SLT2021: HOW FAR ARE WE FROM ROBUST VOICE CONVERSION: A SURVEY
0. 题目
HOW FAR ARE WE FROM ROBUST VOICE CONVERSION: A SURVEY
一个调查: 我们距离鲁棒性强的音色转换还有多远?

1. 摘要
近年来,在深度学习的帮助下,语音转换技术得到了极大的改进,但是在不同条件下产生自然发声的能力仍然不清楚。 在本文中,我们对已知VC模型的鲁棒性进行了深入研究。 我们还修改了这些模型,例如替换了说话人嵌入向量编码,以进一步提高其性能。 我们发现采样率和音频持续时间极大地影响了语音转换。 所有的VC模型对于未见过的说话人, 均表现不好,但是AdaIN-VC相对更健壮。 而且,说话人嵌入向量联合训练的效果比经过说话者身份识别训练网络的效果更适合语音转换
关键词: voice conversion, speaker verification, speaker identification, speaker representation, speaker embedding, network robustness
语音转换,说话人验证,说话人识别,说话人表示,说话人嵌入向量标识,网络的鲁棒性
2. 简介
语音转换(VC)技术旨在在保持语言内容信息的同时,将话语的说话者特征转换为目标说话者的特征。 在以前的工作中,需要配对平行多说话人语料才能实现VC。 最近,有人提出了几种利用非平行数据的模型[1,2,3,4,5]。 DGAN-VC [6]通过对抗训练学习结构内容和说话者信息。 StarGANVC [7]采用条件输入来实现多对多语音转换。 但是,两者都限于在培训过程中在看到的说话者之间进行VC。 再以后就有了使用Zeroshot方法[8、9、10、11、12],其中模型可以在任何说话人的语料之间执行VC,而无需进行微调模型。 AdaIN-VC [13]应用实例规范化操作技巧来满足这一对任意说话人均可以音色转换的要求。 另外一种叫AUTOVC [14], 他采用了预训练的d-vector [15]和信息瓶颈的相关技巧
尽管最近VC技术变得越来越强大,但是大多数论文都在相同语料库(通常是VCTK语料库[16])上训练和评估其VC模型, 并且见过的和未见过的说话人测试语句具有相似录音条件。 但是,在实际应用中,发声的录制条件可能与训练数据完全不同。 如今的VC模型对于实际应用是否足够强大? 答案可能是否定的。[17]成功地对VC模型进行了对抗攻击,这表明当今的VC模型可能仍然不够健壮。 但是,我们不知道它们有多健壮,哪些不匹配的属性特点会对它们产生影响?
这可能是研究鲁棒性的第一篇论文 VC模型。 在以下三个方面,我们用五个常用数据集调查了三种流行的VC模型的鲁棒性:
- 模型如何处理具有: (1)不同采样率,(2)总持续时长, (3)甚至未见过的语言语种
- 通过消融研究来找出这些模型的哪些模块对于语音转换至关重要
- 检查说话人嵌入向量的影响,以确定哪种嵌入向量最适合VC
3. 其他-容易懂
在这里,我们首先介绍本文所涉及的VC模型和扬声器嵌入。 我们调查了实现说话者音色和内容信息解开的模型:DGANVC [6],AdaIN-VC [13]和AUTOVC [14]。 所有这些模型都是公开可用的,因此可以轻松复制。 对于说话人嵌入,我们调查了i-vector [18],d-vector [15]和x-vector [19],它们在说话人验证中均表现良好,并进一步引入了新的嵌入v-vector
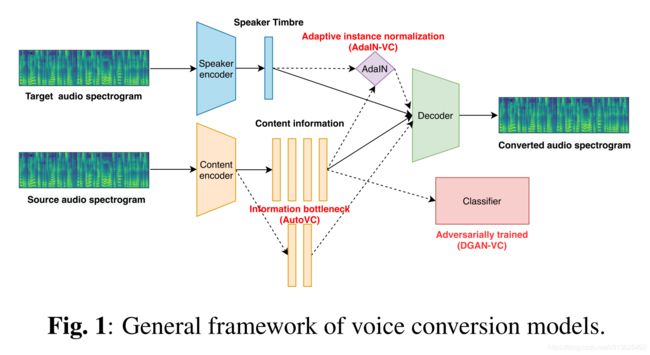
DGAN-VC [6]采用了两阶段的培训框架 多对多语音转换。 Es提供了一个one-hot向量作为说话人嵌入来表示不同的说话人。 在第一阶段,应用附加的分类器,以内容表示为输入并进行对抗性训练,以获得独立于说话者的语言信息。 在第二阶段,然后采用生成对抗网络(GAN)[20]使输出频谱更加逼真
AdaIN-VC [13]使用可变自动编码器[21](VAE), 对于内容编码器,其中潜在表示受KL散度损失限制,并采用自适应实例归一化[22](AdaIN)来实现零脉冲VC。 Ec中使用的实例规范化在保留内容信息的同时删除了音色信息,然后由Es将音色信息提供给具有AdaIN层的解码器
AUTOVC [14]是经过精心设计的自动编码器 信息瓶颈仅受自我重建损失的训练。 信息瓶颈是Ec和D之间的潜在向量的维数。有了这个瓶颈,语言内容和音色信息便会被解开而没有明确的约束,而后者(音色信息)则是在解码过程中由预训练的d矢量提供的
在i-vector [18]中,说话人和话语相关 GMM超向量M建模为
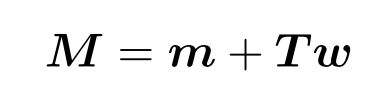
其中m表示与说话者无关的GMM超向量,而T是低秩总可变性矩阵,可同时捕获说话者和话语可变性。 i向量就定义为是w的最大后验估计
d-vector[15]将DNN用作说话者特征提取器,并对说话者识别任务或GE2E损失进行训练[23]。 最后一个隐藏层的输出被视为说话人的的紧凑(非稀疏, 非one-hot)表示,称为d-vector
x-vector[19]使用时延神经网络(TDNN) 学习时间上下文信息。 对说话人识别任务进行训练,最后一个隐藏层的输出用作说话人的表示,称为x-vector
另外,v-vector是此论文中引入的新概念,定义为: 与VC模型联合训练的说话人编码器的表示, 结构设计使用来自AdaIN-VC的,经过VCTK训练的预训练说话人编码器
我们考虑两个客观指标:字符错误率(CER)和说话者验证接受率(SVAR)。 SVAR是说话人验证系统接受的音频数与总的之比。 较低的CER表示保留的内容更好,而较高的SVAR表示音色转换更成功。 自动语音识别(ASR)衡量效果如何 来自源话语的语言信息将保留在转换后的信息中。 我们在Google云语音API中使用了语音转文本服务来计算CER。 对于中文,我们用拼音
说话者验证(SV)衡量转换后的 话语属于在VC中提供音色信息的说话者。 我们使用了第三方预先训练的说话人编码器从话语中提取说话人嵌入向量。 如果转换后的话语和目标发音之间的嵌入余弦相似度(在VC中提供音色信息)大于给定阈值,则认为转换后的话语已成功转换。 我们通过在用于测试的数据集上计算均等错误率(EER)来获得阈值。 对于每个说话者,我们随机采样了128个正样本和128个负样本,示例总数超过100k。 EER为5.65%,阈值为0.6597

这里使用的AUTOVC2,AdaIN-VC3和DGAN-VC4是从官方实施中获得的,并且都接受了VCTK培训。在其最初的实现中,DGANVC和AdaIN-VC利用Griffin-Lim算法[28]从频谱图生成波形,而AUTOVC应用WaveNet [29]作为声码器。为了消除不同声码器的影响,我们对每个模型进行了修改,以输出80维的Mel频谱图,并采用了预训练的MelGAN [30]作为声码器,将这些Mel频谱图转换为波形。由于DGAN-VC仅限于在培训过程中看到的原始执行者中执行VC,因此我们将DGAN-VC的说话人嵌入替换为AdaIN-VC中使用的说话人编码器体系结构,该体系结构可以实现zero-shot。
对于说话人向量的使用,从在VoxCeleb1 [32]和Voxceleb2 [33]上训练的Kaldi [31]预训练系统获得了i-vector和x-vector。对于d-vector,我们使用了在VoxCeleb1和LibriSpeech上训练的AUTOVC的预训练d向量模型。对于v-vector,我们使用来自AdaIN-VC的,经过VCTK训练的预训练说话人编码器
通常,AdaIN-VC和AUTOVC的性能相对优于DGAN-VC,并且都有各自的优势。 将进一步研究这两种模型:
- 我们训练了AUTOVC,将其说话人编码器替换为训练好的的AdaIN-VC(AUTOVC-Vvec)的v-vector
- 我们将VAE架构添加到AUTOVC(-VAE)中
- 我们将AdaIN层集成到AUTOVC的解码器(AdaIN)中
- 我们用一种自动编码器(AdaIN-VC-AE)替换了AdaINVC中的VAE体系结构
结论:
- 就所有数据集的SVAR而言,AUTOVC-Vvec的性能均优于AUTOVC。 但是,相对于AUTOVC,AUTOVC-Vvec在CER方面并未显示出显着改善,因此仍然不够强大
- AdaIN-VC-AE和AUTOVC-AdaIN的性能 在CER和SVAR上都不理想,这表明仅使用AdaIn图层不足以转换扬声器音色。 在AUTOVC修改中,AUTOVC-VAE在CER方面表现最差。 潜在矢量的小尺寸和VAE体系结构都限制了内容编码器提供给解码器的信息。 AUTOVC-VAE的不良结果可能归因于潜在向量和VAE体系结构的不正确组合引起的内容信息不足(略)
讨论不同的说话人嵌入向量如何影响VC的性能:
我们使用三种不同的预训练扬声器嵌入训练了模型,包括分别表示为-I,-D和-X的i矢量,d矢量和x矢量。 我们表示其扬声器编码器共同训练为-Joint的VC模型。 此外,我们训练了AUTOVC,其扬声器编码器被训练有素的AdaIN-VC(AUTOVC-Vvec)的vvector取代了
我们可以看到AdaIN-VC-Joint在所有AdaIN-VC修改中表现最好,在所有AUTOVC修改中AUTOVC-Vvec也是如此。 用d向量和x向量训练的模型不能很好地转换说话者的音色。 使用i-vector训练的模型能够很好地转换音色,但CER却不令人满意。 与其他经过预训练的说话人嵌入(VCTK与VoxCeleb)相比,对V-vector进行的数据处理要少得多,但仍然优于经过预训练的说话人嵌入。 最后,AUTOVC-Joint失败,在每种情况下均具有极高的CER和低SVAR
重要结论:
结果表明,预训练的说话人向量尽管对VC进行了大量语料的预处理,但对VC的效果不如在她的原有任务中ASV的效果。 采用VC模型共同训练的语音嵌入向量更适合语音转换。 结果还表明,VC和说话者验证任务所需的说话者信息不同。 同时, 不同于one-hot训练方式, AUTOVC需要预先训练的说话人向量的嵌入表示,以(帮助)使内容编码器仅能够提取内容信息
4. 其他-不容易懂
- 具体模型结构
- 具体的实验结果