Maskrcnn-benchmark利用自己的数据进行目标检测和关键点检测
Maskrcnn-benchmark利用自己的数据进行目标检测和关键点检测
- 介绍
- 0 环境配置
-
-
- Requirements
- Installation
-
- 1 目标检测任务
-
- 1.1 数据准备
-
- 1.1.1 coco数据集的介绍
- 1.1.2 转coco数据
- 1.1.3 数据检验
- 1.2 数据集在源代码文件中的组织结构
- 1.3 使用预训练模型
- 1.4 源码文件的修改
- 1.5 模型训练
- 1.6 模型验证
- 1.7 前传
- 1.8 几个常见的问题
- 2 关键点检测任务
-
- 2.1 数据准备
- 2.2 源码文件的修改
- 2.3 数据组织/训练/验证
- 2.4 前传
介绍
本文主要利用了Facebook开源的Maskrcnn-benchmark来进行一个自己的项目,该项目的主要任务是对图片中的电表位置进行定位以及进行关键点的检测。网上对Maskrcnn-benchmark训练自己的数据大都集中在如何用于目标检测的任务上,对关键点检测的应用很少涉及,这篇文章对两者都作一个阐述。
maskrcnn-benchmark的github地址
0 环境配置
这一步假设机器里面已经预装了conda环境
请一定要耐心和细致,按照要求一步步来,心态不要崩!!!
首先按照官方各出的安装步骤进行环境配置
注意:
pytorch或pytorch night 的版本必须为1.0.0,torchvision版本也不能太旧,这里使用0.2.2(这是个坑)!!!
安装的时候需要安装过去的版本,因此安装命令需要给出版本,不然默认给定安装最新的版本,那就呵呵了!
Requirements
- PyTorch 1.0 from a nightly release. It will not work with 1.0 nor 1.0.1. Installation instructions can be found in https://pytorch.org/get-started/locally/
- torchvision from master
- cocoapi
- yacs
- matplotlib
- GCC >= 4.9
- OpenCV
- CUDA >= 9.0
Installation
conda create --name maskrcnn_benchmark -y conda activate maskrcnn_benchmark conda install ipython pip pip install ninja yacs cython matplotlib tqdm opencv-python # pip install -i http://pypi.douban.com/simple/ ...... #如果速度慢可以考虑使用豆瓣的源 conda install -c pytorch pytorch-nightly torchvision cudatoolkit=9.0 #上面的命令只能安装最新版本,因此我们需要旧版本必须加上版本号,而且torchvision版本需要大于0.2.2 conda install -c pytorch pytorch-nightly=1.0.1 torchvision=2 .2.2 cudatoolkit=9.0 export INSTALL_DIR=$PWD # install pycocotools cd $INSTALL_DIR git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPI python setup.py build_ext install # install apex cd $INSTALL_DIR git clone https://github.com/NVIDIA/apex.git cd apex python setup.py install --cuda_ext --cpp_ext # install PyTorch Detection cd $INSTALL_DIR git clone https://github.com/facebookresearch/maskrcnn-benchmark.git cd maskrcnn-benchmark # python setup.py build develop unset INSTALL_DIR
1 目标检测任务
1.1 数据准备
Maskrcnn-benchmark支持voc和coco格式的数据,但voc格式似乎针对的任务比较单一,因此建议使用coco格式来准备自己的训练数据。或者,如果自己有时间也可以尝试写一个自己的dataset类,仿照CocoDataset类来写。
1.1.1 coco数据集的介绍
该部分网上各种教程很多,可自行甄别优质教程,关键是要全面,细致。
1.1.2 转coco数据
关于数据转换部分,每个任务有每个任务的具体情形,无法一概而论,不过只要把coco数据集的基本结构了解了,接下来就是依葫芦画瓢的写一个coco格式的.json文件。这一步可能会比较耗费时间,但是如果耐心一点,也能很快写出来。可以参照网上诸多的例如voc格式转coco的代码,自己稍作修改一般能得到自己想要的结果。
1.1.3 数据检验
得到coco格式的数据之后最好是把标签可视化一下,当然如果嫌麻烦,可以先训练,发现效果不行再回头来核查数据。
1.2 数据集在源代码文件中的组织结构
假设你此时位于maskrcnn-benchmark/目录下datasets的组织结构如下
datasets
- coco
- annotations
- instances_train2014.json //训练标签
- instances_test2014.json //验证标签
- train2014 //训练图片
- val2014 //验证图片
为了方便建议仿照上面这样的coco标准命名,但上面的所有名字都不是一定要求这样写的,自己可以合理命名,只要程序中的各个与数据路径有关的地方一一对应上即可。
1.3 使用预训练模型
下面说明一下预训练模型的使用,首先给出模型有关的配置文件所在位置
maskrcnn-benchmark/configs/里面的所有.yaml文件都可以使用,每一个里面的有一个对应将使用的预训练模型,训练中会根据指定的配置文件下载预训练模型加以使用,在后面会进一步说明对.yaml文件的更改和使用。
1.4 源码文件的修改
maskrcnn-benchmark/maskrcnn_benchmark/config/defaults.py
这是模型的一个总的默认配置文件,需要作出一定修改
此处解释一下修改.MIN_SIZE_TRAIN ,.MAX_SIZE_TRAIN 的原因,这里如果设置的太大,很有可能会出现CUDA out of menmory的错误,这里需要特别注意!!!
#Size of the smallest side of the image during training
_C.INPUT.MIN_SIZE_TRAIN = (400,) # (800,)
#Maximum size of the side of the image during training
_C.INPUT.MAX_SIZE_TRAIN = 667
#Size of the smallest side of the image during testing
_C.INPUT.MIN_SIZE_TEST = 400
#Maximum size of the side of the image during testing
_C.INPUT.MAX_SIZE_TEST = 667
#下面的两处修改也需要特别注意!!!必须和自己的类别相对应,如果没有分类,那么就为2
_C.MODEL.ROI_BOX_HEAD.NUM_CLASSES = 2 #类别数量加1
_C.MODEL.RETINANET.NUM_CLASSES = 2 #类别数量加1
configs/xxx.yaml文件的修改,以maskrcnn-benchmark/configse/2e_mask_rcnn_R_50_FPN_1x.yaml为例
下面蓝色圈出来的地方必须修改:- 一个是类别,如果这里面没有类别,与default.py中的一致,那么程序会自动在defaults.py中寻找。
- 特别还有一个是DATASETS,这个是用来指定本次训练所使用的数据集,为了方便我这里没有修改,就借用了coco_2014_train的名字,名字可以随意起,但是在
maskrcnn-benchmark/maskrcnn_benchmark/config/paths_catalog.py中需要有对应的数据集的路径描述,且该路径要与datasets/coco/里面的文件对应起来 - BASE_LR,迭代次数,保存间隔根据自己模型需要而定

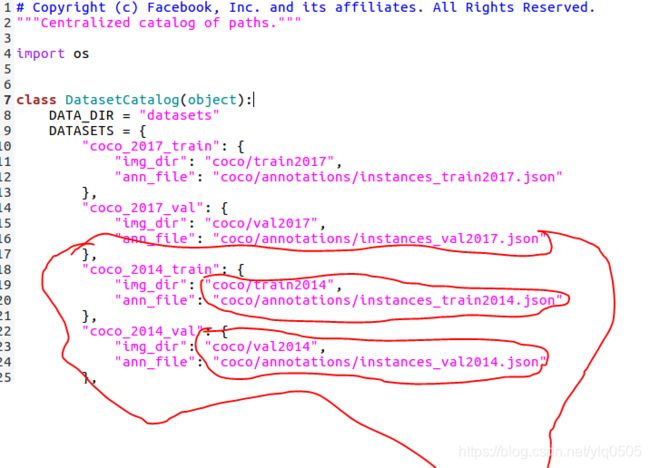
maskrcnn-benchmark/maskrcnn_benchmark/config/paths_catalog.py
这里面是对模型的所有数据集路径的配置,前面.yaml文件中指定的数据集必须在这里面存在,譬如:下图中红色圈出来的就是和上面.yaml配置文件相对应的数据集路径。该路径告诉了程序需要到coco/train2014;coco/annotations/instances_train2014.json去找训练数据。
1.5 模型训练
上面的数据准备,源码更改完毕后,就可以开始训练任务了。
~/maskrcnn-benchmark$ python tools/train_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml
模型首先会去下载预训练模型,然后开始训练过程,输出的训练日志到maskrcnn-benchmark/output/log.txt
同时训练完毕后模型也会被保存在maskrcnn-benchmark/output/路径下xxx.pth即为输出模型
1.6 模型验证
前面的训练完毕会给出对最终的输出模型maskrcnn-benchmark/output/model_final.pth的验证结果,一系列的AP值。但是我们隔一段迭代间隔就保存了模型,现在要想验证任意一个中间模型该怎么做呢?
首先复制一个e2e_mask_rcnn_R_50_FPN_1x.yaml重新命名为e2e_mask_rcnn_R_50_FPN_1x_predict.yaml

把WEIGHT这一行改成自己想要验证的模型的路径即可。比如上图就是验证迭代20000次的模型
然后运行
~/maskrcnn-benchmark$ python tools/test_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x_predict.yaml
即可看到验证结果
1.7 前传
前传过程需要仔细阅读maskrcnn-benchmark/demo/predictor.py
predictor.py文件包含了前传过程的所有的代码,目标检测,分割,关键点检测等都有对应的前传函数来处理!
看懂了predictor.py后,可以自己仿照着写一个只用于目标检测的前传代码predict.py,其实就是将这一部分从predictor.py中抠出来。
主要使用的是coco_demo类中的compute_prediction方法
下面是一段示例代码:
predictions = coco_demo.compute_prediction(img)
scores = predictions.get_field("scores").numpy()
bbox = predictions.bbox[np.argmax(scores)].numpy()
labelList = predictions.get_field("labels").numpy()
#keypoints = predictions.get_field("keypoints")
#scores = keypoints.get_field("logits")
#kps = keypoints.keypoints
#kps = torch.cat((kps[:, :, 0:2], scores[:, :, None]), dim=2).numpy()
#for region in kps:
#print(region.transpose((1, 0))[:2,])
#print(kps)
然后就可以把最终的bbox和类型(如果有的话)存储在.csv文件中保存下来
最终的bbox输出应当为两个点***左上和右下***,这样就确定了矩形定位框,达到了目标检测的目的
为了说明前传使用了哪个输出模型,需要有一个.yaml文件,可以和验证过程使用同一个.yaml文件,里面指明需要使用的模型 output/xxx.pth
~/maskrcnn-benchmark$ python demo/predict --config-file configs/e2e_mask_rcnn_R_50_FPN_1x_predict.yaml
1.8 几个常见的问题
- CUDA out of menmory :首先引起该问题的原因最可能是batch_size太大,需要去defaults.py中手动修改,但是如果调到1了还是报错,那就是前面说的defaults.py中的MIN_SIZE_TRAIN ;MAX_SIZE_TRAIN…设置得太大,调小即可
- loss NAN的错误,一般可以通过调小上面.yaml中的BASE_LR解决
几乎所有问题都可以在源工程的issues下面找到
2 关键点检测任务
由于任务的需要,对于输入图片中歪斜的目标,单单的目标定位框还无法满足需求,这时更希望检测出目标的几个关键点来定位目标的具体位置和方向,因此还需要作一个关键点检测的任务。源代码中的关键点任务是对行人姿态的17个关键点进行检测的,而我们的任务其实只需要检测4个关键点,也即矩形的4个角点。
2.1 数据准备
相比于单纯的矩形定位框检测,对于关键点的检测还需要在coco数据集中增加keypoints数据才能实现。
给coco的.json文件的annotation增加两个字段:
‘keypoints’:[x0,y0,2,x1,y1,2,x2,y2,2,x3,y3,2]
‘num_keypoints’:4解释:x0,y0,x1,y1…表示关键点的坐标,2表示该关键点是可见的且标注了。如果是1则表示标注了但不可见(譬如遮挡),是0则表示无关键点。
另外,给categories增加
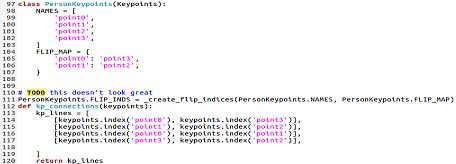
‘keypoints’:[‘point0’,‘point1’,‘point2’,‘point3’],
‘skeleton’:[[0,1],[1,2],[2,3],[0,3]]解释:‘point0’,‘point1’,‘point2’,'point3表示关键点的名字,'skeleton’关键点之间的连接关系。需要根据自己的关键点的意义合理选择更改。
2.2 源码文件的修改
-
maskrcnn-benchmark/maskrcnn_benchmark/data/datasets/coco.py第10行min_keypoints_per_image = 10改为min_keypoints_per_image = 1,因为我们只有四个关键点,如果该值大于4,则无法生成dataset。这里是一个很坑的的点,如果不修改,你会发现你的代码永远读不到数据!!!
-
maskrcnn-benchmark/maskrcnn_benchmark/config/defaults.py_C.MODEL.ROI_KEYPOINT_HEAD.NUM_CLASSES = 17 改为 4 //源代码是对行人姿态关键点定位,共17个关键点,我们只有4个关键点,因此需要对应。
-
maskrcnn-benchmark/maskrcnn_benchmark/structures/keypoints.py
源代码的任务和我们的不同,因此要作出修改,譬如的对于我的任务就会作如下修改:
2.3 数据组织/训练/验证
同前面内容
2.4 前传
前传过程同样是需要仔细阅读maskrcnn-benchmark/demo/predictor.py
predictor.py文件包含了前传过程的所有的代码,目标检测,分割,关键点检测等都有对应的前传函数来处理!下面的两段段代码便为前传过程中关键点导出处理的部分,可视化关键点!
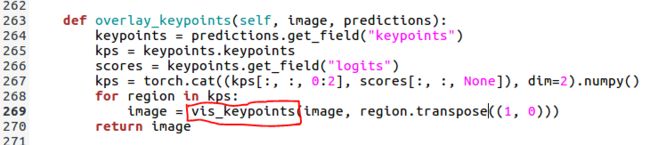
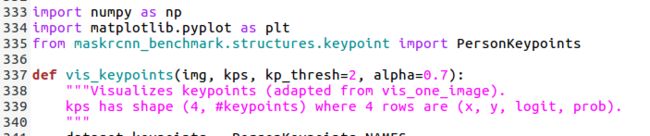
仿照上面的代码可以自己重写一个predict_keypoint.py,专门用作关键点的输出和可视化!
对于传入vis_keypoints的kps参数,其前两行(坐标)形式如下:
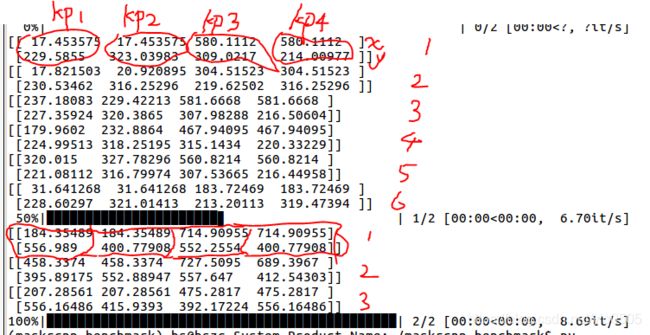
上面的输出代表的测试的是两幅电表图片,第一幅图片输出了6组(因为原图上面可能存在多个表盘,每一组可能代表一个电表的表盘)可能的关键点,第二幅图片输出了3组可能的关键点.每组有四个关键点:kp1,kp2,kp3,kp4。
参考文献
【1】https://zhuanlan.zhihu.com/p/66283696
【2】https://zhuanlan.zhihu.com/p/64605565