快递100获取快递信息(爬虫)
快递100获取快递信息(爬虫)
最近搞js逆向,发现个逆向简单的网站,搞一波
1.搞程序先装环境,requests_html库请求加解析于一体,居家旅行必备
pip install requests
2.安装完成环境,成功一半,接下来分析网站
(1)打开网网址:https://www.kuaidi100.com/?from=openv
(2)F12,一键超神

(3)准备一个快递单号(中通除外,不知为毛查不了)

(4)浏览器搜索快递信息里的某个关键字,运气好搜到了,点进去
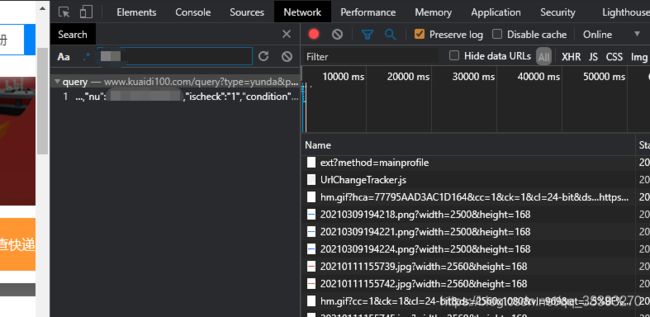
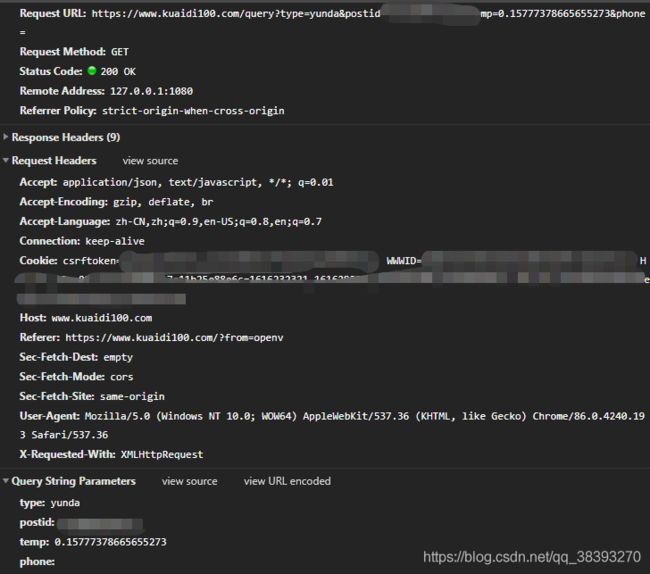
(5)请求头,请求体信息全有,python写一波请求,又是运气好发现可以获取到
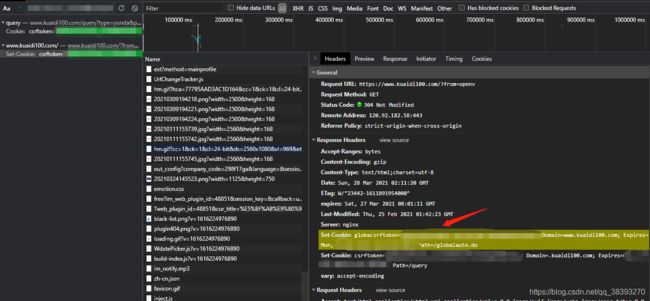
(6)可疑参数都怎么来的?首先请求头里发现只有Cookie的csrftoken值的变化是关键(等两天Cookie对比下就能知道),搜索一下值,运气再次爆表,搜到了
(7)接下来请求体参数,type快递名字,postid快递单号,temp像是时间戳名字,但不是,phone收件人电话(查顺丰快递需要这个)
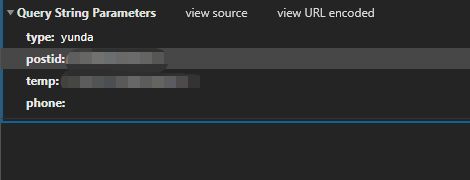
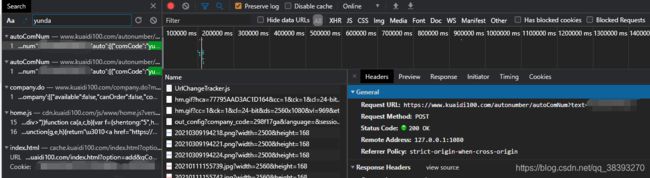
搜到开搞,获取快递名函数有了
(8)找temp,值没有搜到,搜字段,回到获取到信息的网址,看看请求怎么来的,这几个地方挨个点进去看并搜索字段名(大佬有高招麻烦告诉我)

找到,原来是个随机数,too young
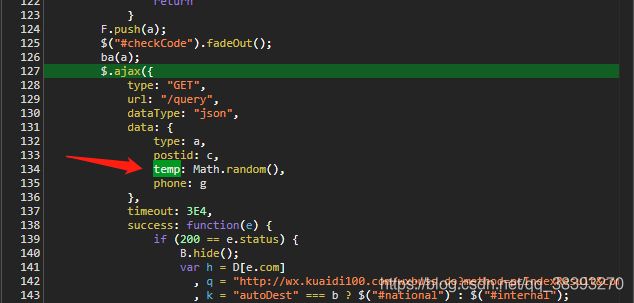
3.分析完毕,代码走起
(1)头部加载库
# @Time : 2021/3/22 16:40
# @Author : 张穆栩
# @File : kaudi100pro.py
# @Software: PyCharm
import re
import random
import requests_html
(2)面向对象,实例的参数
class Kuaidi(object):
def __init__(self, number):
# 转运信息url
self.url = 'https://www.kuaidi100.com/query'
# token url
self.token_url = 'https://www.kuaidi100.com/'
# 快递名url
self.name_url = 'https://www.kuaidi100.com/autonumber/autoComNum'
# 快递名参数
self.number_params = {
'text': number
}
self.token_params = {
'from': 'openv'
}
# 转运信息参数
self.temp = str(random.random())
self.params = {
'type': self.getname(),
'postid': number,
'temp': self.temp,
'phone': ''
}
csrftoken = self.gettoken()
self.headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36',
'Referer': 'https://www.kuaidi100.com/?from=openv',
'Cookie': 'csrftoken=' + csrftoken + '; WWWID=WWWF4FCD42239B8DAC700F22E0571D3952D; Hm_lvt_22ea01af58ba2be0fec7c11b25e88e6c=1615603420,1615603495,1616232321,1616289581; Hm_lpvt_22ea01af58ba2be0fec7c11b25e88e6c=1616289592'
}
(3)获取快递名称
# 获取快递名
def getname(self):
rous = requests_html.HTMLSession().post(self.name_url, params=self.number_params)
name = rous.json()['auto'][0]['comCode']
return name
(4)获取csrftoken
# 获取token
def gettoken(self):
rous = requests_html.HTMLSession().get(self.token_url, params=self.token_params)
Set_Cookie = rous.headers['Set-Cookie']
csrftoken = re.findall(', csrftoken=(.*?);', Set_Cookie)[0]
return csrftoken
(5)获取所有转运信息
# 获取转运信息
def getdata(self):
# 转运信息参数
Session = requests_html.HTMLSession()
rous = Session.get(self.url, headers=self.headers, params=self.params)
print(rous.text)
datas = rous.json()['data']
for data in datas:
print(data)
(6)然后再启动它,搞定
完整代码
import re
import time
import random
import requests_html
session = requests_html.HTMLSession()
class Kuaidi(object):
def __init__(self, number, phone):
# 转运信息url
self.url = 'https://www.kuaidi100.com/query'
# 获取token url和Hm_lvt
self.token_url = 'https://www.kuaidi100.com/'
# 获取快递名url
self.name_url = 'https://www.kuaidi100.com/autonumber/autoComNum'
# 快递名参数
self.number_params = {
'text': number
}
self.token_params = {
'from': 'openv'
}
# 转运信息参数
self.temp = str(random.random())
self.params = {
'type': self.getname(),
'postid': number,
'temp': self.temp,
'phone': ''
}
csrftoken = self.gettoken()
self.headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36',
'Referer': 'https://www.kuaidi100.com/?from=openv',
'Cookie': 'csrftoken=' + csrftoken[0] + '; Hm_lvt_' + csrftoken[1] + '=' + str(int(time.time())) + '; Hm_lpvt_' + csrftoken[1] + '=' + str(int(time.time()))
}
# 获取转运信息
def getdata(self):
# 转运信息参数
rous = session.get(self.url, headers=self.headers, params=self.params)
print(rous.text)
datas = rous.json()['data']
for data in datas:
print(data)
# 获取token 和 Hm_lvt
def gettoken(self):
rous = session.get(self.token_url, params=self.token_params)
Set_Cookie = rous.headers['Set-Cookie']
csrftoken = re.findall(', csrftoken=(.*?);', Set_Cookie)[0]
js_url = re.findall('https://cdn.kuaidi100.com/js/share/count.js(.*)">', rous.text)[0]
url = 'https://cdn.kuaidi100.com/js/share/count.js' + js_url
rous = session.get(url)
Hm_lvt = re.findall('https://hm.baidu.com/hm.js\?(.*)";', rous.text)[0]
return [csrftoken, Hm_lvt]
# 获取快递名
def getname(self):
rous = session.post(self.name_url, params=self.number_params)
name = rous.json()['auto'][0]['comCode']
return name
if __name__ == "__main__":
# 运单号
number = ''
# 手机后四位
phone = ''
Kuaidi(number, phone).getdata()