《OpenCV训练级联分类器》
我是个初学者,我只想把我所学到经验分享一下,不好勿喷。
一.寻找传说中的opencv_traincascade.exe和opencv_createsamples.exe
opencv里自带了opencv_traincascade.exe,opencv_createsamples.exe这两个东东,找出来新建一个文件夹,把这两二货放进去。解释一下:opencv_createsamples.exe是用来创建正样本vec文件的(也就是正样本描述文件),而opencv_traincascade.exe则是用来训练的。
二.正样本和负样本之间微妙关系
正样本:就是你要检测的目标(假如说你要检测一个杯子,那么杯子就是正样本)
负样本:这个就是不包括正样本的图片
1.网上传言:有的人说正样本尺寸应尽量保持在20x20,也有的人说应该看要检测的是什么东西,再保持图片的尺寸,但我选择的是20*20的,而负样本的尺寸就没有那么多要求了啦,一般比正样本的尺寸大就行了,大多少,就看你自己选择了,40*40,50*50都行吧。如果能把图片换成灰度图就更好了,这样可以加快训练的速度。
2.还是网上传言:话说正样本和负样本应该选多少合适呢?毕竟你妹的裁剪图片是个耗时耗力的活儿,一不注意一下午就过去了。有人说1:3,也有人说3:1,7:1之类我的想法就是不管啦,各种情况都试一下。有人试过用几万个正样本去训练,但我一般就用几百到几千,还没试过几万的。事先说明一下,样本越多,训练时间也就越长的啦,我用将近200个正样本和1万多个负样本去训练,光训练到第六层就用了将近8个小时。
3.这个不是网上传言,我自己的想法,看别人的总结的:正样本图片拍摄的时候应该保证各个角度不一样,有独特性,一样的话就相当于做无用功,重复做一件事情。负样本也是一样的,只要不包括正样本就行,你正样本要用到哪个方面就用哪个地方的背景。图片可以自己拍照,也可以拍视频然后转换成图片,帧数可以大点,确保不一样的,还可以去网上下载,有很多人会发压缩包到网上供人下载,但是要积分的,我就下过几次。有的好用,有的就不行了,看运气吧。视频转图片我用的是Free Video to JPG Converter,裁剪图片我用的光影魔术手和美图秀秀。光影魔术手裁剪感觉好一点,他可以设置比例,然后画框就行了。
4.最后再说一点,就一点:裁剪图片的时候尽量保证为正方形(也就是1:1),反正我是用的正方形,其他的我没试过,然后把样本图片归一化尺寸。
三.哈哈哈哈,开始准备正样本啦,九阳神功再现江湖
1.新建一个文件夹,把所有的正样本图片放进去,然后把opencv_createsamples.exe也放进去。
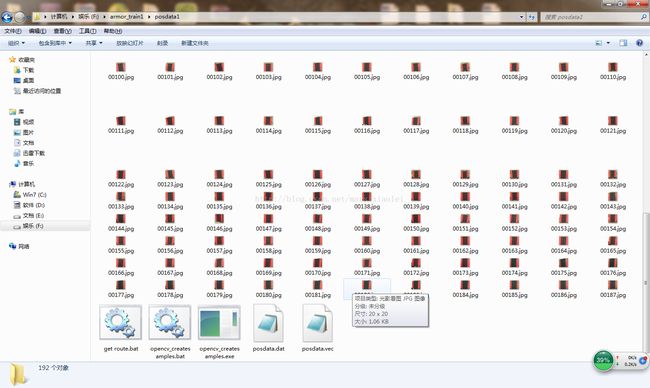
2.新建一个文本文档,后缀名改成.bat,然后输入如下内容:
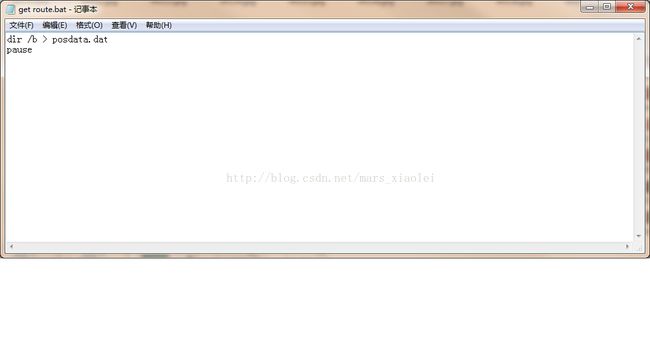
3.运行这个.bat文件,就会生成一个.dat文件,打开这个文件,仔细找找哈,把除图片以外的东西都删掉,一般在最上面和最下面,然后再点击编辑把jpg换成jpg 1 0 0 20 20,点击全部替换,保存ctlr+s,这样一个正样本描述文件就弄球好了。
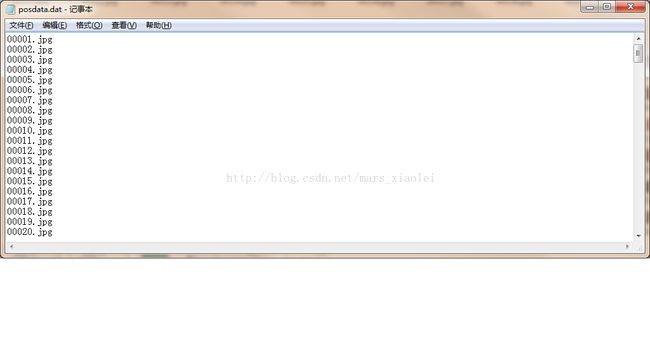
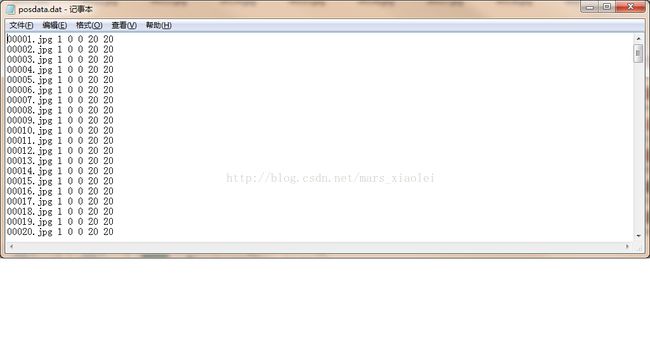
九阳神功秘籍:
a.1代表个数,后面四个数字分别代表着left,top,width,hight
b.这里我用的是.dat文件,相当于就是在windows里的dos中输命令,但是输命令好麻烦啊,宝宝罩不住,要路径还不能粘贴复制,错了还得重新输,所以我就选了这种偷懒的方式,也就是一个运行文件。
四.获取共训练的vec文件,乾坤大挪移,战斗力指数报表,乾坤大挪移颠倒一刚一柔,一阴一阳。
1.之前我们已经把opencv_createsamples.exe和正样本图片放在一块了,那么现在就发挥出他的用处了,新建一个.bat文件,输入以下内容:
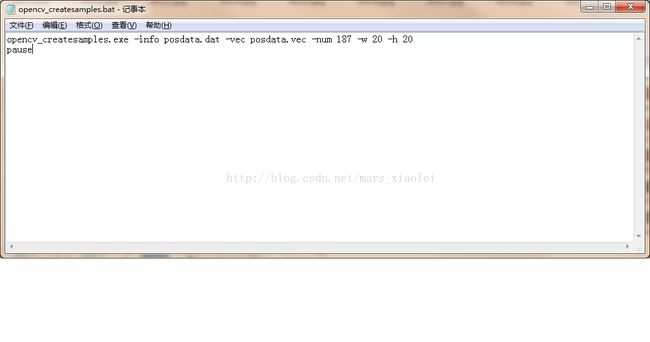
乾坤大挪移秘籍:
a.这里面路径要写对,不然训练的时候会报错,说找不到正样本
b.你要知道你的正样本数量,这里的num就是正样本数量,宽和高就不说了
2.这样一个.vec文件就生成了,里面都是乱码,自己可以打开看看,保存了正样本数据,也可以调用opencv_createsamples.exe去查看
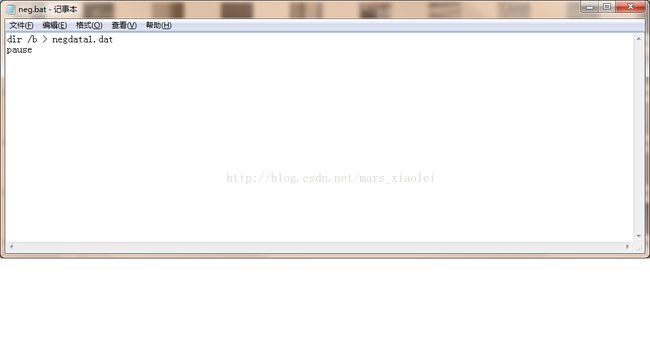
五.准备负样本数据,葵花宝典,唯快不破
1.这个就没有准备正样本那么复杂了,直接新建一个.bat文件,然后输入以下内容,运行.bat文件,再把除图片路径之外的东西全删掉,这里连替换都不用了,是不是很快。
六.啦啦啦,开始训练啦,我是要成为海贼王的男人-蒙奇D.路飞
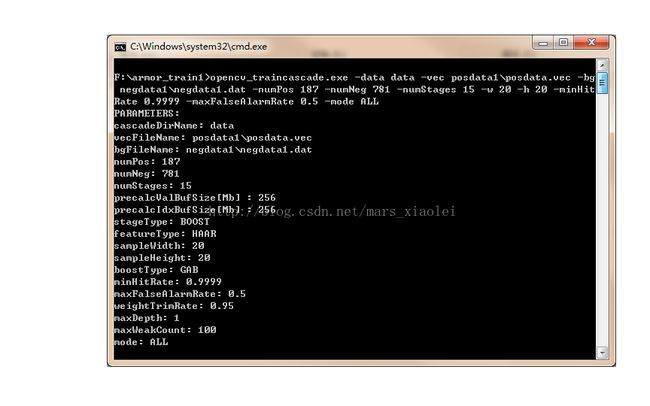
1.把opencv_traincascade.exe放在正样本和负样本文件夹之外的大文件夹内,然后新建一个.bat文件,输入以下内容:
opencv_traincascade.exe -data data -vec posdata1\posdata.vec -bg negdata1\negdata1.dat -numPos 187 -numNeg 781 -numStages 15 -w 20 -h 20 -minHitRate 0.9999 -maxFalseAlarmRate 0.5 -mode ALL
pause

到这里基本上就完了,后面就开始训练了,点击.bat文件,然后就出现一个黑框:
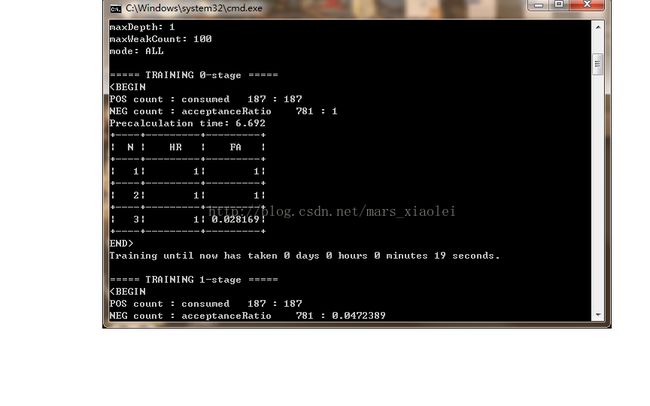
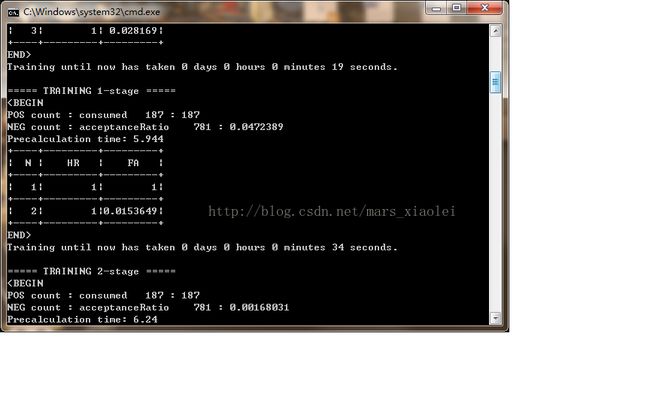
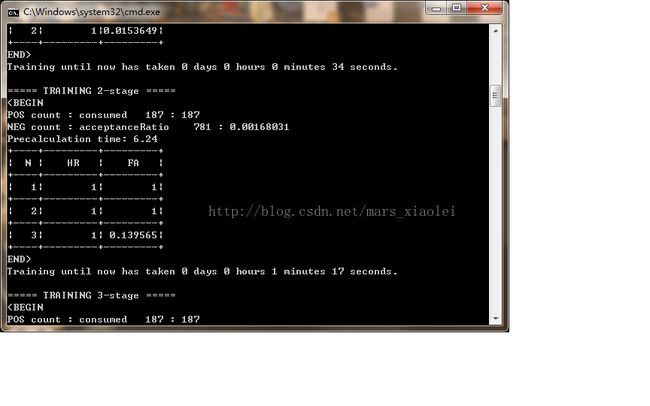
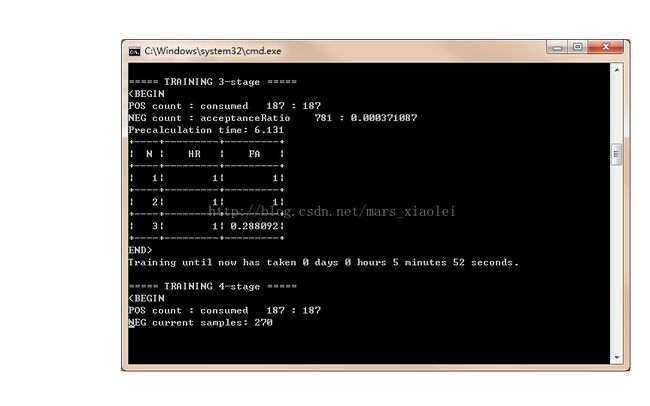
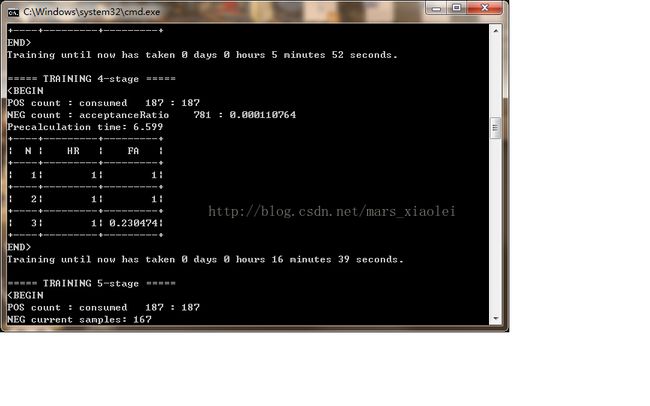
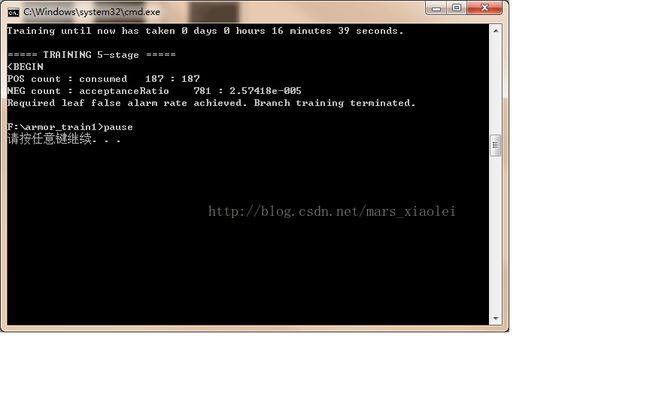
我自己感觉训练的不怎么行,我就是把自己的实际经验分享给大家,希望可以训练得更好。
葵花宝典秘籍:
a.H:训练层数,HR:击中率,FA:虚警率
通用参数:
-data
目录名,如不存在训练程序会创建它,用于存放训练好的分类器
-vec
包含正样本的vec文件名(由 opencv_createsamples 程序生成)
-bg
背景描述文件,也就是包含负样本文件名的那个描述文件
-numPos
每级分类器训练时所用的正样本数目
-numNeg
每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目
-numStages
训练的分类器的级数。
-precalcValBufSize
缓存大小,用于存储预先计算的特征值(feature values),单位为MB
-precalcIdxBufSize
缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB。内存越大,训练时间越短
-baseFormatSave
这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储
级联参数:
-stageType
级别(stage)参数。目前只支持将BOOST分类器作为级别的类型
-featureType<{HAAR(default),LBP}>
特征的类型: HAAR - 类Haar特征;LBP - 局部纹理模式特征
-w
-h
训练样本的尺寸(单位为像素)。必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致
Boosted分类器参数:
-bt<{DAB,RAB,LB,GAB(default)}>
Boosted分类器的类型: DAB - Discrete AdaBoost,RAB - Real AdaBoost,LB - LogitBoost, GAB - Gentle AdaBoost
-minHitRate
分类器的每一级希望得到的最小检测率(正样本被判成正样本的比例)。总的检测率大约为 min_hit_rate^number_of_stages。可以设很高,如0.999
-maxFalseAlarmRate
分类器的每一级希望得到的最大误检率(负样本被判成正样本的比例)。总的误检率大约为 max_false_alarm_rate^number_of_stages。可以设较低,如0.5
-weightTrimRate
Specifies whether trimming should be used and its weight. 一个还不错的数值是0.95
-maxDepth
弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps)
-maxWeakCount
每一级中的弱分类器的最大数目。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given-maxFalseAlarmRate
类Haar特征参数:
-mode
选择训练过程中使用的Haar特征的类型。 BASIC 只使用右上特征, ALL 使用所有右上特征和45度旋转特征
5、detectMultiScale函数参数说明
该函数会在输入图像的不同尺度中检测目标:
image -输入的灰度图像,
objects -被检测到的目标矩形框向量组,
scaleFactor -为每一个图像尺度中的尺度参数,默认值为1.1
minNeighbors -为每一个级联矩形应该保留的邻近个数,默认为3,表示至少有3次检测到目标,才认为是目标
flags -CV_HAAR_DO_CANNY_PRUNING,利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域;
CV_HAAR_SCALE_IMAGE,按比例正常检测;
CV_HAAR_FIND_BIGGEST_OBJECT,只检测最大的物体;
CV_HAAR_DO_ROUGH_SEARCH,只做粗略检测。默认值是0
minSize和maxSize -用来限制得到的目标区域的范围(先找maxsize,再用1.1参数缩小,直到小于minSize终止检测)
好的博客:http://blog.csdn.NET/wuxiaoyao12/article/details/39227189
http://blog.csdn.net/xidianzhimeng/article/details/10470839