AIOps探索 | 基于大模型构建高效的运维知识及智能问答平台(2)

前面分享了平台对运维效率提升的重要性和挑战以及基于大模型的平台建设解决方案,新来的朋友点这里,一键回看精彩原文。
基于大模型构建高效的运维知识及智能问答平台(1) https://mp.csdn.net/mp_blog/creation/editor/135223109
https://mp.csdn.net/mp_blog/creation/editor/135223109
今天楼主将用实例就跟大家分享一下如何构建知识库、构建的知识库如何应用于事件管理中,希望对你们有所帮助~
觉得楼主写的还不错的话,不要吝啬你们的一键三连呐~
楼主收到支持,会快马加鞭为你们带来更多高质量干货~
书接上篇,我们继续往下看

四、案例分享
1.所需要的软件列表
本次案例的实现,全部采用开源或SAAS的产品来提供,并不涉及到私有化部署的软件产品。软件列表如下所示,如何申请apikey请自行研究,在这里不再详细说明:
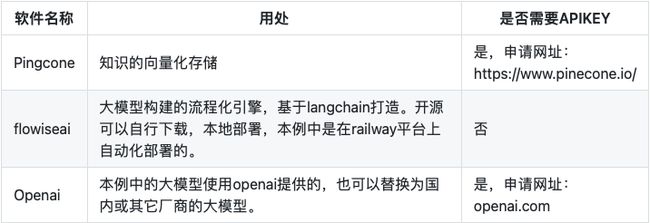
以上软件只是实现该系统的作者推荐列表,在实际的应用中有很多开源、saas、商业版本的软件产品供使用,在这里不再详说明,各位可以根据自己企业的性质自行选择合作的解决方案产品。
2.私有化知识样例说明
由于采用大模型对私有化的知识库数据进行智能问答和知识库系统的实现,因此需要说明私有化知识提供给大模型时一般采取什么格式,会取得比较好的效率。
通常情况下,可以支持各种文档数据,包括work、pdf、markdown、json等,在flowise中都有相应的解析组件可以完成解析,本例中我采用jsons格式,最佳格式是包括两个字段内容prompt和completion,这样大模型可以比较容易识别为“问题”和“答案”。如下示例所示:
{
"prompt": "Redis内存使用率高",
"completion": "Redis内存使用率高可能是由于数据存储的增长或未使用的数据未过期引起的。需要定期清理不必要的数据、优化内存配置以减少内存使用率。"
}
注意:在实际应用中,一定要考虑如果一份文档中包括多个知识点,如何做知识点切分的情况,因此建议采用json格式的数据,比较容易切分,一个“{}”即为一个知识点,pdf、word格式的知识块切分,可自行探索。
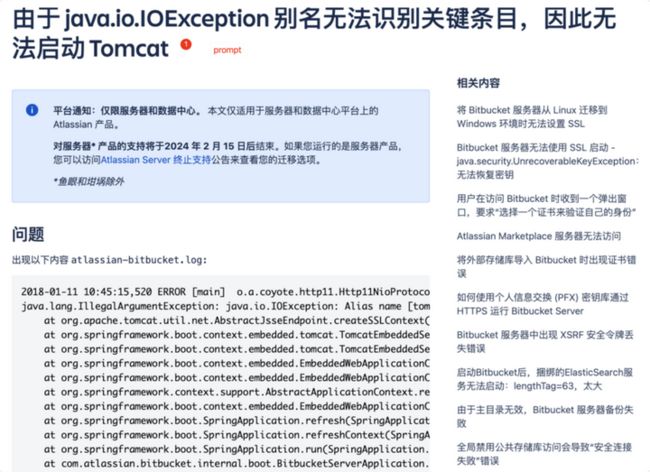
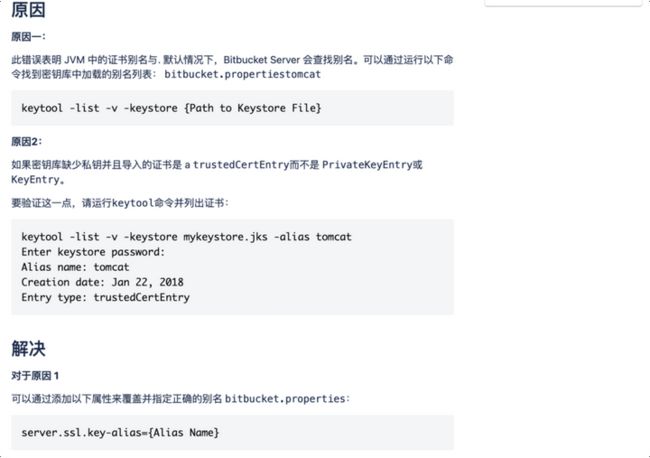
在告警的场景中,可以将告警的内容抽象成一段简单明了的问题存放到prompt字段中,将针对该事件的分析及处置过程整理到completion字段中,completion中可以详细记录产生问题的场景报错信息、问题产生的原因、解决的办法等信息,这样可以提供给大模型更好的推理能力。下面有一份Atlassian的产品报障信息及处置结果的总结,供参考:
-
圈1:标题,即为prompt字段的问题
-
剩下的问题、原因、解决方案,都可以放到completion字段中
3.准备知识数据
在开始之前需要先要有知识数据,本例我们为事件管理的智能问答系统,即在统一事件管理的工作台,事件分析及处置人员在对事件进行处置时,可以直接使用大模型推送的知识,并可以通过反覆盖的交互来完成问题的排查过程。
由于缺少这类的数据,以下知识为通过互联网搜索所得到的知识,比较简漏,但是通过构建这样私有化的知识内容,可以帮助我们走通整个构建的流程。
{"prompt": "Unix服务器保留CPU利用率异常", "completion": "Unix服务器的CPU利用率异常可能是由于不正确的进程管理或资源争用导致的。通过查看系统进程、性能监控工具和日志,可以帮助确定问题的来源,并采取适当的措施来解决它。"}
{"prompt": "GC次数", "completion": "GC次数表示垃圾回收的频率,它受到多种因素的影响,包括应用程序的负载和内存管理设置。要减少GC次数,可以优化代码,减少对象创建,增加堆内存,或者调整垃圾回收策略,以提高系统性能和稳定性。"}
{"prompt": "业务成功率低", "completion": "业务成功率低可能是由于网络问题、系统故障或应用程序错误引起的。需要进行详细的故障排除,包括检查日志、监视系统性能、验证网络连接,以找到并解决问题的根本原因。"}
{"prompt": "Unix服务器保留CPU利用率异常", "completion": "Unix服务器的CPU利用率异常可能是由于不正确的进程管理或资源争用导致的。通过查看系统进程、性能监控工具和日志,可以帮助确定问题的来源,并采取适当的措施来解决它。"}
{"prompt": "Weblogic中间件JVM使用的堆栈空间百分比", "completion": "Weblogic中间件的JVM堆栈空间百分比表示堆栈空间的使用情况。可以通过调整JVM参数、垃圾回收策略和应用程序代码来优化堆栈空间的使用,以提高性能和稳定性。"}
{"prompt": "Linux可用内存少", "completion": "Linux可用内存不足可能是由于运行的进程占用了太多内存,或者内存泄漏导致的。需要检查系统资源使用情况,释放不必要的进程或服务,以增加可用内存。"}
{"prompt": "ESX服务器内存使用率", "completion": "ESX服务器的内存使用率表示服务器内存的利用情况。通过监视内存使用情况、调整虚拟机配置和分配更多内存资源,可以改善性能和避免内存不足问题。"}
{"prompt": "Weblogic中间件JVM使用的Heap空间异常", "completion": "Weblogic中间件的JVM Heap空间异常可能是由内存泄漏或不正确的堆设置引起的。需要分析堆转储文件、调整JVM参数以及检查应用程序代码,以解决问题。"}
{"prompt": "Unix服务器磁盘忙", "completion": "Unix服务器磁盘忙可能是由于磁盘读写操作过多或者磁盘故障引起的。需要查看磁盘活动、日志和性能监控数据,以找到问题并采取适当的措施。"}
{"prompt": "Ping成功率低", "completion": "Ping成功率低通常是由于网络故障或丢包问题引起的。需要检查网络连接、路由、防火墙设置以及网络设备的状态,以提高Ping成功率。"}
{"prompt": "数据存储占用率高", "completion": "高数据存储占用率可能是由于数据积累或未清理的旧数据引起的。需要定期清理、归档或扩展存储资源,以处理数据存储占用率高的问题。"}
{"prompt": "NGINX连接数达上限", "completion": "当NGINX连接数达到上限时,可能是由于并发请求过多或配置限制不当引起的。需要增加连接数限制、优化配置和增加服务器资源以解决问题。"}
{"prompt": "系统成功率低", "completion": "系统成功率低可能是由于软件错误、硬件故障或网络问题引起的。需要进行详细的故障排除,包括检查日志、监视系统性能和验证网络连接,以找到并解决问题的根本原因。"}
{"prompt": "Redis内存使用率高", "completion": "Redis内存使用率高可能是由于数据存储的增长或未使用的数据未过期引起的。需要定期清理不必要的数据、优化内存配置以减少内存使用率。"}
4.构建向量数据库
我们需要登录pinecone,点击indexes,可以看到创建的index列表,本例中我们已经创建即了work index,基本上每个index对应一个领域的知识库,针对其它业务领域的可以再创建一个新的index。

对知识进行向量化之后,会有什么不同,我们可以看一下pingcone数据库存储的信息即可:我们无需创建任何表结果,embeddings方法会将原始数据即圈1位置的原始内容向量化转换为圈2的内容,并将这些信息都存储到一条记录中,一个分割的知识点一条记录。

5.所需要的软件列表
本次案例的实现,全部采用开源或SAAS的产品来提供,并不涉及到私有化部署的软件产品。软件列表如下所示,如何申请apikey请自行研究,在这里不再详细说明:

以上软件只是实现该系统的作者推荐列表,在实际的应用中有很多开源、saas、商业版本的软件产品供使用,在这里不再详说明,各位可以根据自己企业的性质自行选择合作的解决方案产品。
6.流程配置步骤说明
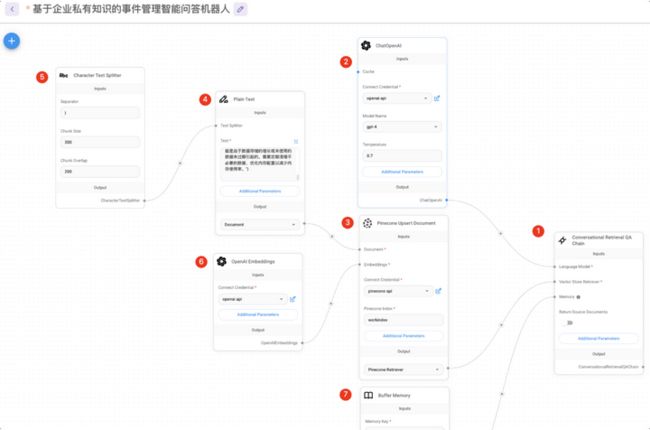
flowiseai是一个可视化的大模型构建工具,提供了非常丰富的算子,可以满足不同情况下用户的建模需求,如上图所示,本例中主要使用了7个关键算法,构建步骤说明如下:
step1:构建一个基于大模型的对话式应用
Flowise 是一个大模型构建工具,可以通过流程化的方式构建不同的应用,在本例中我们构建的是一个对话式机器人,因此,我们从chain中选择conversational retrieval QA Chain,它可以满足我们的需求,将其托动到红圈1所示的位置。
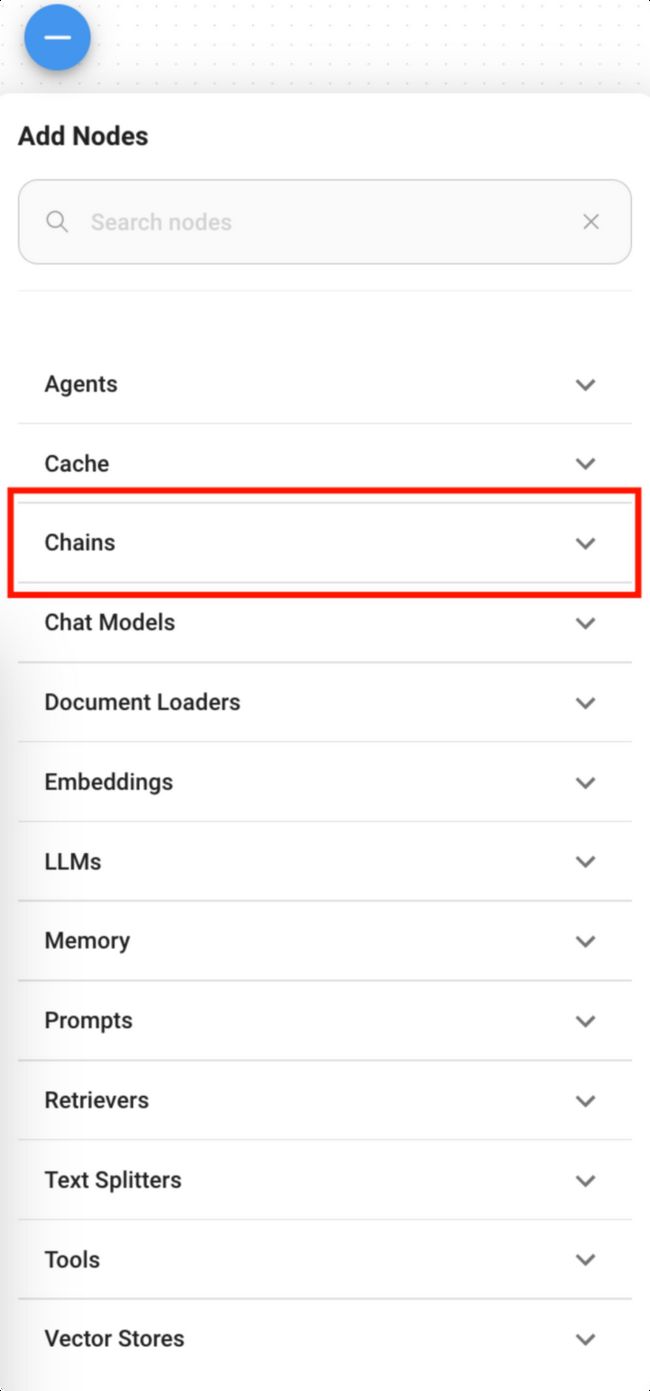
-
Language Model:用于选择大语言模型,可以选择flowise 已经支持的大语言模型,这里不仅仅支持openai,也支持亚马逊的、google的、Facebook等主流场景,因为flowise是一个开源的产品,您也可以将自己私有的大模型填加进来。
-
Vector Store Retriever:大模型进行知识存放的向量化数据库,下面的章节中会介绍向量数据库中存储的到底是什么。
-
Memory:大模型的上下文记忆能力,如果没有配置这个,则每一次问答就结束,没有办法根据上下文会话的内容进行推理。
还有一个更重要的参数,点击Conversation Retrieval QA Chain界面的“Additional Parameters”按钮来配置Prompt,你也可以理解为规则,大致可以说明为你想要大模型角色扮演什么,他的知识从哪里来,回答知识时有些什么样的规则,本例中我配置如下:
You are currently an ITOM expert, responsible for providing solutions to all alarms that occur. You will provide me with answers from the given info. If the answer is not included, say exactly “Hmm, I’m not sure” and stop after that. Refuse to answer any question not about the info. Never break character. Follow these five instructions below in all your responses . Use Chinese lanquage only. 2. Use Chinese characters whenever possible, 3. Do not use English except in programming languages if any;4. Avoid the Latin alphabet whenever possible. 5 Translate any other language to the Chinese language whenever possible
step2:配置QA Chain的大语言模型
本例中我们使用OpenAI来完成,因此选择LLMs中的ChatOpenAI,在这里也可以选择一些其它厂商的模型(如aws、facebook、google等,甚至包括一些国内的大模型),如下图所示:
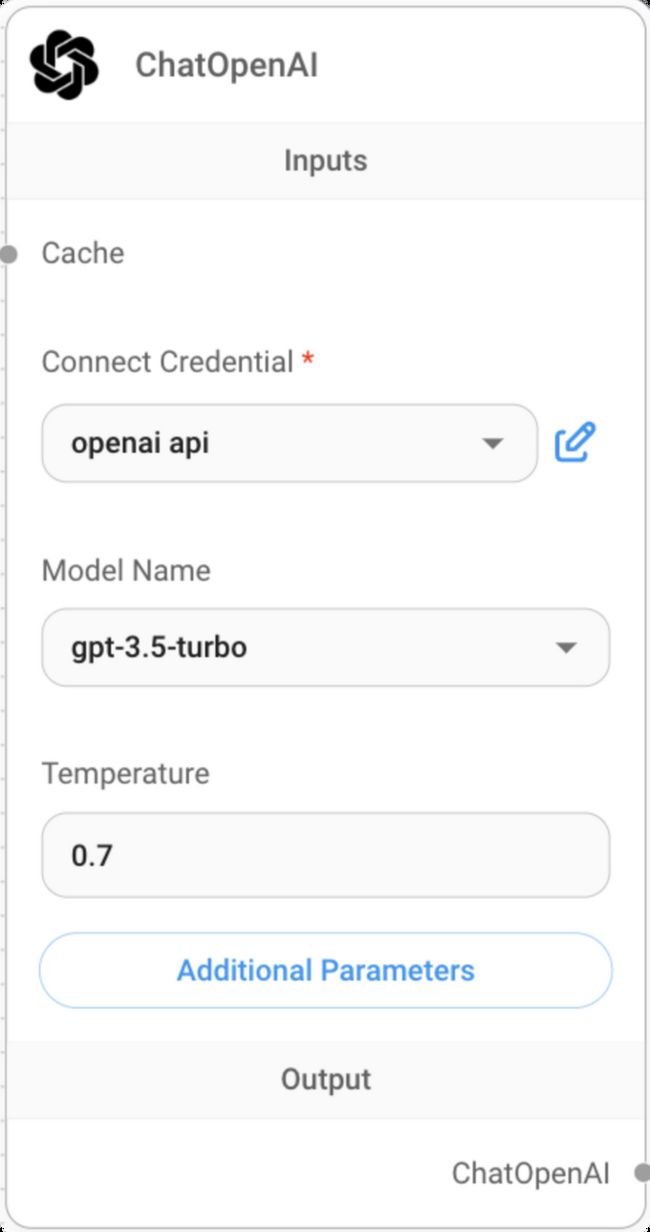
未开通4.0,在这里model Name配置为gpt3.5,connect Credential配置链接 openai 的apikey,其它参数选择默认即可。
step3:配置向量数据库
在本例中我们选择pingcone这一SAAS软件。
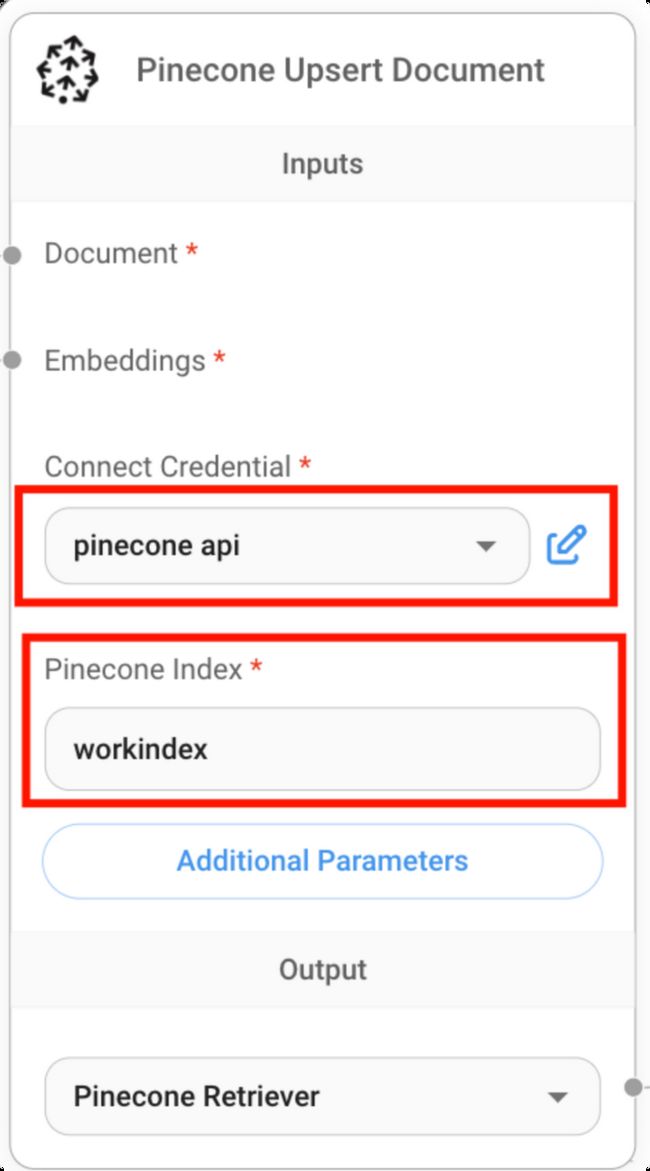
1.向量数据库创建index,获取api key :需要登录pingcone获取一个api key,然后在pinecone中创建一个新的数据库索引,我这边命名为workindex。
2.配置参数:
-
document:代表知识库中输入的知识源,可以是一个或一批文件(pdf、json、word、markdown)等,在flowise 中包括各种解析这种文件的算子。
-
Embeddings:是一个对文件转成文本之后对其进行向量化的算法,把document中的文本进行转向量化的处理,也是有许多开源的算法和厂商提供。
-
connect Credential:是配置连接pinecone数据库的api key参数。
-
Pinecone index:用于配置数据库的索引,在这里选择work index,如果企业内部有多个不同业务领域,则可以配置为不同的index,这样可以使回答更准确,而不易混淆,尤其是业务描述比较相近的情况下。
step4:配置导入知识库
在本例中由于知识内容比较简单,没有大量的数据,我们直接以文本的方式导入,如下图所示:
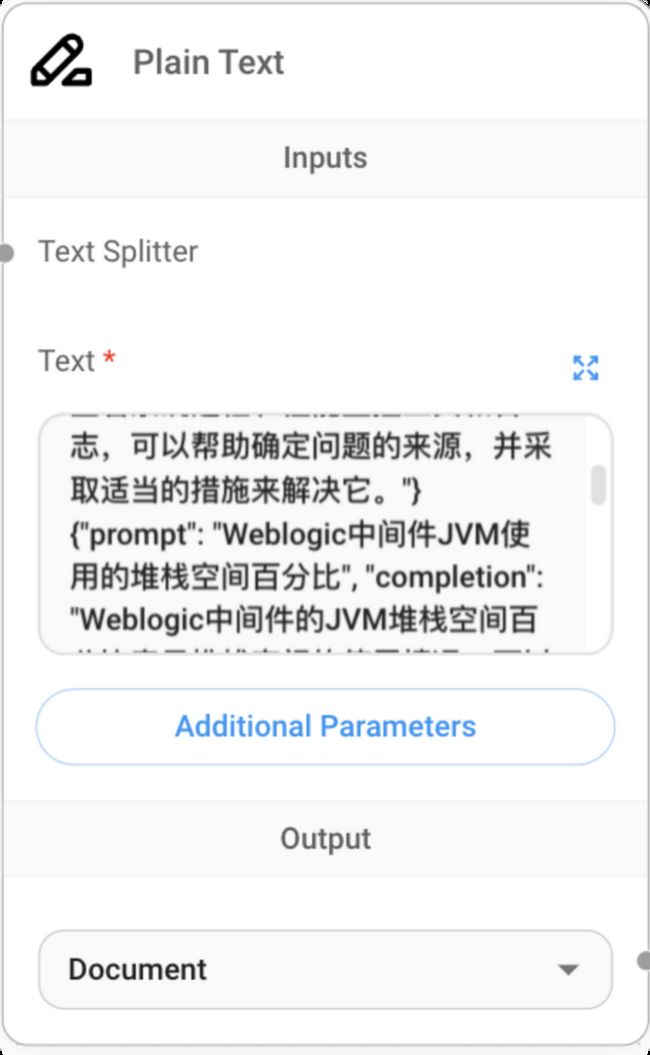
我们直接将知识内容放入text文本框中即可。针对该文本的内容需要切分为不同的知识点,所在还有一个text splitter参数,进入第5步。
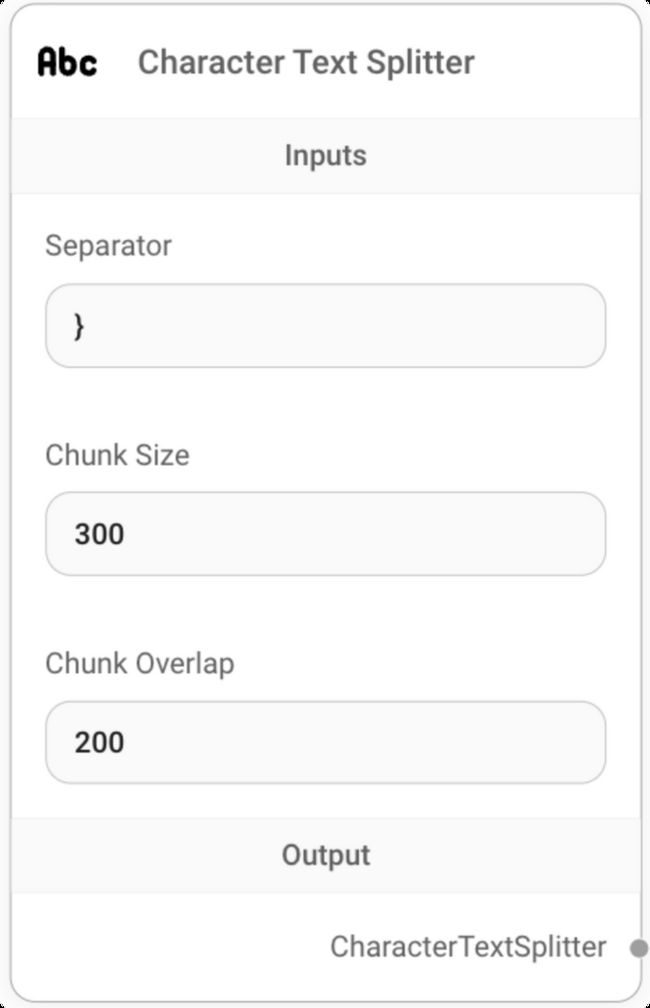
step5:配置文本切分方法
文本切分主要是为了将一个大文件中会包括多个知识点,切分成一个个的独立知识点,存入向量数据库中,由于本例我们使用的json格式,切分比较简单,按“}”来进行切分即可,如下图所示:
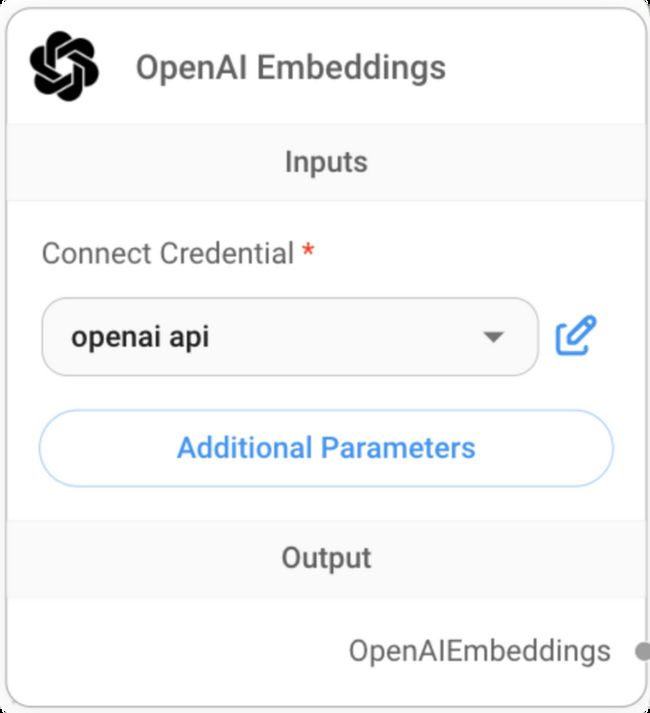
step6:针对切分好的知识点进行向量化转换
如下图所示,本例也使用open ai 的embeddings算法:
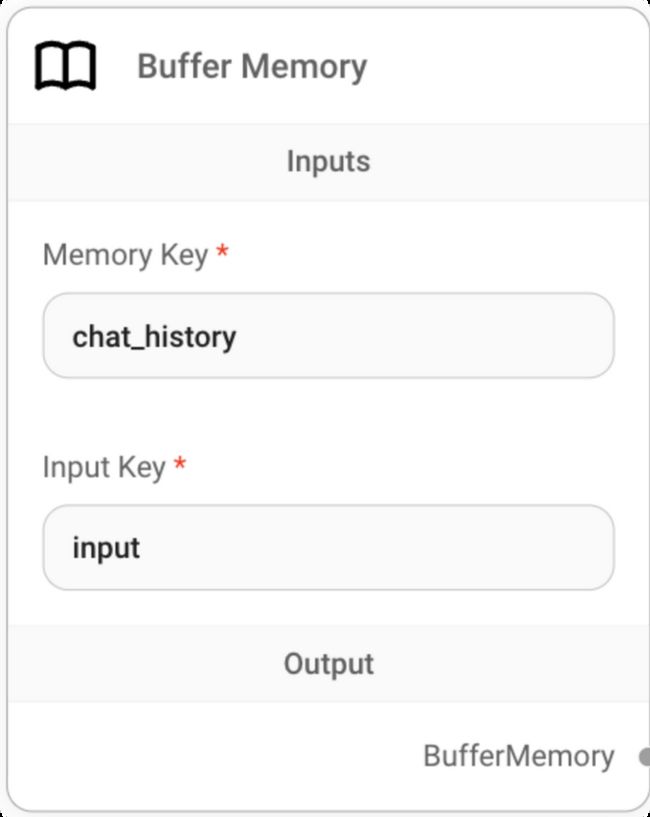
step7:配置智能问答机器人的上下文记忆能力
选择buffer memory算法,参数如下图所配置即可:
step8:验证创建的机器人是否能正常工作
我们输入“cpu利用率异常“,系统已经从我们构建的知识库中找到了答案,并且整个流程也能够跑通了:

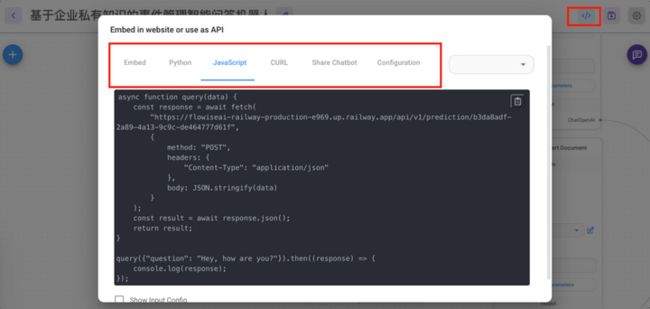
step9:智能问答机器人应用场景集成
集成操作也比较简单,提供了多种集成方法,建议选择javascript方法,只需要在场景中创建一个单独的页面,将javascript的代码嵌入,即可如第8步中看到的样子进行工作了,最后只要调整一下窗口的大小即可。
![]()

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择
 了解更多运维干货与行业前沿动态
了解更多运维干货与行业前沿动态
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散~