C语言编程规范 — 头文件、函数
0 编码规范说明
0.1 前言
为了提高产品或项目代码质量,软件开发人员编写出简洁、可靠、可维护、可测试、高效、可移植的代码,树立良好的编程规范是非常有必要的,良好的编程规范能提高编程效率,规避很多编码安全问题,写出高质量的代码。本博文主要是总结一些业界比较优秀的C语言编程规范,作为自己的编程参考材料。
0.2 编码总体原则
1、清晰第一
清晰性是易于维护、易于重构的程序必需具备的特征。代码首先是给人读的,好的代码应当可以像文章一样发声朗诵出来。
目前软件维护期成本占整个生命周期成本的40%~90%。根据业界经验,维护期变更代码的成本,小型系统是开发期的5倍,大型系统(100万行代码以上)可以达到100倍。业界的调查指出,开发组平均大约一半的人力用于弥补过去的错误,而不是添加新的功能来帮助公司提高竞争力。
“程序必须为阅读它的人而编写,只是顺便用于机器执行。” ——Harold Abelson 和 Gerald Jay Sussman
“编写程序应该以人为本,计算机第二。” ——Steve McConnell
一般情况下,代码的可阅读性高于性能,只有确定性能是瓶颈时,才应该主动优化。
2、简洁为美
简洁就是易于理解并且易于实现。代码越长越难以看懂,也就越容易在修改时引入错误。写的代码越多,意味着出错的地方越多,也就意味着代码的可靠性越低。因此,我们提倡大家通过编写简洁明了的代码来提升代码可靠性。
废弃的代码(没有被调用的函数和全局变量)要及时清除,重复代码应该尽可能提炼成函数。
3、选择合适的风格,与代码原有风格保持一致
产品所有人共同分享同一种风格所带来的好处,远远超出为了统一而付出的代价。在公司已有编码规范的指导下,审慎地编排代码以使代码尽可能清晰,是一项非常重要的技能。 如果重构 / 修改其他风格的代码时,比较明智的做法是根据 现有 代码 的 现有风格继续编写代码,或者使用格式转换工具进行转换成公司内部风格。
0.3 术语定义
原则:编程时必须坚持的指导思想。
规则(要求):编程时强制必须遵守的约定和要求。
建议:编程时必须加以考虑的约定。
示例:对此原则/规则/建议从正、反两个方面给出的例子。
延伸阅读材料:建议进一步阅读的参考资料。
1 头文件
背景
对于C语言来说,头文件的设计体现了大部分的系统设计。不合理的头文件布局是编译时间过长的根本原因,不合理的头文件实际上就是不合理的设计。
术语定义
依赖:本文特指编译依赖。若 x.h 包含了 y.h,则称作 x 依赖 y。依赖关系会进行传导,如 x.h 包含了 y.h,而 y.h 又包含了 z.h,则 x 通过 y 依赖了 z。依赖将导致编译时间的上升。虽然依赖是不可避免的,也是必须的,但是不良的设计会导致整个系统的依赖关系无比复杂,使得任意一个文件的修改都要重新编译整个系统,导致编译时间巨幅上升。
在一个设计良好的系统中,修改一个文件,只需要重新编译数个,甚至是一个文件。
某产品曾经做过一个实验,把所有函数的实现通过工具注释掉,其编译时间只减少了不到10%,究其原因,在于 A 包含 B,B 包含 C,C 包含 D,最终几乎每一个 .c 源文件都包含了项目组所有的头文件,从而导致绝大部分编译时间都花在解析头文件上。
某产品更有一个“优秀实践”,用于将 .c 文件通过工具合并成一个比较大的 .c 文件,从而大幅度提高编译效率。其根本原因还是在于通过合并 .c 文件减少了头文件解析的次数。但是,这样的“优秀实践”是对合理划分 .c 文件的一种破坏。
大部分产品修改一处代码,都得需要编译整个工程,对于TDD之类的实践,要求对于模块级别的编译时间控制在秒级,即使使用分布式编译也难以实现,最终仍然需要合理的划分头文件、以及头文件之间的包含关系,从根本上降低编译时间。
《Google C++ Style Guide》1.2 头文件依赖章节也给出了类似的阐述:
若包含了头文件 aa.h,则就引入了新的依赖:一旦 aa.h 被修改,任何直接和间接包含 aa.h 代码都会被重新编译。如果 aa.h 又包含了其他头文件如 bb.h,那么 bb.h 的任何改变都将导致所有包含了 aa.h 的代码被重新编译,在敏捷开发方式下,代码会被频繁构建,漫长的编译时间将极大地阻碍频繁构建。因此,我们应该倾向于减少包含头文件,尤其是在头文件中包含头文件,以控制改动代码后的编译时间。
合理的头文件划分体现了系统设计的思想,但是从编程规范的角度看,仍然有一些通用的方法,用来合理规划头文件。下文介绍的一些方法,对于合理规划头文件会有一定的帮助。
原则1.1 头文件中适合放置接口的声明,不适合放置实现
说明:头文件是模块(Module)或单元(Unit)的对外接口。头文件中应放置对外部的声明,如对外提供的函数声明、宏定义、类型定义等。
要求:
- 内部使用的函数(相当于类的私有方法)声明不应放在头文件中。
- 内部使用的宏、枚举、结构体定义不应放入头文件中。
- 变量定义不应放在头文件中,应放在 .c 文件中。
- 变量的声明尽量不要放在头文件中,亦即尽量不要使用全局变量作为接口。变量是模块或单元的内部实现细节,不应通过在头文件中声明的方式直接暴露给外部,应通过函数接口的方式进行对外暴露。 即使必须使用全局变量,也只应当在 .c 中定义全局变量,在 .h 中仅声明变量为全局的。
延伸阅读材料:《C语言接口与实现》(David R. Hanson 著 傅蓉 周鹏 张昆琪 权威 译 机械工业出版社 2004年1月)(英文版:“C Interface and Implementations”)
原则1.2 头文件应当职责单一
说明:头文件过于复杂,依赖过于复杂是导致编译时间过长的主要原因。很多现有代码中头文件过大,职责过多,再加上循环依赖的问题,可能导致为了在 .c 中使用一个宏,而包含十几个头文件。
错误示例:某平台定义WORD类型的头文件:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
...
typedef unsigned short WORD;
... 这个头文件不但定义了基本数据类型 WORD,还包含了 stdio.h syslib.h 等等不常用的头文件。如果工程中有10000个源文件,而其中100个源文件使用了 stdio.h 的 printf,由于上述头文件的职责过于庞大,而 WORD 又是每一个文件必须包含的,从而导致 stdio.h / syslib.h 等可能被不必要的展开了9900次,大大增加了工程的编译时间。
原则1.3 头文件应向稳定的方向包含
说明:头文件的包含关系是一种依赖,一般来说,应当让不稳定的模块依赖稳定的模块,从而当不稳定的模块发生变化时,不会影响(编译)稳定的模块。
就我们的产品来说,依赖的方向应该是: 产品依赖于平台,平台依赖于标准库。某产品线平台的代码中已经包含了产品的头文件,导致平台无法单独编译、发布和测试,是一个非常糟糕的反例。
除了不稳定的模块依赖于稳定的模块外,更好的方式是两个模块共同依赖于接口,这样任何一个模块的内部实现更改都不需要重新编译另外一个模块。在这里,我们假设接口本身是最稳定的。
延伸阅读材料:推荐开发人员使用“依赖倒置”原则,即由使用者指定接口,服务提供者实现接口,更具体的描述可以参见《敏捷软件开发:原则、模式与实践》(Robert C.Martin 著 邓辉 译 清华大学出版社2003年9月)的第二部分“敏捷设计”章节。
规则1.1 每一个 .c 文件应有一个同名 .h 文件,用于声明需要对外公开的接口
说明:如果一个 .c 文件不需要对外公布任何接口,则其就不应当存在,除非它是程序的入口,如 main() 函数所在的文件。
现有某些产品中,习惯一个 .c 文件对应两个头文件,一个用于存放对外公开的接口,一个用于存放内部需要用到的定义、声明等,以控制 .c 文件的代码行数。编者不提倡这种风格。这种风格的根源在于源文件过大,应首先考虑拆分 .c 文件,使之不至于太大。另外,一旦把私有定义、声明放到独立的头文件中,就无法从技术上避免别人 include 之,难以保证这些定义最后真的只是私有的。
错误示例:对于如下场景,如在一个 .c 中存在函数调用关系:
void foo()
{
bar();
}
void bar()
{
Do something;
}必须在 foo() 之前声明 bar(),否则会导致编译错误。
正确示例:这一类的函数声明,应当在 .c 的头部声明,并声明为 static,修改如下:
static void bar();
void foo()
{
bar();
}
void bar()
{
Do something;
}规则1.2 禁止头文件循环依赖
说明:头文件循环依赖,指 a.h 包含 b.h,b.h 包含 c.h,c.h 包含 a.h 之类导致任何一个头文件被修改,都导致所有包含了 a.h/b.h/c.h 的代码全部重新编译一遍。而如果是单向依赖,如 a.h 包含 b.h,b.h 包含 c.h,而 c.h 不包含任何头文件,则修改 a.h 不会导致包含了 b.h/c.h 的源代码重新编译。
规则1.3 .c/.h文件禁止包含用不到的头文件
说明:很多系统中头文件包含关系复杂,开发人员为了省事起见,可能不会去一一钻研,直接包含一切想到的头文件,甚至有些产品干脆发布了一个god.h,其中包含了所有头文件,然后发布给各个项目组使用,这种只图一时省事的做法,导致整个系统的编译时间进一步恶化,并对后来人的维护造成了巨大的麻烦。
规则1.4 头文件应当自包含。
说明:简单的说,自包含就是任意一个头文件均可独立编译。如果一个文件包含某个头文件,还要包含另外一个头文件才能工作的话,就会增加交流障碍,给这个头文件的用户增添不必要的负担。
示例:如果 a.h 不是自包含的,需要包含 b.h 才能编译,会带来的危害:每个使用 a.h 头文件的 .c 文件,为了让引入的 a.h 的内容编译通过,都要包含额外的头文件 b.h。额外的头文件 b.h 必须在 a.h 之前进行包含,这在包含顺序上产生了依赖。
注意:该规则需要与 “.c/.h文件禁止包含用不到的头文件” 规则一起使用,不能为了让 a.h 自包含,而在 a.h 中包含不必要的头文件。a.h 要刚刚可以自包含,不能在 a.h 中多包含任何满足自包含之外的其他头文件。
规则1.5 应当用 ifndef/define/endif 结构产生预处理代码块,防止头文件被重复包含
说明:多次包含一个头文件可以通过认真的设计来避免。如果不能做到这一点,就需要采取阻止头文件内容被包含多于一次的机制。
通常的手段是为每个头文件配置一个宏,当头文件第一次被包含时就定义这个宏,并在头文件被再次包含时使用它以排除文件内容。
所有头文件都应当使用 #define 宏命名防止头文件被多重包含,命名格式为 FILENAME_H,为了保证唯一性,更好的命名是PROJECTNAME_PATH_FILENAME_H。
注意:没有在宏的最前面加上单下划线"_",是因为一般以单下划线"_"和双下划线"__"开头的标识符为 ANSI/C 等使用,在有些静态检查工具中,若全局可见的标识符以"_"开头会给出告警。
定义包含保护符时,应该遵守如下规则:
1)保护符使用唯一名称;
2)不要在受保护部分的前后放置代码或者注释。
正确示例:假定VOS工程的 timer 模块的 timer.h,其目录为 VOS/include/timer/timer.h,应按如下方式保护:
#ifndef VOS_INCLUDE_TIMER_TIMER_H //宏名的首尾不要加下划线
#define VOS_INCLUDE_TIMER_TIMER_H
...
#endif
// 也可以使用如下简单方式保护:
#ifndef TIMER_H
#define TIMER_H
...
#endif例外情况:头文件的版权声明部分以及头文件的整体注释部分(如阐述此头文件的开发背景、使用注意事项等)可以放在保护符(#ifndef XX_H)前面。
规则1.6 禁止在头文件中定义变量
说明:在头文件中定义变量,将会由于头文件被其他 .c 文件包含而导致变量重复定义。
规则1.7 只能通过包含头文件的方式使用其他 .c 提供的接口,禁止在.c 中通过 extern 的方式引用外部函数接口、变量
说明:若 a.c 使用了 b.c 定义的foo()函数,则应当在 b.h 中声明 extern int foo(int input); 并在a.c中通过 #include
规则1.8 禁止在 extern "C" 中包含头文件
说明:在 extern "C" 中包含头文件,会导致 extern "C" 嵌套,Visual Studio 对 extern "C" 嵌套层次有限制,嵌套层次太多会导致编译错误。
在 extern "C" 中包含头文件,可能会导致被包含头文件的原有意图遭到破坏。例如,存在 a.h 和 b.h 两个头文件:
//a.h头文件的内容
#ifndef A_H
#define A_H
#ifdef __cplusplus
void foo(int);
#define a(value) foo(value)
#else
void a(int)
#endif
#endif // A_H
//b.h头文件的内容
#ifndef B_H
#define B_H
#ifdef __cplusplus
extern "C" {
#endif
#include "a.h"
void b();
#ifdef __cplusplus
}
#endif
#endif // B_H使用C++编译器展开 b.h,将会得到:
extern "C" {
void foo(int);
void b();
}按照 a.h 作者的本意,函数 foo() 是一个C++自由函数,其链接规范为 “C++”。但在 b.h 中,由于 #include "a.h" 被放到了 extern "C" { } 的内部,函数 foo() 的链接规范被不正确地更改了,变成了 C语言 的链接规范了,这显然是不对的。
错误示例:错误的使用方式:
extern "C"
{
#include "xxx.h"
...
}正确示例:正确的使用方式:
#include "xxx.h"
extern "C"
{
...
} 规则1.9 用 #include
规则1.10 用 #include “filename.h” 格式来引用非标准库的头文件(编译器将从用户的工作目录开始搜索)
建议1.1 一个模块通常包含多个 .c 文件,建议放在同一个目录下,目录名即为模块名。为方便外部使用者,建议每一个模块提供一个 .h ,文件名为目录名
说明:需要注意的是,这个.h并不是简单的包含所有内部的.h,它是为了模块使用者的方便,对外整体提供的模块接口。
以Google test(简称GTest)为例,GTest 作为一个整体对外提供C++单元测试框架,其1.5版本的 gtest 工程下有6个源文件和12个头文件。但是它对外只提供一个 gtest.h,只要包含 gtest.h 即可使用GTest提供的所有对外提供的功能,使用者不必关系 GTest 内部各个文件的关系,即使以后 GTest 的内部实现改变了,比如把一个C源文件拆成两个源文件,使用者也不必关心,甚至如果对外功能不变,连重新编译都不需要。
对于有些模块,其内部功能相对松散,可能并不一定需要提供这个 .h,而是直接提供各个子模块或者 .c 的头文件。
比如产品普遍使用的 VOS,作为一个大模块,其内部有很多子模块,他们之间的关系相对比较松散,就不适合提供一个 vos.h。而VOS的子模块,如Memory(仅作举例说明,与实际情况可能有所出入),其内部实现高度内聚,虽然其内部实现可能有多个.c和.h,但是对外只需要提供一个Memory.h 声明接口。
建议1.2 如果一个模块包含多个子模块,则建议每一个子模块提供一个对外的 .h,文件名为子模块名
说明:降低接口使用者的编写难度
建议1.3 头文件不要使用非习惯用法的扩展名,如 .inc
说明:目前很多产品中使用了 .inc 作为头文件扩展名,这不符合C语言的习惯用法。在使用 .inc 作为头文件扩展名的产品,习惯上用于标识此头文件为私有头文件。但是从产品的实际代码来看,这一条并没有被遵守,一个 .inc 文件被多个 .c 包含比比皆是。
除此之外,使用 .inc 还导致 source insight、Visual stduio等IDE工具无法识别其为头文件,导致很多功能不可用,如“跳转到变量定义处”。虽然可以通过配置,强迫IDE识别 .inc 为头文件,但是有些软件无法配置,如 Visual Assist 只能识别 .h 而无法通过配置识别 .inc 为头文件。
建议1.4 同一产品或项目使用统一的包含头文件的排列方式
说明:常见的包含头文件排列方式:功能块排序、文件名升序、稳定度排序。
正确示例1:以升序方式排列头文件可以避免头文件被重复包含:
#include
#include
#include
#include
#include 正确示例2:以稳定度排序,建议将不稳定的头文件放在前面,如把产品的头文件放在平台的头文件前面:
#include
#include 相对来说,product.h 修改较为频繁,如果有错误,不必编译 platform.h 就可以发现 product.h 中的错误,可以部分减少编译时间。
在 .c 文件中也可以按照合理的顺序包含头文件:C标准库—>操作系统库—>平台库—>项目公共库—>自己自定义的头文件—>对应 .c 文件的 .h 头文件。当然,把对应 .c 文件的 .h 文件也可以放在第一个位置中。
正确示例:.c 源文件包含 .h 头文件的顺序。
//lte_module.c
#include //引用C标准库的头文件
#include
#include
...
#include //引用Linux系统库的头文件
#include
#include
...
#include "vos.h" //引用平台库的头文件
...
#include "common_message.h" //引用项目公共库头文件
...
#include "lte_config.h" //引用项目子模块自定义的头文件
#include "lte_session.h"
...
#include "lte_module.h" //引用.c对应的.h头文件
... 建议1.5 头文件中只存放变量的“声明”而不存放变量的“定义”
说明:头文件中可以声明类型定义,如使用 typedef 关键字声明类型别名,声明结构体类型、枚举类型等,但是不进行变量的定义。
建议1.6 不提倡使用全局变量,尽量不要在头文件中出现像 extern int value; 这类声明
正确示例:
#ifndef GRAPHICS_H //防止 graphics.h 被重复包含
#define GRAPHICS_H
void Function1(…); //全局函数声明
...
typedef struct { //结构体类型声明(大驼峰风格)
{
...
}StudentInfo;
typedef enum { //枚举类型声明(大驼峰风格)
...
}AlarmType;
#endif2 函数
函数设计的精髓:编写整洁函数,同时把代码有效组织起来。
整洁函数要求:代码简单直接、不隐藏设计者的意图、用干净利落的抽象和直截了当的控制语句将函数有机组织起来。
代码的有效组织包括:逻辑层组织和物理层组织两个方面。逻辑层,主要是把不同功能的函数通过某种联系组织起来,主要关注模块间的接口,也就是模块的架构。物理层,无论使用什么样的目录或者名字空间等,需要把函数用一种标准的方法组织起来。例如:设计良好的目录结构、函数名字、文件组织等,这样可以方便查找。
原则2.1 一个函数仅完成一件功能
说明:一个函数实现多个功能给开发、使用、维护都带来很大的困难。
将没有关联或者关联很弱的语句放到同一函数中,会导致函数职责不明确,难以理解,难以测试和改动。
案例:realloc 函数。在标准C语言中,realloc 是一个典型的不良设计。这个函数基本功能是重新分配内存,但它承担了太对的其他任务:如果传入的指针参数为NULL就分配内存,如果传入的大小参数为0就释放内存,如果可行则就地重新分配,如果不行则移到其他地方分配。如果没有足够可用的内存来完成重新分配(扩大原来的内存块或者分配新的内存块),则返回NULL,而原来的内存块保持不变。这个函数不易扩展,容易导致问题。
例如,下面的代码容易导致内存泄漏:
char *buffer = (char *)malloc(XXX_SIZE);
......
buffer = (char *)realloc(buffer, NEW_SIZE);如果没有足够可用的内存用来完成重新分配,函数返回NULL,导致 buffer 原来指向的堆内存被丢失,但是原来的堆内存却还未被释放掉,造成了内存泄漏。
延伸阅读材料:《敏捷软件开发:原则、模式与实践》(Robert C.Martin 著 邓辉 译 清华大学出版社2003年9月)第八章,单一职责原则(SRP)。
原则2.2 重复代码应该尽可能提炼成函数
说明:重复代码提炼成函数可以带来维护成本的降低。
重复代码是产品/项目不良代码最典型的特征之一。在 “代码能用就不改” 的指导原则之下,大量的烟囱式设计及其实现充斥着各产品代码之中。新需求增加带来的代码拷贝和修改,随着时间的迁移,产品中堆砌着许多类似或者重复的代码。
项目组应当使用代码重复度检查工具,在持续集成环境中持续检查代码重复度指标变化趋势,并对新增重复代码及时重构。当一段代码重复两次时,即应考虑消除重复,当代码重复超过三次时,应当立刻着手消除重复。
一般情况下,可以通过提炼函数的形式消除重复代码。
规则2.1 避免函数过长,新增函数不超过 50 行 (非空非注释行)
说明:本规则仅对新增函数做要求,对已有函数修改时,建议不增加代码行。
过长的函数往往意味着函数功能不单一,过于复杂。
函数的有效代码行数,即NBNC(非空非注释行)应当在[1,50]区间。
例外:某些实现算法的函数,由于算法的聚合性与功能的全面性,可能会超过50行。
延伸阅读材料:业界普遍认为一个函数的代码行不要超过一个屏幕,避免来回翻页影响阅读;一般的代码度量工具建议都对此进行检查,例如Logiscope的函数度量:"Number of Statement" (函数中的可执行语句数)建议不超过20行,QA C建议一个函数中的所有行数(包括注释和空白行)不超过50行。
规则2.2 避免函数的代码块嵌套过深,新增函数的代码块嵌套不超过4层
说明:本规则仅对新增函数做要求,对已有函数修改时,建议不增加嵌套层次。
函数的代码块嵌套深度指的是函数中的代码控制块(例如:if、for、while、switch等)之间互相包含的深度。每级嵌套都会增加阅读代码时的脑力消耗,因为需要在脑子里维护一个“栈”(比如,进入条件语句、进入循环......)。应该做进一步的功能分解,从而避免使代码的阅读者一次记住太多的上下文。优秀代码参考值:[1, 4]。
错误示例:代码嵌套深度为5层:
void serial (void)
{
if (!Received)
{
TmoCount = 0;
switch (Buff)
{
case AISGFLG:
if ((TiBuff.Count > 3)&& ((TiBuff.Buff[0] == 0xff) || (TiBuf.Buff[0] == CurPa.ADDR)))
{
Flg7E = false;
Received = true;
}
else
{
TiBuff.Count = 0;
Flg7D = false;
Flg7E = true;
}
break;
default:
break;
}
}
}规则2.3 可重入函数应避免使用共享变量;若需要使用,则应通过互斥手段(互斥锁、信号量)对其加以保护
说明:可重入函数是指可能被多个任务并发调用的函数。在多任务操作系统中,函数具有可重入性是多个任务可以共用此函数的必要条件。共享变量指的全局变量和static变量。
编写C语言的可重入函数时,不应使用 static 静态局部变量,否则必须经过特殊处理,才能使函数具有可重入性。
错误示例:函数 square_exam 返回全局变量 g_exam 的平方值。那么如下函数不具有可重入性。
int g_exam; //定义全局变量
unsigned int example( int para )
{
unsigned int temp;
g_exam = para; //(**) 函数中使用全局变量,影响函数的可重入性
temp = square_exam ( );
return temp;
}此函数若被多个线程调用的话,其结果可能是未知的,因为当(**)语句刚执行完后,另外一个使用本函数的线程可能正好被激活,那么当新激活的线程执行到此函数时,将使 g_exam 被赋于另一个不同的para值,所以当控制重新回到 “temp =square_exam();” 后,计算出的 temp 很可能不是预想中的结果。
正确示例:此函数应如下改进:
int g_exam;
unsigned int example( int para )
{
unsigned int temp;
[申请信号量操作] //若申请不到“信号量”,说明另外的进程正
g_exam = para; //给g_exam赋值并计算其平方过程中(即正在使用此
temp = square_exam( ); //信号),本进程必须等待其释放信号后,才可继
[释放信号量操作] //续执行。其它线程必须等待本线程释放信号量后
//才能再使用本信号。
return temp;
}规则2.4 对参数的合法性检查,由调用者负责还是由接口函数负责,应在项目组/模块内应统一规定。缺省由调用者负责。
说明:对于模块间接口函数的参数的合法性检查这一问题,往往有两个极端现象,即:要么是调用者和被调用者对参数均不作合法性检查,结果就遗漏了合法性检查这一必要的处理过程,造成问题隐患;要么就是调用者和被调用者均对参数进行合法性检查,这种情况虽不会造成问题,但产生了冗余代码,降低了效率。
错误示例:下面注释部分的代码在每一个函数中都写了一次,导致代码有较多的冗余。如果函数的参数比较多,而且判断的条件比较复杂(比如:一个整数数字需要判断范围等),那么冗余的代码会大面积充斥着业务代码。
void PidMsgProc(MsgBlock *msg)
{
MsgBlock *func = NULL;
/*if (msg == NULL) {
return;
}*/
......
GetMsgProcFun(msg, &func);
return;
}
int GetMsgProcFun(MsgBlock *msg, MsgProcItem **func)
{
/*if (msg == NULL) {
return 1;
}*/
......
*func = VOS_NULL_PTR;
for (Index = 0; Index < NELEN(g_MsgProcTable); Index++)
{
if(....) {
*func = &(g_MsgProcTable[Index]);
return 0;
}
}
return 1;
}
int ServiceProcess(int cbNo, MsgBlock *msg)
{
/*if (msg == NULL) {
return 1;
}*/
......
//业务处理代码
......
return 0;
}规则2.5 对函数的错误返回码要全面处理
说明:一个函数(标准库中的函数 / 第三方库函数 / 用户定义的函数)能够提供一些指示错误发生的方法。这可以通过使用错误标记、特殊的返回数据或者其他手段,不管什么时候函数提供了这样的机制,调用程序应该在函数返回时立刻检查错误指示。
错误示例:下面的代码导致宕机:
FILE *fp = fopen("./writeAlarmLastTime.log", "r");
if (fp == NULL) {
return;
}
char buff[128] = "";
fscanf(fp, "%s", buff); //读取最新的告警时间:由于文件writeAlarmLastTime.log为空,导致buff为空
fclose(fp);
long fileTime = GetAlarmTime(buff); //解析获取最新的告警时间:GetAlarmTime函数未检查buff指针,导致宕机正确写法:
FILE *fp = fopen("./writeAlarmLastTime.log", "r");
if (fp == NULL) {
return;
}
char buff[128] = "";
if (fscanf(fp, "%s", buff) == EOF) { //检查函数fscanf的返回值,确保读到数据
fclose(fp);
return;
}
fclose(fp);
long fileTime = GetAlarmTime(buff); //解析获取最新的告警时间规则2.6 设计高扇入,合理扇出(小于7)的函数
说明:扇出是指一个函数直接调用(控制)其它函数的数目,而扇入是指有多少个上级函数调用它。
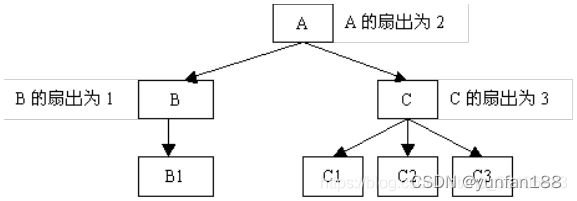
扇出过大,表明函数过分复杂,需要控制和协调过多的下级函数;而扇出过小,例如:总是1,表明函数的调用层次可能过多,这样不利于程序阅读和函数结构的分析,并且程序运行时会对系统资源如堆栈空间等造成压力。通常函数比较合理的扇出(调度函数除外)通常是3~5。
扇出太大,一般是由于缺乏中间层次,可适当增加中间层次的函数。扇出太小,可把下级函数进一步分解多个函数,或合并到上级函数中。当然分解或合并函数时,不能改变要实现的功能,也不能违背函数间的独立性。扇入越大,表明使用此函数的上级函数越多,这样的函数使用效率高,但不能违背函数间的独立性而单纯地追求高扇入。公共模块中的函数及底层函数应该有较高的扇入。
较良好的软件结构通常是顶层函数的扇出较高,中层函数的扇出较少,而底层函数则扇入到公共模块中。
延伸阅读材料:扇入(Fan-in)和扇出(Fan-out)是 Henry 和 Kafura 在1981年引入的,用来说明模块间的耦合(coupling),后面人们扩展到函数/方法、模块/类、包等。
规则2.7 废弃代码(没有被调用的函数和变量) ) 要及时清除
说明:程序中的废弃代码不仅占用额外的空间,而且还常常影响程序的功能与性能,很可能给程序的测试、维护等造成不必要的麻烦。
规则2.8 不要省略函数返回值类型。
说明:C语言中,凡不加类型说明的函数,一律自动按整型处理,即视函数返回值默认为整型。这样做不会有什么好处,却容易被误解为 void 类型。
建议2.1 函数不变参数使用const修饰
说明:不变的值更易于理解/跟踪和分析,把const作为默认选项,在编译时会对其进行检查,使代码更牢固/更安全。
如果参数是指针,且仅作输入用,则应在类型前加 const,以防止该指针在函数体内被意外修改。
正确示例:C99标准 7.21.4.4 中 strncmp 的例子,不变参数声明为const。
int strncmp(const char *s1, const char *s2, register size_t n)
{
register unsigned char u1, u2;
while (n-- > 0)
{
u1 = (unsigned char) *s1++;
u2 = (unsigned char) *s2++;
if (u1 != u2)
{
return u1 - u2;
}
if (u1 == '\0')
{
return 0;
}
}
return 0;
}建议2.2 函数应避免使用全局变量、静态局部变量和 I/O 操作,不可避免的地方应集中使用
说明:带有内部“存储器”的函数的功能可能是不可预测的,因为它的输出可能取决于内部存储器(如某标记)的状态。这样的函数既不易于理解又不利于测试和维护。在C语言中,函数的 static 局部变量是函数的内部存储器,有可能使函数的功能不可预测。
错误示例:如下函数,其返回值(即功能)是不可预测的。
unsigned int integer_sum( unsigned int base )
{
unsigned int index;
static unsigned int sum = 0; //注意,sum是static类型的局部变量
//若改为auto类型,则函数即变为可预测
for (index = 1; index <= base; index++)
{
sum += index;
}
return sum;
}这是因为静态局部变量是存放在进程空间的静态区的,而不是存放在函数的堆栈区,而auto局部变量是存放在函数的堆栈区的。
建议2.3 检查函数所有非参数输入的有效性,如数据文件、公共变量等
说明:函数的输入主要有两种:一种是参数输入;另一种是全局变量、数据文件的输入,即非参数输入。函数在使用输入参数之前,应进行有效性检查。
错误示例:下面的代码可能会导致宕机。
hr = root_node->get_first_child(&log_item); //list.xml为空,导致读出log_item为空
......
hr = root_node->get_next_sibling(&media_next_node); //log_item为空,导致宕机正确写法:确保读出的内容非空。
hr = root_node->get_first_child(&log_item);
......
if (log_item == NULL) //确保读出的内容非空
{
return retValue;
}
hr = root_node->get_next_sibling(&media_next_node);建议2.4 函数的参数个数不超过5个
说明:函数的参数过多,会使得该函数易于受外部(其他部分的代码)变化的影响,从而影响维护工作。函数的参数过多同时也会增大测试的工作量。
函数的参数个数不要超过5个,如果超过了建议拆分为不同函数。
建议2.5 除打印类函数外,不要使用可变长参函数
说明:可变长参函数的处理过程比较复杂容易引入错误,而且性能也比较低,使用过多的可变长参函数将导致函数的维护难度大大增加。
可变长参函数一般用于打印日志类的函数当中。
示例:打印不同类型日志的可变长参日志函数原型声明。
void vos_log_debug(char *module, char *fmt,...);
void vos_log_info(char *module, char *fmt,...);
void vos_log_warn(char *module, char *fmt,...);
void vos_log_error(char *module, char *fmt,...);
void vos_log_fatal(char *module, char *fmt,...);建议2.6 在 .c 源文件范围内声明和定义的所有函数,除非外部可见,否则应该增加static关键字
说明:如果一个函数只是在同一文件中的其他地方调用,那么就用static声明。使用static确保只是在声明它的文件中是可见的,并且避免了和其他文件或库中的相同标识符发生混淆的可能性。
正确示例:建议定义一个STATIC宏,在调试阶段,将STATIC定义为static,版本发布时,改为空,以便于后续的打热补丁等操作。
#ifdef _DEBUG
#define STATIC static
#else
#define STATIC
#endif参考
《华为C语言编程规范(2826-2011.5).pdf》
《高质量C/C++编程指南(林锐-2001).pdf》
华为C语言编程规范(精华总结)