基于spaCy的领域命名实体识别
基于spaCy的命名实体识别
----以“大屠杀”领域命名实体识别研究为例
作者: Dr. W.J.B. Mattingly
Postdoctoral Fellow at the Smithsonian Institution's Data Science Lab and United States Holocaust Memorial Museum
2021年1月
引用:Mattingly, William. Introduction to Named Entity Recognition, 2020. ner.pythonhumanities.com
本文原本是作为自然语言处理任务之命名实体识别(NER)的教材。NER的目的是从非结构化文本中提取结构化数据,即特定的实体,如人名、地名、日期等。到目前为止,从使用现成的框架到自己开发特定领域的解决方案,还没有一种免费的、广泛的关于NER主题和方法的处理方法。本文使用几个不同的数据集来演示NER的使用方法和功用。这些章节与嵌入相关章节的YouTube视频一起使用。完整的播放列表可以在这里找到:https://www.youtube.com/channel/UC5vr5PwcXiKX_-6NTteAlXw。
致谢
这本NER教材是我在史密森学会数据科学实验室做博士后时与美国大屠杀纪念馆合作编写的。如果没有Rebecca Dikow, Mike Trizna和那些在数据科学实验室的人的帮助,这一切都不可能实现,当我写这一系列笔记时,他们耐心倾听并给予我帮助和建议。我还要感谢USHMM的专家,特别是Michael Haley Goldman, Michael Levy和Robert Ehrenreich。
文章目录
- 基于spaCy的命名实体识别
- 一 主要概念和术语
-
- 1 命名实体识别简介
-
- 1.1 本文概述
- 1.2 主要概念
- 1.3 什么是自然语言处理?
- 1.4 什么是命名实体识别?
- 2 spaCy简介
-
- 2.1 关键概念
- 2.2 什么是框架?
- 2.3 什么是spaCy?
- 2.4 分句
- 2.5 命名实体识别(NER)
- 2.6 词性(Part-of-Speech)POS
- 2.7 抽取名词和名词块
- 2.8 抽取动词的动词短语
- 2.9 词形还原
- 3 spaCy基于规则的NER
-
- 3.1 关键概念
- 3.2 什么是基于规则的NER?
- 3.3 为什么要使用基于规则的NER?
- 3.4 什么时候使用基于规则的NER?
- 3.5 基于规则的NER的局限性
- 3.6 spaCy的EntityRuler
- 3.7 练习
- 3.8 基于规则的NER视频
- 4 spaCy基于机器学习的NER
-
- 4.1 关键概念
- 4.2 什么是机器学习?
- 4.3 机器学习的类型
- 4.4 NER中的监督学习
- 4.5 监督学习是如何工作的(注意:数学!)
- 4.6 何时使用机器学习NER?
- 4.7 使用spaCy的机器学习模型
- 4.8 练习
- 4.9 机器学习NER视频
- 二 NER训练基础
-
- 1.1 关键概念
- 1.2 spacy的EntityRuler简介
-
- 1.3 EntityRuler演示实例
- 1.4 向EntityRuler引入复杂的规则和变体(高级)
- 1.5 spaCy中其他基于匹配的技术
- 1.6 练习
- 1.7 视频
- 2 用EntityRuler创建训练集
-
- 2.1 关键概念
- 2.2 训练集简介
- 2.3 spaCy训练集的数据样式
- 2.4 创建一个训练集
- 2.5 练习
- 2.6 视频
- 3 如何训练spaCy模型
-
- 3.1 关键概念
- 3.2 spaCy训练机器学习模型简介
- 3.3 准备数据
- 3.4 训练一个spaCy模型
- 3.5 如何改进上述模型
- 3.6 练习
- 3.7 视频
- 三 高级NER概念
-
- 1 考察一个spaCy模型文件夹
-
- 1.1 关键概念
- 1.2 简介
- 1.3 视频
- 2 词向量简介
-
- 2.1 关键概念
- 2.2 阅读之前
- 2.3 用数字表示文本的需求
- 2.4 为什么要使用词向量?
- 2.5 词向量格式
- 2.6 为什么要使用词向量?
- 2.7 视频
- 3 用Gensim生成词向量
-
- 3.1 关键概念
- 3.2 Gensim简介
- 3.3 准备语料库
- 3.4 创建词向量
- 3.5 测试生成的词向量
- 3.6 练习
- 3.7 视频
- 4 将自定义词向量加载到spaCy模型中
-
- 4.1 关键概念
- 4.2 加载词向量
- 4.3 练习
- 4.4 视频
- 四 解决特定领域的问题(大屠杀研究)
-
- 1 创建良好的实体数据集
-
- 1.1 关键概念
- 1.2 数据集简介
- 1.3 获取数据
- 1.4 维基百科(Wikipedia)
- 1.5 美国大屠杀纪念馆
- 2 创建语料库
-
- 2.1 关键概念
- 2.2 概述
- 2.3 多样性
- 2.4 准备语料库
- 2.5 词性还原与非词性还原(To Lemmatize or Not to Lemmatize)
- 2.6 分割语料库
- 2.7 练习
- 3 “大屠杀”领域NER面临的挑战
-
- 3.1 关键概念
- 3.2 问题概览
- 3.3 关于道德伦理方面
- 3.4 语言方面的
- 3.5 地名
- 3.6 练习
- 3.7 视频
- 4 创建用于“大屠杀”领域NER的LOCATION管件(Pipe)
-
- 4.1 关键概念
- 4.2 概述
- 4.3 创建一个空白spaCy模型
- 4.4 保存spaCy模型
- 4.5 放置管件(Pipes)
- 4.6 添加自定义标签
- 4.7 练习
- 4.8 视频
一 主要概念和术语
1 命名实体识别简介
1.1 本文概述
本文适用于那些有兴趣通过spaCy库训练定制命名实体识别模型的人。特别是对于编码经验有限和没有自然语言处理(NLP)背景的人。本文的学习,需要对Python有基本的了解,然而,对于没有编码经验的人仍然能够通过本文的学习,对自然语言处理、命名实体识别这些领域的常见问题以及这些问题的解决方案有基本的了解。对于那些有兴趣快速了解Python的人,请在PythonHumanities.com上查看我为数字人文主义者设计的学习系列。
本文主要有以下五个目标:
- 向读者介绍自然语言处理和命名实体识别的核心概念。
- 为那些Python知识有限者介绍spaCy库。
- 详述特定领域实体识别工作中的问题和解决方案。
- 详述大屠杀文件呈现给NLP工作者的独特问题。
- 为希望将这些方法应用到自己特定领域的读者提供易于复现效果的代码。
虽然本文是基于大屠杀领域的NER,但其中遇到的问题并非是该领域所独有的。因此,本文可以作为其他领域中遇到类似问题的指南。
主要概念和术语将以粗体标示.
1.2 主要概念
- 自然语言处理(NLP)
- 命名实体识别(NER)
- tokens and tokenization 标识和标识化
- multi-word tokens(MWT)多词短语
- Spans 跨区域段标签
- 管道
1.3 什么是自然语言处理?
命名实体识别(下面介绍)是自然语言处理(即NLP)的一个分支。自然语言处理是人们使用计算机系统解析人类语言,并从文本中提取重要元数据的过程。NLP的目的之一是执行远程读取(distant reading)。
远程阅读由来已久,一直延续到20世纪后期。通常用于当给定语料库中的文本数量大到使研究人员(或一组研究人员)无法仔细阅读整个语料库的情形。为了理解如此庞大的语料库,研究人员通常会将某些特定任务交给计算机,并容许一定误差。接受这种误差,以换取对该语料库更大、更广泛的理解的能力。远程阅读被用于执行一些重要的任务,比如:
- 情感分析=>理解一篇文章的情感
- 文本分类=>将文本分为预先确定的类别
- 命名实体识别=>从文本中提取实体
从这些任务中得到的元数据可以用来获得文本的感觉,而无需仔细阅读它们,因此称为“远程阅读”。
NLP与计算语言学的另外两个类似分支——自然语言理解(NLU)和自动语音识别(ASR)协同工作。为了更好地理解这些领域是如何相互关联的,请看下图。
此图在各种NLP教程中经常被使用。它准确地描绘了NLP领域的多样性以及NLU和ASR的密切合作领域。NLP的目标是将文本输入计算机系统,并让它返回某种输出。这通常是通过一系列管道来实现的,这些管道对输入数据执行一系列的操作。
靠前的管道,可能包括一个分词器,其唯一的工作是将文本分解为单个标识(Token)。标识是文本中具有某种语义的单位。它们可以是单词,如“Martha”。但也可以是标点符号,如“,”在关系分句 — “,a senior,”中。同样,缩写“can’t”中的“ 't ”也可以被认为是一个标识,因为英语中的“ 't ”对应单词“not”。
分词器后面一个常见管道是POS标记器,它的工作是识别文本中的词性。这对于计算机理解单个标识如何在句子中发挥作用是至关重要的。我们在不同的语言中标识词性的方式是不一样的。在屈折变化的语言中(如德语)或高度屈折变化的语言中(如拉丁语或古希腊语),单词的结尾包含了很多关于它在句子中作用的信息,如主格单数或与格复数。在低屈折变化的语言中(比如英语),句子中的位置是最重要的。英语是一种名动宾(NVO)语言。让我们考虑一个例句:
The boy took the ball to the store. 男孩把球带到商店去了。
主格(主语)“boy男孩”在句子中位于前面,然后是动词“took带”,然后是宾格(宾语)“ball球”,最后是与格(间接宾语)“store商店”。“The”和“to”也包含重要的信息。" The "出现了两次告诉读者它不是泛指的球,它是特指球;同样的,商店也是一样。这个句号也告诉了我们一些重要的事情:这是一个陈述名,不是疑问句。对于以某一特定语言为母语的人来说,这些词性可能完全不会被注意到。我们凭直觉理解它们。我们中的一些人可能有记忆五级语法解析树的记忆,但在大多数情况下,我们在心理上和语言上都以一种独特的方式与母语一起发展。我们只是使用语言而无需考虑语法。对于那些花时间学习第二语言的人来说,语法是必须的(有时也是祸根)。我们学习其他语言的方式与学习母语的方式不同。对于电脑来说,也是如此。我们需要让计算机理解词性。
命名实体识别通常会在稍后的管道中出现,因为它需要接收标记化的文本,而且在某些语言中,它需要理解单词词性才能有好的表现。当文本在管道中被顺序处理时,它接收到包含有价值信息的跨区域段标签(Span),比如词性(POS)。当文本到达NER管道时,就到了让机器对单个标识(Token)做出一些结构化决策的时候。
1.4 什么是命名实体识别?
实体是文本中的单词,对应于特定类型的数据。它们可以是数字,如基数;时间,如日期;标称,如人名和地名;以及政治,如地缘政治实体(GPE)。简而言之,实体可以是设计人员希望指定为具有相应标签的文本中的任意项目。
命名实体识别(NER)是系统接受非结构化数据(文本)的输入并输出结构化数据的过程,特别是实体的识别。让我们考虑一下这个简短的例子。
大四的玛莎搬到了西班牙,她将在那里打篮球直到2022年6月5日,或者她不能再能打了。
在本例中,我们有几个潜在的实体。首先是“玛莎”。不同的NER模型对于这样的实体有不同的对应标签,但是PERSON或PER被认为是标准惯例。注意这里的标签是大写的。这也是标准的做法。我们还有一个GPE,即地缘政治实体,本例中显而易见是“西班牙”。最后,我们有一个日期实体,“2022年6月5日”。这些是可以从文本中提取的标准标签。但是,如果当前领域有额外的标签,也可以提取这些标签。也许客户机或用户不仅想要提取PERSON、GPE和DATE,而且还想提取SPORT。在这种情况下,“篮球”可以被提取出来,并被赋予SPORT这个标签。
并非所有实体都是单个标识。与文本一样,有时实体是多词标记(MWT)。让我们考虑上面的同一句话,但有稍有不同:
大四学生玛莎·汤普森(Martha Thompson)搬到了西班牙,她将在那里打篮球直到2022年6月5日,或者直到她不能再打了。
本例,玛莎现在有了姓氏“汤普森”。我们可以将玛莎和汤普森作为单独的实体提取出来,或者将二者作为单独的实体提取出来,因为“玛莎·汤普森”是一个单独的个体。因此,一个NER系统应该将“玛莎·汤普森”识别为一个单一的MWT。
随着我们学习本文和视频,我们将学习新的NER概念。现在,我建议你看下面的视频。大部分章节,都有相应的视频课。
2 spaCy简介
2.1 关键概念
- 框架
- 库
- 基于规则的NLP
- 基于机器学习NLP
- 分词
- 块
- 名词提取
- 词性识别
- 实体识别
2.2 什么是框架?
为了进行自然语言处理,研究者需首先决定使用什么框架。框架是指研究者进行特定任务所使用软件的术语。对于python,贴切的说法是将框架看作一个库,或者是打包成一组的可用类和函数,以便执行复杂任务。决定使用哪个框架取决于如下因素。
首先,并不是所有的框架都支持所有的语言,也不是所有的框架对同一语言有相同程度的支持。
第二,对于特定任务某些框架的表现要优于其他框架。虽然所有框架都能很好地分词(对英文通常如此),但对某些任务,例如通过词元化(spaCy)和词干化(Stanza)找到单词的根,其方式会有所不同。为此类目的而进行的框架抉择通常存在于计算语言学或远程阅读领域,用于发现词(或词组)如何在文本中以各种形式(动词变位和名词变格)出现的。
第三个需要考虑的因素是框架执行NLP的方式。从本质上讲,有两种执行NLP的方法:基于规则的和基于机器学习的。基于规则的自然语言处理的处理过程是框架通过一组预先确定好的规则来处理特定的任务。例如,为了在文本中查找实体,基于规则的方法将包含一个包括所有实体类型的字典,或者也可能包含正则表达式表示识别匹配实体的模式。
如今大多数框架正在从基于规则的方法向基于机器学习的方法转变。基于机器学习的自然语言处理(NLP),是开发人员利用统计数据教计算机系统(称为模型)根据过去的经验(称为训练)执行任务的过程。我们将在后面的笔记中更多地谈论基于机器学习的NLP,因为本文主题spaCy就是一个基于机器学习的Python库。
2.3 什么是spaCy?
spaCy(这个拼写是正确的)库是一个鲁棒性很强的机器学习NLP库,由位于柏林的计算机科学家和计算语言学家团队Explosion AI开发。它支持各种欧洲语言,具有开箱即用的能够解析文本、识别词性和提取实体的统计模型。SpaCy还能够轻松地改进或从头开始训练特定领域文本的自定义模型。
在本文中,我们将详细介绍安装spaCy的步骤,下载一个预先训练好的语言模型,以及执行自然语言处理的基本任务。
对于下载和安装spaCy和语言模型,未在本节讲述。请观看下面的视频并遵循必要的步骤:
https://www.youtube.com/embed/yqruv_QQctI
2.4 分句
自然语言处理的一个常见的基本任务是标记化。我们在上一节简要地介绍了标记化,其目的是将文本分解为独立的元素。这种标记化称为分词。然而标记化,还有许多其他形式,如分句。分句与分词完全相同,不同之处在于,我们不是将文本拆分为单个的单词和标点这样的元素,而是将文本拆分为单个的句子。
如果你熟悉Python,你对内置的split()函数也就不陌生,它是通过空格(默认)分割文本,或者通过传递字符串的参数来定义文本的分割位置,例如split(" . ")。一个常见的应用(在没有NLP框架的情况下)是通过简单地使用split函数将文本分割成句子,但这样处理多少有些轻率。请看下例:
text = "Martin J. Thompson is known for his writing skills. He is also good at programming."
#我们以句号来分割句子.
new = text.split(".")
print (new)
[‘Martin J’, ’ Thompson is known for his writing skills’, ’ He is also good at programming’, ‘’]
虽然我们成功地将这两句话分开,但我们在Martin J这儿得到了错误结果。原因可能很明显:在英语中,通常表示句尾和缩写都用相同的标点。原因可以追溯到中世纪早期,当时爱尔兰僧侣开始引入标点符号和空格,以便更好地阅读拉丁语(那是另一个故事)。
然而,让文本更容易阅读的东西,对于我们轻松拆分句子却带来了极大的阻碍。为此,需要寻求另外一种方法。而这便是分句发挥作用的地方。为了了解分句的不同之处,让我们从第一个spaCy的用法开始。
#首先导入spaCy
import spacy
'''
接下来我们需要加载一个NLP模型对象.
使用spacy.load() 函数.
此模型需要一个参数.
我们使用小型英文预训练模型"en_core_web_sm".
'''
nlp = spacy.load("en_core_web_sm")
'''
nlp对象创建后,我们就可以用它来解析文本了.
使用nlp()得到doc对象.
doc包含了文本中的诸多数据.
'''
doc = nlp(text)
#显示doc对象:
print (doc)
结果如下:
Martin J. Thompson is known for his writing skills. He is also good at programming.
'''
虽然这看起来和上面的text字符串没什么不同, 其实却完全不同.
我们用分句器来展示这样不同。
'''
for sent in doc.sents:
print (sent)
Martin J. Thompson is known for his writing skills.
He is also good at programming.
注意,我们已经使用了spaCy分句器来生成所需的输出:将文本正确地分解成句子。这个简单的示例表明了即使对于一个基本的任务,为什么使用一个NLP框架来执行不仅更容易,而且是必要的。为了更详细地解释这个过程,请观看下面的视频:
https://www.youtube.com/embed/ytAyCO-n8tY
2.5 命名实体识别(NER)
NLP的另一个基本任务(也是本文的主要主题),是命名实体识别(NER)。我在前面提到了NER。在这里,我将通过spaCy演示如何执行基本的NER。同样,我们将像上面那样遍历doc对象,但不是遍历doc对象本身,而是docs.ents。对于我们现在的目的,我只想打印出每个实体的文本(实体字符串本身)及其对应的标签(注意标签后面的_)。我将在接下来的两节中更详细地解释这一过程。
for ent in doc.ents:
print (ent.text, ent.label_)
Martin J. Thompson PERSON
如结果所示,一个spaCy的小型统计机器学习模型(en_core_web_sm)已经正确地识别出Martin J. Thompson是一个实体。什么样的实体?一个人(PERSON)。我们将在第以下章节中探讨它是如何做出这一决定的,我们将在其中更深入地探讨机器学习NLP。也可以以下面视频方式了解这一过程,请看下面的视频:
https://www.youtube.com/embed/lxHNsXudkrY
2.6 词性(Part-of-Speech)POS
在计算语言学领域,理解词性是至关重要的。SpaCy提供了一种简单的方法来解析文本并识别其词性。下面,我们将遍历文本中的每个标记(单词或标点),并识别其词性。
for token in doc:
print(token.text, token.pos_)
Martin PROPN
J. PROPN
Thompson PROPN
is AUX
known VERB
for ADP
his DET
writing NOUN
skills NOUN
. PUNCT
He PRON
is AUX
also ADV
good ADJ
at ADP
programming NOUN
. PUNCT
在这里,我们可以看到两个至关重要的信息:字符串和相应的词性(pos)。有关pos标签的完整列表,请参阅spaCy文档(https://spacy.io/api/annotation#pos-tagging)。然而,其中大多数应该是能够通过名称体现出来的,即PROPN是专有名词,AUX是辅助动词,ADJ是形容词,等等。关于这个过程的更多信息,请看下面的视频。
https://www.youtube.com/embed/nv0pksknFxY
2.7 抽取名词和名词块
通常在处理文本时,我们需要抽取名词和名词块。通过spaCy有几种不同的实现方法。提取名词,我们可以利用doc.noun_chunks属性。
for chunk in doc.noun_chunks:
print(chunk.text)
Martin J. Thompson
his writing skills
He
programming
注意,我们得到了一个所有名词和名词块的列表,即“He”和“programming”是名词,“Martin J. Thompson”和“his writing skills”是名词块。更多相关信息,请看下面的视频。
https://www.youtube.com/embed/aNKt1gKK8Lo
2.8 抽取动词的动词短语
通过给定RegEx预定义模式,我们可以对动词和动词短语做与名词和名词块完全相同的事情。不过这稍许复杂些,需要理解语言模式和文本库。我们将尝试找到一个特定模式的所有实例,即一个辅助动词后跟一个正常动词。
#We import textacy
import textacy
#创建词典列表模式
patterns = [{"POS": "AUX"}, {"POS": "VERB"}]
#利用textacy在doc对象中找到特定模式来创建动词短语
verb_phrases = textacy.extract.matches(doc, patterns=patterns)
#遍历 verb_phrases
for verb_phrase in verb_phrases:
print (verb_phrase)
is known
我们发现了辅助动词后跟规则动词的一个正确的例子:“is known”。更多信息,请查看下面的视频:
https://www.youtube.com/embed/VgGHwIWu-kU
2.9 词形还原
译者:对于中文并不存在词形还原,但为了保证译文的完整性,在些仍保留了这部分内容。
我想在这本节探讨的最后一个项目是词形还原。虽然有些库执行这个概念的方式有所不同,但在大多数NLP框架中,lemmmalization是一个必不可少的组成部分。而像Stanza这样的库可以找到词干,而spaCy则可以找到词元。它们在技术上有点不同,但都试图将所有的单词还原为它们的词根。为了通过spaCy查找词元,我们使用与查找词性相同的过程,即遍历doc对象中的标记。
for token in doc:
print(token.text, token.lemma_)
Martin Martin
J. J.
Thompson Thompson
is be
known know
for for
his -PRON-
writing writing
skills skill
. .
He -PRON-
is be
also also
good good
at at
programming programming
. .
注意,我们看到大多数单词保持不变,但特别要注意的是,“is”被定义为“be”,而“known”变成了“know”。这些是这些动词各自的词元。还要注意对名词的同样影响,比如复数的“skills”被简化为单数形式的“skill”。要了解更多,请看下面的视频。
https://www.youtube.com/embed/YztOLsJkC3A
3 spaCy基于规则的NER
3.1 关键概念
- 基于规则的NER
- 地名辞典
- 何时使用基于规则的NER
- 基于规则的NER的优点和局限性
- spaCy的EntityRuler
3.2 什么是基于规则的NER?
如前所述,NLP和NER有两种类型:基于规则的和基于机器学习的。本节将讲述基于规则的NER,基于机器学习的NER放到下节。
基于规则的NER,是指NLP工作者创建或利用具有一组预定义的指令或规则的NLP系统,以执行特定的NLP任务的一种方法。对于NER来说,这通常意味着使用所谓的地名辞典。地名辞典是与特定标签对齐的实体的列表或字典。在“人”(PERSON)的例子中,是一个姓和名的列表。如果你正在为某个特定地区开发NER(我们将在后面的章节中介绍),这可能是该地区所有地点的列表。
在21世纪初,有定义良好的地名辞典是执行NER的主要方法。它仍然是一些NLP框架的主要方法,如经典语言工具包(CLTK)的v.0.01,但目前正被机器学习模型所取代。
然而,有时研究者可能没有一个领域域中所有潜在名字的列表。在这些情况下,就应该使用基于模式规则的NER,进行基于规则的NLP。在这个场景中,研究者创建一组特定的模式来查找特定实体,然后假定与该模式相一致的任何东西都是需要查找的特定实体。这可以用于地名,比如德国柏林( Berlin, Germany);英格兰伦敦( London, England);德克萨斯达拉斯(Dallas, Texas)。在此场景中,可以使用字符串模式库,如RegEx(正则表达式)来查找大写单词、逗号和另一个大写单词的实例,并假定这种情况是一个位置。然而,这种方法更常见的是用于查找文本中的日期。虽然有很多方法来表示日期,但模式的数量有限。例如,如果我想表示1月1日,我们可以这样写:
- Jan 1
- 1 Jan
- Jan first
- Jan 1st
- January 1st
- January 1
- 1 January
当然可能还有其他潜在的变化,但我要强调的是,表示日期的方法数量有限。因此,通过基于规则模式的方法在文本中查找和提取时间实体通常相当容易。如果日期只以几种方式表示,问题就会变得更加简单。人们可以开发一种模式来找到数字的任何实例,后跟一个大写词或反之亦然,以此作为日期。
3.3 为什么要使用基于规则的NER?
我在前面曾提及,NLP正在从基于规则的方法转向基于机器学习的方法。你可能会想,那为什么还要学习基于规则的NLP和NER。
答案是,在某些情况下,基于规则的解决方案比基于机器学习的解决方案更好。此外,有时两者结合更加合适。理解什么时候使用哪个解决方案也非常重要,因此,对于基于机器学习的NER,基于规则的NER的坚实基础是必不可少的。
3.4 什么时候使用基于规则的NER?
一个重要的问题—什么时候应该使用基于规则的NER方法?答案很简单。当表示一个特定实体的方法有限时,因此可以用这样的规则捕获大约95-97%的方法。我说95% -97%并非是行业标准,而是因为这是我的NER模型的目标数值。如果我可以使用基于规则的方法并获得与机器学习模型相同的准确性,我很可能会这么做,因为实现基于规则的方法进行NER,时间通常比训练、验证和测试机器学习模型所花的时间要少。
正如我们将在下面的视频中看到的,当你知道语料库中每个可能的名字时,这是一个特别有用的方法,比如我们将看到哈利波特的例子(仅为展示)。
3.5 基于规则的NER的局限性
要牢记:基于规则的方法仅仅是基于规则的。如果一个实体不符合你的规则,那么它将不会被标记为一个实体。这在OCR文档、未检查拼写、未编辑或任何形式的未清理的文本中尤为普遍。
虽然清理文本是NLP适当数据准备的重要组成部分,但有时不可能完全清理文本,有时,使用特定NER框架的人可能不知道如何清理文本。这是基于规则的方法的主要局限性,也是当下研究者使用机器学习方法的主要原因之一。对于全新数据,尽管(在某种程度上)与训练样本存在差异,但机器学习模型可以学习并泛化到全新数据。我们将在下节更详细地探讨这一点。
3.6 spaCy的EntityRuler
虽然spaCy主要是作为一个机器学习的NLP库,但它具有使用基于规则的NER方法的能力。这是该库的一个主要优势。因为我们将看到,为了为专业领域开发一个强大的NER系统,基于规则和基于机器学习的方法的结合有时是必不可少的。
尽管spaCy存在几种基于规则的NER方法,但最基本的一种是它的EntityRuler。
让我们回到第1节关于篮球运动员玛莎的例子。在此场景中,我们不仅希望从文本中提取普通实体(PERSON、DATE等),还希望提取一个新的实体SPORT。在后面的章节中,我们将更详细地讨论添加自定义实体。现在,我们将使用这个简单的示例来演示基于规则的NER是如何工作的。
text = "Martha, a senior, moved to Spain where she will be playing basketball until 05 June 2022 or until she can't play any longer."
#Import spacy
import spacy
#创建一个空的spaCy模型将用它来解析英文("en")
nlp = spacy.blank("en")
#创建一个ruler,它将被加到模型上
ruler = nlp.create_pipe("entity_ruler")
#定义一个查找模式并加入ruler
ruler.add_patterns([{"label": "SPORT", "pattern": "basketball"}])
#把ruler加入到模型管道中
nlp.add_pipe(ruler)
#用新的nlp处理文本并得到doc对象
doc = nlp(text)
#遍历所有实体(将得到新实体)
for ent in doc.ents:
print (ent.text, ent.label_)
basketball SPORT
3.7 练习
我们看到输出与期望的一样。我们已经提取了篮球(basketball)字符串和它的正确标签SPORT。如果你不完全理解上面的代码是如何工作的,也不要担心。在本文结束后,就知道了。现在,只需理解基于规则的NER是如何工作的。尝试上面的代码,并尝试创建一个模型,可以在下面的文本中识别足球作为一项运动:
text = "Scott enjoys to play soccer."
#复制上面的代码找到 soccer 及其标签 SPORT
3.8 基于规则的NER视频
完成上述练习后,观看下面关于基于规则的NER的视频。它强化了这些概念,并以哈利波特的第一部作为更大的语料,进行更加深入地探索。
https://www.youtube.com/embed/O_2uq0sdCQo
4 spaCy基于机器学习的NER
4.1 关键概念
- 机器学习
- 统计
- 线性代数
- 矩阵
- 向量
- 张量
- 词嵌入(词向量)
- 机器学习训练、验证和测试
- spaCy模型
4.2 什么是机器学习?
机器学习是人工智能的一个分支。为了理解人工智能以及现代机器学习与它的前身有何不同,请看我关于这个主题的视频(我的系列视频----Machine Learning for DH. 其中关于机器学习的一个短片)。
https://www.youtube.com/embed/G6cW5JybUPU
机器学习(和深度学习)是人们教计算机系统学会用统计和线性代数(而非规则)执行任务的过程,这样系统就可以从重复的(随机的)经验中学习。如果现在还不明白的话,等你看完本文就明白了。本节必须要包含一些数学知识,但它将被保持在绝对的最低限度。我将只介绍绝对必要的数学和数学概念。
在继续之前,我同样推荐我的关于深度学习的短片(我的系列视频----Neural Networks for DH.)
https://www.youtube.com/embed/G0hvxnb7hHM
4.3 机器学习的类型
机器学习有以下几种不同的类型:监督学习、非监督学习和半监督学习。还有其他形式(如强化学习),但这三种是其基本形式。
监督学习是指我们用已知的数据训练来系统。在NER的情况下,我们使用一系列文本来训练系统,这些文本的实体用相应的标签进行了适当的注释。无监督学习是指当你不知道数据的类别时,向系统提供一系列数据,并允许它自行学习和识别模式。这种方法最常用于主题建模和k-means(这些超出本文的范围)。最后是介于两者之间的半监督学习。
在本文中,我们将使用监督学习,因此,我想从头到尾完整说明这个过程,然后解释它是如何工作的。
4.4 NER中的监督学习
如上所述,监督学习是系统从一组已知标签的输入中进行学习的过程。为了进行正确的训练模型,我们将输入数据分为三类:训练数据、验证数据和测试数据。各类数据并没有没有固定的比例。然而,一个好的经验法则是,将所有注释数据的20%的用于测试,然后将剩下的80%以80/20的比例用于(训练/验证)。
前两种数据,训练数据和验证数据,训练模型。它利用训练数据通过预先确定的算法来打磨统计模型。通过预测正确的标签与提供的标签比较,检查其准确性,并做出相应的调整。
所有训练数据的查看与预测完成后,就完成了第一个epoch(数据迭代)。在这个阶段,模型然后根据验证数据测试其准确性。这些数据被排除在训练过程之外,让系统对其整体表现有一个感受。
因为验证数据不在训练过程中,所以它可以用于训练中测试(或验证)其准确性。然后,训练数据被随机化,并epoch次送回系统。同样,没有一个标准来衡量epoch的数值,但是一个好的经验法则是从10开始,看看结果。
一旦模型将这个过程重复到epoch次,它就完成了训练。然后,可以针对测试数据集测试模型的准确性,看看它的性能如何。希望将测试数据与验证数据分开的原因是,尽管一些验证数据没有包含在培训中,但它们渗透到训练过程中。因为测试数据有很好的注释,研究者可以得到模型执行情况的准确感受。
保存了第一个模型后,通常的做法是多次调整模型的参数,以尝试创建更精确的模型。所有的模型都将根据相同的测试数据进行测试。
在这一阶段,根据结果,可能需要获得更多的训练数据,可能需要进行另一个测试,或者研究者可以开始在未见的数据上部署模型并检查结果。未见的数据将是没有注释的数据。
下面的图片很好的描述了这一过程。在图像中,我们看到原始数据输入到算法。
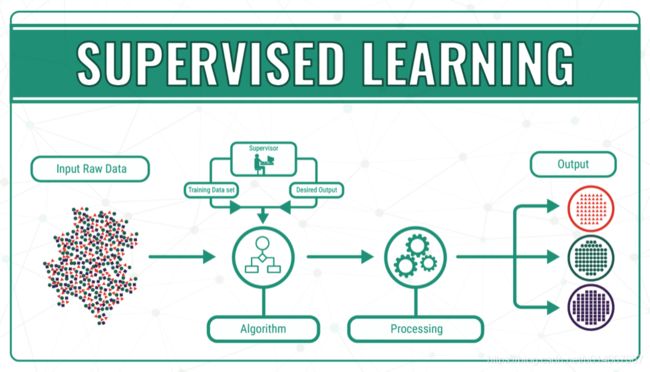
4.5 监督学习是如何工作的(注意:数学!)
正如标题所示,本节将探索数学领域,特别是统计和线性代数。即使你不是数学迷,也请阅读这一节,因为它包含了机器学习背后的基本原理。为了简单解释机器学习是如何工作的(更重要的是为什么),我将尽量减少数学运算。这将让你更好地了解何时使用机器学习方法来进行NER,以及为什么你可能得不到你想要看到的结果,以及如何改进。
监督学习背后的核心概念是统计模型,这是一个可保存和可应用的系统,给定输入(文本)其输出某种结构化数据(实体的标签)。为了理解什么是模型以及它们是如何工作的,我建议看看下面的短视频:
https://www.youtube.com/embed/I9Nl8QIIP54
通过spaCy,NLP工作者不必沉溺于枯燥的神经网络结构。而是利用由spaCy开发的最先进的神经网络架构,只需几行代码就可以轻松地训练spaCy模型。如果你对训练过程是如何工作的感到好奇,我推荐下面的视频:
https://www.youtube.com/embed/s8yQ4lRrEIY
4.6 何时使用机器学习NER?
上节我解释了何时使用基于规则的NER。当你在一个语料库不能列出所有多变的实体,或创建这样的模式过于复杂,相较其准确性不值得时,机器学习就很有用。一个很好的例子就是一个人名字的每一种可能的变化。考虑一下世界上存在的大量人名,以及这些人名的各种组合,它们可以组合成一个独特的实体。即使我们只有1万个姓和1万个名,也需要1亿个模式来匹配所有的变体。世界上姓和名的数量都远不止1万个。
另一种考虑机器学习的情况是,当输入到你的系统的数据不会被完全清理。再次考虑名字的例子。即使你的系统能够处理这些名称的所有1亿种形式,它也会遗漏那些OCR质量较差或具有不同文本编码的名称,因为它是在UTF-8之前创建的文本。
在这些情况下,机器学习是正确的选择,因为机器学习模型不记忆实体。它是学习实体。这意味着,如果一个模型遇到了一个它以前从未见过的实体(即使是错误的),它也有能力用正确的标签泛化和识别这个实体。
4.7 使用spaCy的机器学习模型
所幸正如我们将在本系列中看到的,spaCy不仅使使用机器学习模型变得容易,而且大大降低了训练定制机器学习器模型的复杂性。
#加载库
import spacy
#加载预训练模型
nlp = spacy.load("en_core_web_sm")
#给定文本
text = "Jon Stewart hosted The Daily Show that aired in New York City."
#创建doc
doc = nlp(text)
#从doc中抽取所有实体和相应标签
for ent in doc.ents:
print (ent.text, ent.label_)
Jon Stewart PERSON
The Daily Show WORK_OF_ART
New York City GPE
在上面的例子中,我们看到这小型的英文模型正确地识别了约翰·斯图尔特的身份。它认为《每日秀》是一个有趣的艺术作品,真的是这样的。最后,它正确地将纽约市确定为GPE(地缘政治实体)。现在,让我们引入一些文本损坏问题,以了解模型是如何执行的。
#加载库
import spacy
#加载预训练模型
nlp = spacy.load("en_core_web_sm")
#create a sample text
text = "Jon Stewwasrt hosted The Daily Show that aired in New Yasdfasasdfrk City."
#创建doc
doc = nlp(text)
#从doc中抽取所有实体和相应标签
for ent in doc.ents:
print (ent.text, ent.label_)
Jon Stewwasrt PERSON
The Daily Show WORK_OF_ART
New Yasdfasasdfrk City GPE
请注意,尽管引入了文本损坏,但模型的执行方式完全相同。为什么呢?因为它是从上下文中学习的。它可能以前见过“主持”(hosted)这个词,知道通常是人来主持。它也看到大写的City这个词经常被用来描述GPE。这也就是为什么机器学习能够为不一致的实体或如此数量庞大的实体提供解决方案,但将它们全部合并到一个EntityRuler则是不可能的。
4.8 练习
在以上的代码中,我们尝试了一个小的预训练英语模型。据你所学进行一些猜想:尽管引入了文本损坏,但模型为什么会成功或错误地标识出实体?当你这样做时,请记住这是一个小模型。较大的模型性能更好,其原因我们将在本系列的后面讨论。
4.9 机器学习NER视频
https://www.youtube.com/embed/2Ny0yATnuxY
二 NER训练基础
1.1 关键概念
- 管件
- 工厂
- EntityRuler
- PhraseMatcher
- 匹配器
1.2 spacy的EntityRuler简介
Python库spaCy为进行基于规则的NER提供了几种不同的方法。其中一种方法是通过它的EntityRuler。
EntityRuler是一个spaCy工厂,允许创建一组带有相应标签的模式。spaCy中的工厂是一组预加载在spaCy中的类和函数,它们用来执行设置任务。对于EntityRuler,随时可用的工厂允许用户创建EntityRuler,给它一组指令,然后使用该指令来发现和标记实体。
一旦用户创建了EntityRuler并给它一组指令,用户就可以将其作为新管道添加到spaCy管道中。我已经在以前的章节中简要地讲过管道,这里将更加详细地说明对其进行说明。
管件是管道的一个组件。管道的目的是获取输入数据,对输入数据执行某种操作,然后将这些操作输出为新数据或提取的元数据。管件是管道的单个组件。在spaCy中,有几个不同的管件执行不同的任务。分词器,将文本标记为单个词标记;解析器解析文本,NER识别实体并相应地标记它们。所有这些数据都存储在Doc对象中,正如我们在本文的01_02中看到的那样。
记住管道是有顺序的非常重要。这意味着管道中较前的组件会影响后来的组件接收到的内容。有时,这个顺序非常重要,这意味着以后的管件依赖于以前的管件。某些情况下,这个顺序则不是必需的,这意味着以后的管道可以在没有以前的管道的情况下运行。在创建自定义spaCy模型(或任何管道)时,务必记住这一点。
在本文中,我们将密切关注EntityRuler作为一个spaCy模型管道的组件。现成的spaCy模型预装了一个NER模型;然而,他们中并没有一个真正的EntityRuler。为了将一个EntityRuler合并到一个spaCy模型中,它必须被创建为一个新的管件,给出指令,然后添加到模型中。这些工作完成后,用户可以将带有EntityRuler的新模型保存到磁盘上。
spaCy EntityRuler的完整文档可以在这里找到:https://spacy.io/api/entityruler
本文为非专业人士摘录了此文档,并提供了一些实际应用中的例子。
1.3 EntityRuler演示实例
在下面的代码中,我们将在spaCy现成的小型英语模型中引入一个新管件。这个EntityRuler的目的是正确地识别波兰的小村庄。
#导入所需库
import spacy
#加载预训练模型
nlp = spacy.load("en_core_web_sm")
#示例文本
text = "Treblinka is a small village in Poland. Treblinka was also an extermination camp."
#创建doc
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.label_)
Treblinka ORG
Poland GPE
Treblinka PERSON
从以上代码的结果可以看出,spaCy的小模型无法正确识别波兰的一个小村庄特雷布林卡(Treblinka)。正如示例文本所示,它在二战期间也是一个灭绝营。在第一句中,spaCy模型将特雷布林卡标记为组织,在第二句中将其标记为人。两者都是错误的。第二句话我会接受ORG,因为spaCy的模型不知道如何对一个灭绝营进行分类,但这些结果表明该模型未能根据数据进行泛化。为什么呢?原因有几个,但我怀疑这个模型从来没有遇到过“特雷布林卡”这个词。
在特定领域的自然语言处理中这是常见的问题。通常情况下,对于特定领域,现成的模型会失败,因为它们没有接受过领域特定文本的训练。然而,我们可以通过spaCy的EntityRuler或训练一个新模型来解决这个问题。我们将在接下来的几节中看到,可以使用spaCy的EntityRuler轻松实现这两个目标。
现在,让我们先纠正这个问题,为模型提供正确识别特雷布林卡的指令。为简单起见,我们将使用spaCy的GPE标签。在以后的章节中,我们将教模型,在后面的上下文中将特雷布林卡识别为集中营。
#导入所需库
import spacy
#加载预训练模型
nlp = spacy.load("en_core_web_sm")
#示例文本
text = "Treblinka is a small village in Poland. Treblinka was also an extermination camp."
#创建EntityRuler
ruler = nlp.create_pipe("entity_ruler")
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
#给ruler添加模式
ruler.add_patterns(patterns)
#在"ner"管件之前给模型添加ruler
nlp.add_pipe(ruler, before="ner")
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.label_)
Treblinka GPE
Poland GPE
Treblinka GPE
现在请注意,我们的EntityRuler在“ner”管件之前运行,因此,在NER到达之前预先查找到了实体并标记了它们。因为它在管道中出现得较早,所以它的元数据优先于后面的“ner”管件。另一种选择是将EntityRuler保留在管道的末端,并赋予它覆盖" ner "管件的能力:
#导入所需库
import spacy
#加载预训练模型
nlp = spacy.load("en_core_web_sm")
#示例文本
text = "Treblinka is a small village in Poland. Treblinka was also an extermination camp."
#导入spaCy EntityRuler class
from spacy.pipeline import EntityRuler
#创建EntityRuler,并置为覆盖模式
ruler = EntityRuler(nlp, overwrite_ents=True)
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
#给EntityRuler添加模式
ruler.add_patterns(patterns)
#将EntityRuler加入管道
nlp.add_pipe(ruler)
#创建doc
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.label_)
Treblinka GPE
Poland GPE
Treblinka GPE
1.4 向EntityRuler引入复杂的规则和变体(高级)
在某些情况下,标签可能有一组不同类型的变体,这些变体遵循一个或一组不同的模式。电话号码就是一个这样的例子(spaCy文档中)。在美国,电话号码有几种形式。标准的形式化方法是(xxx)-xxx-xxxx,但经常会看到xxx-xxx-xxxx或xxxxxxxxxx。如果机主将相同的号码提供给美国以外的人,那么则变为+1(xxx)-xxx-xxxx。
对于美国这一特定领域,则可以将RegEx公式传递给模式匹配器以获取所有这些实例。
通过将规则传递给模式,spaCy EntityRuler还允许用户引入各种复杂的规则和变体(通过RegEx)。有许多参数可以传递给模式。有关完整列表,请参见: https://spacy.io/usage/rule-based-matching 。体验其如何工作,我建议使用 spaCy Matcher演示:https://explosion.ai/demos/matcher。
在下面的示例中,我们将使用spaCy文档的中一个示例,其中我们从文本中提取了一个电话号码。当然,同样的任务也可以通过RegEx完成。
#导入所需库
import spacy
#创建一个空白英文模型
nlp = spacy.blank("en")
#示例文本
text = "This is a sample number (555) 555-5555."
#导入spaCy EntityRuler class
from spacy.pipeline import EntityRuler
#创建EntityRuler,并置为覆盖模式
ruler = EntityRuler(nlp, overwrite_ents=True)
#实体和模式列表 (source: https://spacy.io/usage/rule-based-matching)
patterns = [
{"label": "PHONE_NUMBER", "pattern": [{"ORTH": "("}, {"SHAPE": "ddd"}, {"ORTH": ")"}, {"SHAPE": "ddd"},
{"ORTH": "-", "OP": "?"}, {"SHAPE": "dddd"}]}
]
#给EntityRuler添加模式
ruler.add_patterns(patterns)
#将EntityRuler加入管道
nlp.add_pipe(ruler)
#创建doc
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.label_)
(555) 555-5555 PHONE_NUMBER
1.5 spaCy中其他基于匹配的技术
在spaCy中还有另外两个基于规则的方法:Matcher和PhraseMatcher。虽然这些函数与EntityRuler类似,但它们没有将这些匹配项标识为实体,而是提供了它们自己的惟一标签和id,其超出了Doc对象中实体的范围。
1.6 练习
在本节中,尝试开发一个定制EntityRuler来在你自己领域的特定文本中找到一个自定义实体。
1.7 视频
以下视频,我们将探索spaCy的EntityRuler的实体用例,在《哈利·波特》第一册中寻找哈利·波特角色。
https://www.youtube.com/embed/wpyCzodvO3A
2 用EntityRuler创建训练集
2.1 关键概念
- 训练集(training sets)
- start_char
- end_char
- 生成训练集
2.2 训练集简介
在本节中,我们将更加仔细地观察训练集,它们是什么,它们为什么重要,以及如何使用spaCy的EntityRuler来自动创建一个良好的训练数据集(太好了!),此数据集需要手动检查。在下一个视频中,我将向你展示如何使用此训练集在spaCy中训练自定义的NER模型。
spaCy的一个优点是,它的可伸缩性非常好(这意味着它可以在小数据和大数据上表现同样良好),它可以很容易地定制和运用高级机器学习方法,而几乎不需要机器学习知识。然而,如本文的第3节所述,理解机器学习的基础知识会很有帮助,因为它将使你了解如何创建一个良好的训练集,以及为什么某些方法可能会失败或陷入困境。事实上,通过简单的操作,你将对在机器学习NER中,某些方法是否有效产生感觉。
在本文的第3节,曾提到用于训练机器学习模型的数据有三种形式:训练数据、验证数据和测试数据。所有这些数据将采用相同的形式。它将是一个列表数据结构,其中每个索引将包含一个文本(一个句子、段落或整个文本)。文本的长度将取决于你希望通过ML-NER实现的目标。文本的大小会影响训练过程。不过,在此我们先忽略这一点。训练数据需要的另一个元素是该文本中实体的列表,包括它们在文本中的开始位置、结束位置和标签。在训练过程中,这些注释将允许卷积神经网络(spaCy机器学习训练过程背后的体系结构)从数据中学习,并能够正确识别正在训练的实体。
2.3 spaCy训练集的数据样式
SpaCy严格要求你的训练数据以一种特定的形式出现:
TRAIN_DATA = [ (TEXT AS A STRING, {“entities”: [(START, END, LABEL)]}) ]
请注意,TRAIN_DATA是大写的。除了少数例外,python是不大写对象的, TRAIN_DATA即是一个例外。我不知道这个惯例的历史,但是在每本书或教程中,你总会看到TRAIN_DATA是这样的。当然,这是也并非必要,但是在你的代码中尽可能的使用Pythonic总归是一个好作法,这样其他人就可以更容易地阅读你的代码。任何机器学习工作者都希望看到TRAIN_DATA以这种形式呈现。
手工将训练数据转换成这种格式非常困难。研究人员必须计算字符数来指定实体的开始和结束位置。即使使用Python内置的字符串函数来获取起始字符和结束字符,也会遇到另一个问题。spaCy的训练过程读取起始字符和结束字符的方式与使用字符串函数计算字符位置的方式不同。这意味着在训练过程中,spaCy将删除与标记开始和结束位置不一致的标注。这是因为字符串函数对文本分词的方式与spaCy不同。幸运的是,有一些通过EntityRuler内置于spaCy中的方法,能够帮助你完成这一过程。
如果你对手工注释感兴趣,我强烈建议你去试一下Explosion AI的付费软件Prodigy (https://prodi.gy/)。我不会因为推销那种产品而得到报酬的。它很昂贵,但是如果你需要做很多注释(对于图像、文本、视频,甚至音频),那么Prodigy就是你的理想选择。它有一个很友好的用户界面,因为它是由spaCy的同一个团队开发的,它可以无缝地融入spaCy工作流程。你可以在这里测试Prodigy演示:https://prodi.gy/demo。
2.4 创建一个训练集
在下面的代码中,我们将通过EntityRuler制作一个spaCy的机器学习训练集。换句话说,我们将使用基于规则的方法自动生成一个基本训练集。这个训练集会不会有错误?很有可能。这就是为什么要查看训练集并手动验证。然而,通过这种方式,可以大幅增进原型设计,以确定想要训练的定制实体是否具有潜在可行性。在机器学习中,对于特定领域的问题很少有固定的解决方案。如果有的话,就不需要专家了。不断尝试和实验通常是机器学习这种项目的代名词,NER机器学习也一样。
因为我们将暂时只使用此模型,因此创建一个空白英文模型。我们不需要其他组件。这个模型只有一个EntityRuler,我们将临时使用它来生成训练集。回想在上一节中,spaCy小型模型无法正确识别Treblinka作为位置。在下面的代码中,我们将从这三个句子中创建一个基本的训练集,这是一个非常小的训练集。在此声明:这些训练数据远不足以训练一个模型。但其可以很好地扩展。
这里的代码与我们之前看到的相同,但示例文本略有不同。注意它的输出:其正确地将Treblinka识别为GPE。
#导入所需库
import spacy
#创建一个空白英文模型
nlp = spacy.blank("en")
#示例文本
text = "Treblinka is a small village in Poland. Wikipedia notes that Treblinka is not large."
#创建EntityRuler
ruler = nlp.create_pipe("entity_ruler")
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.label_)
Treblinka GPE
Treblinka GPE
现在,我们稍微修改一下这段代码,使其生成一个稍微不同的输出结果,此输出带有文本开头和结尾信息。
#导入所需库
import spacy
#创建一个空白英文模型
nlp = spacy.blank("en")
#示例文本
text = "Treblinka is a small village in Poland. Wikipedia notes that Treblinka is not large."
#创建EntityRuler
ruler = nlp.create_pipe("entity_ruler")
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
doc = nlp(text)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
Treblinka 0 9 GPE
Treblinka 61 70 GPE
注意,现在我们的输出分别用0,9和61,70表示每个实体的开始和结束位置。有了这些数据,我们就可以开始生成我们想要的输出。我们先试着把输入的文本分解成句子,然后得到两组不同的训练数据。
#导入所需库
import spacy
#创建一个空白英文模型
nlp = spacy.blank("en")
#示例文本
text = "Treblinka is a small village in Poland. Wikipedia notes that Treblinka is not large."
#创建EntityRuler
ruler = nlp.create_pipe("entity_ruler")
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
#遍历句子
for sentence in corpus:
doc = nlp(sentence)
#抽取实体
for ent in doc.ents:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
[‘Treblinka is a small village in Poland.’, ‘Wikipedia notes that Treblinka is not large.’]
Treblinka 0 9 GPE
Treblinka 21 30 GPE
注意,输出和开头和结尾都发生了变化。现在,我们可以再次修改我们的代码,使其成为我们想要的格式:
TRAIN_DATA = [ (TEXT AS A STRING, {“entities”: [(START, END, LABEL)]}) ]
#导入所需库
import spacy
#创建一个空白英文模型
nlp = spacy.blank("en")
#示例文本
text = "Treblinka is a small village in Poland. Wikipedia notes that Treblinka is not large."
#创建EntityRuler
ruler = nlp.create_pipe("entity_ruler")
#实体和模式列表
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
TRAIN_DATA = []
#遍历句子
for sentence in corpus:
doc = nlp(sentence)
entities = []
#抽取实体
for ent in doc.ents:
#以要求的格式追加到entities
entities.append([ent.start_char, ent.end_char, ent.label_])
TRAIN_DATA.append([sentence, {"entities": entities}])
print (TRAIN_DATA)
[[‘Treblinka is a small village in Poland.’, {‘entities’: [[0, 9, ‘GPE’]]}], [‘Wikipedia notes that Treblinka is not large.’, {‘entities’: [[21, 30, ‘GPE’]]}]]
2.5 练习
在这段视频里的练习中,用自己熟悉的语料库试着复制这个过程。制定一系列规则标识出想要标识的几个或多个实体。不必想着把他们都找出来。这样做的目的是生成一个足够好的训练集,具有足够的多样性,以便在下一节中训练机器学习模型。在下面的视频中,我将展示如何使用哈利波特第一册中的角色在更大语料范围内生成训练集。
2.6 视频
https://www.youtube.com/embed/YBRF7tq1V-Q
3 如何训练spaCy模型
3.1 关键概念
- 用spaCy的训练过程
3.2 spaCy训练机器学习模型简介
上节我们使用spaCy的EntityRuler为机器学习模型创建了一个基本训练集。这个训练集是我们通过假设实体很可能或肯定会属于某个特定标签得到的。从本质上讲,这种生成训练集的方法是有问题的。它会遗漏一些实体,并错误地标记其他实体。若要将此数据集作为用于训练最终模型的基本训练集,建议手动检查。如若使用此模型作为基线模型,以便通过Prodigy生成更好的训练集,那么此方法也是有效的。
本节我们并不关注提高这个训练集准确性,而是使用它来训练一个自定义的spaCy机器学习NER模型。主要关注的是方法,而非结果。
在第3节中,我们首次接触了机器学习以及它的一些基础知识。如果你还没有看过那一节及其中的视频,建议你在继续学习本节之前先看一下,以下内容假定你对机器学习已经有了基本的了解。
与其他NLP框架相比,我更喜欢spaCy的原因是spaCy能够很好地扩展(在小数据集和大数据集上都可以工作)以及简便易用的训练过程。NER工作者不必通过PyTorch/FastAI或TensorFlow/Keras创建一个定制的神经网络,虽然它们也是一些易用的框架,但其都有一个陡峭的学习曲线。相反,spaCy的用户可以利用spaCy训练过程背后预先设计的CNN架构。在spaCy的3.0版本中(在编写本文时,nightly版本已经可用),预计在2021年初,用户还可以定制这种神经网络架构,扩展spaCy的实用性和可定制性。
使用spaCy训练过程,用户只需了解一些基本概念,例如数据应该以何种格式如何输入训练过程(在上节已介绍)和一些超参数的作用(我们在训练过程中调整的内容,以尝试找到最佳结果)。
3.3 准备数据
如上节所述,输入数据应采用以下格式:
TRAIN_DATA = [ (TEXT AS A STRING, {“entities”: [(START, END, LABEL)]}) ]
首先,让我们用上段视频中的代码来生成我们的训练数据:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Treblinka is a small village in Poland. Wikipedia notes that Treblinka is not large."
corpus = []
doc = nlp(text)
for sent in doc.sents:
corpus.append(sent.text)
nlp = spacy.blank("en")
ruler = nlp.create_pipe("entity_ruler")
patterns = [
{"label": "GPE", "pattern": "Treblinka"}
]
ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
TRAIN_DATA = []
for sentence in corpus:
doc = nlp(sentence)
entities = []
for ent in doc.ents:
entities.append([ent.start_char, ent.end_char, ent.label_])
TRAIN_DATA.append([sentence, {"entities": entities}])
print (TRAIN_DATA)
[[‘Treblinka is a small village in Poland.’, {‘entities’: [[0, 9, ‘GPE’]]}], [‘Wikipedia notes that Treblinka is not large.’, {‘entities’: [[21, 30, ‘GPE’]]}]]
3.4 训练一个spaCy模型
我发现创建一个可以在不同脚本中可重用的函数是方便的方法。下面我使用的boiler plate函数。这是spaCy文档中的,好些地方都有它,包括TowardsDataScience(一个关于数据科学的好博客,有来自不同作者的文章)和Medium。此函数包含两个参数:训练数据和迭代次数。
import random
def train_spacy(TRAIN_DATA, iterations):
#创建一个空白英文模型
nlp = spacy.blank("en")
#若没有则添加NER组件
if "ner" not in nlp.pipe_names:
ner = nlp.create_pipe("ner")
nlp.add_pipe(ner, last=True)
#添加所有实体标签到spaCy模型
for _, annotations in TRAIN_DATA:
for ent in annotations.get("entities"):
ner.add_label(ent[2])
#获取模型中除了NER之外的其他管件
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != "ner"]
#开始训练
#消除其他管件的影响
with nlp.disable_pipes(*other_pipes):
optimizer = nlp.begin_training()
for itn in range(iterations):
print ("Starting iteration " + str(itn))
random.shuffle(TRAIN_DATA)
losses = {}
for text, annotations in TRAIN_DATA:
nlp.update(
[text],
[annotations],
drop=0.2,
sgd=optimizer,
losses=losses
)
print
return (nlp)
#运行函数并创建训练好的模型
trained_nlp = train_spacy(TRAIN_DATA, 10)
在上面的代码中,我们看到spaCy模型在只有两句话的非常小的训练集上进行训练。为了演示这是如何工作的,现在尝试在一个示例句子上使用我们的模型。
text = "The village of Treblinka is located in Poland."
doc = trained_nlp(text)
for ent in doc.ents:
print (ent.text, ent.label_)
Treblinka GPE
注意,我们给机器学习模型NER一个新句子,它正确地将Treblinka识别为“GPE”。但也不要过于激动。对示例文本的微小更改,就会导致丢失实体。
text = "Mark, from New York, said that he wants to go to Treblinka to speak to the locals."
doc = trained_nlp(text)
for ent in doc.ents:
print (ent.text, ent.label_)
if len(doc.ents) == 0:
print ("No entities found.")
No entities found.
现在我们的模型为什么失败了?因为我们训练了一个机器学习模型,而不是一个完整的规则。它知道Treblinka是一个GPE,但它只学会在某些情况下识别它。这些上下文包括诸如village、Wikipedia等词。当我们提供更多训练数据时,机器学习模型会得到极大地改进。数量更多、类型更多样的训练数据,会更加有利于模型性能的提升。
3.5 如何改进上述模型
那么,我们该如何改进这个模型呢?答案是生成更多的训练数据。说起来简单,做到却没那么在某些情况下,可能需要引入数据扩充(将在后面的章节中讨论)。
3.6 练习
本节练习,尝试生成大量的训练数据,并将其输入spaCy模型,然后在新的、未见的文本上测试该模型。观察其表现。
3.7 视频
我匆匆忙忙地完成了本节内容,几乎没有什么解释。原因是此类内容视频形式更容易表达。请看下面的视频,我们以哈利波特第一册中人物为例,在更大语料上执行类似的任务。
https://www.youtube.com/embed/7Z1imsp6g10
三 高级NER概念
1 考察一个spaCy模型文件夹
1.1 关键概念
在文件夹级别来考察spaCy模型的内部细节
1.2 简介
本节真的很重要,却很难以文字形式呈现。如果有好的建议,请告知,我会更新本节。
我录制了一个涵盖此主题的视频。首先我承认这个视频是相当枯燥的,但对于如何理解在这个视频中讨论的概念,如何强调其重要性都不过分。了解spaCy模型如何工作对于自定义spaCy模型至关重要。
1.3 视频
https://www.youtube.com/embed/cuUf2H6uCA8
2 词向量简介
2.1 关键概念
- 词向量(词嵌入)
- 矩阵
- 二元分词和三元分词(Bigrams Trigrams)
- 词袋(Bag of Words)
2.2 阅读之前
在你开始阅读之前,咱们来做这样一件事。提到“集中营”这个词,它能唤起什么概念。首先想到的前几个词是什么,写下一些你想到的专有名词。
2.3 用数字表示文本的需求
词向量(或词嵌入),是单词在多维空间中的矩阵数值表示。词向量的目的是让计算机系统理解词。尽管计算机不能有效地理解文本,但其可以快速而准确地处理数字。因此,把一个单词转换成数字是很重要的。
在管道中创建词向量的初始方法是将语料库中的所有词转换成一个唯一的数字。这些词被存储在一个字典里,如:{“the”:1,“a”,2}等等,这就是所谓的词袋。然而,这种用数字表示词的方法只是让计算机用数字来理解词,区分词。然而,计算机并不理解词表达的意义。
比如以下场景:
Tom loves to eat chocolate.
Tom likes to eat chocolate.
这两个句子用数组(数字列表)表示如下:
1, 2, 3, 4, 5
1, 6, 3, 4, 5
如上例所示,对于人,这两句话几乎是一样的。唯一的区别是汤姆喜欢吃巧克力的程度。然而,如果我们考察数字,这两句话似乎很接近,但却不能从语义上得出确定答案。2和6有多相似?数字6可以表示“恨”,也可以表示“喜欢”。这就是为什么要引入词向量。
如上所述,词向量对这些一维词袋,通过在更高维空间中对词的表示,赋予它们多维意义。这是通过机器学习实现的,并且可以通过Python库(比如Gensim)轻松实现,我们将在下节更详细地探讨Gensim。
2.4 为什么要使用词向量?
词向量的目标是实现对语言的数字理解,以便计算机能够在该语料库上执行更复杂的任务。我们考虑上面的例子。我们如何让计算机理解2和6是同义词或是类似的意思?你可能会想的一个选择是给计算机一本同义词词典。它可以查找同义词,然后知道单词的意思。从表面上看,这种方法非常有意义,但我们探讨一下这个做法,看看为什么它不可能奏效。
下例,我们将使用Python库PyDictionary,它允许我们查找单词的定义和同义词。
from PyDictionary import PyDictionary
dictionary=PyDictionary()
text = "Tom loves to eat chocolate"
words = text.split()
for word in words:
syns = dictionary.synonym(word)
print (f"{word}: {syns[0:5]}\n")
结果:
Tom: ['Felis domesticus', 'tomcat', 'domestic cat', 'gib', 'house cat']
loves: ['amorousness', 'caring', 'lovingness', 'agape', 'adoration']
to: ['digitizer', 'data converter', 'digitiser', 'analog-digital converter']
eat: ['consume', 'garbage down', 'eat up', 'gluttonize', 'take in']
chocolate: ['drinking chocolate', 'drink', 'drinkable', 'potable', 'beverage']
如此简单的句子,结果也很糟糕。为什么呢?这是因为同义词替换是一种常用的数据扩充方法,它没有考虑同义词的句法差异。我不相信有人会认为“Felis domesticus”(一个普通家养猫的拉丁名字),会完全取代汤姆这个名字。“garbage down”也不是“eat”的真正同义词。
或许,我们可以使用同义词来查找具有交叉词的词,或者出现在两个同义词集的词。
from PyDictionary import PyDictionary
dictionary=PyDictionary()
words = ["like", "love"]
for word in words:
syns = dictionary.synonym(word)
print (f"{word}: {syns[0:5]}\n")
结果:
like: ['love', 'prefer', 'enjoy', 'cotton', 'care for']
love: ['amorousness', 'caring', 'lovingness', 'agape', 'adoration']
正如我们所看到的,这样还是有一些潜力的,但它仍然不是完全可靠的,并且这样一个列表将耗费大量算力。出于这两个原因,词向量应是首选方式。因为它们是由计算机在语料库上为特定的任务而生成的。此外,它们本质上是数字的(不是词典),这意味着计算机可以更快地处理它们。
2.5 词向量格式
词向量的维度数是预先定义好的。这种多维数据是通过机器学习得到的。模型考虑了语料库中词的出现频率以及相似上下文中出现的其他词。这使得计算机能够以数字方式确定词的句法相似性,并以数字来表示这些关系。这些是通过向量或矩阵来实现的。为了更简洁地表示,模型将矩阵展开为浮点数向量(十进制数)。维数即矩阵中浮点数个数。
下面的预训练模型是关于大屠杀语料输出的词向量。“know”这个词在向量中看起来是这样的:
know -0.19911548 -0.27387282 0.04241912 -0.58703226 0.16149549 -0.08585547 -0.10403373 -0.112367705 -0.28902963 -0.42949626 0.051096343 -0.04708015 -0.051914077 -0.010533272 -0.23334776 0.031974062 -0.015784053 -0.21945408 0.07359381 0.04936823 -0.15373217 -0.18460844 -0.055799782 -0.057939123 0.14816307 -0.46049833 0.16128318 0.190906 -0.29180774 -0.08877125 0.23563664 -0.036557104 -0.23812544 0.21938106 -0.2781296 0.5112853 0.049084224 0.14876273 0.20611146 -0.04535578 -0.35051352 -0.26381743 0.20824358 0.29732847 -0.013382204 -0.19970295 -0.34890386 -0.16214448 -0.23497184 0.1656344 0.15815939 0.012848561 -0.22887675 -0.21618247 0.13367777 0.1028471 0.25068823 -0.13625076 -0.11771541 0.4857257 0.102198474 0.06380113 -0.22328818 -0.05281015 0.0059655504 0.095453635 0.39693353 -0.066147 -0.1920163 0.5153346 0.24972811 -0.0076305643 -0.05530072 -0.24668717 -0.074051596 0.29288396 -0.0849124 0.37786478 0.2398532 -0.10374063 0.5445305 -0.41955113 0.39866814 -0.23992492 -0.15373677 0.34488577 -0.07166888 -0.48001364 0.0660652 0.061260436 0.32197484 -0.12741785 0.024006622 -0.07915035 -0.04467735 -0.2387938 -0.07527494 0.07079664 0.074456714 0.17877163 -0.002122373 -0.16164272 0.12381973 -0.5908519 0.5827627 -0.38076186 0.095964395 0.020342976 -0.5244792 0.24467848 -0.12481717 0.2869162 -0.34473857 -0.19579992 -0.18069582 0.015281798 -0.18330036 -0.08794056 0.015334953 -0.5609912 0.17393902 0.04283724 -0.07696586 0.2040299 0.34686008 0.31219167 0.14669564 -0.26249585 -0.42771882 0.5381632 -0.123247474 -0.29142144 -0.29963812 -0.32800657 -0.10684048 -0.08594837 0.19670585 0.13474767 0.18349588 -0.4734125 0.15554792 -0.21062694 -0.14191462 -0.12800062 0.2053445 -0.05258381 0.10878109 0.56381494 0.22724482 -0.17778987 -0.061046753 0.10789692 -0.015310492 0.16563527 -0.31812978 -0.1478078 0.4323269 -0.2543924 -0.25956103 0.38653126 0.5080214 -0.18796602 -0.10318089 0.023921987 -0.14618908 0.22923793 0.37690258 0.13323267 -0.34325415 -0.048353776 -0.30283198 -0.2839813 -0.2627738 -0.07422618 -0.31940162 0.38072023 0.56700015 -0.023362642 -0.3786432 0.084006436 0.0729958 0.09483505 -0.2665334 0.12699558 -0.37927982 -0.39073908 0.0063185897 -0.34464878 -0.24011964 0.09303968 -0.15488827 -0.018486138 0.3560308 -0.26005003 0.089302294 0.116130605 0.07684872 -0.085253105 -0.28178927 -0.17346472 -0.20008522 0.004347025 0.34192443 0.017453942 0.06926512 -0.15926014 -0.018554512 0.18478563 -0.040194467 0.38450953 0.4104423 -0.016453728 0.013374495 -0.011256633 0.09106963 0.20074937 0.17310189 -0.12467103 0.16330549 -0.0009963055 0.12181527 -0.05295286 -0.0059491103 -0.04697837 0.38616535 -0.21074814 -0.32234505 0.47269863 0.27924335 0.13548143 -0.2677968 0.03536313 0.3248672 0.2062973 0.29093853 0.1844036 -0.43359983 0.025519002 -0.06319317 -0.2427806 -0.22732906 0.08803728 -0.041860744 -0.151291 0.3400458 -0.29143015 0.25334117 0.06265491 0.26399022 -0.20121849 0.22156847 -0.50599706 0.069224015 0.52325517 -0.34115726 -0.105219565 -0.37346402 -0.02126528 0.09619415 0.017722093 -0.3621799 -0.109912336 0.021542747 -0.13361925 0.2087667 -0.08780184 0.09494446 -0.25047818 -0.07924239 0.21750642 0.2621652 -0.52888566 0.081884995 -0.20485449 0.18029206 -0.5623824 -0.03897387 0.3213515 0.057455678 -0.26524526 0.14741589 0.1257589 0.04708992 0.026751317 -0.014696863 -0.11038961 0.004459205 -0.01394376 0.091146186 -0.15486309 0.20662159 -0.0987916 -0.07740813 0.009704136 0.28866896 0.3916269 0.35061485 0.31678385 0.43233085 0.44510433
对于这些向量,在此使用了300维的行业标准。我们看到每一维度都由一个浮点数表示,并用空格隔开。当模型通过语料库进行训练时,它会对表示每个单词数字不断调整。经过Epoch,模型对词语的相似性有了更清晰的认识,至少对在相似语境中使用的词语是这样的。
2.6 为什么要使用词向量?
当一个词向量模型被训练出来后,我们就可以非常快速和可靠地进行相似性匹配。在本节一开始,咱们考虑了集中营这个词。现在让我们用这些词向量找出10个与集中营最相似的词。
[
('extermination_camp', 0.5768706798553467),
('camp', 0.5369070172309875),
('Flossenbiirg', 0.5099129676818848),
('Sachsenhausen', 0.5068483948707581),
('Auschwitz', 0.48929861187934875),
('Dachau', 0.4765608310699463),
('concen', 0.4753464460372925),
('Majdanek', 0.4740387797355652),
('Sered', 0.47086501121520996),
('Buchenwald', 0.4692303538322449)
]
在我们的词向量中,这些词与“集中营”最为相似。每个元组包含两个索引,索引0是词,索引1是相似度(用浮点表示)。
灭绝营不是一个直接的同义词,因为“灭绝营”和“集中营”在囚犯身上所发生的事情上是有区别的,灭绝营是处决囚犯,然而,这两者非常相似。将“灭绝营”视为最相似的单词,表明词向量是良好对齐的。Camp因为它是一个单个词,在上下文中与contentration camp有相似的含义。其他词是专有名词,它们都是集中营,只有一个例外:“concen”。这显然是数据清理不良造成的。“concen”并不是一个词,很可能是“concen-tration”的另一种写法,。事实上,这也是一个好现象,我们的词向量已经对齐得足够好,表明在向量空间附近有打字错误。
与Auschwitz相似的词:
[
('Auschwitz_Birkenau', 0.6649479866027832),
('Birkenau', 0.5385118126869202),
('subcamp', 0.5343026518821716),
('camp', 0.533636748790741),
('III', 0.5323576927185059),
('stutthof', 0.518073320388794),
('Ravensbriick', 0.5084848403930664),
('Berlitzer', 0.5083401203155518),
('Malchow', 0.5051567554473877),
('Oswiecim', 0.5016494393348694)
]
我们可以看到,最接近奥奇维茨(Auschwitz)的词语是与奥斯威辛集中营有关的地方,如比Birkenau子集中营(奥斯威辛集中营中有许多)、其他集中营(如Ravensbriick)以及奥斯威辛集中营纪念地奥斯威辛(Oswiecim)。
也就是说,我们已经得到了特别是与奥斯威辛(Auschwitz)密切相关的词。
2.7 视频
https://www.youtube.com/embed/eZJm7PisZvk
3 用Gensim生成词向量
3.1 关键概念
- Gensim库
- 如何在Gensim中创建词向量
- 主题模型
3.2 Gensim简介
Gensim是一个功能强大的Python库,最初设计用于生成主题模型。主题模型是一种机器学习模型,通过阅读整个语料库,将单个文档聚合成相似的聚类。为了结果良好,Gensim(包括其他主题模型方法)依赖于词的数字表示。换句话说,这些方法都依赖于词向量。确保结果准确,Gensim能够以相对较少的代码量生成词向量。另外,SpaCy也是一个NLP库,但不能生成自定义词向量。虽然用户可以将词注入到模型中,但从设计上spaCy本身并不是用来生成词向量的。因此,即使spaCy的官方文档也建议使用其他库,例如用Gensim来生成词向量。
本节将展示生成自定义词向量的过程。为了减少任务的执行时间,我们将使用一个很小的语料库。然而,这一过程可以很容易地扩展数百万级文档的语料库。
3.3 准备语料库
为了生成词向量,我们需要一个语料库,下面就创建语料库:
corpus = “Tom is cat, while Jerry is a mouse. Tom and Jerry are characters in a cartoon series. Some of the cartoons contain words, but most are silent. Silent cartoons still have music and sound effects.”
在我们将这个语料库输入Gensim之前,我们需要对其做些预处理。
1.首先,我们需要从语料库中删除停用词。通常Stopwords是指在语料库中频繁出现的词,其出现频率之高,可能为远程阅读提供不了太多的意义,因此,机器学习模型抛弃了它们。其他停用词是在一个语言中作为一个整体出现频率很高的词。我们将使用NLTK(自然语言工具包)提供的以下停用词:
stopwords = ["i","me","my","myself","we","our","ours","ourselves","you","your","yours","yourself","yourselves",
"he","him","his","himself","she","her","hers","herself","it","its","itself","they","them","their",
"theirs","themselves","what","which","who","whom","this","that","these","those","am","is","are","was",
"were","be","been","being","have","has","had","having","do","does","did","doing","a","an","the","and",
"but","if","or","because","as","until","while","of","at","by","for","with","about","against","between",
"into","through","during","before","after","above","below","to","from","up","down","in","out","on","off",
"over","under","again","further","then","once","here","there","when","where","why","how","all","any","both",
"each","few","more","most","other","some","such","no","nor","not","only","own","same","so","than","too","very",
"s","t","can","will","just","don","should","now"
]
corpus = corpus.lower()
words = corpus.split()
new_corpus = []
for word in words:
if word not in stopwords:
new_corpus.append(word)
corpus = " ".join(new_corpus)
print (corpus)
tom cat, jerry mouse. tom jerry characters cartoon series. cartoons contain words, silent. silent cartoons still music sound effects.
2.第二,语料库应该分成句子。在此建议使用spaCy的分句器。
3.分句时也应该去掉句子中的标点符号。可以使用Python中的标准字符串库来实现。
4.此阶段,应该将单词小写(可选)
5.如果希望减少生成词向量的数量,我们也可以考虑将词进行词性还原(可选)Lemmatize
6.我们需要把句子分成单个的词,然后把词列表追加到新对象
import spacy
import string
nlp = spacy.load("en_core_web_sm")
doc = nlp(corpus)
sentences = []
for sent in doc.sents:
sentence = sent.text.translate(str.maketrans('', '', string.punctuation))
words = sentence.split()
sentences.append(words)
print (sentences)
[[‘tom’, ‘cat’, ‘jerry’, ‘mouse’], [‘tom’, ‘jerry’, ‘characters’, ‘cartoon’, ‘series’], [‘cartoons’, ‘contain’, ‘words’, ‘silent’], [‘silent’, ‘cartoons’, ‘still’, ‘music’, ‘sound’, ‘effects’]]
3.4 创建词向量
至此,就可以开始着手生成我们的词向量了。代码如下:
def create_wordvecs(corpus, model_name):
from gensim.models.word2vec import Word2Vec
from gensim.models.phrases import Phrases, Phraser
from collections import defaultdict
print (len(corpus))
phrases = Phrases(corpus, min_count=30, progress_per=10000)
print ("Made Phrases")
bigram = Phraser(phrases)
print ("Made Bigrams")
sentences = phrases[corpus]
print ("Found sentences")
word_freq = defaultdict(int)
for sent in sentences:
for i in sent:
word_freq[i]+=1
print (len(word_freq))
print ("Training model now...")
w2v_model = Word2Vec(min_count=1,
window=2,
size=10,
sample=6e-5,
alpha=0.03,
min_alpha=0.0007,
negative=20)
w2v_model.build_vocab(sentences, progress_per=10000)
w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=30, report_delay=1)
w2v_model.wv.save_word2vec_format(f"data/{model_name}.txt")
create_wordvecs(sentences, "word_vecs")
输出如下:
4
Made Phrases
Made Bigrams
Found sentences
15
Training model now...
3.5 测试生成的词向量
现在,打开并查看词向量文件。这个文本文件的第一行是词向量的形状,应该是两个整数。第一个数字(15)是词汇表中词的数量。第二个数字(10)是每个词的维数。代码如下:
with open ("data/word_vecs.txt", "r") as f:
data = f.readlines()
print (data[0])
15 10
我们来看一下词向量中的第一个词 “Tom” :
print (data[1])
tom 0.046630684 -0.019758822 -0.00631089 0.039143123 -0.027235914 -0.013175516 0.027348584 0.0005846504 -0.02984228 -0.016458655
在这里我们看到两个信息。第一个是字符串,它是单词本身—“tom”。第二部分是10个浮点数,即词向量维度。这就是Gensim模型理解“Tom”的数值方法。也正是spaCy将这些向量加载到模型所期望接收的数据。下一节我们将把这些数据加载到spaCy模型。
3.6 练习
试着用上面的代码为自己的语料库创建自己的自定义词向量。
3.7 视频
https://www.youtube.com/embed/eZJm7PisZvk
4 将自定义词向量加载到spaCy模型中
4.1 关键概念
- 如何将自定义词向量加载到spaCy模型中
4.2 加载词向量
本节非常简短。它有只有一个目的,就是展示将词向量加载到空白spaCy模型所需的代码。我们将使用上节中所创建的词向量:data/word_vecs.txt。
将单词向量加载到空间模型中有两种不同的方式,一种是通过命令行(在视频中演示),另一种是通过Python脚本使用subprocess和sys。我更倾向于后者,因为它可以自动创建空白spaCy模型。我在下面的视频中详细介绍了这两种方法。视频中也对代码做了更深入的解释。
def load_word_vectors(model_name, word_vectors):
import spacy
import subprocess
import sys
subprocess.run([sys.executable,
"-m",
"spacy",
"init-model",
"en",
model_name,
"--vectors-loc",
word_vectors
]
)
print (f"New spaCy model created with word vectors. File: {model_name}")
load_word_vectors("data/sample_model", "data/word_vecs.txt")
New spaCy model created with word vectors. File: data/sample_model
现在你就可以按如下方式调用空白spaCy模型:
import spacy
nlp = spacy.load("data/sample_model")
4.3 练习
试着把上节练习中创建的自定义词向量加载到空白spaCy模型。
4.4 视频
https://www.youtube.com/embed/aQPMWS6XiI8
四 解决特定领域的问题(大屠杀研究)
1 创建良好的实体数据集
1.1 关键概念
- 在哪里可以找到良好的数据集
- 如何清理数据集
1.2 数据集简介
在前面的章节中我们已经讲述了命名实体识别的基础知识以及如何使用spaCy。当了解了这些知识后,本节将转入收集和清理数据。本文09.01,将获取与大屠杀有关的命名实体的必要数据。在09.02中,我们将着力于创建一个语料库,通过spaCy EntityRuler自动创建一个训练集。
在节中,我们将介绍如何找到好的数据集、如何清理数据、以及如何进行一些初步测试,确保拥有已优化过的数据,以便通过spaCy的EntityRuler来创建基于规则的NER。这将使你拥有一个良好的基于规则的NER,它既可以单独使用,也可以用来为机器学习模型创建一个良好的训练集。
1.3 获取数据
首要问题是“我在哪里可以获得数据?” 很不幸,答案是“这要视情况而定”。好的数据集或许是存在的。有几个比较好地方可以找找,比如GitHub、Wikipedia和电子版学术项目。对于每一个项目,你都必须在网上仔细查找,寻找这些数据集。大多数情况下,将数据转换为结构化形式需要一些额外的工作(以及一些Python代码)。在节中,我们将尽力为“集中营”创建一个良好的数据集。
如果我们是为集中营生成实体,那我们有大量的数据,并且这些数据不需要清理或结构化。让我们看看三个不同的地点,在那里我们可以从网上整理一份集中营的名单,这些来源各有优缺点。
1.4 维基百科(Wikipedia)
很有可能,你只需在Google中输入“List of[X]”,就可以开始搜索。如果你对“集中营”([X])这样做,那么你首先遇到的可能会是维基百科 (https://en.wikipedia.org/wiki/List_of_Nazi_concentration_camps)
这个页面之所以特别有用,有以下几个原因。首先,你有一个主要营地的名单,比如奥斯威辛集中营和达豪集中营。但是,更重要的是,您还可以访问subcamps的链接页,即对于Auchwitz,您可以访问此页面:https://en.wikipedia.org/wiki/List_of_subcamps_of_Auschwitz。通过少许Python代码,使用requests和BeautifulSoup,我们可以轻松地编制一个快速列表。
#收集subcamps的代码
#导入所需库
import requests
from bs4 import BeautifulSoup
def grab_subcamps(url, start_row, cell, t_class=False):
'''
This function will grab table data from Wikipedia.
It allows you to grab specific rows and specific cells of data to cultivate lists of entities
url >> the Wikipedia url for grabbing data
start_row >> Where the data starts in the table
cell >> The cell that you desire to grab from the table
t_class >> Some Wikipedia tables have a specific class of table that you need to grab, i.e. "wikipedia sortable".
'''
#页面的url
#创建html对象
s = requests.get(url).content
#创建soup以解析html对象
soup = BeautifulSoup(s)
#抓取第一个table
if t_class == True:
table = soup.find("table", {"class": "wikitable sortable"})
else:
table = soup.find("table")
#创建一个空list用于添加抓取到的camps
camps = []
#从第3行开始按行遍历table
for row in table.find_all("tr")[start_row:]:
#每行只有一个单元格, 处理index exception
try:
#grabs the 2nd cell in each row and cleans the data, splits off the cases of parentheses
#and grabs the first index from that split list
camp = row.find_all("td")[cell].text.strip().split("(")[0].split("/")[0].strip()
camps.append(camp)
except:
IndexError
return (camps)
#打印显示Auschwitz的subcamps
ausch_subcamps = grab_subcamps("https://en.wikipedia.org/wiki/List_of_subcamps_of_Auschwitz", 2, 1)
buch_subcamps = grab_subcamps("https://en.wikipedia.org/wiki/List_of_subcamps_of_Buchenwald", 1, 1, t_class=True)
print (ausch_subcamps)
print ("")
print (buch_subcamps)
[‘Harmense’, ‘Budy’, ‘Babitz’, ‘Birkenau’, ‘Raisko’, ‘Plawy’, ‘Golleschau’, ‘Jawischowitz’, ‘Chelmek’, ‘Monowitz Buna-Werke [6]’, ‘Eintrachthütte’, ‘Neu-Dachs’, ‘Fürstengrube’, ‘Janinagrube’, ‘Lagischa’, ‘Günthergrube’, ‘Gleiwitz I’, ‘Laurahütte’, ‘Blechhammer’, ‘Bobrek’, ‘Gleiwitz II’, ‘Sosnowitz II’, ‘Gleiwitz III’, ‘Hindenburg’, ‘Trzebinia’, ‘Tschechowitz I Bombensucherkommando[9]’, ‘Althammer’, ‘Bismarckhütte’, ‘Charlottengrube’, ‘Neustadt’, ‘Tschechowitz II Vacuum’, ‘Hubertshütte’, ‘Freudenthal’, ‘Lichtewerden’, ‘Sosnitz’, ‘Porombka’, ‘Altdorf’, ‘Radostowitz’, ‘Kobier’, ‘Brünn’, ‘Sosnowitz’, ‘Gleiwitz IV’, ‘Kattowitz’, ‘Bauzug’]
[‘Aachen’, ‘Berka’, ‘Berka’, ‘Stadtallendorf’, ‘Altenburg’, ‘Bad Arolsen’, ‘Aschersleben’, ‘Augustdorf’, ‘Bad Berka’, ‘Bad Gandersheim’, ‘Bad Salzungen’, ‘Bad Salzungen’, ‘Bergisch Gladbach’, ‘Berga’, ‘Berlstedt’, ‘Bernburg’, ‘Billroda’, ‘Blankenhain’, ‘Bochum’, ‘Bochum’, ‘Bochum’, ‘Böhlen’, ‘Braunschweig’, ‘Colditz’, ‘Crawinkel’, ‘Dessau’, ‘Dessau’, ‘Dortmund’, ‘Dortmund’, ‘Duisburg’, ‘Düsseldorf’, ‘Düsseldorf’, ‘Düsseldorf’, ‘Düsseldorf’, ‘Eisenach’, ‘Elsnig’, ‘Ohrdruf’, ‘Essen’, ‘Essen’, ‘Frohburg’, ‘Gelsenkirchen’, ‘Giessen’, ‘Goslar’, ‘Göttingen’, ‘Hadmersleben’, ‘Halberstadt’, ‘Halberstadt’, ‘Halberstadt’, ‘Halberstadt’, ‘Halle’, ‘Hessisch Lichtenau’, ‘Holzen’, ‘Jena’, ‘Kassel’, ‘Kassel’, ‘Cologne’, ‘Cologne’, ‘Cologne’, ‘Cologne’, ‘Kranichfeld’, ‘Bad Langensalza’, ‘Leipzig’, ‘Leipzig’, ‘Leipzig’, ‘Leipzig’, ‘Staßfurt’, ‘Prettin’, ‘Lippstadt’, ‘Lippstadt’, ‘near Mücheln’, ‘Magdeburg’, ‘Markkleeberg’, ‘Meuselwitz’, ‘Nordhausen’, ‘Mühlhausen’, ‘Mühlhausen’, ‘Niederorschel’, ‘Nordhausen’, ‘Kraftsdorf’, ‘Ohrdruf’, ‘Penig’, ‘Raguhn’, ‘Rothenburg’, ‘near Wurzbach’, ‘Schlieben’, ‘Schönebeck’, ‘Schönebeck’, ‘Schwerte’, ‘Sömmerda’, ‘Sonneberg’, ‘Staßfurt’, ‘Suhl’, ‘Bad Berka’, ‘Taucha’, ‘Tonndorf’, ‘Torgau’, ‘Elsteraue’, ‘Unna’, ‘Usingen’, ‘Weferlingen’, ‘Weimar’, ‘Wernigerode’, ‘Westeregeln’, ‘Witten-Annen’, ‘Wolfen’]
以上列出的是奥斯威辛集中营和布痕瓦尔德集中营的subcamps(子营)列表。我们用了很少的代码,从我们第一个Google搜索中收集并清理了这个列表。以这种方式获取数据的好处是,我们对数据的结构会产生一些感觉。我们知道这些是奥斯威辛集中营的子集中营,这意味着我们可以在数据结构中将它们链接到相应的主集中营。
然而,这些数据确实是有代价的。这是从维基百科收集的数据。为了确保这些数据是正确的,应该咨询领域专家。如果手头没有,我建议从更可靠的网站获取数据,比如国家资助的博物馆或学术机构。
1.5 美国大屠杀纪念馆
位于美国华盛顿特区的美国大屠杀纪念馆(USHMM)就是其中的一个机构。在USHMM中搜索集中营集合时,结果仅限于Key Camps(关键集中营) (https://www.ushmm.org/)
得到的结果如下:
ushmm_camps = ['Alderney', 'Amersfoort', 'Auschwitz', 'Banjica', 'Bełżec', 'Bergen-Belsen,', 'Bernburg', 'Bogdanovka', 'Bolzano', 'Bor', 'Breendonk',
'Breitenau', 'Buchenwald,', 'Chełmno', 'Dachau', 'Drancy', 'Falstad', 'Flossenbürg', 'Fort VII', 'Fossoli', 'Grini', 'Gross-Rosen',
'Herzogenbusch', 'Hinzert', 'Janowska', 'Jasenovac', 'Kaiserwald', 'Kaunas', 'Kemna', 'Klooga', 'Le Vernet', 'Majdanek', 'Malchow',
'Maly Trostenets', 'Mechelen', 'Mittelbau-Dora', 'Natzweiler-Struthof', 'Neuengamme', 'Niederhagen', 'Oberer Kuhberg', 'Oranienburg',
'Osthofen', 'Płaszów', 'Ravensbruck', 'Risiera di San Sabba', 'Sachsenhausen', 'Sajmište', 'Salaspils', 'Sobibór', 'Soldau', 'Stutthof',
'Theresienstadt,', 'Trawniki', 'Treblinka', 'Vaivara']
print (ushmm_camps)
[‘Alderney’, ‘Amersfoort’, ‘Auschwitz’, ‘Banjica’, ‘Bełżec’, ‘Bergen-Belsen,’, ‘Bernburg’, ‘Bogdanovka’, ‘Bolzano’, ‘Bor’, ‘Breendonk’, ‘Breitenau’, ‘Buchenwald,’, ‘Chełmno’, ‘Dachau’, ‘Drancy’, ‘Falstad’, ‘Flossenbürg’, ‘Fort VII’, ‘Fossoli’, ‘Grini’, ‘Gross-Rosen’, ‘Herzogenbusch’, ‘Hinzert’, ‘Janowska’, ‘Jasenovac’, ‘Kaiserwald’, ‘Kaunas’, ‘Kemna’, ‘Klooga’, ‘Le Vernet’, ‘Majdanek’, ‘Malchow’, ‘Maly Trostenets’, ‘Mechelen’, ‘Mittelbau-Dora’, ‘Natzweiler-Struthof’, ‘Neuengamme’, ‘Niederhagen’, ‘Oberer Kuhberg’, ‘Oranienburg’, ‘Osthofen’, ‘Płaszów’, ‘Ravensbruck’, ‘Risiera di San Sabba’, ‘Sachsenhausen’, ‘Sajmište’, ‘Salaspils’, ‘Sobibór’, ‘Soldau’, ‘Stutthof’, ‘Theresienstadt,’, ‘Trawniki’, ‘Treblinka’, ‘Vaivara’]
虽然这个是一个干净、良好数据集,但它有一定的局限性。首先,它是不完整的。这是一份关键集中营的名单,不是所有集中营。注意,子营不在列表中。我们面临的第二个问题是,这些集中营的的名称中的某些字符表示重音符号或字母不在英文字母表中。但某些大屠杀文本只使用英文字母和字符,因此,搜索某些单词(如Płaszów)不会在搜索Plaszow时被找到返回。因此在基于规则的搜索方式中,确保规则中包含单词的这两种表示形式,是很重要的。
通过下面的代码,我们可以生成每个单词的副本,包括有或没有这些字符。
def remove_accents(text):
#Polish letters
letters= {
'ł':'l', 'ą':'a', 'ń':'n', 'ć':'c', 'ó':'o', 'ę':'e', 'ś':'s', 'ź':'z', 'ż':'z',
'Ł':'L', 'Ą':'A', 'Ń':'N', 'Ć':'C', 'Ó':'O', 'Ę':'E', 'Ś':'S', 'Ź':'Z', 'Ż':'Z',
#Accent Vowels
"à":"a", "á":"a", "â":"a", "ã":"a", "ä":"a", "å":"a", "æ": "ae",
"À":"A", "Á":"A", "Â":"A", "Ã":"A", "Ä":"A", "Å":"A", "Æ": "ae",
"è":"e", "é":"e", "ê":"e", "ë":"e",
"È":"E", "É":"E", "Ê":"E", "Ë":"E",
"ì":"i", "í":"i", "î":"i", "ï":"i",
"Ì":"I", "Í":"I", "Î":"I", "Ï":"I",
"ò": "o", "ó": "o", "ô": "o", "õ": "o", "ö": "o", "ø": "o",
"Ò": "O", "Ó": "O", "Ô": "O", "Õ": "O", "Ö": "O", "Ø": "O",
"ù": "u", "ú": "u", "û": "u", "ü": "u",
"Ù": "U", "Ú": "U", "Û": "U", "Ü": "U",
"ý": "y", "ÿ": "y",
"Ý": "Y", "Ÿ": "Y",
#Accent Cononants
"ç": "c", "Ç": "C",
"ß": "ss"
}
trans=str.maketrans(letters)
result=text.translate(trans)
return (result)
final = []
for camp in ushmm_camps:
final.append(camp)
final.append(remove_accents(camp))
#Delete all duplicates
ushmm_camps = list(set(final))
ushmm_camps.sort()
print (ushmm_camps)
[‘Alderney’, ‘Amersfoort’, ‘Auschwitz’, ‘Banjica’, ‘Belzec’, ‘Bergen-Belsen,’, ‘Bernburg’, ‘Bełżec’, ‘Bogdanovka’, ‘Bolzano’, ‘Bor’, ‘Breendonk’, ‘Breitenau’, ‘Buchenwald,’, ‘Chelmno’, ‘Chełmno’, ‘Dachau’, ‘Drancy’, ‘Falstad’, ‘Flossenburg’, ‘Flossenbürg’, ‘Fort VII’, ‘Fossoli’, ‘Grini’, ‘Gross-Rosen’, ‘Herzogenbusch’, ‘Hinzert’, ‘Janowska’, ‘Jasenovac’, ‘Kaiserwald’, ‘Kaunas’, ‘Kemna’, ‘Klooga’, ‘Le Vernet’, ‘Majdanek’, ‘Malchow’, ‘Maly Trostenets’, ‘Mechelen’, ‘Mittelbau-Dora’, ‘Natzweiler-Struthof’, ‘Neuengamme’, ‘Niederhagen’, ‘Oberer Kuhberg’, ‘Oranienburg’, ‘Osthofen’, ‘Plaszow’, ‘Płaszów’, ‘Ravensbruck’, ‘Risiera di San Sabba’, ‘Sachsenhausen’, ‘Sajmište’, ‘Salaspils’, ‘Sobibor’, ‘Sobibór’, ‘Soldau’, ‘Stutthof’, ‘Theresienstadt,’, ‘Trawniki’, ‘Treblinka’, ‘Vaivara’]
注意列表中“Płaszów”作为“Plaszow”的标准化形式。这两种形式现在都表示在我们的数据集中,这意味着我们可以开发一个基于规则的EntityRuler,它可以在文本中找到这两种形式的单词。虽然我们能够解决第二个问题,即标准化数据的问题,但我们无法解决第一个问题。如果我们愿意,可以将这个数据集添加到我们的维基百科数据集中,但是我们将在下面看到的,一个更大的数据集带来了新的挑战。
2 创建语料库
2.1 关键概念
- 语料库中挖掘什么信息
2.2 概述
本节主要讲述创建语料库的步骤,使用EntityRuler通过语料库来创建一个大型训练集。我将以此为例研究语料库中应该挖掘什么信息。
2.3 多样性
机器学习模型的目标就是要能够在未见的数据上进行很好地泛化。若要让模型在所有未见的数据(至少是大多数)上得到很好的泛化,最好的方法就是给出各种类型的文本。训练模型时样本的多样性非常关键,因为多样性允许模型从不同类型的文本中学习不同的内容,这些文本是以不同的风格、方言、上下文等编写的。因此,在组合语料库以生成训练数据时,首先需要考虑的就是多样性。因此,要牢记:为模型提供尽可能多的文本数据。
2.4 准备语料库
当你汇集了不同来源的代表各种风格、方言和上下文的文档,就可以开始准备语料库了。在这个阶段,NLP工作者必须考虑如何准备语料库。如何准备语料库从根本上改变了模型所学。
比如以下几个句子:
sent1 = "My name is William Mattingly."
sent2 = "My name is William Mattingly"
sent3 = "my name is william mattingly"
sent4 = "MY NAME IS WILLIAM MATTINGLY"
虽然每一句话对人类来说都是一样的,但对机器来说却完全不同。演示如下:
sents = [sent1, sent2, sent3, sent4]
all_words = []
for sent in sents:
words = sent.split()
for word in words:
all_words.append(word)
no_duplicates = list(set(all_words))
no_duplicates.sort()
print (no_duplicates)
[‘IS’, ‘MATTINGLY’, ‘MY’, ‘Mattingly’, ‘Mattingly.’, ‘My’, ‘NAME’, ‘WILLIAM’, ‘William’, ‘is’, ‘mattingly’, ‘my’, ‘name’, ‘william’]
在上面的代码中,我们将所有句子组合成词袋,然后删除重复的单词。但是,请注意,尽管删除了重复项,但每个单词都会出现多次。因为计算机认为“WILLIAM”, “William”, “william”是不同的词。如何清理和准备训练数据将影响模型对其理解。换句话说,如果训练时你进行了数据清理,但期望模型工作时接受未清理的输入数据,其性能将大打折扣。如果将所有训练数据都小写,当模型遇到大写的单词时,其性能将很难令人满意。
清理和准备数据是自然语言处理中的基本步骤,但在模型训练时,作为模型的创建者,你必须了解这些步骤将如何影响模型的性能,以及你是否应该以特定的方式清理数据。你应该让你的用户知道你所采取的步骤(清理数据的特定方式)以及应该如何将数据提供给你的模型。你甚至可能为用户提供一些辅助函数或类,以帮助他们清理数据,并以训练时所用的方式对数据进行结构化。
以下代码简单性需求其实现。它与上面的代码相同,只是每个句子都是小写的,句号在添加到单词列表之前已被删除。
sents = [sent1, sent2, sent3, sent4]
all_words = []
for sent in sents:
#小写并去除句号.
sent = sent.lower().replace(".", "")
print (sent)
words = sent.split()
for word in words:
all_words.append(word)
no_duplicates = list(set(all_words))
no_duplicates.sort()
print (no_duplicates)
my name is william mattingly
my name is william mattingly
my name is william mattingly
my name is william mattingly
[‘is’, ‘mattingly’, ‘my’, ‘name’, ‘william’]
通过清理文本,我们成功地消除了句号。然而,在这样做的过程中,我们的模型将永远不会遇到专有名词大写的数据。它也永远不会遇到句号。因此,在清理数据时要注意这一点。
2.5 词性还原与非词性还原(To Lemmatize or Not to Lemmatize)
接下来,我们必须考虑词性还原的问题。我们在笔记01.02讲过词性还原,但在这里还是有必要再讲一遍。词性还原就是把所有的词还原为词元或词根的过程。不同的库对词性还原的执行方式也不同。我们将使用spaCy。请看下面句子中的一个新例子。
在这两个句子中,除了时态和一个完全大写之外,他们的意思几乎相同。Lemmatization具有使这两个句子完全相同的功能。
import spacy
nlp = spacy.load("en_core_web_sm")
sent1 = "The ball is his."
sent2 = "THE BALL WAS HIS."
sents = [sent1, sent2]
all_words = []
for sent in sents:
sent = sent.lower().replace(".", "")
doc = nlp(sent)
new = []
for token in doc:
if "-" not in token.lemma_:
new.append(token.lemma_)
else:
new.append(token.text)
sent = " ".join(new)
print (sent)
words = sent.split()
for word in words:
all_words.append(word)
no_duplicates = list(set(all_words))
no_duplicates.sort()
print (no_duplicates)
the ball be his
the ball be his
[‘ball’, ‘be’, ‘his’, ‘the’]
通过对句子进行词性还原,我们能够完全消除这两个文本之间的时态差异。对于各种NLP任务的文本数据清理这一步骤在某些情况下会有用。有时这种方法会很好地简化文本形式,这取决于你希望模型做什么。再者,这样做意味着一个模型将永远不会遇到“was”或任何未词性还原的单词形式。同样,你给模型教什么模型就学什么。
2.6 分割语料库
在本节结束前,最后要注意的是分割。文本分割是将大型语料库(有时是数以百万计的文档)分解成可管理大小的过程,在单个文本文件中用换行符分隔(我的偏好)。我发现参考欲提供给模型的训练数据的大小即可。如果我正在处理拉丁文本,我会选择一个章节大小,即一个章节(通常是4-20个句子)。如果我用的是USHMM口头证词,我会用问答块分割语料库。如果我使用的是常规的文本数据,我可能会将文本分割成单独的句子。
考虑一下你欲提供给模型的训练数据的大小。我发现,对基于规则的EntityRuler自动生成训练数据的过程,分割较小可以消除误报的可能性。
2.7 练习
对于本节中的练习,找到一个符合我上面提到的要求的语料库,并使用不同的方法清理该语料库。
3 “大屠杀”领域NER面临的挑战
3.1 关键概念
- 机器学习道德伦理规范
- 多语种及地区差异引起的语料库问题
- 地名
- 地名解析
3.2 问题概览
开发一个“大屠杀”领域文档的NER模型有几个问题必须解决。它们可以归为以下三类:道德伦理的、语言的、地名解析的。本文将就这三类问题逐一论述。
3.3 关于道德伦理方面
任何数据科学家或NLP/ML工作者在处理像大屠杀这样敏感及微妙的文档时,都必须考虑使用机器学习的严重道德伦理问题。首先,是隐私问题。命名实体识别,根据定义是用来查找和提取命名实体的。文件中提到的个人是否愿意曝露于公众?他们是否希望将自己的名字从上下文中删除并以元数据形式存储?这些是人们应该考虑的一些伦理问题。这并不是说这一进程不能向前推进,但如果要这样做,那么推进者就要负责解释这些伦理考虑以及为补救这些考虑而采取的步骤。
当提到人名时,这些人可能是暴力的受害者、暴力的实施者、受害者的采访者、历史学家等等。人们必须问,是否能够接受让机器决定在上下文中介绍有关个人的功能。能让一台机器来识别暴力的受害者或肇事者吗?这合乎道德吗?这是负责任的吗?可能不会。这实际上取决于期望的输出和NER系统的创建者希望证明其行为正当的程度。
此外,机器学习并是不精确的。这意味着将会发生错误。如果你的NER试图识别人名、GPE和自定义实体,例如集中营和犹太人区,那么导致潜在受害者被标记为集中营的错误在道德上是否可以接受?从机器学习的角度来看,这种错误是可以理解的。但是想象一下,如果一个受害者或受害者的家人试图使用新技术来了解他们的过去,而他们看到自己的名字,或是一个朋友或家人的名字,而这个朋友或家人曾是大屠杀的受害者,被标为集中营。为什么会这样?原因是多种多样的。但是,如果我们从受害者的角度来考虑这个问题,这可能会造成创伤。出于这些原因,我们有责任引入一些保护机制,防止此类事件发生和(或)引入警告和解释,解释可能发生此类错误的原因。
3.4 语言方面的
除了伦理问题,还有一些语言问题使得大屠杀数据特别具有挑战性。首先,大屠杀覆盖了欧洲的大部分地区,因此,那些参与或受大屠杀事件影响的人必然具有不同的语言背景。除此之外,许多人有两种母语或说多种语言。这就产生了数十种语言的文件。此外,有些文件是多语种的。例如,在USHMM的口头证词中,被邀请者可以用英语作证,但随后使用意第绪语或波兰语。这种语言上的突然变化可能会用用记号表示,也可能没有。
在自然语言处理中,处理多种语言的文档是一项具有挑战性的任务。幸运的是,BERT和基于Transformer的机器学习模型的新进展可能提供了执行这一任务的钥匙。目前,我在本文中所采取的步骤仅适用于单一语言文档。如果一个外文单词偶尔出现在文本中,我提供的步骤就足够了。但是,如果文档一半是德语,一半是英语,则需要采取某些预处理步骤来分别处理每种语言。
除了一个文档中存在多种语言外,有时一个文档还可能包含一种语言的特殊方言。如果一个NER模型没有见过这种方言差异,通常会返回较差的结果。例如,在口头证词中,大屠杀的受害者可能用一个只有少数人使用的当地名字来指代他们的出生地,这可能是一个大多数模型都从未遇到过的波兰的村庄。理解为什么这些问题会给模型带来问题以及如何克服这些问题十分重要。正如我们在上节中看到的,解决这些问题的最简单方法是将这些特殊数据引入训练数据中。
3.5 地名
最后一个与大屠杀领域文件有关的问题是地名问题。地名是一种专有名词,对于完全相同的名称,根据所使用的上下文却有着完全不同的含义。例如,如果我说“每年这个时候巴黎的气候很好”,我会说哪里呢?如果你读到这篇文章,你可能会认为我说的是法国巴黎。如果我告诉你,我是在肯塔基州列克星敦的一家咖啡馆里做这番话的,我这番话中的巴黎可能意味着,实际上,我说的是肯塔基州巴黎,列克星敦以外的一个小镇。但如果我告诉你我是在这种情况下说的呢。“我刚从德克萨斯旅行回来。每年这个时候巴黎的气候非常好”,现在,我说的可能是德克萨斯州的巴黎,这样就更清楚一点了。
如果没有上下文,那一句话可能有许多不同的含义。在这个例子中,巴黎是一个地名。在大屠杀文件中,我们经常会遇到一些地点的地名,这些地点根据上下文有特定的实体标签。比如:想象一下,我有一个模型,可以识别两种类型的实体: LOCATION 和 GHETTO。
“Warsaw is a large city in Poland. During WWII, the Warsaw Ghetto was created.”
作为人类,你会如何理解这两句话?如果你说,第一句华沙是一个LOCATION,第二句华沙是一个GHETTO,无疑是正确的。NER和NLP中的技巧就是创建能够执行此任务的系统。大屠杀文件中充满了这样的例子。我们解决这些问题的方法是,在模型中加入正确的地名解析训练集,或手动注释确保地名被正确标记的训练集,这样模型就可以学习正确识别地名。
3.6 练习
对于你的数据中存在的地名,想想如何解析他们?
3.7 视频
本节没有视频。
4 创建用于“大屠杀”领域NER的LOCATION管件(Pipe)
4.1 关键概念
- 如何向spaCy模型添加管
- 如何自定义管件标签
4.2 概述
本章我们将介绍如何创建空白spaCy模型,从其他模型加载管件,并保存新模型。我们还将使用自定义实体。
4.3 创建一个空白spaCy模型
任何时候创建自定义spaCy模型,从空白模型开始通常是一个好主意。我们先来这样做。spaCy 空类接受一个参数,即语言(language)。在下例中,我们想要创建一个空白的英文模型。不同语言将影响spaCy如何分割文本。
import spacy
main_nlp = spacy.blank("en")
我们现在的目标是从spaCy 小型英文模型中获取NER管件,首先将其注入空白模型中。先来获取预训练好的英文模型。
en_model = spacy.load("en_core_web_sm")
接下来,需要获取特定NER管件。可以通过函数get_pipe()来实现。它需要一个参数,即所需的管件。因为想获取NER管件,我们将参数指定为“ner”。
ner = en_model.get_pipe("ner")
有了这个管件,我们可以使用add_pipe()函数将它添加到空白的spaCy模型中。
main_nlp.add_pipe(ner)
现在已经将“ner”添加到我们的main_nlp管道中,让我们来测试它并确保其工作正常。
sent = "Hello, my name is Bob and I live in the United States."
doc = main_nlp(sent)
for ent in doc.ents:
print (ent.text, ent.label_)
Bob PERSON
the United States GPE
请注意,我们的空白模型现在可以使用小型英文spaCy模型中的ner管件。测试成功!
4.4 保存spaCy模型
保存spaCy模型同样很简单。在继续下面的工作之前,让我们先保存空白模型。我们可以用to_disk()函数来完成。这个函数需要一个参数,即我们保存模型的位置。我们将把它放在models的子文件夹中。
main_nlp.to_disk("models/sample_model")
4.5 放置管件(Pipes)
有时,我们想创建有多个管件(Pipes)的更复杂的管道(pipelines)。在这些场景中,我们需要在特定位置放置特定管件(Pipes)。看看如何做到这一点。
我们可以用几种不同的方法。首先,可以在脚本中按顺序放置管道。添加的最后一个管件(Pipes)将是管道(pipelines)中的最后一个管件(Pipes)。在下面的代码中,我们将英语和德语NER添加到我们的管道中。但这样做,会出现错误:
import spacy
main_nlp = spacy.blank("en")
en_ner = spacy.load("en_core_web_sm").get_pipe("ner")
de_ner = spacy.load("de_core_news_sm").get_pipe("ner")
main_nlp.add_pipe(en_ner)
main_nlp.add_pipe(de_ner)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
7
8 main_nlp.add_pipe(en_ner)
----> 9 main_nlp.add_pipe(de_ner)
c:\python38\lib\site-packages\spacy\language.py in add_pipe(self, component, name, before, after, first, last)
339 name = util.get_component_name(component)
340 if name in self.pipe_names:
--> 341 raise ValueError(Errors.E007.format(name=name, opts=self.pipe_names))
342 if sum([bool(before), bool(after), bool(first), bool(last)]) >= 2:
343 raise ValueError(Errors.E006)
ValueError: [E007] 'ner' already exists in pipeline. Existing names: ['ner']
出现此错误的原因是,我们正在试图给 main_nlp 添加两个具有相同名称(“ner”)的NER管件。其实只需给每个管件一个不同的名字即可。实现代码如下,然后我们将遍历 main_nlp 管道以确保正确列出了所有管件。
import spacy
main_nlp = spacy.blank("en")
en_ner = spacy.load("en_core_web_sm").get_pipe("ner")
de_ner = spacy.load("de_core_news_sm").get_pipe("ner")
main_nlp.add_pipe(en_ner, name="en_ner")
main_nlp.add_pipe(de_ner, name="de_ner")
for pipe in main_nlp.pipeline:
print (pipe)
结果如下:
('en_ner', )
('de_ner', )
注意以上结果,我们不仅获得了具有唯一名称的正确管件,而且还获得了管件的预期顺序。若要把"de_ner"放在"en_ner"的前面,则在add_pipe()函数中增加参数,根据要放置的位置,使用 before或after。本例我们将使用before=”en_ner”。
import spacy
main_nlp = spacy.blank("en")
en_ner = spacy.load("en_core_web_sm").get_pipe("ner")
de_ner = spacy.load("de_core_news_sm").get_pipe("ner")
main_nlp.add_pipe(en_ner, name="en_ner")
main_nlp.add_pipe(de_ner, name="de_ner", before="en_ner")
for pipe in main_nlp.pipeline:
print (pipe)
结果如下:
('de_ner', )
('en_ner', )
以特定顺序放置特定管件非常重要,因为后面的管件将接收前面管件的数据。在NER的情况下,这意味着后面的管件不能覆盖前面的管件的结果,除非我们给予它们相应权限。
4.6 添加自定义标签
为了更好地演示如何添加自定义标签,参见下面的视频。
4.7 练习
尝试创建一些自定义管道,看看以不同的顺序放置它们时在文本中的表现。
4.8 视频
https://www.youtube.com/embed/1l3v2Zcgb3s
全文完
- 译者:Xirong Cui
- 日期:February 22, 2021
- 邮箱:[email protected]