CVPR 2021 论文大盘点-超分辨率篇
关注公众号,发现CV技术之美
本文总结超分辨率相关论文,包括图像、视频、盲超分辨率、无参考型图像超分辨率以及基于参考的超分辨率等。共计 32 篇。
其中大量的论文在研究超分辨率算法的加速和训练、真实世界超分辨率问题,说明学界算法在加速向工业界产品转化。值得大家关注~!
大家可以在:
https://openaccess.thecvf.com/CVPR2021?day=all
按照题目下载这些论文。
如果想要下载所有CVPR 2021论文,请点击这里:
CVPR 2021 论文开放下载了!
Data-Free Knowledge Distillation For Image Super-Resolution
本篇文章研究了在移动电话和智能相机中广泛使用的单图像超分辨率(SISR)任务的无数据压缩方法。并在各种数据集和架构上的实验表明,所提出的方法能够在没有原始数据的情况下有效地学习适合移动端部署的学生网络,例如,在 Set5 的 ×2 超分辨率下,PSNR下降了 0.16dB。
作者 | Yiman Zhang、Hanting Chen、Xinghao Chen、Yiping Deng、 Chunjing Xu、Yunhe Wang
单位 | 华为;北大
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Data-Free_Knowledge_Distillation_for_Image_Super-Resolution_CVPR_2021_paper.pdf
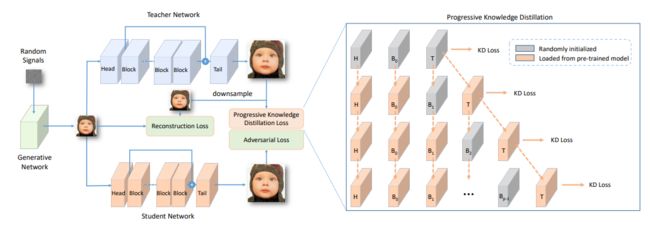
AdderSR: Towards Energy Efficient Image Super-Resolution
本篇文章利用加法神经网络(AdderNets)对单图像的超分辨率问题进行了研究。与卷积神经网络相比,加法神经网络利用加法来计算输出特征,从而避免了传统乘法的大量能量消耗。
但由于计算模式的不同,很难将现有的加法神经网络在大规模图像分类上的成功经验直接移植到图像超分辨率任务上。具体来说,加法器操作不能轻易地学习身份映射,这对图像处理任务来说是至关重要的。此外,高通滤波器的功能也不能由加法器网络来保证。
为此,作者对加法器操作和身份映射之间的关系进行了彻底分析,并插入新操作以提高使用加法器网络的 SR 模型的性能。然后,开发一个可学习的功率激活,用于调整特征分布和细化细节。
在几个基准模型和数据集上进行的实验表明,使用 AdderNets 的图像超分辨率模型可以达到与其 CNN 基线相当的性能和视觉质量,而且能耗降低了约2.5倍。
作者 | Dehua Song、Yunhe Wang、Hanting Chen、Chang Xu、 Chunjing Xu、Dacheng Tao
单位 | 华为;北大;悉尼大学
论文 | https://arxiv.org/pdf/2009.08891.pdf
代码 | https://github.com/huawei-noah/AdderNet
Cross-MPI: Cross-scale Stereo for Image Super-Resolution using Multiplane Images
问题:现有的 RefSR(有参SR) 方法由于较少考虑场景下的结构,无法在较大的分辨率差距下完成高保真的超分辨率,如 8 倍的分辨率提升。
目的:解决多平面图像(MPI)表示法的引发 RefSR 问题(在实际的多尺度相机系统中)。
具体方法:Cross-MPI,是一个端到端的 RefSR 网络,由一个新的基于平面感知注意力的 MPI 机制、一个多尺度引导上采样模块以及一个超分辨率(SR)合成和融合模块组成。所提出的平面感知注意力机制没有采用跨尺度立体之间的直接详尽匹配,而是充分利用隐藏的场景结构进行高效的基于注意力的对应搜索。进一步结合温和的由粗到细的引导上采样策略,提出的 Cross-MPI 能够实现稳健而准确的细节传输。
结果:在数字合成的和光学放大的跨尺度数据上的实验结果表明,Cross- MPI 框架可以实现对现有 RefSR 方法的更好性能,即使在尺度差异很大的情况下,也是真正适合实际多尺度相机系统的SR。
作者 | Yuemei Zhou, Gaochang Wu, Ying Fu, Kun Li, Yebin Liu
单位 | 清华;东北大学;北京理工大学;天津大学
论文 | https://arxiv.org/abs/2011.14631
主页 | http://www.liuyebin.com/crossMPI/crossMPI.html

ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
这篇文章想要解决的是超分辨的加速问题。ClassSR,是首个将分类和超分辨率结合在一起的子图像级的 SR 管道。通过数据的特性来解决加速问题,使得 ClassSR 与其他加速网络方法可以同时使用。而且一个压缩到极限的网络仍然可以被 ClassSR 加速。通过实验验证,ClassSR 可以帮助大多数现有的方法(如FSRCNN、CARN、SRResNet、RCAN)在 DIV8K 数据集上节省高达 50% 的 FLOPs。另外,该文还提出一种具有两个新的损失的分类方法。它根据由特定分支处理的子图像的修复难度来划分,而不是预先确定的标签,因此它也可以直接应用于其他低层次的视觉任务。
作者 | Xiangtao Kong, Hengyuan Zhao, Yu Qiao, Chao Dong
单位 | 中科院;国科大等
论文 | https://arxiv.org/abs/2103.04039
代码 | https://github.com/Xiangtaokong/ClassSR

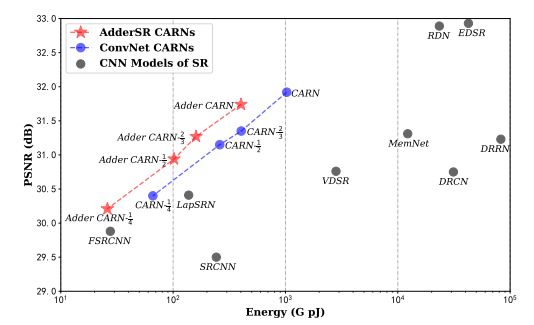
Robust Reference-based Super-Resolution via C2-Matching
基于参考的超级分辨率(Ref-SR)是近期非常值得研究的一项任务,它是通过引入额外的高分辨率(HR)参考图像来增强低分辨率(LR)输入图像。现有的 Ref-SR 方法大多依赖于隐性的对应匹配,从参考图像中借用HR纹理来补偿输入图像的信息损失。但由于在输入和参考图像之间存在两个差距:transformation gap(转换差距(如比例和旋转))和分辨率差距(如HR和LR),会导致执行局部迁移变得困难。
方案:提出 C2-Matching,它可以跨过 transformation(变换)和分辨率,产生明确的鲁棒性匹配。具体来说,对于 transformation gap,提出 contrastive correspondence network(对比性对应网络),使用输入图像的增强视图来学习 transformation-robust 对应关系;对于分辨率差距,采用 teacher-student 关联蒸馏法,从较容易的 HR-HR 匹配中进行知识蒸馏,来指导较模糊的 LR-HR 匹配;最后,通过设计一个动态聚合模块来解决隐藏的错位问题。另外,为了更好对 Ref-SR 在现实环境下的性能进行评估,作者构建了 Webly-Referenced SR(WR-SR)数据集,它模拟了实际使用场景。
结果表明,在标准的 CUFED5 基准上,C2-Matching 明显优于现有技术,超过 1dB。值得注意的是,它在WR-SR 数据集上也显示出它极强的泛化能力,以及对大尺度和旋转变换的鲁棒性。
作者 | Yuming Jiang, Kelvin C.K. Chan, Xintao Wang, Chen Change Loy, Ziwei Liu
单位 | 南洋理工大学&腾讯PCG
论文 | https://arxiv.org/abs/2106.01863
代码 | https://github.com/yumingj/C2-Matching
GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
作者 | Kelvin C.K. Chan, Xintao Wang, Xiangyu Xu, Jinwei Gu, Chen Change Loy
单位 | 南洋理工大学 S-Lab ;商汤科技
论文 | https://arxiv.org/abs/2012.00739
代码 | https://github.com/ckkelvinchan/GLEAN
解读 | CVPR 2021 Oral | GLEAN: 基于隐式生成库的高倍率图像超分辨率

SRWarp: Generalized Image Super-Resolution under Arbitrary Transformation
文章所提出的 SRWarp 算法为解决任意倍数(2.5x\3.5x等)而不是预定义倍数(2x\4X)的超分辨率问题。并通过广泛的实验和消融研究证明了 SRWarp 的必要性,以及它在各种变换下的优势。
作者 | Sanghyun Son, Kyoung Mu Lee
单位 | 首尔大学
论文 | https://arxiv.org/abs/2104.10325
代码 | https://github.com/sanghyun-son/srwarp
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution
基于参考的图像超分辨率通过利用外部参考图像进行恢复高频细节方面取得了成功。其中纹理细节是根据它们的 point- 或 patch-wise 对应关系从参考图像迁移到低分辨率(LR)图像。因此,高质量的对应关系匹配是至关重要的。现有的 RefSR 方法往往忽略了 LR 和 Ref 图像之间隐藏的巨大分布差异,使得信息利用的有效性降低。
本次工作中,作者提出用于 RefSR 的新方法:MASA 网络,设计两个新的模块来解决上述问题。所提出的 Match (匹配)和 Extraction(提取)模块通过一个从粗到细的对应匹配方案大大降低了计算成本。Spatial Adaptation(空间适应)模块用来学习 LR 和 Ref 图像之间的分布差异,并以空间适应的方式将参考特征的分布 remaps(重新映射)为 LR特征的分布。以此更加鲁棒地处理不同的参考图像。大量的定量和定性实验验证了所提出的模型的有效性。
作者 | Liying Lu, Wenbo Li, Xin Tao, Jiangbo Lu, Jiaya Jia
单位 | 港中文&快手&思谋科技
论文 | https://arxiv.org/abs/2106.02299
代码 | https://github.com/dvlab-research/MASA-SR

Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
真实世界实时深度超分辨率测评数据集及基准测试。
作者 | Lingzhi He, Hongguang Zhu, Feng Li, Huihui Bai, Runmin Cong, Chunjie Zhang, Chunyu Lin, Meiqin Liu, Yao Zhao
单位 | 北京交通大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/He_Towards_Fast_and_Accurate_Real-World_Depth_Super-Resolution_Benchmark_Dataset_and_CVPR_2021_paper.pdf
主页 | http://mepro.bjtu.edu.cn/resource.html

Exploring Sparsity in Image Super-Resolution for Efficient Inference
本篇文章对图像 SR 中的稀疏性进行了探讨,以提高 SR 网络的推理效率。具体来说,开发一个 Sparse Mask SR(SMSR)网络,以学习稀疏掩码来删减冗余的计算。在 SMSR 中,空间掩码学习识别 "重要 "区域,而通道掩码学习标记那些 "不重要 "区域中的冗余通道。因此,多余的计算可以被准确地定位和跳过,同时保持相当的性能。实验证明,SMSR 实现了最先进的性能,对于x2/3/4的SR,FLOPs减少了41%/33%/27%。
作者 | Longguang Wang, Xiaoyu Dong, Yingqian Wang, Xinyi Ying, Zaiping Lin, Wei An, Yulan Guo
单位 | 中国人民解放军国防科技大学;东京大学;RIKEN AIP
论文 | https://arxiv.org/abs/2006.09603
代码 | https://github.com/LongguangWang/SMSR

Neural Side-By-Side: Predicting Human Preferences for No-Reference Super-Resolution Evaluation
Neural Side-BySide(NeuralSBS),用于无参考型图像超分辨率,可以比较不同的 SR 模型或调整其超参数。
作者 | Valentin Khrulkov、Artem Babenko
单位 | 高等经济大学(俄罗斯)
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Khrulkov_Neural_Side-by-Side_Predicting_Human_Preferences_for_No-Reference_Super-Resolution_Evaluation_CVPR_2021_paper.pdf
代码 | https://github.com/KhrulkovV/NeuralSBS

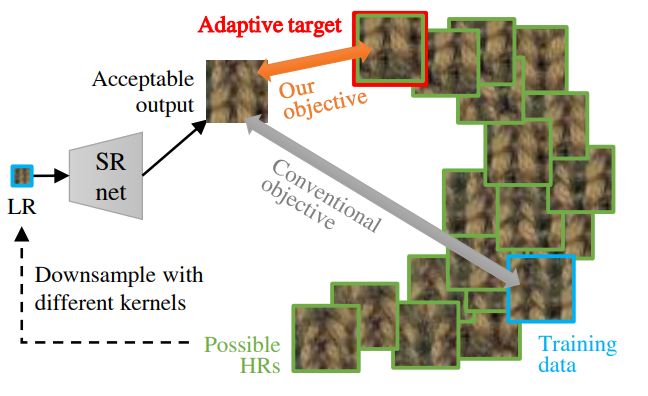
Tackling the Ill-Posedness of Super-Resolution through Adaptive Target Generation
文章提出新的方法,通过引入自适应目标来处理 SR 的 ill-posed 问题。该方法可以应用于现有的训练数据和网络结构,不需要任何修改,也不需要增加太多的训练时间。通过实验结果得出它优于以前最先进的方法,特别是在生成感观上令人满意的图像方面。
对于盲 SR 来说,所提出方法拥有另一个优势,即不需要额外的努力来寻找准确的模糊核。
作者 | Younghyun Jo、Seoung Wug Oh、Peter Vajda、Seon Joo Kim
单位 | 延世大学;Adobe Research;Facebook
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Jo_Tackling_the_Ill-Posedness_of_Super-Resolution_Through_Adaptive_Target_Generation_CVPR_2021_paper.pdf
代码 | https://github.com/yhjo09/AdaTarget
LAU-Net: Latitude Adaptive Upscaling Network for Omnidirectional Image Super-resolution
latitude adaptive upscaling network(LAU-Net)用于 ODI (全景图像)超分辨率,允许不同纬度的像素采用不同的 upscaling 因子。具体来说,引入一个 Laplacian 多级分离架构,将 ODI 分成不同的纬度带,并以不同的因子对其进行分层放大。此外,提出一个具有纬度自适应奖励的深度强化学习方案,以便为不同的纬度带自动选择最佳放大系数。
作者称 LAU-Net 是首次尝试考虑 ODI 超分辨率的纬度差异算法。实验结果表明,LAU-Net 大大推进了 ODI 的超分辨率性能。
作者 | Xin Deng、Hao Wang、Mai Xu、Yichen Guo、Yuhang Song、Li Yang
单位 | 北航;牛津大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Deng_LAU-Net_Latitude_Adaptive_Upscaling_Network_for_Omnidirectional_Image_Super-Resolution_CVPR_2021_paper.pdf
代码 | https://github.com/wangh-allen/LAU-Net
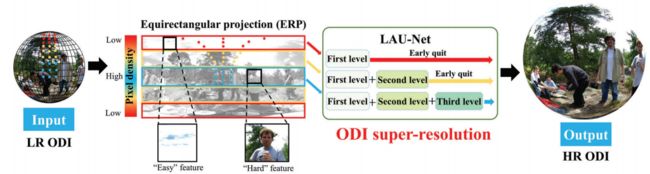
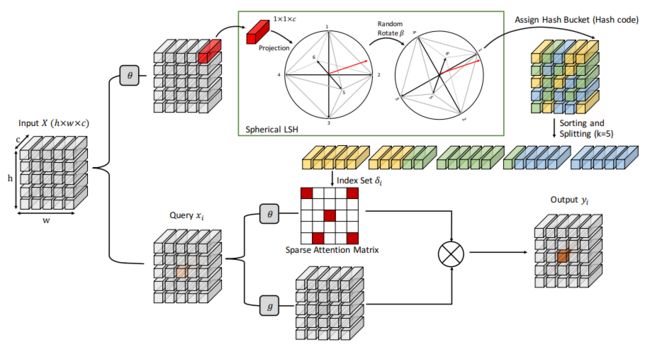
Image Super-Resolution with Non-Local Sparse Attention
Non-Local Sparse Attention(NLSA),用于深度单图像的超分辨率网络,它同时具有稀疏表示和非局部操作的优点。
作者 | Yiqun Mei, Yuchen Fan, Yuqian Zhou
单位 | 伊利诺伊大学厄巴纳-香槟分校
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Mei_Image_Super-Resolution_With_Non-Local_Sparse_Attention_CVPR_2021_paper.pdf
Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
无监督真实世界图像超分辨
作者 | Yunxuan Wei, Shuhang Gu, Yawei Li, Longcun Jin
单位 | 华南理工大学;悉尼大学;苏黎世联邦理工学院
论文 | https://arxiv.org/abs/2004.01178
代码 | https://github.com/ShuhangGu/DASR

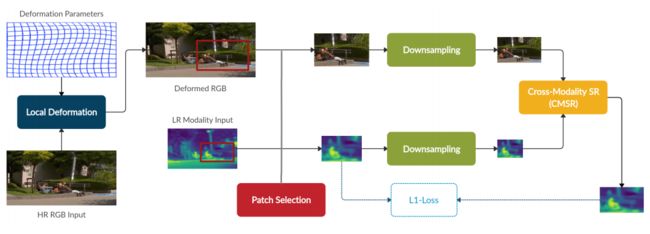
Single Pair Cross-Modality Super Resolution
文中提出 CMSR,一个用于跨模态超分辨率的深度网络,不同于之前方法,它被设计用来处理弱对齐的图像。该网络只对两幅输入图像进行训练,学习它们的内部统计数据和相关性,并应用它们对目标模态进行上样。CMSR 包含一个 internal transformer ,它与上采样过程本身一起被即时训练,没有明确的监督。实验证明,CMSR 成功地提高了输入图像的分辨率,从 RGB对应的图像中获得了有价值的信息,没有引入伪影或不相关的细节。
作者 | Guy Shacht, Sharon Fogel, Dov Danon, Daniel Cohen-Or, Ilya Leizerson
单位 | 特拉维夫大学;Elbit Systems
论文 | https://arxiv.org/abs/2004.09965
End-to-End Learning for Joint Image Demosaicing, Denoising and Super-Resolution
该工作提出一种基于专门设计的深度卷积神经网络(CNN)的联合去马赛克、去噪和超分辨率的端到端解决方案。并系统地研究了解决这一问题的不同方法,以及与所提出的方法进行了比较。
在大型图像数据集上进行的广泛实验表明,所提出方法在数量上和质量上都优于最先进的方法。另外在提出的方案中应用了各种损失函数,并证明了通过使用平均绝对误差作为损失函数,可以获得比其他情况更优越的结果。
作者 | Wenzhu Xing and Karen Egiazarian
单位 | 坦佩雷大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Xing_End-to-End_Learning_for_Joint_Image_Demosaicing_Denoising_and_Super-Resolution_CVPR_2021_paper.pdf

Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
现有的色彩引导的深度超分辨率(DSR)方法需要成对的RGB-D数据作为训练样本,其中 RGB 图像被用作结构指导来恢复退化的深度图,基于二者的几何相似性。但在实际的测试环境中,成对的数据可能是有限的或昂贵的。
因此,本次工作首次探索在训练阶段学习跨模态的知识,在训练阶段,RGB和深度模态都是可用的,但在目标数据集上测试,其中只有单一的深度信息模态存在。研究的关键思想是在不改变网络结构的情况下,将场景结构指导的知识从RGB 模态蒸馏到单一DSR任务中。
具体来说,构建一个辅助的深度估计(DE)任务,以RGB图像作为输入来估计深度图,并对DSR任务和DE任务进行协同训练,以提高DSR的性能。在此基础上,提出一个跨任务交互模块,以实现双边跨任务知识迁移。
首先,设计一个跨任务蒸馏方案,鼓励 DSR 和 DE 网络以师生角色互换的方式相互学习。然后,提出结构预测(SP)任务,提供额外的结构正则化,以帮助 DSR 和 DE 网络学习更多的信息结构表征来进行深度恢复。
通过实验证明,与其他 DSR 方法相比,该方案取得了卓越的性能。
作者 | Baoli Sun, Xinchen Ye, Baopu Li, Haojie Li, Zhihui Wang, Rui Xu
单位 | 大连理工大学;百度等
论文 | https://arxiv.org/abs/2103.12955

Deep Burst Super-Resolution
本次工作解决了现实世界中的多帧超分辨率问题。其中引入一个新的数据集BurstSR,包含从手持相机拍摄的 RAW 连拍序列,以及使用变焦镜头获得的相应的高分辨率ground truths。又提出一个多帧超分辨率网络,它可以通过基于注意力的融合,自适应地结合来自多个输入图像的信息。通过实验验证所提出方法在现实世界的 bursts 中获得了很好的结果,比单帧和多帧的替代方案都要好。
作者 | Goutam Bhat 、Martin Danelljan 、Luc Van Gool 、Radu Timofte
单位 | 苏黎世联邦理工学院
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Bhat_Deep_Burst_Super-Resolution_CVPR_2021_paper.pdf

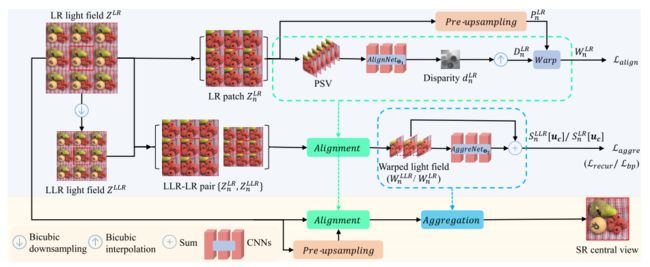
Light Field Super-Resolution with Zero-Shot Learning
该工作的主要贡献有:
1、提出首个用于光场 SR 的零样本学习框架,它通过仅从输入 LR 光场本身提取的例子来学习输入特定的 SR 映射。
2、对不同的学习策略进行了分析,并提出一个 divideand-conquer (分而治之)的策略,以便从高度有限的训练数据中有效地学习。
3、提出错误引导的微调算法,以进一步扩展零样本学习框架,共同使用源数据集和目标输入。
4、通过综合实验,从数量和质量上验证了所提出的框架相对于SoTA光场SR方法的优越性。
作者 | Zhen Cheng 、Zhiwei Xiong、 Chang Chen 、Dong Liu 、Zheng-Jun Zha
单位 | 中国科学技术大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Cheng_Light_Field_Super-Resolution_With_Zero-Shot_Learning_CVPR_2021_paper.pdf
Fast Bayesian Uncertainty Estimation and Reduction of Batch Normalized Single Image Super-Resolution Network
作者 | Aupendu Kar, Prabir Kumar Biswas
单位 | 印度理工学院
论文 | https://arxiv.org/abs/1903.09410
代码 | https://github.com/aupendu/sr-uncertainty

Practical Single-Image Super-Resolution Using Look-Up Table
通过使用LUT(SR-LUT)提出一种简单而实用的单图像 SR 方法。该方法本质上更快,因为预计算的 HR 值只需从 SR-LUT 中检索,并对最终输出进行少量计算。
与 bicubic interpolation(双三次插值算法)相比,该快速模型(Ors-V和Ors-F)运行速度更快,同时实现了更好的定量性能,而视觉质量上慢速模型(Ors-S)“看起来”更好,但运行时间稍长。
作者 | Younghyun Jo、 Seon Joo Kim
单位 | 延世大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Jo_Practical_Single-Image_Super-Resolution_Using_Look-Up_Table_CVPR_2021_paper.pdf
代码 | https://github.com/yhjo09/SR-LUT

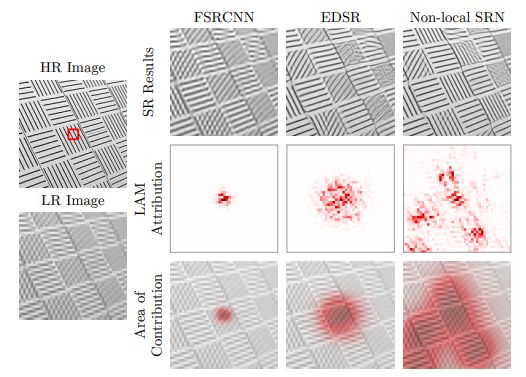
Interpreting Super-Resolution Networks with Local Attribution Maps
作者 | Jinjin Gu, Chao Dong
单位 | 悉尼大学;中科院
论文 | https://arxiv.org/abs/2011.11036
主页 | https://x-lowlevel-vision.github.io/lam.html
Scene Text Telescope: Text-Focused Scene Image Super-Resolution
Scene Text Telescope,以文字为焦点的场景图像超分辨率
作者 | Jingye Chen, Bin Li, Xiangyang Xue
单位 | 复旦大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Chen_Scene_Text_Telescope_Text-Focused_Scene_Image_Super-Resolution_CVPR_2021_paper.pdf

盲超分辨
Learning the Non-differentiable Optimization for Blind Super-Resolution
作者 | Zheng Hui、Jie Li、Xiumei Wang、Xinbo Gao
单位 | 西安电子科技大学;重庆邮电大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Hui_Learning_the_Non-Differentiable_Optimization_for_Blind_Super-Resolution_CVPR_2021_paper.pdf

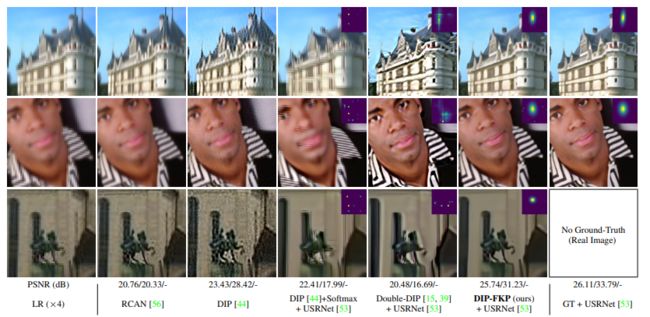
Flow-based Kernel Prior with Application to Blind Super-Resolution
Kernel estimation 通常是盲图像超分辨率(SR)的关键问题之一。最近,Double-DIP 提出通过网络结构的先验对核进行建模,而 KernelGAN 则采用了深度线性网络和若干正则化损失来约束核空间。但都未能充分利用一般的SR 核假设,即各向异性的高斯核对图像SR是足够的。
为此,该文提出一种用于核建模的归一化基于流的核先验(FKP)。通过学习各向异性的高斯核分布和可操作的隐藏分布之间的可逆映射,FKP 可以很容易地用于替代 Double-DIP 和 KernelGAN 的核建模模块。具体来说,FKP 在隐空间而不是网络参数空间中优化内核,这使得它能够产生合理的内核初始化,遍历所学的内核流形,并提高优化的稳定性。
在合成图像和真实世界图像上进行的大量实验表明,所提出的 FKP 能够以较少的参数、运行时间和内存使用量显著提高内核估计的准确性,从而获得最先进的盲 SR 结果。
作者 | Jingyun Liang, Kai Zhang, Shuhang Gu, Luc Van Gool, Radu Timofte
单位 | 苏黎世联邦理工学院;悉尼大学;鲁汶大学
论文 | https://arxiv.org/abs/2103.15977
代码 | https://github.com/JingyunLiang/FKP
KOALAnet: Blind Super-Resolution using Kernel-Oriented Adaptive Local Adjustment
KOALAnet,是基于 SR 特征的面向核的自适应局部调整(KOALA)的新型盲SR框架,它联合学习空间变化的降质和修复核,以适应真实图像中的空间变化的模糊特征。KOALAnet 对于用随机降质得到的合成 LR 图像的性能优于最近的盲 SR 方法,并且进一步表明,KOALAnet 通过有效地处理混有焦点内和焦点外区域的图像,使其不被过度锐化,对具有故意模糊的艺术照片产生了最自然的结果。
作者 | Soo Ye Kim、Hyeonjun Sim、Munchurl Kim
单位 | 韩国科学技术院
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Kim_KOALAnet_Blind_Super-Resolution_Using_Kernel-Oriented_Adaptive_Local_Adjustment_CVPR_2021_paper.pdf

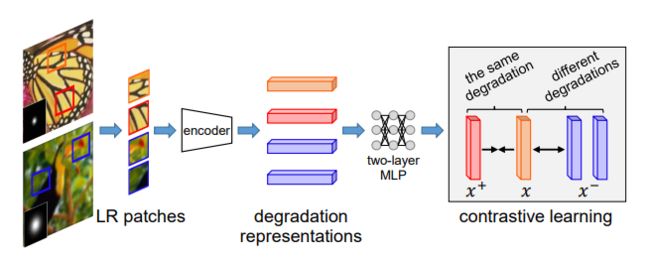
Unsupervised Degradation Representation Learning for Blind Super-Resolution
文章提出一个无监督降质表示学习方案,用于盲SR,而不需要明确的降质估计。具体来说,学习抽象的表征来区分表征空间中的各种降质,而不是像素空间中的明确估计。此外,引入一个 Degradation-Aware SR(DASR)网络,它可以根据学习到的表征灵活地适应各种降质情况。事实证明,该方案可以提取鉴别性的表征来获得准确的降质信息。
在合成图像和真实图像上的实验表明,所提出网络在盲SR 任务中取得了最先进的性能。
作者 | Longguang Wang, Yingqian Wang, Xiaoyu Dong, Qingyu Xu, Jungang Yang, Wei An, Yulan Guo
单位 | 国防科技大学;东京大学
论文 | https://arxiv.org/abs/2104.00416
代码 | https://github.com/LongguangWang/DASR
视频超分辨率
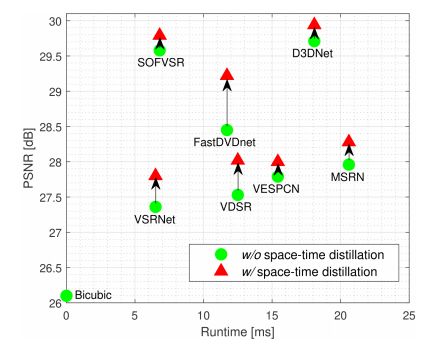
Space-Time Distillation for Video Super-Resolution
本次工作旨在提高紧凑型 VSR 网络的性能,而不改变其原始架构,通过知识蒸馏的方法,将知识从复杂的 VSR 网络迁移到紧凑型网络中。
具体来说,提出 space-time distillation(STD),在VSR任务中利用空间和时间知识。对于空间蒸馏,从两个网络中提取暗示高频视频内容的空间注意力图,这些图被进一步用于迁移空间建模能力。对于时间蒸馏,通过蒸馏时间记忆单元的特征相似性来缩小紧凑模型和复杂模型之间的性能差距,这些特征相似性是由使用 ConvLSTM 在训练片段中产生的特征图序列编码的。在训练过程中,STD可以很容易地被纳入任何网络,而不改变原有的网络结构。
在标准基准上的实验结果表明,在资源受限的情况下,所提出的方法明显提高了现有VSR网络的性能,而不增加推理时间。
作者 | Zeyu Xiao 、Xueyang Fu 、Jie Huang 、Zhen Cheng 、Zhiwei Xiong
单位 | 中国科学技术大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Xiao_Space-Time_Distillation_for_Video_Super-Resolution_CVPR_2021_paper.pdf
Turning Frequency to Resolution: Video Super-resolution via Event Cameras
作者 | Yongcheng Jing、Yiding Yang、Xinchao Wang、Mingli Song、 Dacheng Tao
单位 | 悉尼大学;斯蒂文斯理工学院;新加坡国立大学;浙江大学
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Jing_Turning_Frequency_to_Resolution_Video_Super-Resolution_via_Event_Cameras_CVPR_2021_paper.pdf

BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
作者 | Kelvin C.K. Chan, Xintao Wang, Ke Yu, Chao Dong, Chen Change Loy
单位 | 南洋理工大学、腾讯PCG应用研究中心、香港中文大学-商汤科技联合实验室
论文 | https://arxiv.org/abs/2012.02181
代码 | https://github.com/ckkelvinchan/BasicVSR-IconVSR
备注 | 在Vid4上突破28dB大关!视频超分新的里程碑:IconVSR

Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
基于时空特征可控插值的视频超分辨率网络
作者 | Gang Xu, Jun Xu, Zhen Li, Liang Wang, Xing Sun, Ming-Ming Cheng
单位 | 南开大学;中科院;腾讯优图
论文 | https://arxiv.org/abs/2104.10642
代码 | https://github.com/CS-GangXu/TMNet
简介 | 18

- END -
编辑:CV君
转载请联系本公众号授权
END,入群????备注:SR
