一文入门卷积神经网络:CNN通俗解析
摘要: CNN基础知识介绍及TensorFlow具体实现,对于初学者或者求职者而言是一份不可多得的资料。

定义:
简而言之,卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。卷积神经网络的创始人是着名的计算机科学家Yann LeCun,目前在Facebook工作,他是第一个通过卷积神经网络在MNIST数据集上解决手写数字问题的人。

Yann LeCunn
卷积神经网络的出现是受到了生物处理过程的启发,因为神经元之间的连接模式类似于动物的视觉皮层组织。
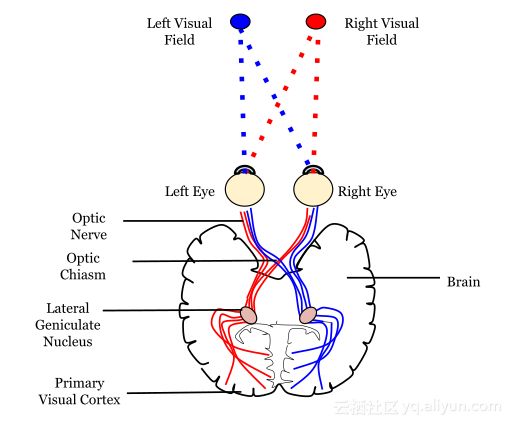
人脑的视觉结构
个体皮层神经元仅在被称为感受野的视野受限区域中对刺激作出反应,不同神经元的感受野部分重叠,使得它们能够覆盖整个视野。

计算机视觉与人类视觉
正如上图所示,我们在谈论任何类型的神经网络时,都不可能不提及一点神经科学以及人体(特别是大脑)及其功能相关的知识,这些知识成为创建各种深度学习模型的主要灵感的来源。
卷积神经网络的架构:

卷积神经网络架构
如上图所示,卷积神经网络架构与常规人工神经网络架构非常相似,特别是在网络的最后一层,即全连接。此外,还注意到卷积神经网络能够接受多个特征图作为输入,而不是向量。
下面让我们探索构成卷积神经网络的基本构件及相关的数学运算过程,并根据在训练过程中学到的特征和属性对图像进行可视化和分类。
输入层|Input Layer:
输入层主要是n×m×3 RGB图像,这不同于人工神经网络,人工神经网络的输入是n×1维的矢量。
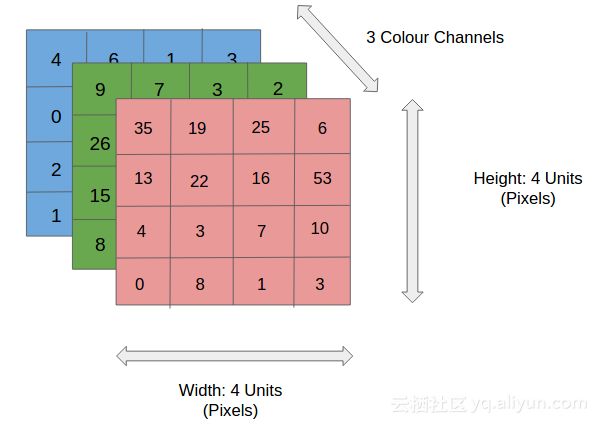
RGB图像
卷积层|Convolution Layer:
在卷积层中,计算输入图像的区域和滤波器的权重矩阵之间的点积,并将其结果作为该层的输出。滤波器将滑过整个图像,重复相同的点积运算。这里注意两件事:
- 滤波器必须具有与输入图像相同数量的通道;
- 网络越深,使用的滤波器就越多;拥有的滤波器越多,获得的边缘和特征检测就越多;

前向卷积运算
卷积层输出的尺寸:
输出宽度:
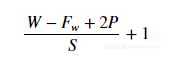
输出高度:

其中:
- W :输入图像的宽度
- H :输入图像的高度
- Fw :滤波器或内核的宽度
- Fh :滤波器的高度
- P :填充
- S :移动步幅
卷积层输出的通道数等于卷积操作期间使用的滤波器的个数。
为什么选择卷积?
有时候可能会问自己,为什么要首先使用卷积操作?为什么不从一开始就展开输入图像矩阵?在这里给出答案,如果这样做,我们最终会得到大量需要训练的参数,而且大多数人都没有能够以最快的方式解决计算成本高昂任务的能力。此外,由于卷积神经网络具有的参数会更少,因此就可以避免出现过拟合现象。
池化层|Pooling Layer:
目前,有两种广泛使用的池化操作——平均池化(average pooling)和最大池化(max pooling),其中最大池化是两者中使用最多的一个操作,其效果一般要优于平均池化。池化层用于在卷积神经网络上减小特征空间维度,但不会减小深度。当使用最大池化层时,采用输入区域的最大数量,而当使用平均池化时,采用输入区域的平均值。
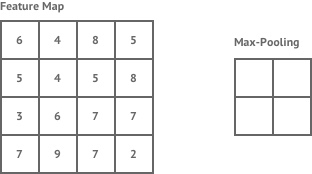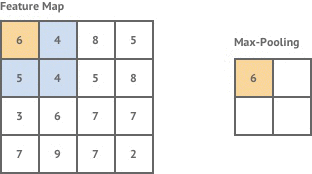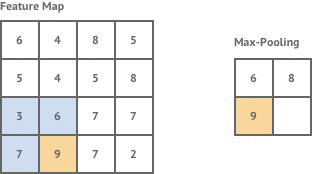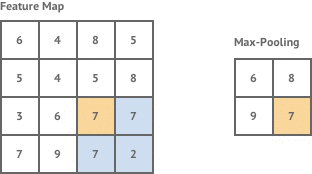
最大池化
为什么要池化?
池化层的核心目标之一是提供空间方差,这意味着你或机器将能够将对象识别出来,即使它的外观以某种方式发生改变,更多关于池化层的内容可以查看Yann LeCunn的文章。
非线性层|Non-linearity Layer:
在非线性层中,一般使用ReLU激活函数,而不是使用传统的Sigmoid或Tan-H激活函数。对于输入图像中的每个负值,ReLU激活函数都返回0值,而对于输入图像中的每个正值,它返回相同的值(有关激活函数的更深入说明,请查看这篇文章)。

ReLU激活函数
全连接层}Fully Connected Layer:
在全连接层中,我们将最后一个卷积层的输出展平,并将当前层的每个节点与下一层的另一个节点连接起来。全连接层只是人工神经网络的另一种说法,如下图所示。全连接层中的操作与一般的人工神经网络中的操作完全相同:
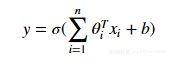
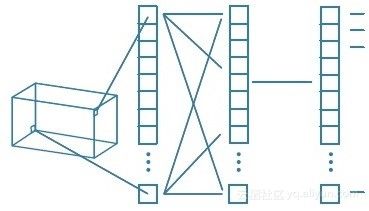
卷积层展开
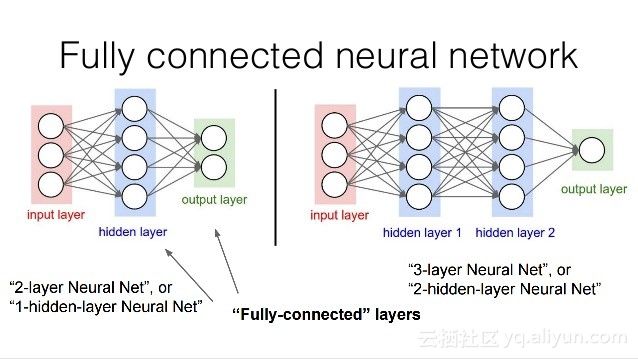
全连接层
上面讨论的层和操作都是每个卷积神经网络的核心组件,现在已经讨论了卷积神经网络在前向传播中经历的操作,下面让我们跳转到卷积神经网络在反向传播中经历的操作。
反向传播|Backpropagation:
全连接层:
在全连接层中,反向传播与任何常规人工神经网络完全相同,在反向传播中(使用梯度下降作为优化算法),使用损失函数的偏导数即损失函数关于权重的导数来更新参数,其中我们将损失函数的导数与激活输出相乘,激活输出的导数与非激活输出相乘,导数为未激活的输出与权重相对应。
数学表达式如下:
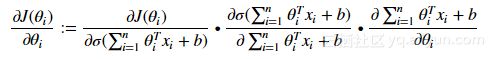
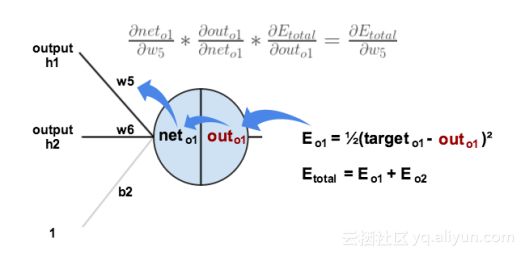
反向传播说明图
在计算梯度之后,我们从初始权重中减去它以得到新的优化:
![]()
其中:
- θi+ 1 :优化的权重
- θi:初始权重
- α :学习率
- ∇J(θi):损失函数的梯度
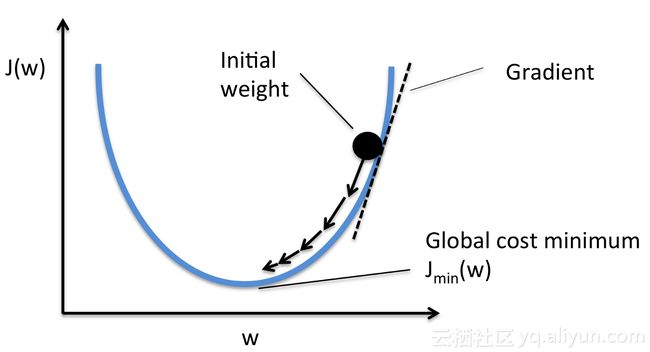
梯度下降
在下面的动态图中,是将梯度下降应用于线性回归的结果。从图中可以清楚地看到代价函数越小,线性模型越适合数据。
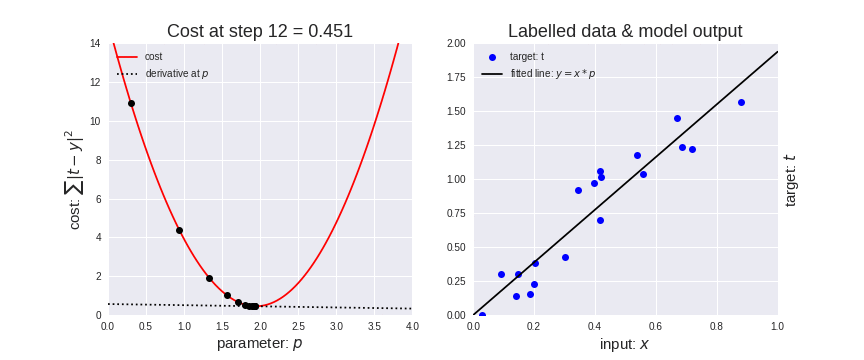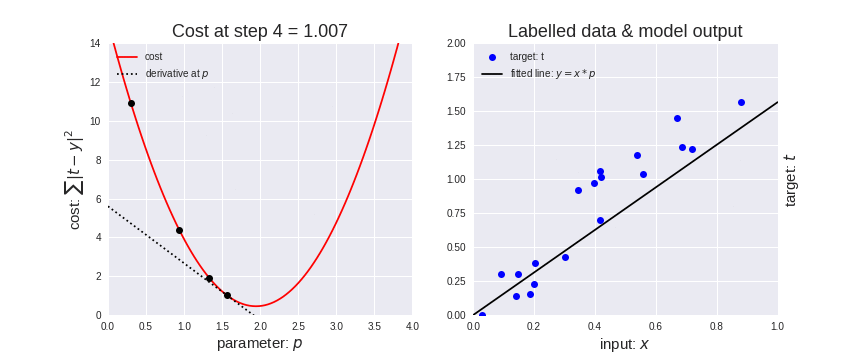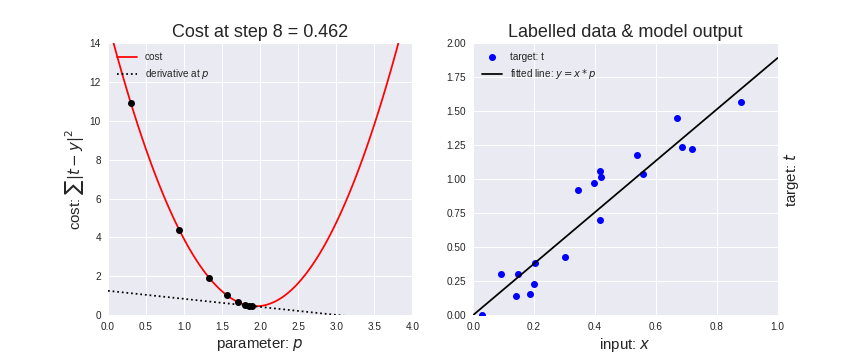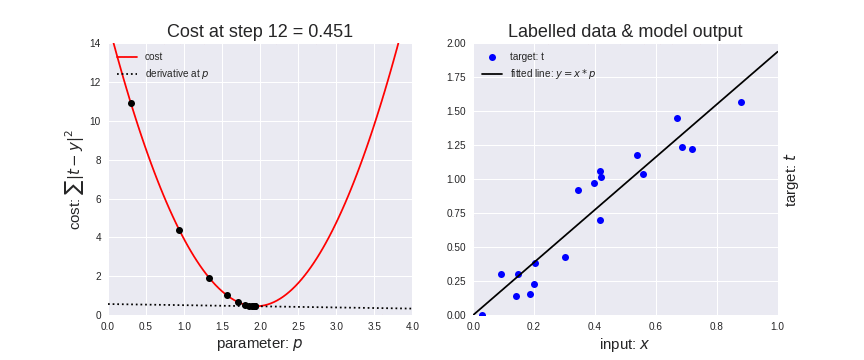
梯度下降应用于线性回归
此外,请注意一点,应该谨慎地选择学习率的取值,学习率太高可能会导致梯度超过目标最小值, 学习率太低可能导致网络模型收敛速度变慢。

小学习率与大学习率
在所有优化任务中,无论是在物理学、经济学还是计算机科学中,偏导数都被大量使用。偏导数主要用于计算因变量f(x, y, z)相对于其独立变量之一的变化率。例如,假设你拥有一个公司的股份,后者的股票会根据多种因素(证券、政治、销售收入等)上涨或下跌,在这种情况下通过偏导数,你会计算多少股票受到影响而其他因素保持不变,股票发生变化,则公司的价格也会发生变化。
池化层|Pooling Layer:
在最大池化特征图层中,梯度仅通过最大值反向传播,因此稍微更改它们并不会影响输出。在此过程中,我们将最大池化操作之前的最大值替换为1,并将所有非最大值设置为零,然后使用链式法则将渐变量乘以先前量以得到新的参数值。
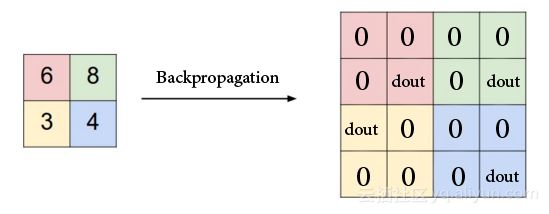
池化层反向传播
与最大池化层不同,在平均池化层中,梯度是通过所有的输入(在平均合并之前)进行传播。
卷积层|Convolution Layer:
你可能现在问自己,如果卷积层的前向传播是卷积,那么它的反向传播是什么?幸运的是,它的向后传播也是一个卷积,所以你不必担心学习新的难以掌握的数学运算。

卷积层反向传播
其中:
- ∂hij:损失函数的导数
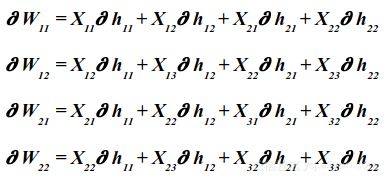
简而言之,上图表明了反向传播是如何在卷积层中起作用的。现在假设你已经对卷积神经网络有了深刻的理论理解,下面让我们用TensorFlow构建的第一个卷积神经网络吧。
TensorFlow实现卷积神经网络:
什么是Tensorflow?

TensorFlow是一个使用数据流图进行数值计算的开源软件库。它最初由谷歌机器智能研究机构谷歌大脑团队开发,用于机器学习和深度神经网络的研究。
什么是张量?
张量是一个有组织的多维数组,张量的顺序是表示它所需数组的维数。

张量的类型
什么是计算图?
计算图是计算代数中的一个基础处理方法,在机器学习中的神经网络和其他模型推导算法和软件包方面非常富有成效。计算图中的基本思想是表达一些模型——例如前馈神经网络,计算图作为表示计算步骤序列的一个有向图。序列中的每个步骤对应于计算图中的顶点, 每个步骤对应一个简单的操作,每个操作接受一些输入并根据其输入产生一些输出。
在下面的图示中,我们有两个输入w1 = x和w2 = y,这个输入将流经图形,其中图形中的每个节点都是数学运算,为我们提供以下输出:
- w3 = cos(x),余弦三角函数操作
- w4 = sin(x),正弦三角函数操作
- w5 = w3∙w4,乘法操作
- w6 = w1 / w2,除法操作
- w7 = w5 + w6,加法操作
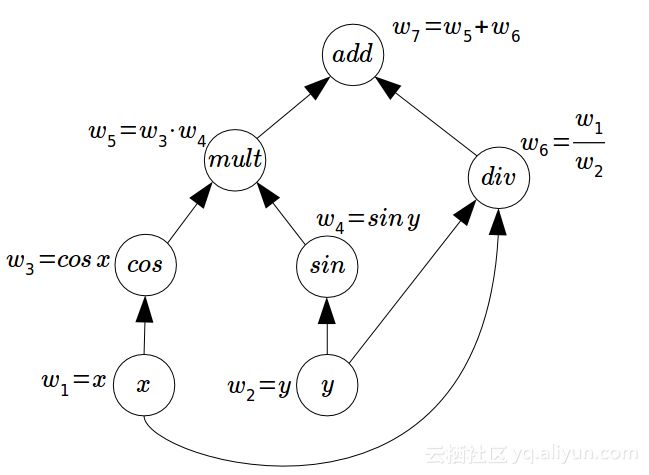
现在我们了解了什么是计算图,下面让我们TensorFlow中构建自己的计算图吧。
代码:
# Import the deep learning library
import tensorflow as tf
# Define our compuational graph
W1 = tf.constant(5.0, name = "x")
W2 = tf.constant(3.0, name = "y")
W3 = tf.cos(W1, name = "cos")
W4 = tf.sin(W2, name = "sin")
W5 = tf.multiply(W3, W4, name = "mult")
W6 = tf.divide(W1, W2, name = "div")
W7 = tf.add(W5, W6, name = "add")
# Open the session
with tf.Session() as sess:
cos = sess.run(W3)
sin = sess.run(W4)
mult = sess.run(W5)
div = sess.run(W6)
add = sess.run(W7)
# Before running TensorBoard, make sure you have generated summary data in a log directory by creating a summary writer
writer = tf.summary.FileWriter("./Desktop/ComputationGraph", sess.graph)
# Once you have event files, run TensorBoard and provide the log directory
# Command: tensorboard --logdir="path/to/logs" 使用Tensorboard进行可视化:
什么是Tensorboard?
TensorBoard是一套用于检查和理解TensorFlow运行和图形的Web应用程序,这也是Google的TensorFlow比Facebook的Pytorch最大的优势之一。

上面的代码在Tensorboard中进行可视化
在卷积神经网络、TensorFlow和TensorBoard有了深刻的理解,下面让我们一起构建我们的第一个使用MNIST数据集识别手写数字的卷积神经网络。

MNIST数据集
我们的卷积神经网络模型将似于LeNet-5架构,由卷积层、最大池化和非线性操作层。
卷积神经网络三维仿真
代码:
# Import the deep learning library
import tensorflow as tf
import time
# Import the MNIST dataset
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# Network inputs and outputs
# The network's input is a 28×28 dimensional input
n = 28
m = 28
num_input = n * m # MNIST data input
num_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
X = tf.placeholder(tf.float32, [None, num_input])
Y = tf.placeholder(tf.float32, [None, num_classes])
# Storing the parameters of our LeNET-5 inspired Convolutional Neural Network
weights = {
"W_ij": tf.Variable(tf.random_normal([5, 5, 1, 32])),
"W_jk": tf.Variable(tf.random_normal([5, 5, 32, 64])),
"W_kl": tf.Variable(tf.random_normal([7 * 7 * 64, 1024])),
"W_lm": tf.Variable(tf.random_normal([1024, num_classes]))
}
biases = {
"b_ij": tf.Variable(tf.random_normal([32])),
"b_jk": tf.Variable(tf.random_normal([64])),
"b_kl": tf.Variable(tf.random_normal([1024])),
"b_lm": tf.Variable(tf.random_normal([num_classes]))
}
# The hyper-parameters of our Convolutional Neural Network
learning_rate = 1e-3
num_steps = 500
batch_size = 128
display_step = 10
def ConvolutionLayer(x, W, b, strides=1):
# Convolution Layer
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return x
def ReLU(x):
# ReLU activation function
return tf.nn.relu(x)
def PoolingLayer(x, k=2, strides=2):
# Max Pooling layer
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, strides, strides, 1],
padding='SAME')
def Softmax(x):
# Softmax activation function for the CNN's final output
return tf.nn.softmax(x)
# Create model
def ConvolutionalNeuralNetwork(x, weights, biases):
# MNIST data input is a 1-D row vector of 784 features (28×28 pixels)
# Reshape to match picture format [Height x Width x Channel]
# Tensor input become 4-D: [Batch Size, Height, Width, Channel]
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# Convolution Layer
Conv1 = ConvolutionLayer(x, weights["W_ij"], biases["b_ij"])
# Non-Linearity
ReLU1 = ReLU(Conv1)
# Max Pooling (down-sampling)
Pool1 = PoolingLayer(ReLU1, k=2)
# Convolution Layer
Conv2 = ConvolutionLayer(Pool1, weights["W_jk"], biases["b_jk"])
# Non-Linearity
ReLU2 = ReLU(Conv2)
# Max Pooling (down-sampling)
Pool2 = PoolingLayer(ReLU2, k=2)
# Fully connected layer
# Reshape conv2 output to fit fully connected layer input
FC = tf.reshape(Pool2, [-1, weights["W_kl"].get_shape().as_list()[0]])
FC = tf.add(tf.matmul(FC, weights["W_kl"]), biases["b_kl"])
FC = ReLU(FC)
# Output, class prediction
output = tf.add(tf.matmul(FC, weights["W_lm"]), biases["b_lm"])
return output
# Construct model
logits = ConvolutionalNeuralNetwork(X, weights, biases)
prediction = Softmax(logits)
# Softamx cross entropy loss function
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
# Optimization using the Adam Gradient Descent optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_process = optimizer.minimize(loss_function)
# Evaluate model
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# recording how the loss functio varies over time during training
cost = tf.summary.scalar("cost", loss_function)
training_accuracy = tf.summary.scalar("accuracy", accuracy)
train_summary_op = tf.summary.merge([cost,training_accuracy])
train_writer = tf.summary.FileWriter("./Desktop/logs",
graph=tf.get_default_graph())
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
start_time = time.time()
for step in range(1, num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(training_process, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
loss, acc, summary = sess.run([loss_function, accuracy, train_summary_op], feed_dict={X: batch_x,
Y: batch_y})
train_writer.add_summary(summary, step)
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
end_time = time.time()
print("Time duration: " + str(int(end_time-start_time)) + " seconds")
print("Optimization Finished!")
# Calculate accuracy for 256 MNIST test images
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: mnist.test.images[:256],
Y: mnist.test.labels[:256]}))
上面的代码显得有些冗长,但如果一段一段的对其进行分解,读起来不是很难理解。
运行完该程序,对应结果应如下所示:
Step 1, Minibatch Loss= 74470.4844, Training Accuracy= 0.117
Step 10, Minibatch Loss= 20529.4141, Training Accuracy= 0.250
Step 20, Minibatch Loss= 14074.7539, Training Accuracy= 0.531
Step 30, Minibatch Loss= 7168.9839, Training Accuracy= 0.586
Step 40, Minibatch Loss= 4781.1060, Training Accuracy= 0.703
Step 50, Minibatch Loss= 3281.0979, Training Accuracy= 0.766
Step 60, Minibatch Loss= 2701.2451, Training Accuracy= 0.781
Step 70, Minibatch Loss= 2478.7153, Training Accuracy= 0.773
Step 80, Minibatch Loss= 2312.8320, Training Accuracy= 0.820
Step 90, Minibatch Loss= 2143.0774, Training Accuracy= 0.852
Step 100, Minibatch Loss= 1373.9169, Training Accuracy= 0.852
Step 110, Minibatch Loss= 1852.9535, Training Accuracy= 0.852
Step 120, Minibatch Loss= 1845.3500, Training Accuracy= 0.891
Step 130, Minibatch Loss= 1677.2566, Training Accuracy= 0.844
Step 140, Minibatch Loss= 1683.3661, Training Accuracy= 0.875
Step 150, Minibatch Loss= 1859.3821, Training Accuracy= 0.836
Step 160, Minibatch Loss= 1495.4796, Training Accuracy= 0.859
Step 170, Minibatch Loss= 609.3800, Training Accuracy= 0.914
Step 180, Minibatch Loss= 1376.5054, Training Accuracy= 0.891
Step 190, Minibatch Loss= 1085.0363, Training Accuracy= 0.891
Step 200, Minibatch Loss= 1129.7145, Training Accuracy= 0.914
Step 210, Minibatch Loss= 1488.5452, Training Accuracy= 0.906
Step 220, Minibatch Loss= 584.5027, Training Accuracy= 0.930
Step 230, Minibatch Loss= 619.9744, Training Accuracy= 0.914
Step 240, Minibatch Loss= 1575.8933, Training Accuracy= 0.891
Step 250, Minibatch Loss= 1558.5853, Training Accuracy= 0.891
Step 260, Minibatch Loss= 375.0371, Training Accuracy= 0.922
Step 270, Minibatch Loss= 1568.0758, Training Accuracy= 0.859
Step 280, Minibatch Loss= 1172.9205, Training Accuracy= 0.914
Step 290, Minibatch Loss= 1023.5415, Training Accuracy= 0.914
Step 300, Minibatch Loss= 475.9756, Training Accuracy= 0.945
Step 310, Minibatch Loss= 488.8930, Training Accuracy= 0.961
Step 320, Minibatch Loss= 1105.7720, Training Accuracy= 0.914
Step 330, Minibatch Loss= 1111.8589, Training Accuracy= 0.906
Step 340, Minibatch Loss= 842.7805, Training Accuracy= 0.930
Step 350, Minibatch Loss= 1514.0153, Training Accuracy= 0.914
Step 360, Minibatch Loss= 1722.1812, Training Accuracy= 0.875
Step 370, Minibatch Loss= 681.6041, Training Accuracy= 0.891
Step 380, Minibatch Loss= 902.8599, Training Accuracy= 0.930
Step 390, Minibatch Loss= 714.1541, Training Accuracy= 0.930
Step 400, Minibatch Loss= 1654.8883, Training Accuracy= 0.914
Step 410, Minibatch Loss= 696.6915, Training Accuracy= 0.906
Step 420, Minibatch Loss= 536.7183, Training Accuracy= 0.914
Step 430, Minibatch Loss= 1405.9148, Training Accuracy= 0.891
Step 440, Minibatch Loss= 199.4781, Training Accuracy= 0.953
Step 450, Minibatch Loss= 438.3784, Training Accuracy= 0.938
Step 460, Minibatch Loss= 409.6419, Training Accuracy= 0.969
Step 470, Minibatch Loss= 503.1216, Training Accuracy= 0.930
Step 480, Minibatch Loss= 482.6476, Training Accuracy= 0.922
Step 490, Minibatch Loss= 767.3893, Training Accuracy= 0.922
Step 500, Minibatch Loss= 626.8249, Training Accuracy= 0.930
Time duration: 657 seconds
Optimization Finished!
Testing Accuracy: 0.9453125
综上,们刚刚完成了第一个卷积神经网络的构建,正如在上面的结果中所看到的那样,从第一步到最后一步,模型的准确性已经得到很大的提升,但我们的卷积神经网络还有较大的改进空间。
现在让我们在Tensorboard中可视化构建的卷积神经网络模型:
可视化卷积神经网络

准确性和损失评估
结论:
卷积神经网络是一个强大的深度学习模型,应用广泛,性能优异。卷积神经网络的使用只会随着数据变大和问题变得更加复杂变得更加具有挑战性。
注意:
可以在以下位置找到本文的Jupyter笔记本:
- https://github.com/AegeusZerium/DeepLearning/blob/master/Deep%20Learning/Demystifying%20Convolutional%20Neural%20Networks.ipynb
参考文献:
- https://en.wikipedia.org/wiki/Convolutional_neural_network
- https://en.wikipedia.org/wiki/Yann_LeCun
* http://yann.lecun.com/exdb/mnist/ - https://opensource.com/article/17/11/intro-tensorflow
- https://en.wikipedia.org/wiki/Tensor
- http://www.cs.columbia.edu/~mcollins/ff2.pdf
- https://github.com/tensorflow/tensorboard
- http://yann.lecun.com/exdb/lenet/
作者信息
Lightning Blade,机器学习热爱者
本文由阿里云云栖社区组织翻译。
文章原标题《Demystifying Convolutional Neural Networks》,译者:海棠,审校:Uncle_LLD。