根因定位论文:Root Cause Analysis of Anomalies of Multitier Services in Public Clouds
转载原链接:https://jckling.github.io/2021/01/23/Other/Root%20Cause%20Analysis%20of%20Anomalies%20of%20Multitier%20Services%20in%20Public%20Clouds/
Root Cause Analysis of Anomalies of Multitier Services in Public Clouds
-
- 简介
- 相关工作
- 异常传播类型和系统架构
- 系统架构
-
- Step 1
- Step 2
- 异常传播图(Anomaly Propagation Graph, APG)
-
- 多层服务请求跟踪
- 构造 VCG
- 构造 APG
- 根本原因定位
-
- 度量数据收集
- 相似度计算
- 随机游走算法
- 实验评估
-
- 实验环境
- 性能评估
- 虚拟机级别的根本原因分析
-
- 多种原因引起异常的根本原因分析
- 诊断时间分析
- 方法讨论
- 进程级别的根本原因分析
从云供应商的角度,快速定位导致云平台上多层业务异常的根本原因,解决方案应该对租户的服务或应用程序是无侵入的(非侵入式)。
简介
多层服务或云应用涉及上百个组件,而这些组件又分布在不同的主机上。IaaS 云允许租户共享物理计算基础设施,可能影响性能。
公有云上租户的多层服务出现异常,可能是租户自身服务组件的问题,也可能是被其他租户的服务影响。
多层服务组件之间的依赖关系非常复杂,入侵式修改租户的服务组件代码不可行。
考虑错误传播距离、错误传播概率,解决方案包含 2 个部分
- 数据收集:对租户是非侵入性的,用以捕获多层服务组件的依赖关系并收集必要的服务度量数据
- 根本原因定位:找出可能引发异常的根本原因列表,以及每个可能的根本原因对应的概率
- 相似性评分的指标:基于服务的指标数据和底层基础设施的资源利用率进行计算
- 随机游走算法:模拟多层服务中异常传播的影响
在真实世界的小规模云平台上实现并部署了该系统,使用三层 Web 应用程序和 Storm 应用程序进行了实验,证明了解决方案可以在虚拟机级别和进程级别定位异常根源。
对多种原因引起的异常进行了模拟实验,同时说明了在定位算法中采用相似度评分和随机漫步传播两步的合理性和必要性。实验结果表明,在不同场景下,定位异常的平均精度比现有方法提高了 15% ~ 71% 。
相关工作
Pivot Tracing、伪异常聚类算法…… 云环境下应用程序的性能异常诊断。
当异常沿着服务调用的路径在系统组件之间传播时,对多层服务的请求跟踪对于分析异常的根本原因是必要的。
请求跟踪
- 利用特定于应用程序的知识或明确声明不同组件事件之间的因果关系,其缺点是用户必须获取和修改目标应用程序或中间件的源代码,而且不能用于黑箱服务;
- vPath ,可以在虚拟机外进行请求跟踪,但是 vPath 是在基于 XEN 的虚拟化环境中设计的,无法移植到基于 KVM 的虚拟化环境中;
- 在不了解源代码的情况下,通过内核检测或虚拟机内部的流量监控来推断因果路径
- 请求跟踪由 PreciseTracer 产生的因果路径图推断
社交网络中的谣言源检测旨在从网络中找出异常现象的根源,社交网络中的边缘连接具有确定性,时间是其谣言传播模型中的一个重要维度。
在云环境中,虚拟机之间的边缘连接很难确定,因此本文的异常传播模型不把时间作为一个维度,因为异常传播几乎是实时的。异常是否从一个节点传播到另一个节点受到其他因素的影响,例如它们之间是否存在严重的资源争夺。
异常传播类型和系统架构
异常传播类型
- 外部因素:虚拟机之间的资源争夺,异常可能从其他租户的虚拟机传播到该服务的一个虚拟机
- 内部因素:软件 bug,异常可能沿着服务调用的路径在多层服务的组件之间传播
进行实验来证明这些因素是如何影响服务性能
实验环境:5 台物理主机构成的云环境,租户 A 申请 5 台虚拟机,租户 B 申请 3 台虚拟机,一些虚拟机分配在同一个物理主机(资源竞争),两个租户都运行三层 Web 应用程序 RUBiS 。
- RUBiS 是一个为学术研究而开发的电子商务基准,可以根据研究人员设置的参数自动创建用户(10w)和商品(10w),初始化模拟一个在线购物网站;RUBiS 还提供了一个可模拟发送请求的用户行为的客户端,能够收集用户请求响应时间的统计结果。
- 租户 A 的 LVS 虚拟机根据用户请求的内容,将请求定向到两个 Apache 虚拟机中的一个(vm2和vm4),即vm1实现了基于任务的负载平衡
- 负载平衡策略:使用 SearchItemsByRegion 函数和 ViewUserInfo 函数(R1表示)的请求由 vm2服务,使用 SearchItemsByCategory 函数和 ViewItem 函数的请求(R2表示)由vm4服务
- 2 条调用路径
- P1:vm1->vm2->vm3
- P2:vm1->vm4->vm5
- 租户 B 只有 1 条调用路径P:vm6->vm7->vm8

使用 CPU 负载生成器来提高vm8的 CPU 负载,同时记录租户 A 的服务请求响应时间,R1的平均请求响应时间基本保持不变,R2的平均响应时间随着vm8的负载越来越重而递增。 - vm5和vm8共享物理主机的 CPU 资源
- 2 种异常传播类型:vm8->vm5、vm5->vm4->vm1
结论:在公有云中,存在两种异常传播路径:1)由于资源竞争而共存的虚拟机之间的异常传播路径;2)服务调用路径上的多层服务组件之间的异常传播路径。
命题1:云提供商有必要提供服务,帮助租户确定异常的根本原因。
系统架构
数据收集子系统:在多层服务提供服务时一直运行
- 在线请求跟踪
- 度量数据收集
根本原因定位子系统:在租户提交异常时被激活,返回一个排序的根本原因列表
- 构建异常传播图(VCG)
- 构建虚拟机通信图(APG)
- 相似性计算
- 随机游走算法

租户发现服务请求r的响应时间很长,提交给云提供商异常 a
- 找出所有可能导致异常a的原因,并构建异常传播图(Anomaly Propagation Graph, APG) G a A P G G_a^{APG} GaAPG。
- 确定 G a A P G G_a^{APG} GaAPG中每个元素作为异常a的根本原因的概率,并找出最可能的根本原因。
Step 1
跟踪在线请求,收集和保存数据。根据收集的数据可以构建请求r的虚拟机通信图(VM Communication Graph, VCG),其中每条边反映了两台虚拟机之间的服务调用关系。
考虑由于资源竞争而导致的虚拟机之间的异常传播,异常传播图包含两种边,并置依赖边(collocation dependency)和服务调用边(service call)。
Step 2
寻找 APG 中最可能的根本原因,这里的问题是如何评估一个节点是根本原因的可能性。
定义度量标准:相似性。计算多层服务中各组件的服务时间并监控各虚拟机的资源使用情况,在度量数据收集模块中完成。
利用这些度量数据计算 APG 中每个虚拟机的相似性,然后再通过随机游走算法,结合虚拟机传播异常的概率,最终确定可能导致异常a的根本原因。
异常传播图(Anomaly Propagation Graph, APG)
v m i → v m j vm_i \rightarrow vm_j vmi→vmj 表示 v m i vm_i vmi 依赖 v m j vm_j vmj:事实上,这些依赖边是异常传播的反向方向
- 服务调用边: v m i vm_i vmi 在处理请求时调用 v m j vm_j vmj
- 并置依赖边: v m i vm_i vmi和 v m j vm_j vmj位于同一个物理服务器中,而且 v m i vm_i vmi 是多层服务的一个服务组件
云提供商很容易检索共享物理机的虚拟机信息。例如,在 OpenStack 中,云提供商可以通过 nova 项目中实现的 api 获得物理机中的虚拟机分配情况。
一个请求会触发一系列的服务调用,服务调用边将形成一个有向无环图,这里称之为虚拟机通信图(VM Communication Graph, VCG),在图的拓扑结构上,VCG 实际上是对应 APG 的子图。
云提供商无法直接获得租户服务的调用关系信息。他们必须收集和分析数据来推断这些服务调用依赖的边缘。考虑到租户的隐私问题和多层服务的复杂性,云提供商应该在不入侵多层服务的情况下,基于请求跟踪技术构建 VCG 。
多层服务请求跟踪
在多层服务中,一个请求在操作系统内核或共享库中触发一系列的交互活动,PreciseTracer 使用 Systemtap 捕获这些活动。
当为单个请求提供服务时,一系列具有因果关系或之前发生的关系的活动构成了因果路径图,PreciseTracer 提供了因果路径图,这是一个有向无环图,其中顶点是组件的活动,边表示两个活动之间的因果关系。
- 有四种类型的活动:BEGIN、END、SEND、RECEIVE
- SEND 和 RECEIVE 活动是发送和接收消息的活动
- BEGIN 活动标志着服务新请求的开始,END 活动标志着服务请求的结束
PreciseTracer 记录一个发送消息的活动为 S i , j i S^i_{i,j} Si,ji,表示进程i向进程j发送消息,记录一个接收消息的活动为 R j i , j R_j^{i,j} Rji,j,表示进程j 从进程i接收一条消息。下图包含简单的活动序列 { R c , 1 1 , S 1 , 2 1 , R 1 , 2 2 , S 2 , 3 2 , R 2 , 3 3 , S 3 , x 3 } \{R^1_{c,1},S^1_{1,2},R^2_{1,2},S^2_{2,3},R^3_{2,3},S^3_{3,x}\} {Rc,11,S1,21,R1,22,S2,32,R2,33,S3,x3},根据这个图可以计算每个组件(虚拟机)在服务单个请求时的服务时间。对于下图中的请求,机器 B 的服务时间是 t ( S 2 , 3 2 ) − t ( R 1 , 2 2 ) t(S^2_{2,3})-t(R^2_{1,2}) t(S2,32)−t(R1,22),其中 t ( ⋅ ) t(·) t(⋅)为对应活动的时间戳,此外,定义 h ( ⋅ ) h(·) h(⋅)作为运行相应活动的虚拟机的主机名。

构造 VCG
下图给出了由 PreciseTracer 在图 1 中所示场景中生成的因果路径图示例, v m i vm_i vmi中的服务 1 调用了两次 v m 4 vm_4 vm4 中的服务 2
- 第一次调用:请求 S 1 , 2 1 S^1_{1,2} S1,21、 R 1 , 2 2 R^2_{1,2} R1,22;响应 S 2 , 1 2 S^2_{2,1} S2,12、 R 2 , 1 1 R^1_{2,1} R2,11
- 第二次调用:请求 S 1 , 2 1 ’ S^{1’}_{1,2} S1,21’、 R 1 , 2 2 ’ R^{2’}_{1,2} R1,22’;响应 S 2 , 1 2 ’ S^{2’}_{2,1} S2,12’、 R 2 , 1 1 ’ R^{1’}_{2,1} R2,11’
服务 2 调用 v m 5 vm_5 vm5中的服务 3 两次,然后再返回给服务 1


不关心服务之间通信的细节,将因果图转换为虚拟机级别的服务调用边,即 VCG 。
- 根据每个活动的主机名,将因果路径图中的活动划分为不同的集合,活动集合 § v \text{\S}{v} §v 包含所有与 v m v vm_v vmv相关的活动
- 对于每个虚拟机 v m v vm_v vmv,按照时间戳对 § v \text{\S}{v} §v 中的活动进行排序
- 对于每个虚拟机 v m v vm_v vmv,尝试在区分服务调用的请求者和响应者的基础上确定其相关边的方向
- 对于 SEND 活动,找到对应的 RECEIVE 活动
- 找不到满足 h ( S j , i j ) = h ( R j , i j ) h(S^j_{j,i})=h(R^j_{j,i}) h(Sj,ij)=h(Rj,ij) 和 t ( S j , i j ) < t ( R i , j j ) t(S^j_{j,i})
构造 APG
使用 nova api 获得并置边,根据 VCG 获得服务调用边。以图 1 所示的场景为例,租户 A 的用户发起的 ViewItem 请求将通过路径 2 传播,对应的 APG 如下图所示。

根本原因定位
在本文中,异常是指多层服务请求的响应时间超过了用户能够容忍的时间。定义 Φ a ( i ) \Phi_a(i) Φa(i)为虚拟机 v m i vm_i vmi 是导致异常 a的根本原因的概率, v m r o o t vm_{root} vmroot表示导致异常的根本原因的虚拟机。
定义 R ( r ) \mathbb{R}(r) R(r) 为一个请求的集合,这些请求构成了与r相同的因果路径图;定义 S ( v m i , R ( r ) ) \mathbb{S}(vm_i,\mathbb{R}(r)) S(vmi,R(r))为 v m i vm_i vmi度量数据与 R ( r ) \mathbb{R}(r) R(r) 的请求响应时间之间的相似性,相似性可以在一定程度上推导出其为根本原因的概率。
竞争资源可能导致响应时间增加,但不一定是异常的根本原因。以图 1 所示的场景为例,只有当 S ( v m 1 , R 2 ) \mathbb{S}(vm_1,R_2) S(vm1,R2)和 S ( v m 6 , R 2 ) \mathbb{S}(vm_6,R_2) S(vm6,R2)都很高时,租户 A 的异常才可能是由 v m 6 vm_6 vm6引起。使用随机游走算法来反映异常传播的可能性。
命题2:作为根本原因的虚拟机必须满足两个条件:1)虚拟机的度量数据必须与请求的响应时间 R ( r ) \mathbb{R}(r) R(r)高度相似;2)虚拟机通过 APG 传播异常的可能性必须很高。
度量数据收集
- 服务时间:虚拟机 v m i vm_i vmi对请求 r的服务时间表示为 η i = ∑ x ( t ( S i , x i ) − t ( R x , i i ) ) − ∑ y ( t ( R y , i i ) − t ( S i , y i ) ) \eta_i = \sum_{x}(t(S^i_{i,x})-t(R^i_{x,i})) - \sum_{y}(t(R^i_{y,i})-t(S^i_{i,y})) ηi=∑x(t(Si,xi)−t(Rx,ii))−∑y(t(Ry,ii)−t(Si,yi)) ,x表示向虚拟机 v m i vm_i vmi发起请求的虚拟机,y表示接收虚拟机 v m i vm_i vmi 请求的虚拟机;左式表示虚拟机 v m i vm_i vmi处理所有请求的时间和,包括等待响应时间,因此减去右式的等待间隔。
- 资源消耗:使用 Ganglia 分布式监控系统收集资源利用率,默认收集物理机的度量数据,使用插件 sFlow 收集虚拟机的度量数据,包括 CPU 和内存消耗、I/O 和网络吞吐量。
相似度计算
度量数据和响应时间在一定程度上可以用于衡量虚拟机是导致异常的根本原因的概率。
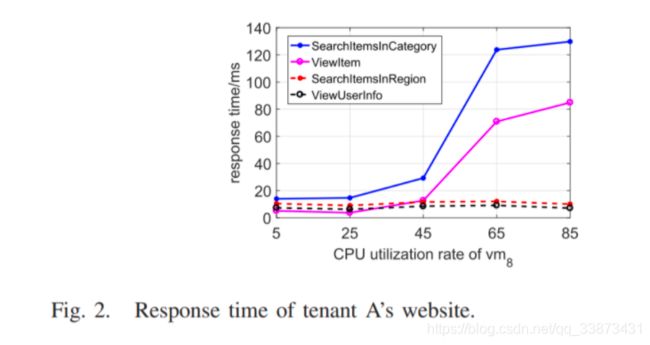
仍然以图 1 所示的场景为例,增加 v m 8 vm_8 vm8的 CPU 利用率,同时发送 SearchItemsByCategory 请求。下图显示了通过路径 2 处理请求的响应时间、 v m 5 vm_5 vm5的服务时间、 v m 1 vm_1 vm1的服务时间和 v m 8 vm_8 vm8的 CPU 利用率的变化趋势,其中三条曲线和 v m 5 vm_5 vm5的服务时间都有较强的相关性( t e t_e te和 t s t_s ts之间)。
如图 2 所示,当 v m 8 vm_8 vm8的 CPU 利用率小于某个阈值时,响应时间不会随着 当 v m 8 vm_8 vm8的 CPU 利用率的增加而增加。

如果 v m i vm_i vmi是多层服务的一个组件,根据其服务时间 η i \eta_i ηi计算相似度;对于共享物理主机的虚拟机,首先计算请求的响应时间与不同类型的资源竞争(如 CPU 和内存、I/O 和网络吞吐量)之间的相关性,然后选择这些相关性的最大值来表示其相似性。
定义 t ( r ) t(r) t(r) 表示发起请求 r r r 的时间戳, τ ( r ) \tau(r) τ(r) 表示其响应时间。根据 t s t_s ts 到 t e t_e te 时间段计算的皮尔逊相关性系数,定义函数计算 v m i vm_i vmi 度量值 M M M 与请求 R ( r ) \mathbb{R}(r) R(r) 响应时间的相关性
ℜ ( i , M , R ( r ) , t s , t e ) = C o v ( M t s t e ( M , i ) , T t s t e ( R ( r ) ) ) σ M t s t e ( M , i ) σ T t s t e ( R ( r ) ) \Re(i,M,\mathbb{R}(r),t_s,t_e) = \frac{Cov(\mathbb{M}^{t_e}_{t_s}(M,i),\mathbb{T}^{t_e}_{t_s}(\mathbb{R}(r)))}{\sigma_{\mathbb{M}^{t_e}_{t_s}(M,i)}\sigma_{\mathbb{T}^{t_e}_{t_s}(\mathbb{R}(r))}} ℜ(i,M,R(r),ts,te)=σMtste(M,i)σTtste(R(r))Cov(Mtste(M,i),Ttste(R(r)))
- M t s t e ( M , i ) \mathbb{M}^{t_e}_{t_s}(M,i) Mtste(M,i) 表示虚拟机 v m i vm_i vmi 的度量数据
- T t s t e ( R ( r ) ) \mathbb{T}^{t_e}_{t_s}(\mathbb{R}(r)) Ttste(R(r)) 表示相关请求的响应时间
相似度 S ( v m i , R ( r ) ) \mathbb{S}(vm_i,\mathbb{R}(r)) S(vmi,R(r))
S ( v m i , R ( r ) ) = { ℜ ( i , M , R ( r ) , t s , t e ) , if v m i ∈ V C G max { ℜ ( i , M , R ( r ) , t s , t e ) ∣ v ∈ Υ } , otherwise \mathbb{S}(vm_i,\mathbb{R}(r))=\left\{ \begin{array}{rcl} \Re(i,M,\mathbb{R}(r),t_s,t_e), & \text{if}\ vm_i\in{VCG}\\ \max{\{\Re(i,M,\mathbb{R}(r),t_s,t_e)|v\in\Upsilon}\}, & \text{otherwise}\\ \end{array} \right. S(vmi,R(r))={ℜ(i,M,R(r),ts,te),max{ℜ(i,M,R(r),ts,te)∣v∈Υ},if vmi∈VCGotherwise
Υ \Upsilon Υ 表示竞争的资源类型,例如 CPU、内存、I/O、网络
-
在 v m i vm_i vmi 处理请求 R ( r ) \mathbb{R}(r) R(r) 时,收集 v m i vm_i vmi 的服务时间 η i \eta_i ηi 的历史数据
给定一个因果路径图,根据拓扑排序算法,求得活动序列 § \text{\S} §,然后使用活动 A A A 的属性元组(活动类型,程序名)来表示 § \text{\S} § 中的活动 A A A 。以图 5 为例,可以得到因果路径图序列为 { ( B , P 1 ) , ( S , P 1 ) , ( R , P 2 ) , ( S , P 2 ) , ( R , P 1 ) , ( S , P 1 ) , ( R , P 2 ) , ( S , P 2 ) , ( R , P 3 ) , ( S , P 3 ) , ( R , P 2 ) , ( S , P 2 ) , ( R , P 3 ) , ( S , P 3 ) , ( R , P 2 ) , ( S , P 2 ) , ( R , P 1 ) , ( E , P 1 ) } \{(B,P_1), (S, P_1), (R, P_2), (S, P_2), (R, P_1), (S, P_1), (R, P_2), (S, P_2), (R, P_3), (S, P_3), (R, P_2), (S, P_2), (R, P_3), (S, P_3), (R, P_2), (S, P_2), (R, P_1), (E,P_1)\} {(B,P1),(S,P1),(R,P2),(S,P2),(R,P1),(S,P1),(R,P2),(S,P2),(R,P3),(S,P3),(R,P2),(S,P2),(R,P3),(S,P3),(R,P2),(S,P2),(R,P1),(E,P1)} B B B、 E E E、 S S S、 R R R 表示四种活动, P i P_i Pi 表示进程 i i i 的名称。最后,只需要找出与 r r r 因果路径图具有相同序列的因果路径图。 -
确定时间点 t s t_s ts 和 t e t_e te
t s = min { t ∣ τ ( r t ) E ( T t − w t ( R ( r ) ) ) } > δ t_s = \min{\{t|\frac{\tau(r_t)}{E(\mathbb{T}^t_{t-w}(\mathbb{R}(r)))}\}>\delta} ts=min{t∣E(Tt−wt(R(r)))τ(rt)}>δ
- r t r_t rt 表示请求, t t t 为时间戳, w w w 为时间窗口长度
- t s t_s ts 表示最早时间点 t t t,在 t t t 时刻发出的请求响应时间与前一个时间窗口发出的请求的平均响应时间之比大于阈值 δ \delta δ (例如,1.2)
随机游走算法
给定一个 APG G A P G ( V , E ) G^{APG}(V,E) GAPG(V,E) ,定义矩阵 Q Q Q
- 前向边
- 后向边: ρ \rho ρ 由管理员设置,范围在 0~1 之间
- 重边
Q i j = { S ( v m j , R ( r ) ) , if e i j ∈ E ρ S ( v m j , R ( r ) ) , if e j i ∈ E , e i j ∉ E max ( 0 , S ( v m i , R ( r ) ) − max k : e j , k ∈ E S ( v m k , R ( r ) ) ) , if j = i Q_{ij}=\left\{ \begin{array}{rcl} \mathbb{S}(vm_j,\mathbb{R}(r)), & \text{if}\ e_ij\in{E}\\ \rho\mathbb{S}(vm_j,\mathbb{R}(r)), & \text{if}\ e_{ji}\in{E},e_{ij}\notin{E}\\ \max{(0,\mathbb{S}(vm_i,\mathbb{R}(r))-\max_{k:e_j,k\in{E}}\mathbb{S}(vm_k,\mathbb{R}(r)))}, & \text{if}\ j=i\\ \end{array} \right. Qij=⎩⎨⎧S(vmj,R(r)),ρS(vmj,R(r)),max(0,S(vmi,R(r))−maxk:ej,k∈ES(vmk,R(r))),if eij∈Eif eji∈E,eij∈/Eif j=i
将矩阵 Q Q Q 的每一行标准化,得到转移概率矩阵 Q ‾ = Q i j ∑ j Q i j \overline{Q}=\frac{Q_{ij}}{\sum_j{Q_{ij}}} Q=∑jQijQij ,在 APG 上进行随机游走,从 v m i vm_i vmi 移动到 v m j vm_j vmj 的概率为 Q ‾ i j \overline{Q}_{ij} Qij 。多次移动并计算每台虚拟机上的访问次数。更多的访问次数意味着该虚拟机更可能是一个根本原因。
实验评估
实验环境
- OpenStack:搭建云环境,提供虚拟机服务等。
- PreciserTracer:在每台虚拟机上部署代理 TCP_Tracer ,然后把不同虚拟机的活动日志关联到因果路径图中。从因果路径图中计算关于每个虚拟机服务时间的度量数据,并将结果存储在数据库中。
- Ganglia:部署在每个物理服务器上,收集每个虚拟机的资源利用率。

性能评估
基准方法
- 随机选择(Random Selection, RS):模拟随机检查虚拟机
- 突变(Sudden Change, SC):比较当前时间窗口和以前时间窗口的度量比率
基于距离的排名(Distance Based Rank, DBR):每个组件c都形成一个传播图,其中的节点是可以从c到达的异常组件。确定根本原因转化为选择最优传播图的问题,排名由源实体到其他所有异常实体的最小总距离决定。
评价指标
- 最佳 K 精度(Precision at top K , PR@K):每种算法给出的前K个虚拟机
- 各类别平均值的平均(Mean Average Precision, MAP):量化方法的整体性能
定义 N a ( i ) N_a(i) Na(i) 表示在查找到导致异常 a a a 的根本原因 v m i vm_i vmi 前检查过但不是真正的根本原因的虚拟机数量,基于此定义:
- 平均假阳性(Average False Positive, AFP)
- 最大假阳性(Max False Positive, MFP)
虚拟机级别的根本原因分析
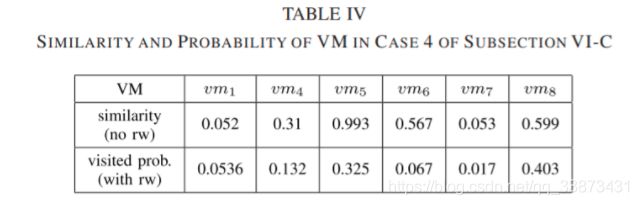
如图 1 所示的架构,考虑 4 种情况:
- 由服务中的一个组件引起并通过服务调用传播的异常( v m 4 vm_4 vm4)
在 v m 4 vm_4 vm4 上进行延迟注入,每个请求SearchItemsByCategory的延迟在 2ms ~25 ms - 由其他租户的并置虚拟机引起的异常,并通过并置边缘进行传播( v m 8 vm_8 vm8 和 v m 5 vm_5 vm5) 编排 v m 8 vm_8 vm8 的 CPU 利用率,将会影响 v m 5 vm_5 vm5 上 MySQL 的性能,最终导致服务异常
- 并置的虚拟机资源不足,无法传播影响业务(几乎不影响)编排 v m 6 vm_6 vm6 的 CPU 利用率,不影响 v m 1 vm_1 vm1 上 LVS 的性能
- 两个并置虚拟机发生资源不足,其中一个无法传播( v m 8 vm_8 vm8 和 v m 5 vm_5 vm5) 结合情况 2、3,同时编排 v m 6 vm_6 vm6 和 v m 8 vm_8 vm8 的 CPU 利用率
多种原因引起异常的根本原因分析
接下来采用不同的根本原因分析方法来定位这三种异常的根本原因,在这个实验中度量定义中的 A \mathbb{A} A 包含了上述三种异常情况。
CloudSim 是云计算基础设施和服务的建模和仿真框架,只能模拟非常简单的应用程序模型;Networkcloudsim 在 CloudSim 的基础上进行扩展,可以使用通信元素或任务来模拟应用程序。
首先设计一种算法构建云环境,在租户申请虚拟机时模拟虚拟机分配到物理服务器,然后还设计了一种算法来构建面向云租户的多层服务拓扑结构,最后使用 Networkcloudsim 模拟云和租户服务的运行。
诊断时间分析
方法讨论
随机游走算法,排除那些仅仅因为相同的周期性用户行为模式而与多层服务高度相关的虚拟机。
进程级别的根本原因分析
租户 A 和租户 B 同时运行 Storm 应用程序,租户 A 同时运行两个进程,如果租户 A 的服务性能异常,必须定位是哪个进程行为异常导致。
Storm 应用程序被建模为一个称为拓扑(topology)的有向图,通常包括两种类型的组件:spout 和 bolt ,spout 是数据流的一个源,而 bolt 使用来自 spout 或其他 bolt 的元组,并按照用户代码定义的方式进行处理。Spout 和 bolt 可以在多个虚拟机上并行执行多个任务,即在一个集群中的工作节点中。
下图包含一个 spout 和两个 bolt 的链式拓扑,数据 spout 是分布式流媒体平台 Kafka 的消费者,数据 spout 订阅 Kafka 的一个主题,Kafka 将自动发送数据到 spout 。数据 spout 连接到一个SplitSentence bolt ,该 bolt 将每一行拆分为单词,并使用字段分组提供给 WordCount bolt ,WordCount bolt 基于不同的输入单词元组递增计数器。
租户 A 将 spout 和 bolt 的并行度设置为 2 ,即对于每个 spout 或 bolt , v m 1 vm_1 vm1、 v m 2 vm_2 vm2 和 v m 3 vm_3 vm3 中都同时运行两个任务。租户 B 将 spout 和 bolt 的并行度设置为 1 。
由于在同一个虚拟机上运行着两个进程,所以云提供商不能使用 PreciseTracer 来执行请求跟踪或直接收集度量数据,Storm 提供了 Thrift API ,可以在不干扰租户服务的情况下监控拓扑的运行。

首先,云提供商可以使用 getExecutors 函数来获取租户 A 的拓扑进程列表。对于每个进程,云提供商可以使用 getComponent_id 函数来获取进程名,再使用 getHost 函数来查找进程运行的虚拟机。根据进程名可以构建进程之间的通信关系,根据虚拟机名称可以通过云平台的 API 找到租户 B 的虚拟机。
有了两种关系,云提供商可以构造如下图所示的 APG。

然后,云提供商可以使用 getComplete_ms_avg 函数来获取元组进程的总时间(从数据 spout 接收句子到 WordCount bolt 完成句子的单词计数的时间),再使用 getExecute_ms_avg 函数获取每个 bolt 进程所花费的时间。
使用这些度量数据,云供应商可以计算出这些节点的相似性。
最后,云提供商可以对 APG 使用随机游走算法,找出根本原因列表及其相应的概率。
