【目标检测基础】
目标检测
对计算机而言,能够“看到”的是图像被编码之后的数字,但它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。
目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置
分类 VS 检测
分类

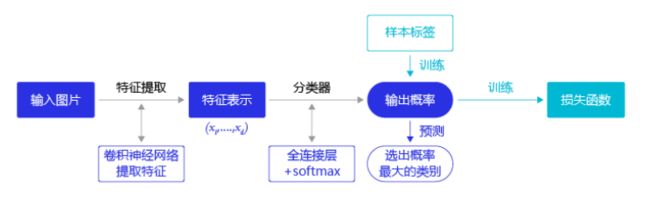
分类问题:所属类别(用卷积网络提取特征,然后用特征预测分类概率)
图像分类流程示意图:
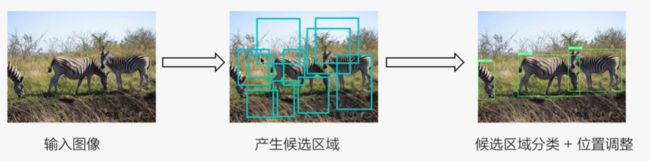
通过图(a),分类任务:得到最终的分类所属类别可能是动物或是斑马
检测

检测问题:所属类别 + 物体位置
不仅要检测出图片上出现了哪些物体,还要标出物体所在的区域
最终要完成的检测任务效果是要做出来矩形框:把物体所在的区域给框住,并且告诉人们,这是一个什么类别的物体。
目标检测发展历程
假设我们现在有某种方式可以在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域,然后对每个候选区域,可以把它单独当成一幅图像来看待,使用图像分类模型对它进行分类,看它属于哪个类别或者背景。
![]()
###
检测算法的核心问题
-
如何产生候选区域,并对他们进行标注
-
如何提取图像特征,并将提取道德特征图与候选区域的类别和位置进行关联。
穷举法(笨蛋算法)
A为图像上的某个像素点,B为A右下方另外一个像素点,A、B两点可以确定一个矩形框,记作AB。
-
如图3(a)所示:A在图片左上角位置,B遍历除A之外的所有位置,生成矩形框A1B1, …, A1Bn, …
-
如图3(b)所示:A在图片中间某个位置,B遍历A右下方所有位置,生成矩形框AkB1, …, AkBn, …
当A遍历图像上所有像素点,B则遍历它右下方所有的像素点,最终生成的矩形框集合{AiBj}将会包含图像上所有可以选择的区域。

###
两阶段目标检测算法

区域卷积神经网络(R-CNN)模型
使用传统图像算法 Selective Search 产生候选区域。
Selective Search: step0:生成区域集R step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…} step2:找出相似度最高的两个区域,将其合并为新集,添加进R step3:从S中移除所有与step2中有关的子集 step4:计算新集与所有子集的相似度 step5:跳至step2,直至S为空
Fast R-CNN模型
通过将不同区域的物体共用卷积层的计算,大大缩减了计算量,提高了处理速度,而且还引入了调整目标物体位置的回归方法,进一步提高了位置预测的准确性。
Faster R-CNN模型
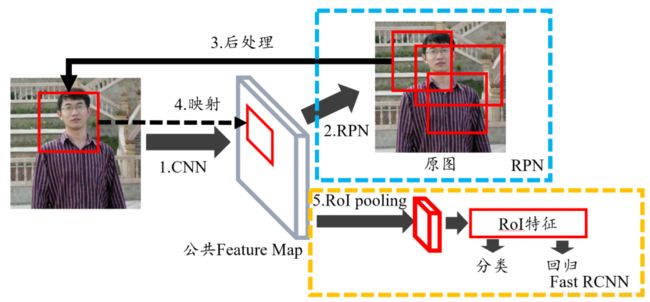
提出了RPN的方法来产生物体的候选区域,这一方法不再需要使用传统的图像处理算法来产生候选区域,进一步提升了处理速度。
RPN就是用来提取候选框的网络。用滑动窗口来扫描图像,并寻找存在目标的区域。
RPN 扫描的区域被称为 anchor,这是在图像区域上分布的矩形,实际上,在不同的尺寸和长宽比下,图像上会有将近 20 万个 anchor,并且它们互相重叠以尽可能地覆盖图像。
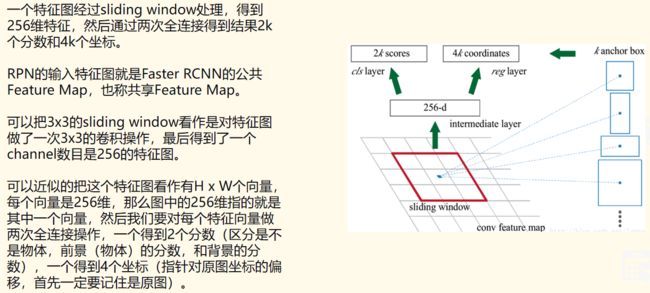
Mask R-CNN模型
只需要在Faster R-CNN模型上添加比较少的计算量,就可以同时实现目标检测和物体实例分割两个任务。
单阶段目标检测算法

典型算法:SSD、YOLO
只使用一个网络同时产生候选区域并预测出物体的类别和位置
基础知识
边界框(bounding box)
检测任务需要同时预测物体的类别和位置,通常使用边界框(bounding box,bbox)来表示物体的位置。
正好能包含住物体的矩形框。
边界框的表示方法

真实框(gt_box)
数据集标注中给出的目标物体对应的边界框,ground truth box ,简称gt_box
预测框(pred_box)
由模型预测输出的可能包含目标物体的边界框prediction box,简称 pred_box
检测任务输出

锚框(Anchor box)
人为构造出来的假想框,以某种指定的规则生成的矩形框。
生成方式
先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。
指定宽度和高度,在图像上选一个中心点。

在一般目标检测任务里,流程如下:

预测框
可以理解为是在锚框的基础上进行微调,由模型预测调整的幅度
每个候选区域可以看做类似机器学习里面的一个样本,如果给他们打上标签,就可以建立模型了。
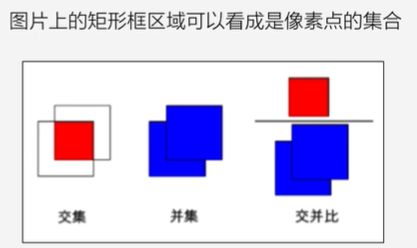
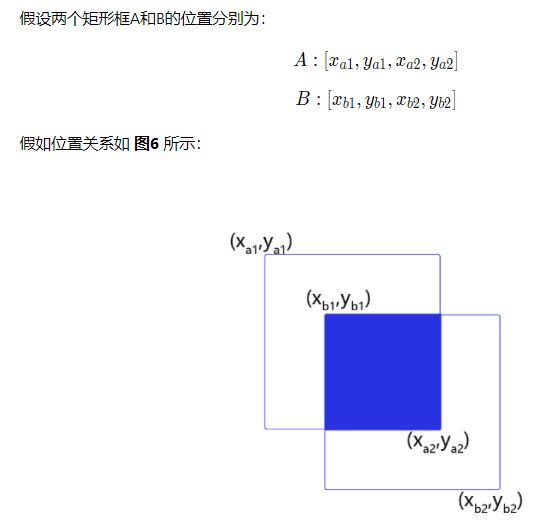
交并比(IoU)
如何衡量锚框跟真实框之间的关系呢?
使用交并比(Intersection of Union,IoU)作为衡量指标。

例如:

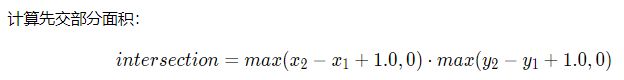
"+1" 的目的,是为了排除两个框之间重叠的像素对面积的影响,取max(*,0)的目的是为了避免出现负数的情况
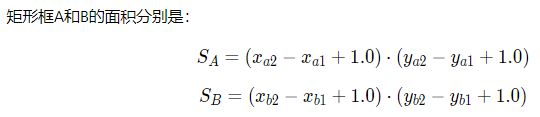
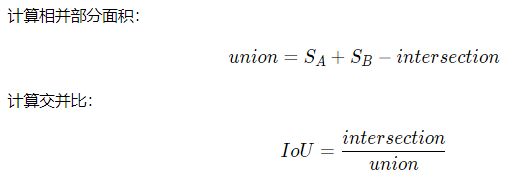
附:
intersection()
返回包含两个或更多集合之间相似性的集合
含义:返回的集合包含两个集合中都存在的项目,或者使用两个以上的集合进行比较,则在所有集合中都存在。
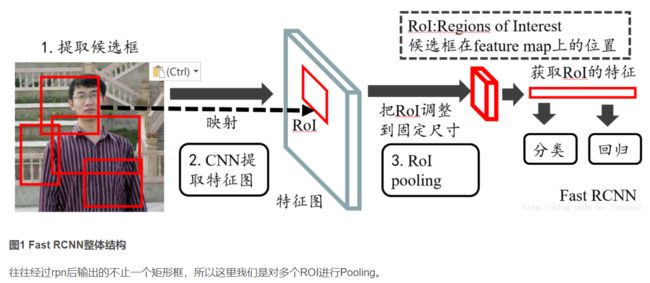
ROI Pooling
是pooling层的一种,指的是在“特征图上的框”。
特点是 输入特征图 尺寸不固定、但 输出特征图 尺寸固定。
-
在Fast RCNN中, RoI是指Selective Search完成后得到的“候选框”在特征图上的映射,如下图所示
-
在Faster RCNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs。