目标检测之anchor free
目标检测之anchor free 2022.2
- CornerNet
- CenterNet
- ExtremeNet
- FCOS
- FoveaBox
- RepPoints
- ATSS
- LSNet

禁止任何形式的转载!!!
CornerNet
2018ECCV《CornerNet: Detecting Objects as Paired Keypoints》
CornerNet采取了类似检测关键点的方法,通过检测左上点和右下点来框出物体的位置。

网络结构如下:Hourglass Network是关键点检测中常用的网络,左上点和右下点分别进行预测


-
corner pooling module
对于一个物体的左上点,其右下区域包含了物体的特征信息,同样对于物体的右下点,其左上区域包含了物体的特征信息,这时角点的周围只有四分之一的区域包含了物体信息,其他区域都是背景,因此传统的池化方法就显然不适用了。以左上角为例,左上角需要的物体信息其实是在右下角,所以在进行pooling的时候,更应该关注将该点的右下角信息。下图是top-left corner pooling:

-
Heatmaps
这里预测的是每个物体的角点位置,值越高越可能是物体的左上/右下点。如果GT的角点只对应到Heatmap上一个点,由于人为主观标记的因素,这个点有可能不是最好的点,所以以GT这个点周围的一个范围会进行惩罚衰减(设置了一个半径为R的区域,也就是图中圆圈部分,物体越大R越大)。即预测到的虽然不是GT,但在这个圈里面基本就不会产生loss。惩罚衰减是按照2D Gaussian来分布的。(有点类似与Focal Loss)

-
Offsets
这里主要是对角点坐标在进一步的修正。因为网络下采样的时候,损失了小数部分,所以在Heatmaps中的位置并不能很好的映射回去,需要再偏移调整一下。 -
Embeddings
上面到多组角点的位置,如何将其两两对应?因此Embeddings 分支负责将左上角点的分支与右下角点的分支进行匹配,找到属于同一个物体的角点。属于同一个物体的角点,他们的Embeddings 应该相似。

训练Loss:从训练loss大概就能知道他们的编码方式


预测后处理:这里用最大池化取代了 NMS 操作
- heatmaps经过sigmoid平滑处理之后做了一个类 似NMS 操作,即用 3x3 的maxpool(stride=1, pad=1) 寻找亮点,heatmaps 中只保留亮点位置处的值(其他置0);
- 分别选择top100个heatmaps亮点作为目标顶点候选点,这样的话存在 100x100 种组合
根据候选点位置解码左上角和右下角顶点位置; - 匹配两类顶点,类别不同的排除,Embedding 差距大于阈值(0.5, 训练时要保证大于1) 的排除,左上角和右下角位置不符合空间位置关系的排除;
- 最后只保留 top1000 对顶点组合作为检测目标;
缺点:同类别不同目标的角点容易错误地组合起来形成误检框。

CenterNet
2019CVPR 《Objects as Points》主要讲这一篇
but,这里还有一篇《CenterNet: Keypoint Triplets for Object Detection》
“虽然根本上都是受到cornetnet的启发,但是一篇是corner-centernet,一篇是真centernet。centernet那篇最牛逼的(我认为的)就是在于不需要voting,也不需要nms。直接predict centers,然后(再)predict长宽。简单到可以直接用到3d detection上(虽然没有概念效果有多好)论文也是写的真的简单清晰直观明了,吹爆!(另外一篇瞄了一眼,主要是觉得跟我这么喜欢的paper居然抢了一个名字。。。所以我就没怎么看,所以我就不评价了。。。。)” — 知乎评价
CenterNet算CornerNet 的拓展版,其核心思想预测中心点和宽高。这样比预测角点更方便,省去了匹配的Embeddings。

整个网络结构也是比较简洁:backbone可以切换,这里Hourglass的效果最好
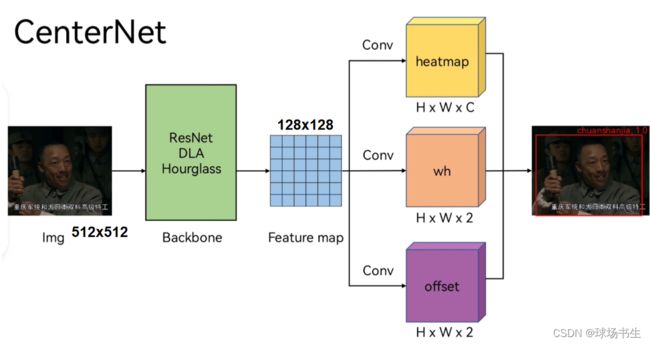
- heatmaps:与CornerNet一样,将 GT 通过高斯核将目标以 GT 中心点为中心辐射;
- offset:与CornerNet类似,因为下采样取整导致的精回归误差(回归目标=实际中心坐标 - 取整后中心点坐标),不过这里是中心的位置偏移;
- wh:物体的宽高
推理预测:
- hm 经过 sigmoid 平滑处理,之后做一个类似NMS操作,即用 3x3 的 maxpool(stride=1, pad=1) 寻找亮点,hm 中只保留亮点位置处的值(其他置0)
- 选择 top100 个 hm 亮点作为目标候选点
- 根据候选点位置解码出目标包围框:
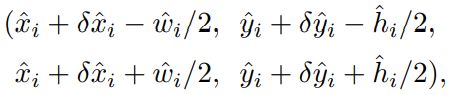
ExtremeNet
2019CVPR《Bottom-up Object Detection by Grouping Extreme and Center Points》
作者认为:绝大多数的目标都不是常规的矩形,如果我们强制用矩形表示目标,那么会包括除了目标本身外很多的背景像素,这些像素并不是我们需要的。此外,这种方法需要列举大量候选框可能存在的位置,而不是真正对图像的语义信息进行理解,这种方法的计算成本是非常庞大的。而且bounding box是远远不能和目标本身划等号的,在形状,姿态等方面有很大的差距。

ExtremeNet利用沙漏网络为每个类别的五个关键点(四个极值点和一个中心点)进行检测:

由于中心点是通过四个极值点的几何计算得到的,所以对于中心点并不进行偏移预测。因此,整个网络的输出:heatmaps(热点图) 5xC维,其中C为要分类的数目;4x2 偏移图(4个极值点,2个方向偏移值)。在损失函数设计和偏移预测上,遵循和CornerNet相同的策略。
预测的点如何进行匹配呢?极值点分组Center grouping (作者未使用向量嵌入方法将角点进行分组,认为这可能缺少足够的全局视图信息。个人觉得maybe)

首先通过检测峰值(peaks)将所有(大于阈值)关键点提取出来。枚举四个极值点热图的峰值的组合,并计算了组合边界框的几何中心,当且仅当其几何中心在中心热图中具有高响应时,才会生成边界框(返回一个最终得分,得分的计算方式是五个点得分的平均值)。
- ghost box suppression:Center grouping算法可能会出现这样的情况:处理三个共线且尺度相同的目标时,是产生三个正确的小框还是一个错误的大框呢?这种假阳性的检测结果称为ghost box。解决办法:使用一种soft NMS来抑制ghost box:如果某个边框中包含的所有小框的分数之和超过其本身得分的3倍,则将其得分除以2。
- Edge aggregation:

极值点并非总是唯一的,如图一个汽车的极值点可能是水平或竖直的线段,文中极值点的响应是对边缘多个点的弱响应而不是一个点的强响应。这有可能使得弱响应可能会低于阈值被忽略。解决办法:对于每个局部最大值的极点,我们在垂直方向或水平方向汇总其得分。然后对所有单调递减的分数进行聚合,并在聚合方向上的局部最小值处停止聚合。经过边缘聚合处理后,大大增强了中间像素的响应值。

FCOS
2019ICCV《FCOS: Fully Convolutional One-Stage Object Detection》
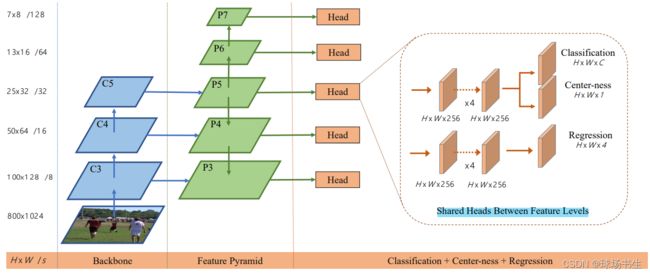
沿用FPN的思想,整体看下来并没有特别多的新颖的地方。分层的好处是不同的层可以预测不同大小的物体,因为物体中心重合的时候大多数都是尺度差异较大的物体相重合,比如一个人拿着球拍:能解决目标像素点重叠的问题

重叠的像素我们称为ambiguous,以图中空心橙色圈为例(ambiguous),选择最小的GT框,取出离小框边最长的距离d,如果d大于mi或小于mi-1就在第Pi层归为负样本,反之为正样本。即不同的层预测不同尺寸的物体。

- Centerness
论文一开始并没有加入centerness分支,发现检测效果并没有那么好。后来认为是大量低质量预测框导致的,低质量预测框指的是一个真实物体框内离物体中心点较远的点,预测效果较差。centerness的设计就是为了抑制低质量框,降低它的分数,实现离中心点远时它的值小,近时它的值大。

加Sqrt是为了减缓center-ness的衰减速度。

在将分类分数乘以 centerness 分数后,低质量框(在 y = x 线下)被推到图的左侧。这表明这些框的分数大大降低了。

FoveaBox
2019CVPR《FoveaBox: Beyond Anchor-based Object Detector》
其思想跟FCOS很相似,都是在RetinaNet的基础上,在不同stage输出的特征图上得到目标类别并回归出目标的位置。

由于目标尺寸变换范围较大,FoveaBox同样采用了不同的level预测不同尺寸的目标的方法(在FCOS中,使用多level预测的目的是为了解决anchor free的时候,目标重叠的问题),因为重叠就没有办法分配正负样本了,这样可以有效减少目标重合。
有所不同的是:分层的大小是可以通过η参数学习的,因为η是动态的,给出的范围是一个动态区间,一个物体的尺寸可能同时满足不同层的覆盖区域,也就会在不同的特征图上进行检测。这与传统FPN只在一个特征图上进行检测有所不同。

FoveaBox的class 子网络计算的是每个输出位置分别存在不同类别目标的置信度,box子网络则是直接计算每个输出位置的与类别无关的目标包围框(左上和右下顶点坐标)。
-
Object Fovea:与FCOS的Centerness不同,在Fovea中并不是ground-truth对应的区域均是正样本。如上图所示,狗虽然很大,但是真正的正样本,是中间红色区域部分,这里作者引入了个σ1参数,可以动态设置正样本范围。对于负样本,也设置了一个缩放因子σ2 ,用于生成负样本区域。如果一个cell没有被分配,那么就是ignore区域不参与反向传播。由于仍然存在正负样本不均的情况,所以作者在训练分类的时候仍然采用了Focal Loss。
-
Box Prediction:FoveaBox不是直接去学习中点与边框之间的距离,而是去学习一个预测坐标与真实坐标的映射关系,假如真实框为[x1,y1,x2,y2] ,我们目标就是学习一个映射关系 [tx1,ty2,tx2,ty2] ,这个关系是中心点cell [x,y]与边框坐标的关系,如下:

接着使用简单的L1损失来进行优化,其中为z是归一化因子,将输出空间映射到中心为1的空间,使得训练稳定。最后使用log空间函数进行正则化。 -
Inference:首先使用阈值0.05,过滤掉不靠谱的点,然后在剩下的点中选取得分排名前1000的点作为候选点,再然后,使用非极大值抑制,对1000个点进行过滤,最后留下top100个点作为最终的结果。
“其实看了这么多anchor-free的论文,应该心里都有个数,在这个阶段大家都是在不断提出各种head预测方法(各种keypoint的组合),而不是在刷点。每种方法最大的差别就是如何预测以及如何设置正负样本。 那段时间真的很多公司都在招实习生做这个,早期的时候大家很容易想出不同的范式,后面要想新的就没那么容易了,况且审稿人品味也会变高。”
RepPoints
2019ICCV《RepPoints: Point Set Representation for Object Detection》
CNN卷积神经网络之DCN

中心思想:利用3x3可变形卷积得到的9个点来进行定位。DCN是MSRA的传统艺能了
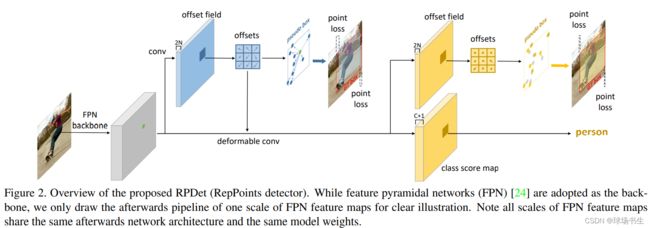
性能最优的目标检测器通常遵循一个 multi-stage 的识别范式,其中目标定位是逐步细化的。作者对定位进行了refine,他自称是1.5 stage。RepPoints使用了两次回归和一次分类,并且分类和最后一次回归使用的不是普通卷积,而是可形变卷积。
采用特征金字塔网络(FPN)作为主干,但为了清晰说明,只绘制了一种规模的 FPN 特征图的后续pipeline, FPN 特征图的所有尺度都共享相同的网络架构和相同的模型权重。
RepPoints其实是对可形变卷积进一步的改进,相比可形变卷积有两个优点:
- 通过定位和分类的直接监督来学习可形变卷积的偏移量,使得偏移量具有可解释性。
- 可以通过采样点来直接生成伪框 (pseudo box),不需要另外学习边界框,并且分类和定位有联系。
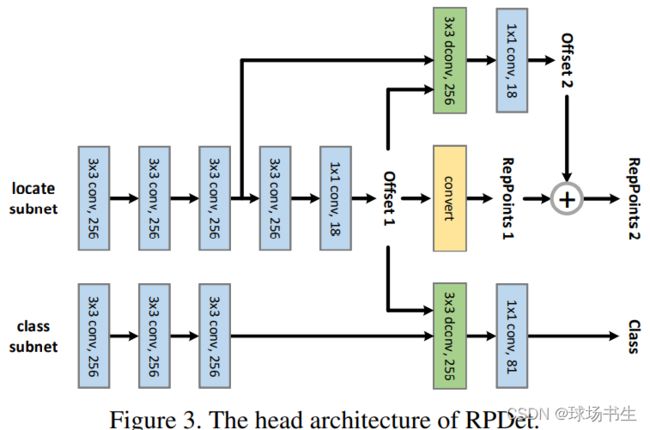
第一组RepPoints通过回归中心点的偏移值获得。第二组RepPoints代表最终的目标位置,由第一组RepPoints优化调整得到。RepPoints的学习主要由两个目标驱动:
- 伪预测框pseudo box和GT box的左上角点和右上角点的距离损失
- 后续的目标分类损失
第一组RepPoints由距离损失和分类损失引导,第二组RepPoints仅使用距离损失进行引导,主要为了学习到更精准的目标定位。
不同的阶段的正样本定义不同:
- 对于第一阶段,gt的大小满足对应pyramid level,且gt的中心点落在对应的location时,该location是正例。
- 第二阶段:伪框与gt iou大于0.5的points为正例(当前的anchor-based方法有点类似,将第一阶段的输出当作anchor)。分类,大于0.5的是正例,小于0.4是负例。
- 9个点如何形成一个框?作者做了实验:
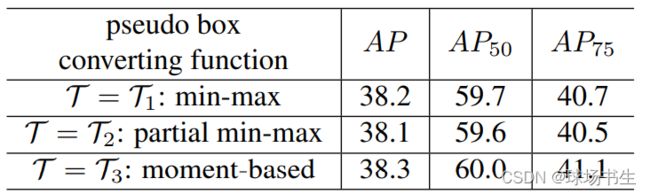
1、Min-max function:在所有点中找最小和最大值,获得包括所有点的外接框。
2、Partial min-max function:采样部分点,进行上述操作。
3、Moment-based function:用所有点的均值和方差计算box的中心点和scale,scale需要乘全局共享的可学习乘子λx和λy。
三种方法可以插入到网络中,但效果差异较小。
ATSS
2020CVPR oral《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》
正如我前面提到的(那时我还没看过ATSS,oh我这敏锐的观察力,没赶上anchor free的风口),之前anchorfree每种方法最大的差别就是如何预测以及如何设置正负样本,作者开始思考anchor free和anchor based的性能差异的原因究竟是定义正负训练样本,还是如何预测回归或anchor的数量?
本文提出了自适应训练样本的选择方法(Adaptive Training Sample Selection, ATSS ),下面直接给出结论:
- 说明anchor-free和anchor-based检测器之间的本质区别是如何定义正负训练样本;
- 说明在图像上每个位置平铺多个anchor来检测目标是无用的操作。
接下来就是实验证明:
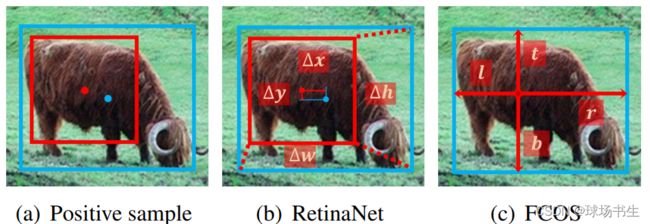
- 以RetinaNet和FCOS作例,anchor-free和anchor-based两者存在三点主要差别:
1)每个位置平铺的anchor数量:RetinaNet在每个位置平铺多个anchor,而FCOS在每个位置平铺一个anchor point;
2)正负样本的定义方式:RetinaNet借助IoU区分正负样本,而FCOS利用空间和幅度限制选择正负样本;
3)回归起始状态:RetinaNet从anchor box回归边界框,而FCOS由anchor point定位边界框。
作者通过实验分别考察这三点,最终发现(2)是问题核心所在,(1)和(3)无关痛痒。

FCOS的性能提升可能来自以下几点:添加GN、使用GIoU回归损失函数、限制gt box的正样本数量、在回归分支加入中心性信息、为每个层级特征金字塔添加可训练标量。其实这些tricks也可以用在anchor-based中,为了更公平的分析,作者给RetinaNet (Anchor=1)加入上述tricks后AP提升到37.0%。
可见剩下只有0.8%的差异可能来自于(1)定义正样本和负样本的方法;(2)预测锚框还是点?
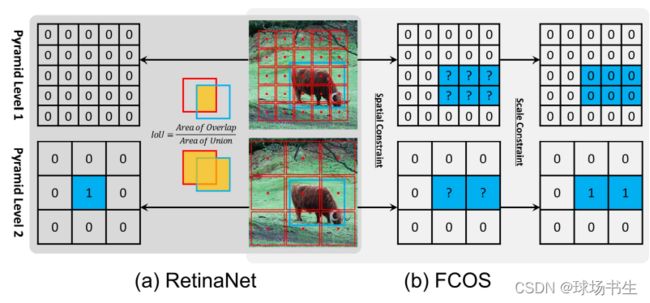
- 定义正样本和负样本的方法:RetinaNet借助IoU将anchor boxes划分为正、负样本。FCOS利用空间和幅度限制选择正负样本;gt内部的点都作为候选正样本点,然后根据为每个金字塔层级定义的幅度范围确定最终的正样本点,未被选择的点均是负样本点。
- 预测锚框还是点:RetinaNe回归anchor box与object box之间的四个偏移量,而FCOS回归anchor point到object box四条边之间的距离。
交叉进行实验,结果表明,正样本和负样本的定义是anchor-based和anchor-free检测器的本质区别。

Adaptive Training Sample Selection(ATSS):基于上述分析,如何更好地定义正负样本,对于目标检测的提升有着重要的意义,之前的FCOS、RetinaNet等都是属于hard型的定义方法,本文提出了自适应选择正负样本的方法。
算法流程:
- 在每一个特征图上按照L2距离找到离ground-truth中心最近的k个候选正样本集,若总共有L个特征图,则候选正样本集有k*L个;
- 计算ground-truth和候选正样本集的均值方差,得到tg=mg+vg,从而为每个gt设置一个IoU阀值;
- 选择IoU大于或等于阈值tg的候选样本作为最终正样本。值得注意的是,我们还将正样本的中心限制在ground-truth框中,此外如果将一个anchor分配给多个ground-truth box,则将选择IoU最高的那一个进行分配,其余为负样本。

均值是一个相对稳定的量,高的均值意味着高质量的候选框。标准差判定某层级是否适合与当前目标的检测。这样就不需要设置一个固定范围来将GT划分到某一层。以(a)为例,如果均值都高说明这个物体比较好检测,但是我们不应该用所有的层都来检测,要选择最适合的层所以用均值+方差来过滤。以(b)为例,当均值都低,比如小物体,所有层都不那么容易检测,但我们仍然要选择最适合的层,通过过滤可以判断是更低层适合小目标检测。
有人做过实验:

关于超参数k 的选择:k在7-17之间是鲁棒的。k太小时选样本点太少,统计特性不稳定,k太大时选样本点太多,包含太多低质量的候选样本。
LSNet
2021CVPR Location-Sensitive Visual Recognition with Cross-IOU Loss

目标检测,实例分割和姿态估计本质上都是识别物体,只是表征物体的形式有所不同,目标检测用bbox,实例分割用mask,姿态估计用keypoint。既然都是识别物体,作者就准备使用一套方案来完成三个任务。
但是那么多点,怎么计算损失呢,作者还是想使用IOU但是进行了改进,有了Cross-IOU Loss:

建议参考知乎:https://zhuanlan.zhihu.com/p/366651996这里讲得很清楚,个人觉得这种统一并不是很实用。但是还是有一些启发:
- 以后在标注新的目标检测数据集时,建议标注四个极值点,而非直接画框框住物体。标极值点比直接画框平均快4倍,而且极值点本身包含有物体的语义信息。
- Cross-IOU Loss
- Pyramid DCN:DCN不仅只在目标所在的FPN层计算,还会把DCN的offsets等比例映射至相邻的FPN层进行计算,将三层的所得特征相加,形成最终的landmarks特征。利用这些特征再预测一组向量,两组向量叠加最终形成预测向量。

禁止任何形式的转载!!!