数据仓库模型设计开发流程与规范
版本:V1.0
最后修改日期:2021/03/17
本文首发微信公众号:码上观世界
1. 数据模型设计目标
为使下游数据使用方低成本获取一致性的可靠数据服务,数据模型设计方需要达到如下目标:
成本:模型设计者要平衡性能和成本要素对数据模型的影响,现有海量大数据情况下,以保障业务和性能为前提,合理使用数据模型方案和存储策略,尽量消除不必要的数据复制与冗余。
性能:模型设计者需要兼顾模型刷新性能开销、产出时间和访问性能。
数据一致性及数据互通:各个数据模型或者数据表之间必须保障数据输出的一致性,相同粒度的相同数据项(指标、维度)应具有相同的字段名称和业务描述,不同算法的业务指标应显性化区分。
数据质量:数据公共层模型需要屏蔽上游垃圾数据源,一方面要保障数据本身的高质量,减少数据缺失、错误、异常等情况的发生;另一方面要保障其对应的业务元数据的高质量,数据有明确的业务含义,为数据提使用者供正确的指引。
易用:在保障以上目标的前提下,数据用户能从业务角度出发快速找到所需数据;能较快的掌握模型的适用场景和使用方法;能相对便捷获取数据。
2. 数据模型设计指导思想
数据模型设计以ER模型、维度模型和宽表模型理论为指导以及阿里巴巴数据仓库建设实践为经验参考。
2.1 ER模型
数据仓库之父Bill lnmon 提出的建模方法是从全企业的高度设计一个3NF 模型,用实体关系( Entity Relationship, ER )模型描述企业业务,在范式理论上符合3NF 。数据仓库中的3NF 与OLTP 系统中的3NF的区别在于,它是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系的抽象。其具有以下几个特点:
需要全面了解企业业务和数据。
实施周期非常长。
对建模人员的能力要求非常高。
2.2 维度模型
数据仓库领域的Ralph Kimball 大师所倡导的,维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。维度模型的维度退化即是宽表模型。
ER模型是一种范式模型,ER模型和维度模型虽然建模工具类似,比如都使用实体关系来表示,主要区别在于:
1. 着眼点不同:维度建模着眼点在产生事实的业务过程,ER模型着眼点在实体和实体的关系,ER模型的关系更为一般化。
2. ER模型的实体通常是具有业务价值的业务对象,比如商品,客户等,维度模型的维度更着重业务检索需求,如日期、地域、商品等,如下图示例:
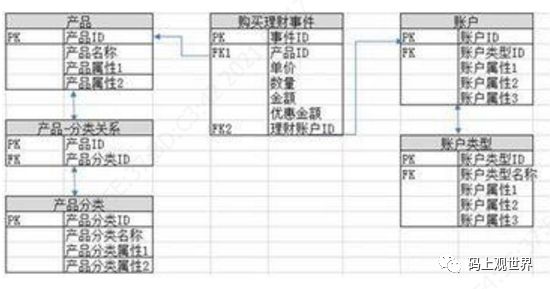

3. 数据模型设计基本原则
高内聚和低耦合:软件设计方法论中的高内聚和低耦合原则同样适用于数据建模,这主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
核心模型与扩展模型分离:建立核心模型与扩 展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要,必要时让核心模型与扩展模型做关联,不能让扩展字段过度侵入核心模型,破坏了核心模型的架构简洁性与可维护性。
公共处理逻辑下沉及单一:越是底层公用的处理逻辑更应该在数据调度依赖的底层进行封装与实现,不要让公共的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。
成本与性能平衡:适当的数据冗余换取查询和刷新性能,不宜过度冗余与数据复制。
数据可回滚(数据生成支持幂等性):处理逻辑不变,在不同时间多次运行数据结果确定不变。
一致性:相同的字段在不同表字段名相同,字段值相同。
命名清晰可理解:表命名规范需清晰、一致,表名需易于下游理解和使用。
4. 数据模型设计步骤总览
4.1 数据模型设计总体步骤
业务建模:生成业务模型,主要解决业务层面的分解和程序化,常用工具如流程图、时序图、用例图等。
领域建模:生成领域模型,主要是对业务模型进行抽象处理, 生成领域概念模型,这一步中会涉及到概念的分组(主题),比如Teradata FS-LDM模型将金融业的领域概念划分成10大主题:当事人、产品、协议、事件、资产、财务、机构、地域、营销、渠道。
逻辑建模:生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
物理建模:生成物理模型,主要解决逻辑模型针对不同关系数据库的物理化以及性能等一些具体的技术问题。
上述步骤是模型从抽象化到具体落地的过程,也反应了模型的不同抽象层次。每个层次内部还可以继续按照层次具体分解,比如业务模型还可以分为顶层模型,业务域,业务流程,业务环节。
4.2 数据模型设计实施流程
各步骤按照实施过程涉及到的内容见下图:
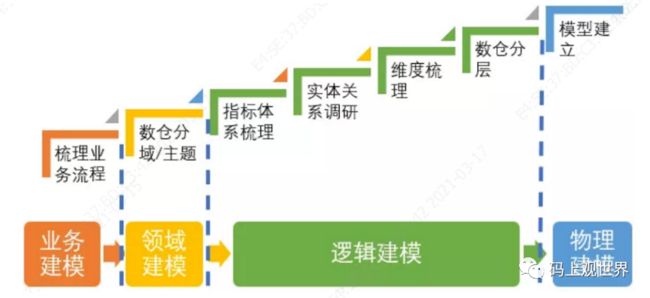
业务调研和需求分析是数据仓库建设的基石。在代码开发之前,数据架构设计主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。再次,根据需求抽象整理出相关指标体系。数仓建模主要关注从业务建模领域建模到逻辑建模的过程,其中业务建模和领域建模是基础,逻辑建模是核心。本文将上述实施步骤通过流程梳理如下:

5. 数据模型设计术语名词解释
术语 |
解释 |
主题(域) |
主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。主题域是对某个主题进行分析后确定的主题的边界。 |
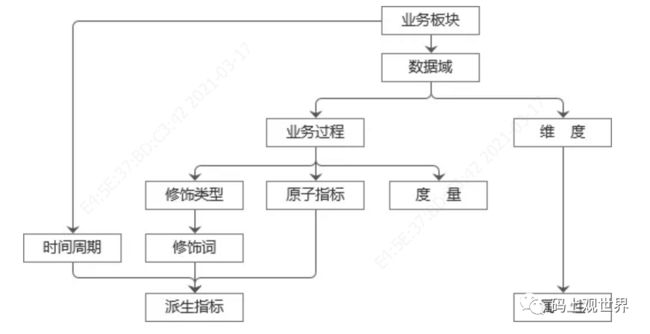
数据域 |
指面向业务分析,将业务过程或者维度进行抽象的集合。其中, 业务过程可以概括为一个个不可拆分的行为事件, 在业务过程之下, 可以定义指标;维度是指度量的环境,如买家下单事件,买家是维度。为保障整个体系的生命力, 数据域是需要抽象提炼,并且长期维护和更新的, 但不轻易变动。在划分数据域时, 既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中和扩展新的数据域。 |
业务板块 |
业务板块定义了数据仓库的多种命名空间,是一种系统级的概念对象。当数据的业务含义存在较大差异时,您可以创建不同的业务板块,让各成员独立管理不同的业务,后续数据仓库的建设将按照业务板块进行划分。 |
业务过程 |
指企业的业务活动事件,如下单、支付、退款都是业务过程。请注意,业务过程是一个不可拆分的行为事件, 通俗地讲,业务过程就是企业活动中的事件 |
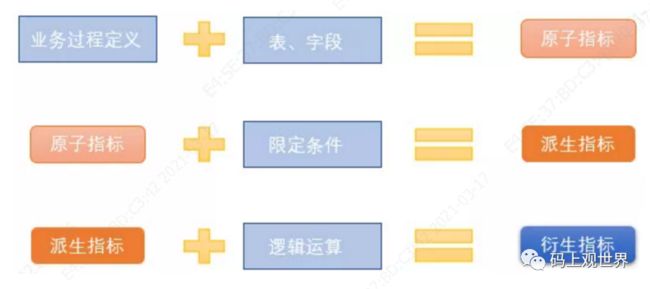
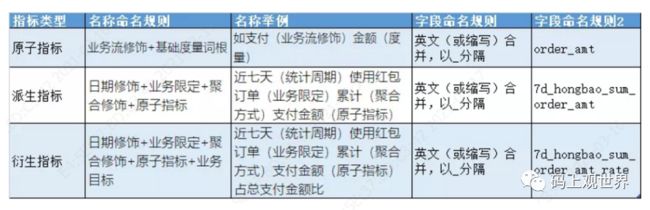
业务限定 |
统计的业务范围,用于筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。原子指标是计算逻辑的标准化定义,业务限定则是条件限制的标准化定义。 |
时间周期 |
用来明确数据统计的时间范围或者时间点,如最近30 天、自然周、截至当日等 |
修饰类型 |
是对修饰词的一种抽象划分。修饰类型从属于某个业务域,如日志域的访问终端类型涵盖无线端、PC 端等修饰词 |
修饰词 |
指除了统计维度以外指标的业务场景限定抽象。修饰词隶属于一种修饰类型,如 在日志域的访问终端类型下, 有修饰词PC 端、无线端等 |
统计粒度 |
统计分析的对象或视角,定义数据需要汇总的程度,可以理解为聚合运算时的分组条件(类似于SQL中group by的对象)。粒度是维度的一个组合,指明您的统计范围。例如,某个指标是某个卖家在某个省份的成交额,则粒度就是卖家、省份这两个维度的组合。如果您需要统计全表的数据,则粒度为全表。在指定粒度时,您需要充分考虑到业务和维度的关系。统计粒度也被称为粒度,是维度或维度组合,一般用于派生指标构建,是汇总表的唯一性识别方式。 |
指标 |
指标分为原子指标和派生指标。派生指标是以原子指标为基准,组装统计粒度、统计周期及业务限定而生成的。 原子指标是对指标统计口径、具体算法的一个抽象。根据计算逻辑复杂性,Dataphin将原子指标分为两种: 原生的原子指标:例如支付金额。 衍生原子指标:基于原子指标组合构建。例如,客单价通过支付金额除以买家数组合而来。 派生指标是业务中常用的统计指标。为保证统计指标标准、规范、无二义性地生成,OneData方法论将派生指标抽象为四部分:派生指标=原子指标+业务限定+统计周期+统计粒度。 |
维度 |
维度是度量的环境,用来反映业务的一类属性, 这类属性的集合构成一个维度, 维度也可以称为实体对象。维度属于一个数据域,如地理维度(其中包挤罔家、地区、 省以及城市等级别的内容)、时间维度(其中包括年、季、月、周、日等级别的内容) |
维度属性 |
维度属性隶属于一个维度, 如地理维度里面的国家名称、同家ID 、省份名称等都属于维度属性 |
派生指标 |
派生指标=一个原子指标+多个修饰词(可选)+时间周期。可以理解为对原子指派生指标标业务统计范罔的圈定。如原子指标:支付金额,最近l天海外买家支付金额则为派生指标(最近l 天为时间周期, 海外为修饰词, 买家作为维度,而不作为修饰词) |
注意:
这里有两个概念:主题域和数据域,两者概念一致,虽然都是从业务上划分,只是角度不同。主题从高层业务视角来划分,面向业务。数据域从系统数据打通的角度来划分,面向数据。数据域可能涉及到多主题域,主题域也可能涉及到多数据域。
6. 数据模型设计实施过程
6.1 数据调研
通过跟业务分析师或者运营人员了解数据需求,借助各种分析工具对涉及到的业务流程进行梳理和业务领域划分。这一步骤输出的文档包括业务流程图、时序图、活动图、用例图等。
6.2 数据域划分
数据仓库是面向主题的应用,主要功能是将数据综合、归类并进行分析利用。数据仓库模型设计除横向的分层外,通常还需要根据业务情况纵向划分数据域。数据域是联系较为紧密的数据主题的集合,是业务对象高度概括的概念层次归类,目的是便于数据的管理和应用。
通常您需要阅读各源系统的设计文档、数据字典和数据模型设计文档,研究逆向导出的物理数据模型。然后进行跨源的主题域合并,梳理出整个企业的数据域。划分数据域,需要分析各个业务模块中有哪些业务活动。数据域,可以按照用户企业的部门划分,也可以按照业务过程或者业务板块中的功能模块划分。例如,A公司电商营销业务板块可以划分为如下表所示的数据域。数据域中的每一部分,都是根据实际业务过程进行归纳、抽象得出的。
输出文档:数据域和业务过程分类关系,格式可以是类似下面的图例:

6.3 指标规范定义
指标规范定义输出文档格式为:
数据域 |
业务过程 |
指标 |
指标类型 |
名称 |
说明 |
维度 |
||
交易域 |
支付 |
金额 |
原子指标 |
order_amt |
区域 |
时间 |
渠道 |
|
笔数 |
原子指标 |
order_cnt |
||||||
售后域 |
退款 |
笔数 |
原子指标 |
refund_cnt |
||||
6.4 ER模型梳理
这一步骤是按照自下向上快速构建数仓的方式,对业务需要的业务过程建模。细化领域模型中得出的实体及其属性、维度及其属性、业务过程及其维度和度量、指标,输出ER图文档。

6.5 数据域映射
该步骤将ER图中每个业务过程涉及到的业务表及其数据来源维度、指标等信息列举出来,输出数据源映射文档。
数据域 |
业务过程 |
数据源 |
数据源类型 |
业务表 |
表类型 |
名称 |
维度、度量、属性 |
交易域 |
支付 |
交易 |
mysql |
order_table |
事实表 |
订单表 |
区域id |
时间id |
|||||||
金额 |
|||||||
prod_table |
维度表 |
商品表 |
类目 |
||||
cust_table |
维度表 |
客户表 |
年龄 |
||||
售后域 |
退款 |
售后 |
oracle |
refund_table |
事实表 |
退款表 |
区域id |
时间id |
|||||||
金额 |
6.6 数仓分层
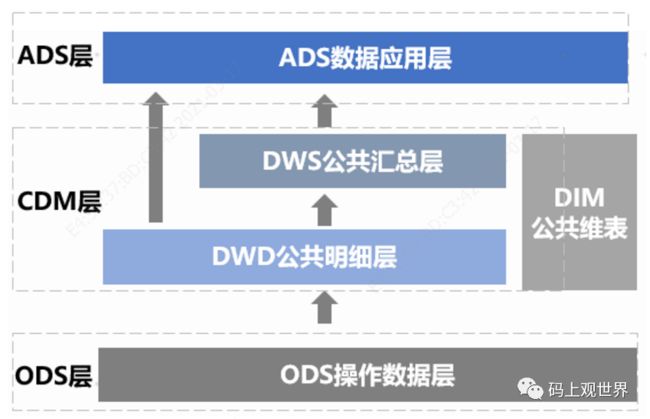
操作数据层( ODS ):把操作系统数据几乎无处理地存放在数据仓库系统中。包括全量和增量同步的结构化数据、经过处理后的非结构化数据以及根据数据业务需求及稽核和审计要求保存历史数据、清洗数据。
数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。
公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。明细粒度事实层的表通常也被称为逻辑事实表。
数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
7. 数据模型设计开发规范
完整文档关注公众号:码上观世界,回复“数据模型设计开发规范”下载。