论文阅读:Dialogue Response Selection with Hierarchical Curriculum Learning(ACL2021)

Abstract
作者在研究对话反应选择匹配模型的时候,发现使用随机负样本训练的模型再实际应用场景中并不理想,所以作者提出了一个分层课程学习框架,从易到难训练匹配模型。
学习框架包括两个互补课程:语料级的课程CC和实例级的课程IC。在CC中,模型在对话上下文和回答之间搜索匹配线索的能力逐渐增强,在IC中,它也能逐步增强模型识别对话上下文和回答候选之间匹配到错误信息的能力。
实验中,作者使用三个最先进的匹配模型在三个基准数据上实验,证明了所提出的学习框架能够显著提高模型在各个指标上的性能。
Introduction
构建智能对话,一个重要的挑战是回答的选择问题,也就是从一组候选回答中选择与上下文语义最符合的回答。(这是基于检索的对话,而不是对话生成)
之前有人提出了不同的匹配模型来衡量对话上下文和回答候选之间的匹配程度。但是这些工作只是用简答的启发式构造的数据来训练模型。
在不同上下文中,人的回答被认为是正例。而其他来自对话文本的回答被认为是负例。在实际中,负样本往往是随机抽样得到的,训练的目标是保证正样本的得分高于负样本。
最近,一些研究人员提出说,随机抽样的负样本往往与上下文完全无关。用这些数据可能不能使模型真正学会处理真实场景中的跟那个高难度的干扰。也就是说,这样的负样本太简单了,模型不容易学到对话需要的本质的东西。

表1 举例说明A和B之间的对话上下文,P1和P2是容易和困难的正例;N1和N2是易(负)和难(负)。
在这篇文章中,作者使用课程学习概念,即设计一个合适的学习方案,使模型在该学习方案下由易到难训练。
Penha and Hauff(2020)采用了CL的思想来处理响应选择任务。但是,他们只将课程学习应用于正样本的选择,而忽略了负样本的多样性。
简而言之,作者的贡献可以概括为:
(1)提出了一个分层的课程学习框架来解决对话回答选择的任务;
(2)在三个基准数据集上的实验结果表明,这个方法可以显著提高匹配模型的性能。
Conclusion
在这项工作中,提出了一个新的层次课程学习框架来训练多回合会话回答选择模型。在训练过程中,该框架同时采用语料库级和实例级课程,根据学习过程的状态动态选择合适的训练数据。在两个基准数据集上的大量实验和分析表明,这个方法可以显著提高匹配模型在各个评价指标上的性能。代码、模型和其他相关资源可以在github上找到。GitHub - yxuansu/HCL: Dialogue Response Selection with Hierarchical Curriculum Learning (ACL 2021)
Background
这里的背景介绍更像是任务定义。
给定数据集![]() ,其中,r指的是正样本,c是对话,学习模型s(),的目的是在一群负样本R-中成功的找到正样本r。目标函数可以定义为:
,其中,r指的是正样本,c是对话,学习模型s(),的目的是在一群负样本R-中成功的找到正样本r。目标函数可以定义为:

m是与对话的上下文相关的负样本的个数。在大多数工作中,都采用随机从数据集中选择的方式得到负样本R-。最近有人提出新的想法,在测试中,对于每一个正负样本对,采用一个分数s(c,r),来反应匹配程度,这样一来就可以根据匹配的分数对候选集进行排序。
Methodology
Overview
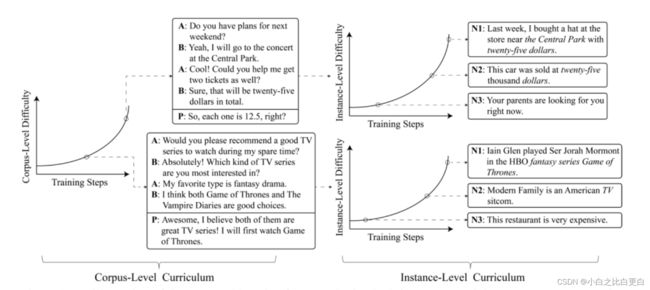
图1 学习框架:在左侧,呈现了两组不同难度的训练情境(上面的比下面的更难,并且表示积极的反应)。对于每个训练实例,我们显示了三个相关的负面反应(N1、N2和N3),难度从下到上依次递增。在否定句中,同时出现在对话上下文中的单词都标为斜体。
模型分为两个补充课程,左边是语料级右边是实例级,在语料级的训练里面,逐级增加难度,逐渐提高模型在候选相应重选出包含匹配线索的能力。对于实例级训练来说,它可以控制对话上下文和负样本的匹配难度,也就是负样本干扰的程度。从比较容易的否定开始,逐渐增强模型识别不匹配信息的能力。
Corpus-Level Curriculum
数据集![]() ,简单的正样本在语义和词汇上有明显的重叠,而困难样本则需要推理来识别。
,简单的正样本在语义和词汇上有明显的重叠,而困难样本则需要推理来识别。
为了衡量每一个训练数据![]() 的难度,需要计算相关性得分。
的难度,需要计算相关性得分。![]() 的得分越高,相关性越高。语料库级难度定义为:
的得分越高,相关性越高。语料库级难度定义为:
![]()
得分会被归一化到[0.0, 1.0]。相关性越高则得分越低,较低的得分说明这个模型更容易学习到匹配关系。
训练过程中,除了衡量匹配的难度以外还要知道什么时候应该增加难度。也就是训练过程中学习难度怎么调整。也就是说在时刻t时,给定一个pcc(t)值,表示训练的数据的难度,训练只能使用难度得分小于这个数值的样本。作者将pcc(t)定义为:
![]()
pcc(0)是初值,训练开始时,采用最简单的数据样本进行训练,逐渐增大pcc值,直到pcc=1时,说明模型可以任意使用任何样本,训练课程完成。

Instance-Level Curriculum
实例课程控制候选集的难度。对于一个样本对,它的负样本可以是训练集中任意一个样本,但是不同的负样本对于模型来说的难度是不一样的。作者发现,较低难度的候选集总是很容易找到,但是困难样本则很难找到,模型需要去识别它们之间更细粒度的语义不一致性。
在课程级训练中,主要目的是根据学习状态选择难度适当的候选集。在开始时,从整个数据集中随机选择负样本,这些负样本大多很容易区分。随着训练的进行,模型从较高难度的候选集中采样,即从训练数据中的较难子集采样,逐渐增加候选集的难度。
同样,也需要使用一个得分dci来衡量困难程度。得分就是相关度得分里面降序排序之后的排列等级。
![]()
排名越小说明候选集和对话上下文相关性越高,模型越难区分出来。
至于难度的调整,这里也给出了一个公式:
![]()
从易到难的候选集的学习速度由一个实例级的函数pic(t)控制。给定一个实例,负样本的排序等级rj要小于![]() ,也就是说负样本
,也就是说负样本![]() 的集合里面采样。这个数值越小,说明越难。式子中,k0表示训练开始时,从整个训练集中采样。
的集合里面采样。这个数值越小,说明越难。式子中,k0表示训练开始时,从整个训练集中采样。时间步长T由课程级训练决定。
Hierarchical Curriculum Learning
训练伪代码:

对于排序,作者构建了一个双编码结构的离线匹配模型。可以离线计算所有上下文和回答并存在缓存里,任何对话和回答对的相关性可以定义为:![]() 。(矩阵计算)
。(矩阵计算)
Experiment Setups
三个数据集:Douban Dataset. 、 Ubuntu Dataset. 、E-Commerce Dataset.
评价指标:平均精度MAP、平均MRR、P@1、R10@1、R10@2、R10@5... Rn@k表示k个候选里面第n个的召回率。
MRR(Mean reciprocal rank)是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
基准模型
单轮对话匹配模型: RNN、CNN、LSTM、biLSTM、MV-LSTM、Match-LSTM。这些模型将所有对话上下文当成一个长句子输入,然后匹配与候选集的得分。
多轮对话匹配模型:DL2R、Multi-View、DUA、DAM、MRFN、IOI、SMN、MSN。这些模型不是将对话上下文作为一个单一的话语来处理,而是以更复杂的方式从不同的话语中聚合信息。
基于Bert的匹配模型:SA-BERT
实现细节具体看论文吧
实验结果


主要结果
表2显示了豆瓣、Ubuntu和电子商务数据集上的结果,其中X+HCL表示使用建议的学习HCL训练模型X。我们可以看到,HCL显著提高了所有三个匹配模型在所有评估指标方面的性能,表明了我们方法的鲁棒性和普遍性。我们还观察到,通过HCL训练,一个不使用预训练语言模型的模型(MSN)甚至可以超越豆瓣数据集上使用预训练语言模型(SA-BERT)的先进模型。这些结果表明,虽然培训策略在以前的研究中没有得到充分的探索,但它对于建立一个合格的反应选择模型可能是非常决定性的。
CC和IC的有效性
在豆瓣数据集上通过去除CC或IC来训练不同的模型。实验结果如表3所示,我们可以看到CC和IC单独使用时对整体性能都有积极的贡献。仅使用IC比仅使用CC有更大的改进,这表明识别错误匹配信息的能力是模型实现最优性能的更重要因素。但当CC和IC结合使用时,性能最佳,说明CC和IC是互补的。
后面是跟其他模型的对比和细节分析。