\n') #
train_clean=[]
train_clean=cleandata(traindata['review'])
# 所有清洗后的文本
all_clean=train_clean.append(pre_clean)
all_text=all_clean.iloc[:,0] # 取第一列 否则报错 转成了series
m=6100
n=6328
train_text=train_clean[0:m].iloc[:,0]
test_text=train_clean[m:n].iloc[:,0]
# Tf-idf
# 训练整个语料库
# TF-IDF一步到位
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_df=0.5,min_df=0.0003)
# =============================================================================
# all_text_vector = tfidf.fit_transform(all_text) #fit的同时transform成vector
# =============================================================================
tfidf.fit(all_text) # 让tfidf去fit这些数据
all_text_vector=tfidf.transform(all_text).toarray()
train_text_vector=tfidf.transform(train_text)
test_text_vector=tfidf.transform(test_text)
train_label=traindata[0:m]['label']
test_label=traindata[m:n]['label']
# =============================================================================
# 先算TF 再算IDF
# count_v1=CountVectorizer(vocabulary=count_v0.vocabulary_);
# counts_train = count_v1.fit_transform(train_text);
#
# count_v2=CountVectorizer(vocabulary=count_v0.vocabulary_);
# counts_test = count_v2.fit_transform(test_text);
#
# tfidftransformer = TfidfTransformer();
# train_text_vector = tfidftransformer.fit(counts_train).transform(counts_train)
# test_text_vector = tfidftransformer.fit(counts_test).transform(counts_test)
# print(train_text_vector)
# =============================================================================
# classifcation methods
# bayes alpha=0.2 0.7
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB(alpha = 0.2)
# svm 0.64
# =============================================================================
# from sklearn.svm import SVC
# clf = SVC(kernel = 'linear')
# =============================================================================
# decition tree
# =============================================================================
# from sklearn.tree import DecisionTreeClassifier
# clf = DecisionTreeClassifier()
# =============================================================================
# logistic
# =============================================================================
# from sklearn.linear_model import LogisticRegression
# clf = LogisticRegression()
# =============================================================================
# MLP
# =============================================================================
# from sklearn.neural_network import MLPClassifier
# clf = MLPClassifier()
# =============================================================================
# output auc
clf = clf.fit(train_text_vector,train_label)
# =============================================================================
# preds = clf.predict(test_text_vector); #输出预测标签
# preds = preds.tolist()
# =============================================================================
# proba
proba=clf.predict_proba(test_text_vector)
from sklearn import metrics
auc=metrics.roc_auc_score(test_label,proba[:,1]) # 看测试集的auc如何
pre_text=pre_clean.iloc[:,0]
pre_text_vector=tfidf.transform(pre_text)
pre_proba=clf.predict_proba(pre_text_vector)
Sklearn中CountVectorizer,TfidfVectorizer详解
文本特征提取:将文本数据转化成特征向量的过程,比较常用的文本特征表示法为词袋法
词袋法:不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征,这些不重复的特征词汇集合为词表,每一个文本都可以在很长的词表上统计出一个很多列的特征向量, 如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量。 主要有两个api来实现 CountVectorizer 和 TfidfVectorizer
CountVectorizer:只考虑词汇在文本中出现的频率,属于词袋模型特征。
TfidfVectorizer: 除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量。能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征。属于Tfidf特征。
相比之下,文本条目越多,Tfid的效果会越显著
CountVectorize: CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
CountVectorizer参数详解
CountVectorizer(analyzer='word', binary=False, decode_error='strict', dtype=
一般要设置的参数是:ngram_range,max_df,min_df,max_features,analyzer,stop_words,token_pattern等,具体情况具体分析
ngram_range:例如ngram_range(min,max),是指将text分成min,min+1,min+2,.........max 个不同的词组。比如 '我 爱 中国' 中ngram_range(1,3)之后可得到'我' '爱' '中国' '我 爱' '爱 中国' 和'我 爱 中国',如果是ngram_range (1,1) 则只能得到单个单词'我' '爱'和'中国'。
max_df:可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效。 min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词。
max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集。
analyzer:一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型。
stop_words:设置停用词,设为english将使用内置的英语停用词,设为一个list可自定义停用词,设为None不使用停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表。
token_pattern:过滤规则,表示token的正则表达式,需要设置analyzer == ‘word’,默认的正则表达式选择2个及以上的字母或数字作为token,标点符号默认当作token分隔符,而不会被当作token。
decode_error:默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误,还可以设为replace,作用尚不明确。
binary:默认为False,一个关键词在一篇文档中可能出现n次,如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的。
其他参数详细参考:sklearn——CountVectorizer详解_九点澡堂子的博客-CSDN博客_countvectorizer
简单实例入门:
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['我 爱 中国 中国','爸爸 妈妈 爱 我','爸爸 妈妈 爱 中国']
# corpus = ['我爱中国','爸爸妈妈爱我','爸爸妈妈爱中国']
vectorizer = CountVectorizer(min_df=1, ngram_range=(1, 1)) ##创建词袋数据结构,里面相应参数设置
features = vectorizer.fit_transform(corpus) #拟合模型,并返回文本矩阵
print("CountVectorizer:")
print(vectorizer.get_feature_names()) #显示所有文本的词汇,列表类型
print(vectorizer.vocabulary_) #词汇表,字典类型
print(features) #文本矩阵
print(features.toarray()) #.toarray() 是将结果转化为稀疏矩阵
print(features.toarray().sum(axis=0)) #统计每个词在所有文档中的词频
CountVectorizer 结果依次为:
#词表
['中国', '妈妈', '爸爸']
#key:词,value:对应编号
{'中国': 0, '爸爸': 2, '妈妈': 1}
#第一行 (0, 0) 2 表示为:第0个列表元素,**词典中索引为0的元素**, 词频为2
(0, 0) 2
(1, 1) 1
(1, 2) 1
(2, 1) 1
(2, 2) 1
(2, 0) 1
#将结果转化为稀疏矩阵
[[2 0 0]
[0 1 1]
[1 1 1]]
#文本中的词频
[3 2 2]
TfidfVectorizer:
什么是TF-IDF
TF-IDF(term frequency-inverse document frequency)词频-逆向文件频率。在处理文本时,如何将文字转化为模型可以处理的向量呢?TF-IDF就是这个问题的解决方案之一。字词的重要性与其在文本中出现的频率成正比(TF),与其在语料库中出现的频率成反比(IDF)。
TF为某个词在文章中出现的总次数。为了消除不同文章大小之间的差异,便于不同文章之间的比较,我们在此标准化词频:TF = 某个词在文章中出现的总次数/文章的总词数。
IDF为逆文档频率。逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1)。
为了避免分母为0,所以在分母上加1。
TF-IDF值 = TF * IDF。
相关参数:
TfidfVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm='l2', preprocessor=None, smooth_idf=True,
stop_words=None, strip_accents=None, sublinear_tf=False,
token_pattern='(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=True,
vocabulary=None)
具体参数详解可以参考上面的CountVectorizer参数,大多数是一样的。具体详细参数详解参考:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
简单入门实例,可以和CountVectorizer结果对比一下:
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['我 爱 中国 中国','爸爸 妈妈 爱 我','爸爸 妈妈 爱 中国']
###### corpus = ['我爱中国','爸爸妈妈爱我','爸爸妈妈爱中国']
print("TfidfVectorizer:")
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=(1, 1))
features = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names()) #显示所有文本的词汇,列表类型
print(vectorizer.vocabulary_) #词汇表,字典类型
print(features) #文本矩阵,得到tf-idf矩阵,稀疏矩阵表示法
print(features.shape) #(3, 3)
print(features.toarray()) #.toarray() 是将结果转化为稀疏矩阵
print(features.toarray().sum(axis=0)) #统计每个词在所有文档中的词频
TfidfVectorizer 结果依次为:
TfidfVectorizer:
['中国', '妈妈', '爸爸']
{'中国': 0, '爸爸': 2, '妈妈': 1}
(0, 0) 1.0 #得到tf-idf矩阵,稀疏矩阵表示法
(1, 2) 0.7071067811865476
(1, 1) 0.7071067811865476
(2, 0) 0.5773502691896257
(2, 2) 0.5773502691896257
(2, 1) 0.5773502691896257
(3, 3)
[[1. 0. 0. ]
[0. 0.70710678 0.70710678]
[0.57735027 0.57735027 0.57735027]]
[1.57735027 1.28445705 1.28445705]
可以看到:"我" “爱”这两个单字是没有的,主要是参数token_pattern默认正则匹配字数是大于2的,如果想保留需重新设置一下,参考链接中第三步:https://blog.csdn.net/blmoistawinde/article/details/80816179
Sklearn-GridSearchCV网格搜索
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。
回到sklearn里面的GridSearchCV,GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
GridSearchCV的sklearn官方网址:sklearn.model_selection.GridSearchCV — scikit-learn 1.0.2 documentation
classsklearn.model_selection.GridSearchCV(estimator,param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True,cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise',return_train_score=True)
常用参数解读
estimator:所使用的分类器,如estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features='sqrt',random_state=10), 并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法。
param_grid:值为字典或者列表,即需要最优化的参数的取值,param_grid =param_test1,param_test1 = {'n_estimators':range(10,71,10)}。
scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
进行预测的常用方法和属性
grid.fit():运行网格搜索
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评分
网格搜索实例
param_test1 ={'n_estimators':range(10,71,10)}
gsearch1= GridSearchCV(estimator =RandomForestClassifier(min_samples_split=100,
min_samples_leaf=20,max_depth= 8,max_features='sqrt',random_state=10),
param_grid =param_test1,scoring='roc_auc',cv=5)
gsearch1.fit(X,y)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
输出结果如下:
([mean: 0.80681, std:0.02236, params: {'n_estimators': 10},
mean: 0.81600, std: 0.03275, params:{'n_estimators': 20},
mean: 0.81818, std: 0.03136, params:{'n_estimators': 30},
mean: 0.81838, std: 0.03118, params:{'n_estimators': 40},
mean: 0.82034, std: 0.03001, params:{'n_estimators': 50},
mean: 0.82113, std: 0.02966, params:{'n_estimators': 60},
mean: 0.81992, std: 0.02836, params:{'n_estimators': 70}],
{'n_estimators': 60},
0.8211334476626017)
如果有transform,使用Pipeline简化系统搭建流程,将transform与分类器串联起来(Pipelineof transforms with a final estimator)
pipeline= Pipeline([("features", combined_features), ("svm", svm)])
param_grid= dict(features__pca__n_components=[1, 2, 3],
features__univ_select__k=[1,2],
svm__C=[0.1, 1, 10])
grid_search= GridSearchCV(pipeline, param_grid=param_grid, verbose=10)
grid_search.fit(X,y)
print(grid_search.best_estimator_)
sklearn-pipeline机器学习实例
一、问题描述
这个实例原型是《Hands On Machine Learning with Sklearn and Tensorflow》书第二章End-to-End Machine Learning Project的课后题,题目的解答和正文掺杂在一起,我做了一些整理,也有一些补充(所以不敢保证没有纰漏)。仅供需要的同学批判性地参考,顺便给自己当一个笔记。 :)
数据集是来自 https://github.com/ageron/handson-ml 下的master/datasets/housing,简而言之,就是根据房子的一些属性来预测房子的价格。数据文件中一共有10个字段,具体地,特征
X={'longitude','latitude','housing_median_age','total_rooms', 'total_bedrooms','population','households','median_income','ocean_proximity'},
其中'ocean_proximity'为文本类型,表示房子靠海的程度,只有5种情况——{'NEAR BAY', '<1H OCEAN', 'INLAND', 'NEAR OCEAN', 'ISLAND'}。
标签
Y={'median_house_value'},
为连续型数据,因此此为一个多元回归问题。该问题的示意图略图如下:
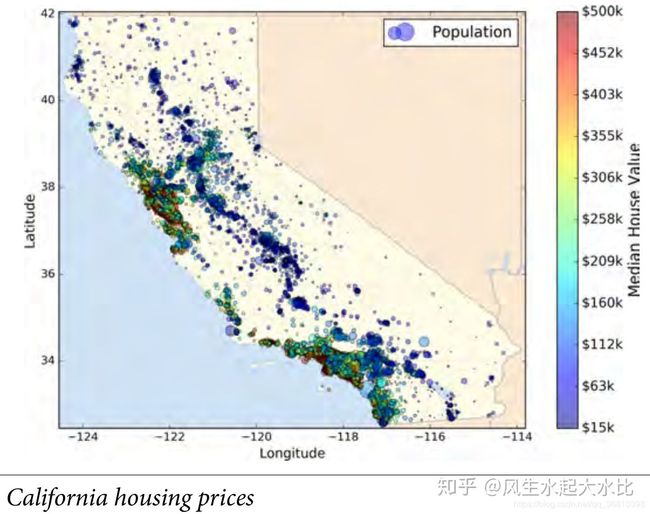
二、Pipeline处理流程示意图

上图中间即为该end-to-end机器学习模型的流程图(pipeline),其中两侧的6个框中的即为pipeline的组件,亦即本模型的操作。需要说明的有以下几点:
(1)本数据中“分类型数据”不含异常值,因为异常值处理没有组件;
(2)其中Imputer和StandardScaler为python自带的类,其他的类是需要自己编写;
(3)其中LabelBinary类,直接用会报错,原因见于 https://stackoverflow.com/questions/46162855/fit-transform-takes-2-positional-arguments-but-3-were-given-with-labelbinarize ,
修改方法是自己在此类的基础上做一下修改,得到新类MyLabelBinary(见代码中)。
【更详细的内容,请参考原书或下述代码】
三、实例代码
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import numpy as np
import time
#### 读入数据,划分训练集和测试集
data=pd.read_csv('../handsOn/datasets/housing/housing.csv')
housing = data.drop("median_house_value", axis=1)
housing_labels = data["median_house_value"].copy()
L=int(0.8*len(housing))
train_x=housing.ix[0:L,:]
train_y=housing_labels.ix[0:L]
test_x=housing.ix[L:,:]
test_y=housing_labels.ix[L:]
cat_attribute=['ocean_proximity']
housing_num=housing.drop(cat_attribute,axis=1)
num_attribute=list(housing_num)
start=time.clock()
#### 构建 pipeline
from sklearn.preprocessing import Imputer,StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator,TransformerMixin
from sklearn.pipeline import FeatureUnion
from sklearn.preprocessing import LabelBinarizer
##构建新特征需要的类
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
class CombinedAttributeAdder(BaseEstimator,TransformerMixin):
def __init__(self,add_bedrooms_per_room=True):
self.add_bedrooms_per_room=add_bedrooms_per_room
def fit(self, X, y=None):
return(self)
def transform(self,X):
'''X is an array'''
rooms_per_household=X[:,rooms_ix]/X[:,household_ix]
population_per_household=X[:,population_ix]/X[:,household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room=X[:,bedrooms_ix]/X[:,rooms_ix]
return(np.c_[X,rooms_per_household,population_per_household,bedrooms_per_room])
else:
return(np.c_[X,rooms_per_household,population_per_household])
##根据列名选取出该列的类
class DataFrameSelector(BaseEstimator,TransformerMixin):
def __init__(self,attribute_names):
self.attribute_names=attribute_names
def fit(self, X, y=None):
return(self)
def transform(self,X):
'''X is a DataFrame'''
return(X[self.attribute_names].values)
##对分类属性进行onhehot编码
class MyLabelBinarizer(BaseEstimator,TransformerMixin):
def __init__(self):
self.encoder = LabelBinarizer()
def fit(self, x, y=0):
self.encoder.fit(x)
return self
def transform(self, x, y=0):
return self.encoder.transform(x)
##构造数值型特征处理的pipeline
num_pipeline=Pipeline([
('selector',DataFrameSelector(num_attribute)),
('imputer',Imputer(strategy='median')),
('attribute_adder',CombinedAttributeAdder()),
('std_scaler',StandardScaler())
])
##构造分类型特征处理的pipeline
cat_pipeline=Pipeline([
('selector',DataFrameSelector(cat_attribute)),
('label_binarizer',MyLabelBinarizer())
])
##将上述pipeline用FeatureUnion组合,将两组特征组合起来
full_pipeline=FeatureUnion(transformer_list=[
('num_pipeline',num_pipeline),
('cat_pipeline',cat_pipeline)
])
##特征选择类:用随机森林计算特征的重要程度,返回最高的K个特征
class TopFeaturesSelector(BaseEstimator,TransformerMixin):
def __init__(self,feature_importance_k=5):
self.top_k_attributes=None
self.k=feature_importance_k
def fit(self,X,y):
reg=RandomForestRegressor()
reg.fit(X,y)
feature_importance=reg.feature_importances_
top_k_attributes=np.argsort(-feature_importance)[0:self.k]
self.top_k_attributes=top_k_attributes
return(self)
def transform(self, X,**fit_params):
return(X[:,self.top_k_attributes])
##数据预处理以及选取最重要的K个特征的pipeline
prepare_and_top_feature_pipeline=Pipeline([
('full_pipeline',full_pipeline),
('feature_selector',TopFeaturesSelector(feature_importance_k=5))
])
##用GridSearchCV计算最随机森林最优的参数
train_x_=full_pipeline.fit_transform(train_x)
# Tree model,select best parameter with GridSearchCV
param_grid={
'n_estimators':[10,50],
'max_depth':[8,10]
}
reg=RandomForestRegressor()
grid_search=GridSearchCV(reg,param_grid=param_grid,cv=5)
grid_search.fit(train_x_,train_y)
##构造最终的数据处理和预测pipeline
prepare_and_predict_pipeline=Pipeline([
('prepare',prepare_and_top_feature_pipeline),
('random_forest',RandomForestRegressor(**grid_search.best_params_))
])
#### 对上述总的pipeline用GridSearchCV选取最好的pipeline参数
param_grid2={'prepare__feature_selector__feature_importance_k':[1,3,5,10],
'prepare__full_pipeline__num_pipeline__imputer__strategy': ['mean', 'median', 'most_frequent']}
grid_search2=GridSearchCV(prepare_and_predict_pipeline,param_grid=param_grid2,cv=2,
scoring='neg_mean_squared_error', verbose=2, n_jobs=4)
grid_search2.fit(train_x,train_y)
pred=grid_search2.predict(test_x)
end=time.clock()
print('RMSE on test set={}'.format(np.sqrt(mean_squared_error(test_y,pred))))
print('cost time={}'.format(end-start))
print('grid_search2.best_params_=\n',grid_search2.best_params_)
上述程序的的输出结果在准确率上并不高,因为为了提高速度,GridSearchCV都是用了最简单的参数,可以扩大参数范围,提高精度。
sklearn-pipeline用法实例——房价预测 - 知乎