循证护理教育中的移动辅助同伴评估方法
摘要:
学习循证护理的学生可以帮助医疗保健团队做出适当的医疗决策,并为患者提供有价值的建议,从而优化特定情况下的患者护理质量。在临床工作中,护理人员通过搜索相关的经验性护理文献来参与决策,这是进入临床实践所需的基本能力。在传统的教学中,向护理学生学习问题、干预、比较和结果的方法,学习使用图书馆资源,收集经验护理知识进行决策。然而,对大多数学生来说,要有足够的实践来正确地做出决策,并有机会从不同的角度来看待医疗案例,这是一个挑战。因此,我们提出了一种基于同伴评估的问题、干预、比较和结果的方法,以帮助护理学生找到正确的证据,并对病人护理做出适当的决定。我们在一个护理大学的培训项目中用我们的方法进行了一个实验。实验结果表明,采用传统方法学习的被试比采用传统方法学习的被试具有更好的循证护理知识、学习态度和批判性思维能力。
关键词:
批判性思维、循证护理、信息技术、移动的学习、同伴评估、技术
循证护理培训:
循证护理知识在护理临床环境中的护理中非常重要。21研究人员已经进行了相关研究,利用计算机技术提高护生搜索证据的能力。经验护理架构图显示了根据称为皮科的四个部分对临床问题的澄清:分别为问题/人群、干预、比较和结果。皮科模型可以帮助护生找到更合适的答案来解决临床问题。它还可以帮助根据具体的患者问题定义临床问题,并帮助护理人员通过循证医学实践的五个步骤在文献中找到相关的临床证据:提出一个问题,找到与问题相关的证据,评估证据,将证据与自己的临床知识结合起来,并考虑患者的状况,评估所发现证据的有效性和效率。
同行评估:
本文提出了一种半自动建模领域本体的方法(称为认知本体)。从现有的数据库、概念网、自由库和文字网络等知识来源中系统地提取了本体的概念和它们之间的关系。通过使用概念之间的层次关系,对单一和多个结构分类进行建模。概念之间的关联性是通过概念之间的属性来建模的。所提出的本体构建方法采用自上而下和自下而上的知识构建方法进行领域建模。该本体的主要层次结构是通过英语单词WordNet的词汇组织来构建的。
WordNet中的属性仅是用于定义同步集结构的结构属性。这些属性并不提供概念之间的关系/意义。WordNet中的动词用于定义概念之间的属性。对称、反义词和传递属性类型通过使用同义词和动词的超动关系仔细插入,例如,“吃”和“吃”是对称属性。类似地,针对填充本体的每个概念插入个体。由于学前教育水平的学习内容主要是图形表示,图像从图像网中检索,代表一个概念和图像中的相关概念。
建模的功能分类:
目前的工作扩展了基本概念来支持复杂实体的建模。这些实体被命名为抽象概念(功能信息分类)。在学前课程中,功能分类概念的一些例子是食肉动物、食草动物、野生动物和驯养动物。食肉动物的概念可以有鸟类、爬行动物或哺乳动物,但它们都有一个共同的功能特征,即它们以肉为食。用于表示功能分类的形式主义是语义web规则语言(SWRL)。SWRL是本体web语言(OWL)的扩展,与描述语言(DL)相结合,支持类、子类关系、等价类、不相交和对称关系以及个体和数据属性。
分类样本的制定:
推理引擎是专家系统的一个组件,它利用逻辑规则、概念和属性来推断新的知识,即本例中的分类范例。推理执行规则,并在知识库上执行称为推理的冲突解决方案。目前的工作使用前向推理(数据驱动推理)方法来创建分类范例。推理引擎利用了建模的规则和概念之间的关系,如继承、逆、传递、对称、不同、所有不同和不相交。
实验与结果:
为评价该方法的有效性,我们将该方法对儿童的分类技能学习与传统的工作表和教科书教学方法进行了比较。
参与者:
采用准实验的前测试和后测试设计方法进行评价。采用随机抽样的方法,从当地幼儿园抽取79名儿童(3-6岁,男女)。儿童是从遵循统一课程的学校中挑选出来的,即牛津大学出版社。在实验期间,通过选择学校不同班级的儿童,以避免他们之间的知识共享,形成完整的对照组和实验组。对照组和实验组分别为34名和45名儿童。对照组的儿童通过课堂教学、工作表和教科书继续他们的日常学习练习。教师主要遵循教科书,但他们也定期提供根据正在进行的教科书内容计划的印刷工作表。实验小组除了进行日常学习实践外,还使用了安装在所提供的平板电脑上的移动应用程序。该实验是在学年年中对所有儿童进行。实验持续了22天。
测试前和测试后都是由一位资深儿童心理学家设计的,他是一名医生和研究人员。这些测试与Kimura等人实验的类别集非常一致。前测试和后测试根据分类级别分为两部分,即结构分类和功能分类。该测试前和后测试的每个结构和功能部分包含五个样本。每个范例都包含属于单一类别并具有相似的感知属性的结构项。
译:Both pre-test and post-test were designed by a senior psychologist,he is a teacher and researcher.These tests are similar to experiments.Pre-test and post-test are divided into two parts according to classification level:namely, structure classification and function classification. Each structural and functional part of the pre-test and post-test contains five samples. Each example contains structure items that belong to a single category and have similar perceptual properties.
表1测试前和测试后的情况。测试前和测试后的设计.
| 分门别类 | 前测 | 克朗巴赫的阿尔法分数 | 后测 | 克朗巴赫的阿尔法分数 |
| 结构 | 生物 | 0.7 | 非生物 | 0.62 |
| 物品 | 物品 | |||
| 鸟 | 鱼 | |||
| 固定的 | 运动的 | |||
| 项目 | 设备 | |||
| 水果 | 蔬菜 | |||
| 占领 | 载运工具 | |||
| 功能 | 食草动物 | 0.6 | 杂食动物 | 0.69 |
| 鞋类 | 头饰 | |||
| 野生的 | 水 | |||
| 动物 | 车辆 | |||
| 来源 | 牛奶 | |||
| 牛奶 | 产品 | |||
| 浮动 | 法律 | |||
| 对象 | 占用 |
采用成人评分方法对前后测试进行了验证。心理学、计算机科学和教育领域的35名研究生和本科生参与了对范例、每个范例相关项目和选择的评估。评估是为了评估学龄前儿童测试前、后内容的接受程度和适宜性。每个评估者使用李克特5分量表对所有样本进行评分。评估人员被要求进行评分.
在“基于结构和功能信息”的分类方面,这个范例有多合适。所有评价者的克伦巴赫alpha得分如下:测试前结构分类(p¼0.70)、测试前功能分类(p¼0.60)、测试后结构分类(p¼0.62)和测试后功能分类(p¼0.69)。采用alpha >.60的可接受值进行分析。所有测试对象都用清晰的图片表示,并用适当的文本标记。这些项目和类别的图片表示由两名可用性专家进行了验证,特别是手机游戏设计专家。
克朗巴哈系数(Cronbach's alpha或Cronbach's α)是一个统计量,是指量表所有可能的项目划分方法的得到的折半信度系数的平均值,是最常用的信度测量方法。
结果:
表2显示了测试前分数的描述性结果。可以对测试前的分数进行评估参与者在应用治疗(使用动态分类样本)之前,具有同等和基本的知识,即分类能力。对照组和实验组的结构分类的总体平均得分均高于功能分类。年龄较大的孩子比年龄较小的孩子表现得更好,因为年龄较小的孩子大多是学习记忆(计数、字母表、颜色识别等)和电机(图纸、着色等)技能,而不是分类和其他认知教学大纲。然而,前测设计得很好,即使是年龄较小的孩子也在结构和功能分类方面都有得分。所有参与者在年龄方面的得分成绩都呈线性模式。目前,本研究只考虑了参与者在分类能力方面的集体改善,但可以进行深入的研究来验证年龄和分类能力之间的关系。
| 分组 | 年龄 | 数量 | 平均结构 | 平均功能 | 平均得分之和(%) |
| 控制组 | 3 | 7 | 3.15 | 2.65 | 5.8 |
| 4 | 9 | 3.61 | 3.26 | 6.87 | |
| 5 | 12 | 4.5 | 4.94 | 9.44 | |
| 6 | 17 | 4.71 | 4.66 | 9.37 | |
| 实验组 | 3 | 4 | 3.13 | 2.68 | 5.8 |
| 4 | 7 | 3.65 | 3.16 | 6.81 | |
| 5 | 10 | 4.65 | 5.07 | 9.72 | |
| 6 | 13 | 4.27 | 4.45 | 8.72 |
表2的结果显示,两组儿童得分相似,即对照组平均得分为7.87(1.584 std div),实验组平均得分为7.76。
表三:各组前测得分的t检验结果。
| 分组 | 数量 | 平均数 | SD | 平均差 | t |
| 控制组 | 45 | 7.836 | 0.597 | 0.089 | 0.568 |
| 实验组 | 34 | 7.760 | 0.576 |
结果表明,对照组45人)与实验组34人的受试者测试前得分无显著性差异。这些结果表明,两组儿童在治疗前均具有相同水平的分类能力。

对照组和实验组的测试后得分的描述性分析见表4。两组中所有儿童的测试后分数都有所增加。此外,在功能分类方面,实验组的得分相对高于对照组。甚至在实验组中,更年轻的儿童的功能分类水平也表现出了显著的增加。在实验组的测试后分数中可见一种聚集模式,即年龄较小的儿童而年龄较大的儿童(5岁和6岁)的得分相同。两组总体平均值的差异为实验组使用动态范例应用的对照组比遵循传统教学方法的对照组提高了分类技能。
| 分组 | 年龄 | 数量 | 平均结构 | 平均功能 | 平均得分之和(%) |
| 控制组 | 3 | 7 | 3.93 | 3.47 | 7.4 |
| 4 | 9 | 4.56 | 4.76 | 9.32 | |
| 5 | 12 | 5.63 | 6.43 | 12.05 | |
| 6 | 17 | 6.06 | 6.72 | 12.78 | |
| 实验组 | 3 | 4 | 5.13 | 4.64 | 9.77 |
| 4 | 7 | 5.07 | 6.33 | 11.4 | |
| 5 | 10 | 7.10 | 7.50 | 14.6 | |
| 6 | 13 | 7.77 | 7.64 | 15.41 |
表5:各组学生后测得分的t检验结果。
| 分组 | 数量 | 平均数 | SD | 平均差 | t |
| 控制组 | 45 | 10.422 | 1.660 | 0.247 | -7.043 |
| 实验组 | 34 | 12.83 | 1.232 |
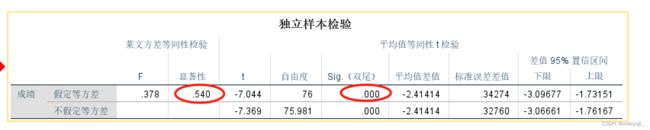
对两组学生所获得的后测得分的t检验的分析见表5。可以看出,动态范例学习方法存在显著效应,这表明由于基于知识的学习模型,儿童的测试后得分存在显著差异。因此,结果显示,在类游戏方法中经历动态创建分类范例的儿童在提高分类能力方面优于使用传统教学学习方法的儿童。
结论:
目前的工作提出了一种基于知识的方法来建模现实世界对象的结构和功能分类知识。所建模的知识用于分类范例的动态创建。它是通过使用移动应用程序的实验证明的,暴露于不同和多个分类范例提供了增强的分类能力的学习。与使用书籍和工作表进行传统教学的孩子相比,从建模知识中体验到动态创建的分类范例的孩子获得了更高的分数。这种增强的分类学习的原因是,所提出的技术遵循了建设性的教学法,从而补救了传统教学教学法的局限性。按照以学生为中心的建设性教学法,学生们暴露在一个学习环境中,允许他们构建新的知识,他们的行为提供了对他们对这些概念的理解的评估。
问题:
实验组三岁的孩子才4个,是否样本量过少,缺乏准确性?