【论文简述】DPSNet End-to-end Deep Plane Sweep Stereo(ICLR 2019)
一、论文简述
1. 第一作者:Sunghoon Im
2. 发表年份:2019
3. 发表期刊:ICLR
4. 关键词:MVS、深度学习、端到端、代价体、代价聚合
5. 探索动机:双目立体匹配无法扩展到多视图,平面扫描方法无法进行端到端学习。
- Recently, convolutional neural networks (CNNs) have demonstrated some capacity to address this issue by leveraging semantic information inferred from the scene. The most promising of these methods employ a traditional stereo matching pipeline, which involves computation of matching cost volumes, cost aggregation, and disparity estimation. Some are designed for binocular stereo and cannot readily be extended to multiple views.
- The CNN-based techniques for multiview processing both follow the plane-sweep approach, but require plane-sweep volumes as input to their networks.As a result, they are not end-to-end systems that can be trained from input images to disparity maps.
6. 工作目标:解决上述问题。
7. 核心思想:提出了深度平面扫描网络(DPSNet),用于鲁棒的MVS的端到端CNN框架。和同期的MVSNet的工作的区别如下:
we would like to refer the reader to the concurrent work by Yao et al. (2018) that also adopts differential warping to construct a multi-scale cost volume, then refined an initial depth map guided by a reference image feature. Our work is independent of this concurrent effort. Moreover, we make distinct contributions: (1) We focus on dense depth estimation for a reference image in an end-to-end learning manner, different from Yao et al. (2018) which reconstructs the full 3D of objects. (2) Our cost volume is constructed by concatenating input feature maps, which enables inference of accurate depth maps even with only two-view matching. (3) Our work refines every cost slice by applying context features of a reference image, which is beneficial for alleviating coarsely scattered unreliable matches such as for large textureless regions.
8. 实验结果:在几个数据集上获得了最先进的结果,消融研究表明,每一项技术都能提高精度。
9. 论文下载:
https://arxiv.org/pdf/1905.00538.pdf
二、实现过程
1. DPSNet概述
深度平面扫描网络(DPSNet)由四个部分组成:特征提取、代价体构建、代价聚合和深度图回归。

2. 多尺度特征提取
首先将参考图像和目标图像输入7个卷积层(第一层7×7滤波器,其它层3 × 3滤波器)进行编码,并使用空间金字塔池化(SPP)模块从这些图像中提取多层次的上下文信息,有四个固定大小的平均池化块(16×16;8×8;4×4:2×2)。将多层次的上下文信息上采样到与原始特征图相同的大小后,将所有特征图连接起来,并输入2D卷积层,为所有输入图像生成32通道特征表示,用于构建代价体。
3. 使用非结构化双视图图像生成代价体
使用传统的平面扫描立体来生成图像对的代价体。为了减少图像噪声的影响,可以通过平均其他图像对的代价体来利用多个图像。首先设置垂直于参考视点z轴的虚拟平面的数量,并在逆深度空间均匀采样,如下所示:
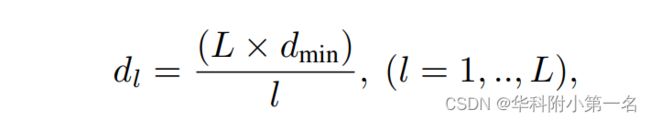
其中L是深度标签的总数,dmin是用户指定的最小场景深度。
通过连接所有深度的参考图像特征和形变图像的特征,获得了一个4D体(W×H×2C×L),连接特征比特征的绝对差值更能提高性能。
给定4D体,DPSNet通过在连接的特征上使用一系列3D卷积来学习大小为W × H × L的代价体。所有的卷积层由3 × 3 × 3滤波器和残差块组成。在训练步骤中,只使用一个配对图像(另一个是参考图像)来获得代价体。在测试中,可以通过平均所有的代价体来使用任意数量的配对图像(N≥1)。
4. 代价聚合
代价聚合的关键思想是通过保留边缘的滤波在支持窗口内正则化噪声的代价体。在端到端学习过程中引入了一种上下文感知的代价聚合方法。上下文网络获取的代价体的每个切片和从上一步提取参考图像的特征,然后输出经过改进的代价切片。我们对所有代价切片执行相同的流程。将初始体和残差体相加得到最终的代价体。
具体,在上下文网络中使用空洞卷积进行代价聚合,以更好地利用上下文信息。上下文网络由7个带有3 × 3滤波器的卷积层组成,其中每一层都有不同的感受野(1,2,4,8,16,1和1)。使用上下文网络的共享权重来处理所有的代价切片。然后,通过双线性插值将代价体(其大小等于特征大小)上采样到图像的原始大小。

5. 深度回归
通过softmax运算σ(·)从预测代价cl计算每个标签概率。通过加权和计算预测标签值。深度由标签数量L和最小场景深度dmin计算,L和dmin分别设为64和0.5,如下所示:
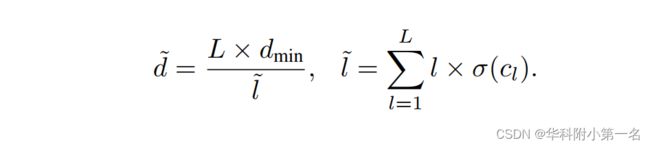
6. 训练损失
设θ为网络中所有可学习参数的集合,包括特征提取、代价体生成和代价聚合(平面扫描和深度回归没有可学习参数)。让d^,d~分别为初始代价体和改进代价体的预测深度,设dgt为相应的监督信号。训练损失的公式为:
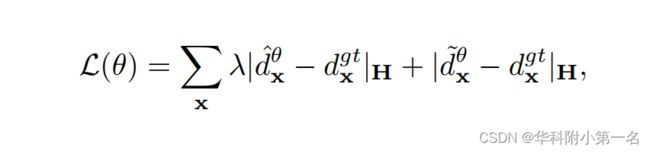
其中j·jH为Huber范数,在PyTorch中称为SmoothL1Loss。λ设置为0.7。
7. 实验
7.1. 数据集
MVS,SUN3D, RGBD,Scenes11,ETH3D
7.2. 实现
从头开始训练模型需要进行1200K次迭代。使用ADAM优化器,批大小为16,PyTorch,四个NVIDIA 1080Ti GPU,通常需要4天。网络2视图匹配前向传递大约需要0.5秒,每匹配一个新帧(640 × 480图像分辨率)需要额外的0.25秒。
7.3. 结果
SOTA