springboot项目实现 redis缓存穿透,雪崩,击穿模拟与解决方案演示
文章目录
-
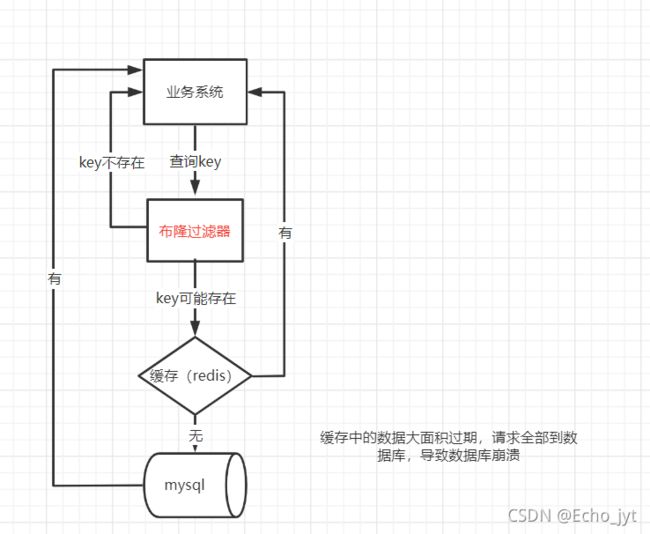
- 用户获取数据的过程
-
- 传统
-
- 传统系统的问题
- 为什么直接请求数据库会很慢
- 引入redis缓存
- 引入redis带来的常见问题
-
- 缓存穿透
-
- 场景模拟
-
- 步骤
- 解决方案
- 解决方案模拟演示——使用布隆过滤器进行非法数据拦截
-
- 布隆过滤器简介
- 使用谷歌的布隆过滤器
- 缓存雪崩
-
- 场景模拟
- 解决
- 解决方案模拟演示——使用加锁
- 缓存击穿
-
- 场景模拟
- 解决方案
- 解决方案模拟——加锁
用户获取数据的过程
传统
没有缓存,直接请求数据库。
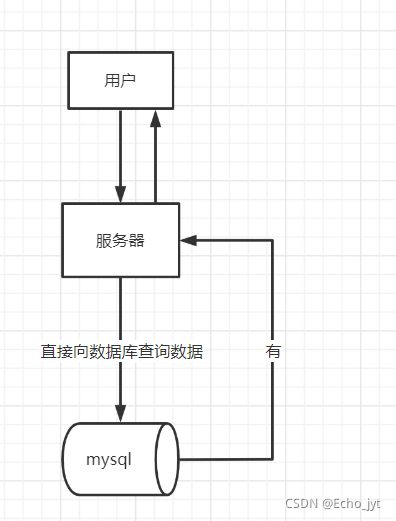
现在也有很多内部系统,教务系统等等都是这样的
传统系统的问题
最明显的问题就是: 慢!。
大家没发现我们学校的抢课系统每次都很慢吗?我猜大概率就是没用缓存,或者说服务做得不好,再或者代码写得有问题等等。
为什么直接请求数据库会很慢
大家需要知道一个知识:
- 请求速度:HTTP > > > IO流 > > > redis缓存 > > > java缓存
- mysql 数据库对于高并发来说天然支持不好,mysql 单机支撑到 2000QPS 也开始容易报警了
- 查一次数据库会耗时很多,一旦当数据请求量过大和高并发来了的时候,数据库就挺不住了,就会一直执行select语句,直接崩掉。这就抢课系统会很慢的原因!
引入redis缓存
所以我们需要redis, 因为它高性能,高并发

凡事有利也有弊
引入redis带来的常见问题
缓存穿透,雪崩,击穿
缓存穿透
- 含义:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,导致数据库崩溃的现象
- 为什么会有用户请求没有的数据呢?这种情况一般都是黑客攻击
- 请求每次都“视缓存于无物”,直接查询数据库,这种恶意攻击场景的缓存穿透就会直接把数据库给打死。

场景模拟
步骤
- 为了安全,利用hashMap模拟数据库
/**
* HashMap模拟数据库数据
*/
private static Map<Long, DataObject> dbDataList = new HashMap<>();
/**
* 初始化数据库,值为1~10000
*/
@PostConstruct
private void initData() {
for (long i = 1; i <= maxIdnum; i++) {
//addToBloomFilter(String.valueOf(i));
dbDataList.put(i, new DataObject(i, "name:" + i));
}
}
-
数据库中现在有一个为id的键,现在存有1~10000的数据。
-
我们去请求10001~11000,这是数据库没有的数据

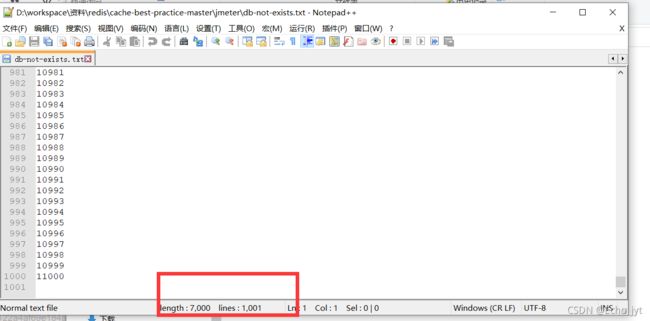
-
利用jmeter进行测试,线程数为1000,重复执行3次
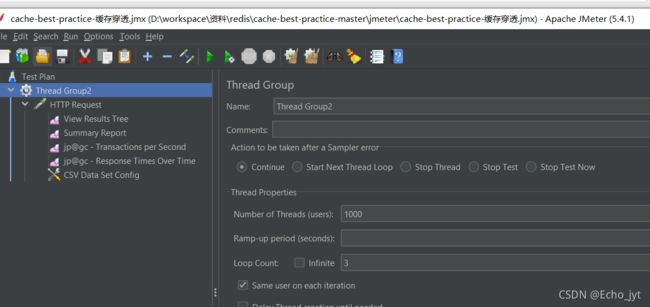
观察输出结果,可以发现3000次请求全部打到数据库去了,我们这里只是模拟了一下,实际黑客攻击是,并发量可能更大,直接会把你的数据库打崩的。


解决方案
-
对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,等下次再次查询缓存的时候就会有这个值,就不再向数据库请求了。设置空结果的过期时间会很短,最长不超过五分钟。
-
设置可访问的白名单:使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
-
采用布隆过滤器:布隆过滤器可以用于检索一个元素是否在一个集合中,将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
-
进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
解决方案模拟演示——使用布隆过滤器进行非法数据拦截
布隆过滤器简介
- 它的优点是空间效率和查询时间都远远超过一般的算法,
- 缺点是有一定的误识别率和删除困难,可以判断一个数据一定不存在,只能判断一个数据极大概率存在,原因是因为hash冲突
比如数据 a a a, b i t [ h 1 ] ∗ b i t [ h 2 ] ∗ b i t [ h 3 ] = 1 bit[h_1]*bit[h_2] *bit[h_3] = 1 bit[h1]∗bit[h2]∗bit[h3]=1 ,说明它大概率存在
查询数据 d d d, b i t [ h 1 ] ∗ b i t [ h 2 ] ∗ b i t [ h 3 ] = 1 bit[h_1]*bit[h_2] *bit[h_3] = 1 bit[h1]∗bit[h2]∗bit[h3]=1 ,但是它不存在,因为它的hash值恰好和 a a a 的hash值一样
查询数据e, b i t [ h 1 ] ∗ b i t [ h 2 ] ∗ b i t [ h 3 ] = 0 bit[h_1]*bit[h_2] *bit[h_3] = 0 bit[h1]∗bit[h2]∗bit[h3]=0,一定不存在

使用谷歌的布隆过滤器
导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
BloomFilterHelper
package com.jyt.test;
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
// 设定最小期望长度
p = Double.MIN_VALUE;
}
int sizeOfBitArray = (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
return sizeOfBitArray;
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
int countOfHash = Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
return countOfHash;
}
}
RedisBloomFilter
package com.jyt.test;
import com.google.common.base.Preconditions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
/**
* @Classname RedisBloomFilter
* @Description TODO
* @Date 2021/11/1 19:36
* @Created by Echo
*/
@Service
public class RedisBloomFilter {
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
// System.out.println("key : " + key + " " + "value : " + i);
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
// System.out.println("key : " + key + " " + "value : " + i);
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
简单看看代码逻辑
public DataObject getData(Long id) {
//布隆过滤器中不存在,则直接返回空
if (!bloomFilteExists(String.valueOf(id))) {
System.out.println("布隆过滤器中不存在, id: " + id);
return null;
}
//从缓存读取数据
DataObject result = getDataFromCache(id);
if (result == null) {
//缓存不存在,从数据库查询数据的过程加上锁,避免缓存击穿导致数据库压力过大
RLock lock = redissonClient.getLock(DATA_LOCK_NAME + id);
lock.lock(15, TimeUnit.SECONDS);
if (lock.isLocked()) {
try {
//双重判断,第二个以及之后的请求不必去找数据库,直接命中缓存
//再次查询缓存
result = getDataFromCache(id);
if (result == null) {
// 从数据库查询数据
result = getDataFromDB(id);
// 将查询到的数据写入缓存
setDataToCache(id, result);
}
} finally {
//锁只能被拥有它的线程解锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
} else {
if (result.getId() == ID_NOT_EXISTS) {
return null;
}
}
return result;
}

所有的请求都被布隆过滤器拦截了

缓存雪崩
- 含义:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮
- 这个时候的redis形同虚设,数据请求全部到数据库中去了
比如双11淘宝网首页的数据,在redis中突然大面积过期,那么全国上千万的并发量直接请求阿里的数据库,必然会造成缓存雪崩,直接把数据库打崩。

场景模拟
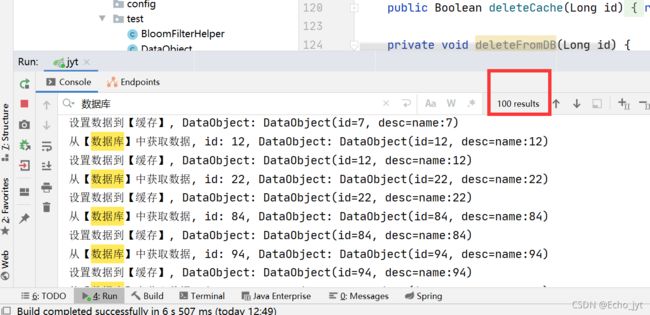
数据库中有1-10000 的数据,我们手动删除1-100的数据,,模拟缓存大面积失效。
利用jmeter测试:300并发量,循环10次
查询了数据库200次数据库

解决
- 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
- 使用锁或队列:用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。
- 设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
- 将缓存失效时间分散开:比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
解决方案模拟演示——使用加锁
public DataObject getData(Long id) {
//布隆过滤器中不存在,则直接返回空
if (!bloomFilteExists(String.valueOf(id))) {
System.out.println("布隆过滤器中不存在, id: " + id);
return null;
}
//从缓存读取数据
DataObject result = getDataFromCache(id);
if (result == null) {
//缓存不存在,从数据库查询数据的过程加上锁,避免缓存击穿导致数据库压力过大
RLock lock = redissonClient.getLock(DATA_LOCK_NAME + id);
lock.lock(15, TimeUnit.SECONDS);
if (lock.isLocked()) {
try {
//双重判断,第二个以及之后的请求不必去找数据库,直接命中缓存
//再次查询缓存
result = getDataFromCache(id);
if (result == null) {
// 从数据库查询数据
result = getDataFromDB(id);
// 将查询到的数据写入缓存
setDataToCache(id, result);
}
} finally {
//锁只能被拥有它的线程解锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
} else {
if (result.getId() == ID_NOT_EXISTS) {
return null;
}
}
return result;
}
每个数据值请求了数据库一次,其余的都命中了缓存
缓存击穿
- 含义:某一个高热点的key突然过期,这个时候高并发请求过来,从这个点出去全部请求到数据库导致数据库崩溃的现象,就像在一个完好无损的桶上凿开了一个洞,所以叫做击穿

场景模拟
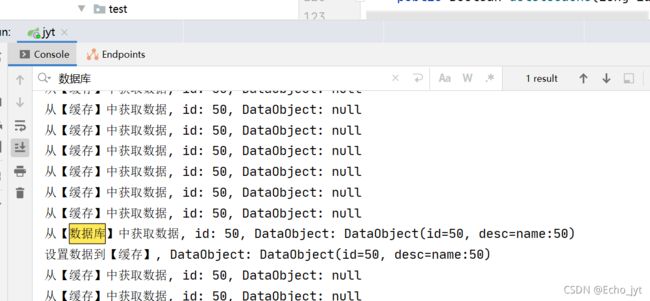
假设id值为50的数据是一个高热点数据,我们手动删除它,模仿突然过期
删除:
curl http://127.0.0.1:8080/data/deleteCache?id=50
查询:
curl http://127.0.0.1:8080/data/getData1?id=50
利用jmeter测试:100并发量,循环1次

解决方案
与缓存雪崩类似
- 设置热点数据永远不过期
- 或者加上互斥锁就能搞定了
解决方案模拟——加锁
只有一次请求到数据库,其余请求都命中了缓存
本人是菜鸟学生,在准备redis的技术分享,很多东西都是在网上查的加上自己的讲解,代码是从网上大佬趴下来改的。
参考:
https://blog.csdn.net/huchao_lingo/article/details/105552004
https://mp.weixin.qq.com/s/knz-j-m8bTg5GnKc7oeZLg
https://space.bilibili.com/130763764/search/video?keyword=%E7%BC%93%E5%AD%98
https://blog.csdn.net/qq_28743877/article/details/104721672
https://blog.csdn.net/weixin_43748936/article/details/110225696