1、代理模式(Proxy Pattern)
直接与间接:
人们对复杂的软件系统常有一种处理手法,即增加一层间接层,从而对系统获得一种更为灵活、
满足特定需求的解决方案。

动机(Motivate):
在面向对象系统中,有些对象由于某种原因(比如对象创建的开销很大,或者某些操作需要安全控制,或者需要进程外的访问等),直接访问会给使用者、或者系统结构带来很多麻烦。
如何在不失去透明操作对象的同时来管理/控制这些对象特有的复杂性?增加一层间接层是软件开发中常见的解决方式。
意图(Intent):
为其他对象提供一种代理以控制对这个对象的访问。
--摘自《设计模式》
结构图(Struct):
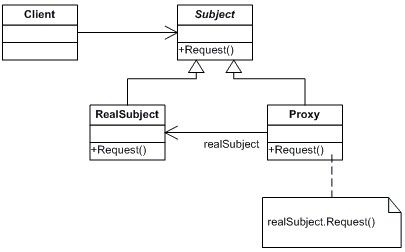
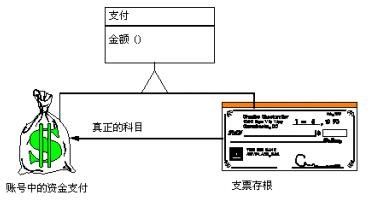
生活中的例子:
代理模式提供一个中介以控制对这个对象的访问。一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。
代码实例:
在软件系统中,我们无时不在跨越障碍,当我们访问网络上一台计算机的资源时,我们正在跨越网络障碍,当我们去访问服务器上数据库时,我们又在跨越数据库访问障碍,同时还有网络障碍。跨越这些障碍有时候是非常复杂的,如果我们更多的去关注处理这些障碍问题,可能就会忽视了本来应该关注的业务逻辑问题,Proxy模式有助于我们去解决这些问题。我们以一个简单的数学计算程序为例,这个程序只负责进行简单的加减乘除运算:
public class Math { public double Add(double x, double y) { return x + y; } public double Sub(double x, double y) { return x - y; } public double Mul(double x, double y) { return x * y; } public double Dev(double x, double y) { return x / y; } }
如果说这个计算程序部署在我们本地计算机上,使用就非常之简单了,我们也就不用去考虑Proxy模式了。但现在问题是这个Math类并没有部署在我们本地,而是部署在一台服务器上,也就是说Math类根本和我们的客户程序不在同一个地址空间之内,我们现在要面对的是跨越Internet这样一个网络障碍:

这时候调用Math类的方法就没有下面那么简单了,因为我们更多的还要去考虑网络的问题,对接收到的结果解包等一系列操作。
public class App { public static void Main() { Math math = new Math(); // 对接收到的结果数据进行解包 double addresult = math.Add(2,3); double subresult = math.Sub(6,4); double mulresult = math.Mul(2,3); double devresult = math.Dev(2,3); } }
为了解决由于网络等障碍引起复杂性,就引出了Proxy模式,我们使用一个本地的代理来替Math类打点一切,即为我们的系统引入了一层间接层,示意图如下:
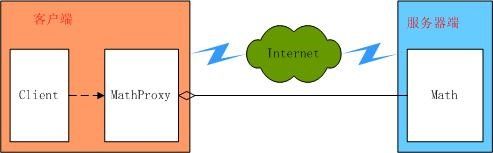
我们在MathProxy中对实现Math数据类的访问,让MathProxy来代替网络上的Math类,这样我们看到MathProxy就好像是本地Math类,它与客户程序处在了同一地址空间内:
public class MathProxy { private Math math = new Math(); // 以下的方法中,可能不仅仅是简单的调用Math类的方法 public double Add(double x, double y) { return math.Add(x, y); } public double Sub(double x, double y) { return math.Sub(x, y); } public double Mul(double x, double y) { return math.Mul(x, y); } public double Dev(double x, double y) { return math.Dev(x, y); } }
现在可以说我们已经实现了对Math类的代理,存在的一个问题是我们在MathProxy类中调用了原实现类Math的方法,但是Math并不一定实现了所有的方法,为了强迫Math类实现所有的方法,另一方面,为了我们更加透明的去操作对象,我们在Math类和MathProxy类的基础上加上一层抽象,即它们都实现与IMath接口,示意图如下:
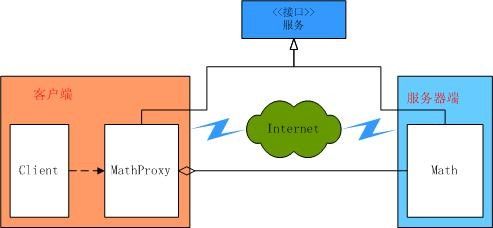
public interface IMath { double Add(double x, double y); double Sub(double x, double y); double Mul(double x, double y); double Dev(double x, double y); } // Math类和MathProxy类分别实现IMath接口: public class MathProxy : IMath { // } public class Math : IMath { // }
此时我们在客户程序中就可以像使用Math类一样来使用MathProxy类了:
public class App { public static void Main() { MathProxy proxy = new MathProxy(); double addresult = proxy.Add(2, 3); double subresult = proxy.Sub(6, 4); double mulresult = proxy.Mul(2, 3); double devresult = proxy.Dev(2, 3); } }
到这儿整个使用Proxy模式的过程就完成了,回顾前面我们的解决方案,无非是在客户程序和Math类之间加了一个间接层,这也是我们比较常见的解决问题的手段之一。另外,对于程序中的接口Imath,并不是必须的,大多数情况下,我们为了保持对对象操作的透明性,并强制实现类实现代理类所要调用的所有的方法,我们会让它们实现与同一个接口。但是我们说代理类它其实只是在一定程度上代表了原来的实现类,所以它们有时候也可以不实现于同一个接口。
代理模式实现要点:
1.远程(Remote)代理:为一个位于不同的 地址空间的对象提供一个局域代表对象。这个不同的地址空间可以是在本机器中,也可是在另一台机器中。远程代理又叫做大使(Ambassador)。好处是系统可以将网络的细节隐藏起来,使得客户端不必考虑网络的存在。客户完全可以认为被代理的对象是局域的而不是远程的,而代理对象承担了大部份的网络通讯工作。由于客户可能没有意识到会启动一个耗费时间的远程调用,因此客户没有必要的思想准备。
2.虚拟(Virtual)代理:根据需要创建一个资源消耗较大的对象,使得此对象只在需要时才会被真正创建。使用虚拟代理模式的好处就是代理对象可以在必要的时候才将被代理的对象加载;代理可以对加载的过程加以必要的优化。当一个模块的加载十分耗费资源的情况下,虚拟代理的好处就非常明显。
3.Copy-on-Write代理:虚拟代理的一种。把复制(克隆)拖延到只有在客户端需要时,才真正采取行动。
4.保护(Protect or Access)代理:控制对一个对象的访问,如果需要,可以给不同的用户提供不同级别的使用权限。保护代理的好处是它可以在运行时间对用户的有关权限进行检查,然后在核实后决定将调用传递给被代理的对象。
5.Cache代理:为某一个目标操作的结果提供临时的存储空间,以便多个客户端可以共享这些结果。
6.防火墙(Firewall)代理:保护目标,不让恶意用户接近。
7.同步化(Synchronization)代理:使几个用户能够同时使用一个对象而没有冲突。
8.智能引用(Smart Reference)代理:当一个对象被引用时,提供一些额外的操作,比如将对此对象调用的次数记录下来等。
2、迭代器模式(Iterator Pattern)
动机(Motivate):
在软件构建过程中,集合对象内部结构常常变化各异。但对于这些集合对象,我们希望在不暴露其内部结构的同时,可以让外部客户代码透明地访问其中包含的元素;同时这种“透明遍历”也为“ 同一种算法在多种集合对象上进行操作”提供了可能。
使用面向对象技术将这种遍历机制抽象为“迭代器对象”为“应对变化中的集合对象”提供了一种优雅的方法。
意图(Intent):
提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。
--摘自《设计模式》
结构图(Struct):
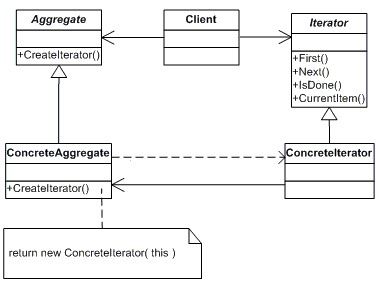
适用性:
1.访问一个聚合对象的内容而无需暴露它的内部表示。
2.支持对聚合对象的多种遍历。
3.为遍历不同的聚合结构提供一个统一的接口(即, 支持多态迭代)。
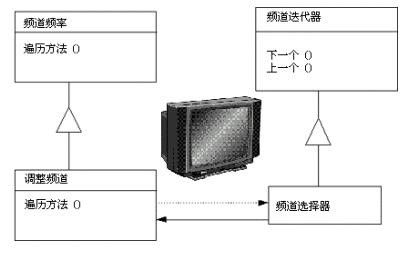
生活中的例子:
迭代器提供一种方法顺序访问一个集合对象中各个元素,而又不需要暴露该对象的内部表示。在早期的电视机中,一个拨盘用来改变频道。当改变频道时,需要手工转动拨盘移过每一个频道,而不论这个频道是否有信号。现在的电视机,使用[后一个]和[前一个]按钮。当按下[后一个]按钮时,将切换到下一个预置的频道。想象一下在陌生的城市中的旅店中看电视。当改变频道时,重要的不是几频道,而是节目内容。如果对一个频道的节目不感兴趣,那么可以换下一个频道,而不需要知道它是几频道。
代码实现:
在面向对象的软件设计中,我们经常会遇到一类集合对象,这类集合对象的内部结构可能有着各种各样的实现,但是归结起来,无非有两点是需要我们去关心的:一是集合内部的数据存储结构,二是遍历集合内部的数据。面向对象设计原则中有一条是类的单一职责原则,所以我们要尽可能的去分解这些职责,用不同的类去承担不同的职责。Iterator模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明的访问集合内部的数据。下面看一个简单的示意性例子,类结构图如下:
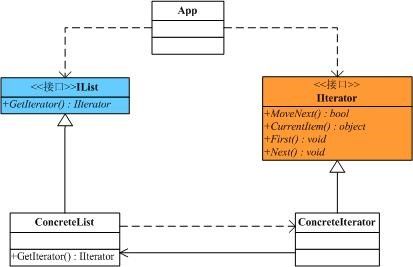
首先有一个抽象的聚集,所谓的聚集就是就是数据的集合,可以循环去访问它。它只有一个方法GetIterator()让子类去实现,用来获得一个迭代器对象。
////// 抽象聚集 /// public interface IList { IIterator GetIterator(); }
抽象的迭代器,它是用来访问聚集的类,封装了一些方法,用来把聚集中的数据按顺序读取出来。通常会有MoveNext()、CurrentItem()、Fisrt()、Next()等几个方法让子类去实现。
////// 抽象迭代器 /// public interface IIterator { bool MoveNext(); Object CurrentItem(); void First(); void Next(); }
具体的聚集,它实现了抽象聚集中的唯一的方法,同时在里面保存了一组数据,这里我们加上Length属性和GetElement()方法是为了便于访问聚集中的数据。
////// 具体聚集 /// public class ConcreteList : IList { int[] list; public ConcreteList() { list = new int[] { 1, 2, 3, 4, 5 }; } public IIterator GetIterator() { return new ConcreteIterator(this); } public int Length { get { return list.Length; } } public int GetElement(int index) { return list[index]; } }
具体迭代器,实现了抽象迭代器中的四个方法,在它的构造函数中需要接受一个具体聚集类型的参数,在这里面我们可以根据实际的情况去编写不同的迭代方式。
/**/ ////// 具体迭代器 /// public class ConcreteIterator : IIterator { private ConcreteList list; private int index; public ConcreteIterator(ConcreteList list) { this.list = list; index = 0; } public bool MoveNext() { if (index < list.Length) return true; else return false; } public Object CurrentItem() { return list.GetElement(index); } public void First() { index = 0; } public void Next() { if (index < list.Length) { index++; } } }
简单的客户端程序调用:
/**/////// 客户端程序 /// class Program { static void Main(string[] args) { IIterator iterator; IList list = new ConcreteList(); iterator = list.GetIterator(); while (iterator.MoveNext()) { int i = (int)iterator.CurrentItem(); Console.WriteLine(i.ToString()); iterator.Next(); } Console.Read(); } }
.NET中Iterator中的应用:
在.NET下实现Iterator模式,对于聚集接口和迭代器接口已经存在了,其中IEnumerator扮演的就是迭代器的角色,它的实现如下:
public interface IEumerator { object Current { get; } bool MoveNext(); void Reset(); }
属性Current返回当前集合中的元素,Reset()方法恢复初始化指向的位置,MoveNext()方法返回值true表示迭代器成功前进到集合中的下一个元素,返回值false表示已经位于集合的末尾。能够提供元素遍历的集合对象,在.Net中都实现了IEnumerator接口。
IEnumerable则扮演的就是抽象聚集的角色,只有一个GetEnumerator()方法,如果集合对象需要具备跌代遍历的功能,就必须实现该接口。
public interface IEnumerable { IEumerator GetEnumerator(); }
Iterator实现要点:
1.迭代抽象:访问一个聚合对象的内容而无需暴露它的内部表示。
2.迭代多态:为遍历不同的集合结构提供一个统一的接口,从而支持同样的算法在不同的集合结构上进行操作。
3.迭代器的健壮性考虑:遍历的同时更改迭代器所在的集合结构,会导致问题。
3、命令模式(Command Pattern)
耦合与变化:
耦合是软件不能抵御变化灾难的根本性原因。不仅实体对象与实体对象之间存在耦合关系,实体对象与行为操作之间也存在耦合关系。
动机(Motivate):
在软件系统中,“行为请求者”与“行为实现者”通常呈现一种“紧耦合”。但在某些场合,比如要对行为进行“记录、撤销/重做、事务”等处理,这种无法抵御变化的紧耦合是不合适的。
在这种情况下,如何将“行为请求者”与“行为实现者”解耦?将一组行为抽象为对象,可以实现二者之间的松耦合。
意图(Intent):
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤消的操作。
--摘自《设计模式》
结构图(Struct):
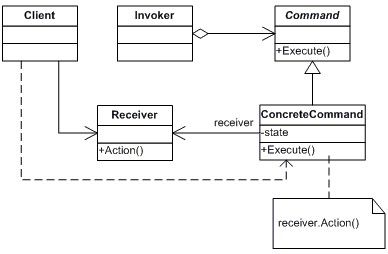
适用性:
1.使用命令模式作为"CallBack"在面向对象系统中的替代。"CallBack"讲的便是先将一个函数登记上,然后在以后调用此函数。
2.需要在不同的时间指定请求、将请求排队。一个命令对象和原先的请求发出者可以有不同的生命期。换言之,原先的请求发出者可能已经不在了,而命令对象本身仍然是活动的。这时命令的接收者可以是在本地,也可以在网络的另外一个地址。命令对象可以在串形化之后传送到另外一台机器上去。
3.系统需要支持命令的撤消(undo)。命令对象可以把状态存储起来,等到客户端需要撤销命令所产生的效果时,可以调用undo()方法,把命令所产生的效果撤销掉。命令对象还可以提供redo()方法,以供客户端在需要时,再重新实施命令效果。
4.如果一个系统要将系统中所有的数据更新到日志里,以便在系统崩溃时,可以根据日志里读回所有的数据更新命令,重新调用Execute()方法一条一条执行这些命令,从而恢复系统在崩溃前所做的数据更新。
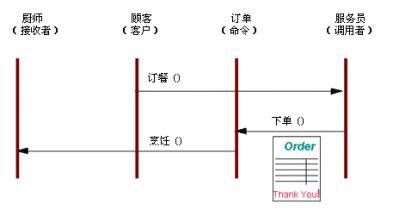
生活中的例子:
Command模式将一个请求封装为一个对象,从而使你可以使用不同的请求对客户进行参数化。用餐时的账单是Command模式的一个例子。服务员接受顾客的点单,把它记在账单上封装。这个点单被排队等待烹饪。注意这里的"账单"是不依赖于菜单的,它可以被不同的顾客使用,因此它可以添入不同的点单项目。
代码实现:
在众多的设计模式中,Command模式是很简单也很优雅的一种设计模式。Command模式它封装的是命令,把命令发出者的责任和命令执行者的责任分开。我们知道,一个类是一组操作和相应的一些变量的集合,现在有这样一个类Document,如下:

////// 文档类 /// public class Document { /**//// /// 显示操作 /// public void Display() { Console.WriteLine("Display"); } /**//// /// 撤销操作 /// public void Undo() { Console.WriteLine("Undo"); } /**//// /// 恢复操作 /// public void Redo() { Console.WriteLine("Redo"); } }
通常客户端实现代码如下:
class Program { static void Main(string[] args) { Document doc = new Document(); doc.Display(); doc.Undo(); doc.Redo(); } }
这样的使用本来是没有任何问题的,但是我们看到在这个特定的应用中,出现了Undo/Redo的操作,这时如果行为的请求者和行为的实现者之间还是呈现这样一种紧耦合,就不太合适了。可以看到,客户程序是依赖于具体Document的命令(方法)的,引入Command模式,需要对Document中的三个命令进行抽象,这是Command模式最有意思的地方,因为在我们看来Display(),Undo(),Redo()这三个方法都应该是Document所具有的,如果单独抽象出来成一个命令对象,那就是把函数层面的功能提到了类的层面,有点功能分解的味道,我觉得这正是Command模式解决这类问题的优雅之处,先对命令对象进行抽象:
![]()
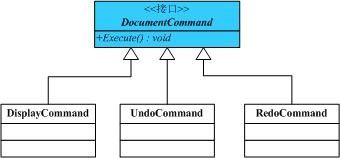
////// 抽象命令 /// public abstract class DocumentCommand { Document _document; public DocumentCommand(Document doc) { this._document = doc; } /**//// /// 执行 /// public abstract void Execute(); }
其他的具体命令类都继承于该抽象类,如下:
示意性代码如下:
////// 显示命令 /// public class DisplayCommand : DocumentCommand { public DisplayCommand(Document doc) : base(doc) { } public override void Execute() { _document.Display(); } } /**//// /// 撤销命令 /// public class UndoCommand : DocumentCommand { public UndoCommand(Document doc) : base(doc) { } public override void Execute() { _document.Undo(); } } /**//// /// 重做命令 /// public class RedoCommand : DocumentCommand { public RedoCommand(Document doc) : base(doc) { } public override void Execute() { _document.Redo(); } }
现在还需要一个Invoker角色的类,这其实相当于一个中间角色,前面我曾经说过,使用这样的一个中间层也是我们经常使用的手法,即把A对B的依赖转换为A对C的依赖。如下:
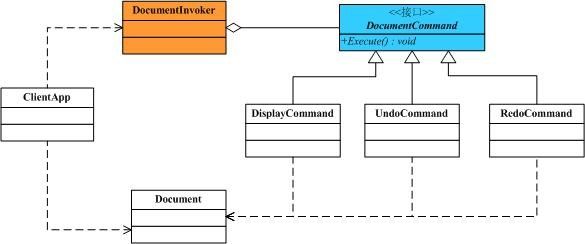
////// Invoker角色 /// public class DocumentInvoker { DocumentCommand _discmd; DocumentCommand _undcmd; DocumentCommand _redcmd; public DocumentInvoker(DocumentCommand discmd, DocumentCommand undcmd, DocumentCommand redcmd) { this._discmd = discmd; this._undcmd = undcmd; this._redcmd = redcmd; } public void Display() { _discmd.Execute(); } public void Undo() { _undcmd.Execute(); } public void Redo() { _redcmd.Execute(); } }
现在再来看客户程序的调用代码:
class Program { static void Main(string[] args) { Document doc = new Document(); DocumentCommand discmd = new DisplayCommand(doc); DocumentCommand undcmd = new UndoCommand(doc); DocumentCommand redcmd = new RedoCommand(doc); DocumentInvoker invoker = new DocumentInvoker(discmd,undcmd,redcmd); invoker.Display(); invoker.Undo(); invoker.Redo(); } }
可以看到在客户程序中,不再依赖于Document的Display(),Undo(),Redo()命令,通过Command对这些命令进行了封装,使用它的一个关键就是抽象的Command类,它定义了一个操作的接口。同时我们也可以看到,本来这三个命令仅仅是三个方法而已,但是通过Command模式却把它们提到了类的层面,这其实是违背了面向对象的原则,但它却优雅的解决了分离命令的请求者和命令的执行者的问题,在使用Command模式的时候,一定要判断好使用它的时机。
Command实现要点:
1.Command模式的根本目的在于将“行为请求者”与“行为实现者”解耦,在面向对象语言中,常见的实现手段是“将行为抽象为对象”。
2.实现Command接口的具体命令对象ConcreteCommand有时候根据需要可能会保存一些额外的状态信息。
3.通过使用Compmosite模式,可以将多个命令封装为一个“复合命令”MacroCommand。
4.Command模式与C#中的Delegate有些类似。但两者定义行为接口的规范有所区别:Command以面向对象中的“接口-实现”来定义行为接口规范,更严格,更符合抽象原则;Delegate以函数签名来定义行为接口规范,更灵活,但抽象能力比较弱。
5.使用命令模式会导致某些系统有过多的具体命令类。某些系统可能需要几十个,几百个甚至几千个具体命令类,这会使命令模式在这样的系统里变得不实际。
Command的优缺点:
命令允许请求的一方和接收请求的一方能够独立演化,从而且有以下的优点:
1.命令模式使新的命令很容易地被加入到系统里。
2.允许接收请求的一方决定是否要否决(Veto)请求。
3.能较容易地设计-个命令队列。
4.可以容易地实现对请求的Undo和Redo。
5.在需要的情况下,可以较容易地将命令记入日志。
6.命令模式把请求一个操作的对象与知道怎么执行一个操作的对象分割开。
7.命令类与其他任何别的类一样,可以修改和推广。
8.你可以把命令对象聚合在一起,合成为合成命令。比如宏命令便是合成命令的例子。合成命令是合成模式的应用。
9.由于加进新的具体命令类不影响其他的类,因此增加新的具体命令类很容易。
命令模式的缺点如下:
1.使用命令模式会导致某些系统有过多的具体命令类。某些系统可能需要几十个,几百个甚至几千个具体命令类,这会使命令模式在这样的系统里变得不实际。
class Program { static void Main(string[] args) { Document doc = new Document(); doc.Display(); doc.Undo(); doc.Redo(); } }
4、模板方法(Template Method)
无处不在的Template Method
如果你只想掌握一种设计模式,那么它就是Template Method!
动机(Motivate):
变化 -----是软件设计的永恒主题,如何管理变化带来的复杂性?设计模式的艺术性和复杂度就在于如何
分析,并发现系统中的变化和稳定点,并使用特定的设计方法来应对这种变化。
意图(Intent):
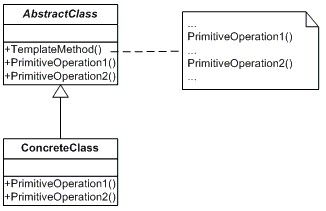
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 --摘自《设计模式》
结构图(Struct):
适用性:
1.一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。
2.各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。这是Opdyke和Johnson所描述过的“重分解以一般化”的一个很好的例子。首先识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
3.控制子类扩展。模板方法只在特定点调用“Hook”操作,这样就只允许在这些点进行扩展。
生活中的例子:
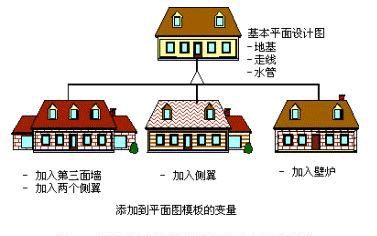
代码实现:
假如我们需要简单的读取Northwind数据库中的表的记录并显示出来。对于数据库操作,我们知道不管读取的是哪张表,它一般都应该经过如下这样的几步:
1.连接数据库(Connect)
2.执行查询命令(Select)
3.显示数据(Display)
4.断开数据库连接(Disconnect)
这些步骤是固定的,但是对于每一张具体的数据表所执行的查询却是不一样的。显然这需要一个抽象角色,给出顶级行为的实现。如下图:
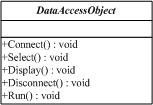
Template Method模式的实现方法是从上到下,我们首先给出顶级框架DataAccessObject的实现逻辑:
public abstract class DataAccessObject { protected string connectionString; protected DataSet dataSet; protected virtual void Connect() { connectionString = "Server=.;User Id=sa;Password=;Database=Northwind"; } protected abstract void Select(); protected abstract void Display(); protected virtual void Disconnect() { connectionString = ""; } // The "Template Method" public void Run() { Connect(); Select(); Display(); Disconnect(); } }
显然在这个顶级的框架DataAccessObject中给出了固定的轮廓,方法Run()便是模版方法,Template Method模式也由此而得名。而对于Select()和Display()这两个抽象方法则留给具体的子类去实现,如下图:

class Categories : DataAccessObject { protected override void Select() { string sql = "select CategoryName from Categories"; SqlDataAdapter dataAdapter = new SqlDataAdapter( sql, connectionString); dataSet = new DataSet(); dataAdapter.Fill(dataSet, "Categories"); } protected override void Display() { Console.WriteLine("Categories ---- "); DataTable dataTable = dataSet.Tables["Categories"]; foreach (DataRow row in dataTable.Rows) { Console.WriteLine(row["CategoryName"].ToString()); } Console.WriteLine(); } } class Products : DataAccessObject { protected override void Select() { string sql = "select top 10 ProductName from Products"; SqlDataAdapter dataAdapter = new SqlDataAdapter( sql, connectionString); dataSet = new DataSet(); dataAdapter.Fill(dataSet, "Products"); } protected override void Display() { Console.WriteLine("Products ---- "); DataTable dataTable = dataSet.Tables["Products"]; foreach (DataRow row in dataTable.Rows) { Console.WriteLine(row["ProductName"].ToString()); } Console.WriteLine(); } }
再来看看客户端程序的调用,不需要再去调用每一个步骤的方法:
public class App { static void Main() { DataAccessObject dao; dao = new Categories(); dao.Run(); dao = new Products(); dao.Run(); // Wait for user Console.Read(); } }
在上面的例子中,需要注意的是:
1.对于Connect()和Disconnect()方法实现为了virtual,而Select()和Display()方法则为abstract,这是因为如果这个方法有默认的实现,则实现为virtual,否则为abstract。
2.Run()方法作为一个模版方法,它的一个重要特征是:在基类里定义,而且不能够被派生类更改。有时候它是私有方法(private method),但实际上它经常被声明为protected。它通过调用其它的基类方法(覆写过的)来工作,但它经常是作为初始化过程的一部分被调用的,这样就没必要让客户端程序员能够直接调用它了。
3.在一开始我们提到了不管读的是哪张数据表,它们都有共同的操作步骤,即共同点。因此可以说Template Method模式的一个特征就是剥离共同点。
Template Mehtod实现要点:
1.Template Method模式是一种非常基础性的设计模式,在面向对象系统中有着大量的应用。它用最简洁的机制(虚函数的多态性)为很多应用程序框架提供了灵活的扩展点,是代码复用方面的基本实现结构。
2.除了可以灵活应对子步骤的变化外,“不用调用我,让我来调用你(Don't call me ,let me call you)”的反向控制结构是Template Method的典型应用。“Don’t call me.Let me call you”是指一个父类调用一个子类的操作,而不是相反。
3.在具体实现方面,被Template Method调用的虚方法可以具有实现,也可以没有任何实现(抽象方法,纯虚方法),但一般推荐将它们设置为protected方法。
5、桥接模式(Bridge Pattern)
动机(Motivate):
在软件系统中,某些类型由于自身的逻辑,它具有两个或多个维度的变化,那么如何应对这种“多维度的变化”?如何利用面向对象的技术来使得该类型能够轻松的沿着多个方向进行变化,而又不引入额外的复杂度?
意图(Intent):
将抽象部分与实现部分分离,使它们都可以独立的变化。
--摘自《设计模式》
结构图(Struct):
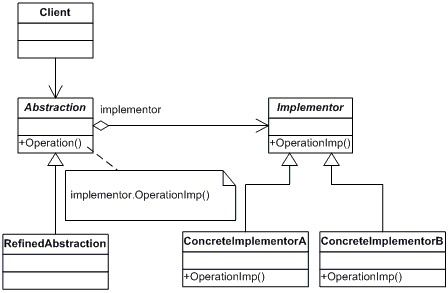
生活中的例子:
我想大家小时候都有用蜡笔画画的经历吧。红红绿绿的蜡笔一大盒,根据想象描绘出格式图样。而毛笔下的国画更是工笔写意,各展风采。而今天我们的故事从蜡笔与毛笔说起。
设想要绘制一幅图画,蓝天、白云、绿树、小鸟,如果画面尺寸很大,那么用蜡笔绘制就会遇到点麻烦。毕竟细细的蜡笔要涂出一片蓝天,是有些麻烦。如果有可能,最好有套大号蜡笔,粗粗的蜡笔很快能涂抹完成。至于色彩吗,最好每种颜色来支粗的,除了蓝天还有绿地呢。这样,如果一套12种颜色的蜡笔,我们需要两套 24支,同种颜色的一粗一细。呵呵,画还没画,开始做梦了:要是再有一套中号蜡笔就更好了,这样,不多不少总共36支蜡笔。

再看看毛笔这一边,居然如此简陋:一套水彩12色,外加大中小三支毛笔。你可别小瞧这"简陋"的组合,画蓝天用大毛笔,画小鸟用小毛笔,各具特色。
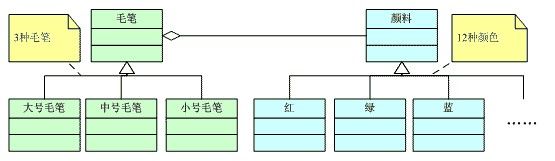
呵呵,您是不是已经看出来了,不错,我今天要说的就是Bridge模式。为了一幅画,我们需要准备36支型号不同的蜡笔,而改用毛笔三支就够了,当然还要搭配上12种颜料。通过Bridge模式,我们把乘法运算3×12=36改为了加法运算3+12=15,这一改进可不小。那么我们这里蜡笔和毛笔到底有什么区别呢?
实际上,蜡笔和毛笔的关键一个区别就在于笔和颜色是否能够分离。【GOF95】桥梁模式的用意是"将抽象化 (Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化"。关键就在于能否脱耦。蜡笔的颜色和蜡笔本身是分不开的,所以就造成必须使用36支色彩、大小各异的蜡笔来绘制图画。而毛笔与颜料能够很好的脱耦,各自独立变化,便简化了操作。在这里,抽象层面的概念是: "毛笔用颜料作画",而在实现时,毛笔有大中小三号,颜料有红绿蓝等12种,于是便可出现3×12种组合。每个参与者(毛笔与颜料)都可以在自己的自由度上随意转换。
蜡笔由于无法将笔与颜色分离,造成笔与颜色两个自由度无法单独变化,使得只有创建36种对象才能完成任务。Bridge模式将继承关系转换为组合关系,从而降低了系统间的耦合,减少了代码编写量。
代码实现:
abstract class Brush { protected Color c; public abstract void Paint(); public void SetColor(Color c) { this.c = c; } } class BigBrush : Brush { public override void Paint() { Console.WriteLine("Using big brush and color {0} painting", c.color); } } class SmallBrush : Brush { public override void Paint() { Console.WriteLine("Using small brush and color {0} painting", c.color); } } class Color { public string color; } class Red : Color { public Red() { this.color = "red"; } } class Green : Color { public Green() { this.color = "green"; } } class Blue : Color { public Blue() { this.color = "blue"; } } class Program { public static void Main() { Brush b = new BigBrush(); b.SetColor(new Red()); b.Paint(); b.SetColor(new Blue()); b.Paint(); b.SetColor(new Green()); b.Paint(); b = new SmallBrush(); b.SetColor(new Red()); b.Paint(); b.SetColor(new Blue()); b.Paint(); b.SetColor(new Green()); b.Paint(); } }
适用性:
1.如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的联系。
2.设计要求实现化角色的任何改变不应当影响客户端,或者说实现化角色的改变对客户端是完全透明的。
3 .一个构件有多于一个的抽象化角色和实现化角色,系统需要它们之间进行动态耦合。
4 .虽然在系统中使用继承是没有问题的,但是由于抽象化角色和具体化角色需要独立变化,设计要求需要独立管理这两者。
Bridge要点:
1.Bridge模式使用“对象间的组合关系”解耦了抽象和实现之间固有的绑定关系,使得抽象和实现可以沿着各自的维度来变化。
2.所谓抽象和实现沿着各自维度的变化,即“子类化”它们,得到各个子类之后,便可以任意它们,从而获得不同平台上的不同型号。
3.Bridge模式有时候类似于多继承方案,但是多继承方案往往违背了类的单一职责原则(即一个类只有一个变化的原因),复用性比较差。Bridge模式是比多继承方案更好的解决方法。
4.Bridge模式的应用一般在“两个非常强的变化维度”,有时候即使有两个变化的维度,但是某个方向的变化维度并不剧烈——换言之两个变化不会导致纵横交错的结果,并不一定要使用Bridge模式。
6、适配器模式(Adapter Pattern)
适配(转换)的概念无处不在......
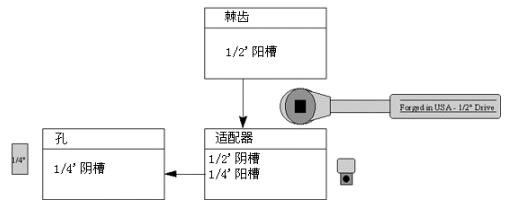
适配,即在不改变原有实现的基础上,将原先不兼容的接口转换为兼容的接口。
例如:二转换为三箱插头,将高电压转换为低电压等。

动机(Motivate):
在软件系统中,由于应用环境的变化,常常需要将“一些现存的对象”放在新的环境中应用,但是新环境要求的接口是这些现存对象所不满足的。
那么如何应对这种“迁移的变化”?如何既能利用现有对象的良好实现,同时又能满足新的应用环境所要求的接口?这就是本文要说的Adapter 模式。
意图(Intent):
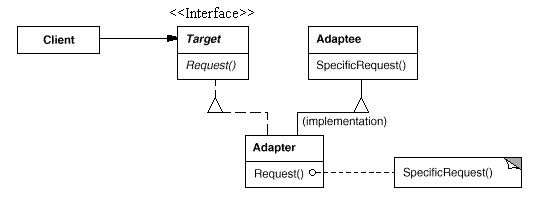
将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
--摘自《设计模式》
结构(Struct):

生活中的例子:
适用性:
1.系统需要使用现有的类,而此类的接口不符合系统的需要。
2.想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。这些源类不一定有很复杂的接口。
3.(对对象适配器而言)在设计里,需要改变多个已有子类的接口,如果使用类的适配器模式,就要针对每一个子类做一个适配器,而这不太实际。
示意性代码实例:
interface IStack { void Push(object item); void Pop(); object Peek(); } //对象适配器(Adapter与Adaptee组合的关系) public class Adapter : IStack //适配对象 { ArrayList adaptee;//被适配的对象 public Adapter() { adaptee = new ArrayList(); } public void Push(object item) { adaptee.Add(item); } public void Pop() { adaptee.RemoveAt(adaptee.Count - 1); } public object Peek() { return adaptee[adaptee.Count - 1]; } } //类适配器 public class Adapter : ArrayList, IStack { public void Push(object item) { this.Add(item); } public void Pop() { this.RemoveAt(this.Count - 1); } public object Peek() { return this[this.Count - 1]; } }
Adapter模式的几个要点:
Adapter模式主要应用于“希望复用一些现存的类,但是接口又与复用环境要求不一致的情况”,在遗留代码复用、类库迁移等方面非常有用。
定义了两种Adapter模式的实现结构:对象适配器和类适配器。但类适配器采用“多继承”的实现方式,带来不良的高耦合,所以一般不推荐使用。对象适配器采用“对象组合”的方式,更符合松耦合精神。
Adapter模式可以实现的非常灵活,不必拘泥于GOF23中定义的两种结构。例如,完全可以将Adapter模式中的“现存对象“作为新的接口方法参数,来达到适配的目的。
Adapter模式本身要求我们尽可能地使用”面向接口的编程"风格,这样才能在后期很方便的适配。
.NET框架中的Adapter应用:
(1)在.Net中复用com对象:
Com 对象不符合.net对象的接口
使用tlbimp.exe来创建一个Runtime Callable Wrapper(RCW)以使其符合.net对象的接口。
(2).NET数据访问类(Adapter变体):
各种数据库并没有提供DataSet接口
使用DBDataAdapter可以将任何各数据库访问/存取适配到一个DataSet对象上。
(3)集合类中对现有对象的排序(Adapter变体);
现有对象未实现IComparable接口
实现一个排序适配器(继承IComparer接口),然后在其Compare方法中对两个对象进行比较。
7、外观模式(Facade Pattern)
动机(Motivate):
在软件开发系统中,客户程序经常会与复杂系统的内部子系统之间产生耦合,而导致客户程序随着子系统的变化而变化。那么如何简化客户程序与子系统之间的交互接口?如何将复杂系统的内部子系统与客户程序之间的依赖解耦?
意图(Intent):
为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
--摘自《设计模式》
结构图(Struct):

适用性:
1.为一个复杂子系统提供一个简单接口。
2.提高子系统的独立性。
3.在层次化结构中,可以使用Facade模式定义系统中每一层的入口。
生活中的例子:
代码实现:
我们平时的开发中其实已经不知不觉的在用Façade模式,现在来考虑这样一个抵押系统,当有一个客户来时,有如下几件事情需要确认:到银行子系统查询他是否有足够多的存款,到信用子系统查询他是否有良好的信用,到贷款子系统查询他有无贷款劣迹。只有这三个子系统都通过时才可进行抵押。我们先不考虑Façade模式,那么客户程序就要直接访问这些子系统,分别进行判断。类结构图下:

在这个程序中,我们首先要有一个顾客类,它是一个纯数据类,并无任何操作,示意代码:
//顾客类 public class Customer { private string _name; public Customer(string name) { this._name = name; } public string Name { get { return _name; } } }
下面这三个类均是子系统类,示意代码:
//银行子系统 public class Bank { public bool HasSufficientSavings(Customer c, int amount) { Console.WriteLine("Check bank for " + c.Name); return true; } } //信用子系统 public class Credit { public bool HasGoodCredit(Customer c) { Console.WriteLine("Check credit for " + c.Name); return true; } } //贷款子系统 public class Loan { public bool HasNoBadLoans(Customer c) { Console.WriteLine("Check loans for " + c.Name); return true; } }
看客户程序的调用:
//客户程序 public class MainApp { private const int _amount = 12000; public static void Main() { Bank bank = new Bank(); Loan loan = new Loan(); Credit credit = new Credit(); Customer customer = new Customer("Ann McKinsey"); bool eligible = true; if (!bank.HasSufficientSavings(customer, _amount)) { eligible = false; } else if (!loan.HasNoBadLoans(customer)) { eligible = false; } else if (!credit.HasGoodCredit(customer)) { eligible = false; } Console.WriteLine("\n" + customer.Name + " has been " + (eligible ? "Approved" : "Rejected")); Console.ReadLine(); } }
可以看到,在不用Façade模式的情况下,客户程序与三个子系统都发生了耦合,这种耦合使得客户程序依赖于子系统,当子系统化时,客户程序也将面临很多变化的挑战。一个合情合理的设计就是为这些子系统创建一个统一的接口,这个接口简化了客户程序的判断操作。看一下引入Façade模式后的类结构图:

外观类Mortage的实现如下:
//外观类 public class Mortgage { private Bank bank = new Bank(); private Loan loan = new Loan(); private Credit credit = new Credit(); public bool IsEligible(Customer cust, int amount) { Console.WriteLine("{0} applies for {1:C} loan\n", cust.Name, amount); bool eligible = true; if (!bank.HasSufficientSavings(cust, amount)) { eligible = false; } else if (!loan.HasNoBadLoans(cust)) { eligible = false; } else if (!credit.HasGoodCredit(cust)) { eligible = false; } return eligible; } }
顾客类和子系统类的实现仍然如下:
//银行子系统 public class Bank { public bool HasSufficientSavings(Customer c, int amount) { Console.WriteLine("Check bank for " + c.Name); return true; } } //信用证子系统 public class Credit { public bool HasGoodCredit(Customer c) { Console.WriteLine("Check credit for " + c.Name); return true; } } //贷款子系统 public class Loan { public bool HasNoBadLoans(Customer c) { Console.WriteLine("Check loans for " + c.Name); return true; } } //顾客类 public class Customer { private string name; public Customer(string name) { this.name = name; } public string Name { get { return name; } } }
而此时客户程序的实现:
//客户程序类 public class MainApp { public static void Main() { //外观 Mortgage mortgage = new Mortgage(); Customer customer = new Customer("Ann McKinsey"); bool eligable = mortgage.IsEligible(customer, 125000); Console.WriteLine("\n" + customer.Name + " has been " + (eligable ? "Approved" : "Rejected")); Console.ReadLine(); } }
可以看到引入Façade模式后,客户程序只与Mortgage发生依赖,也就是Mortgage屏蔽了子系统之间的复杂的操作,达到了解耦内部子系统与客户程序之间的依赖。
.NET架构中的Façade模式
Façade模式在实际开发中最多的运用当属开发N层架构的应用程序了,一个典型的N层结构如下:

在这个架构中,总共分为四个逻辑层,分别为:用户层UI,业务外观层Business Façade,业务规则层Business Rule,数据访问层Data Access。其中Business Façade层的职责如下:
l 从“用户”层接收用户输入
l 如果请求需要对数据进行只读访问,则可能使用“数据访问”层
l 将请求传递到“业务规则”层
l 将响应从“业务规则”层返回到“用户”层
l 在对“业务规则”层的调用之间维护临时状态
对这一架构最好的体现就是Duwamish示例了。在该应用程序中,有部分操作只是简单的从数据库根据条件提取数据,不需要经过任何处理,而直接将数据显示到网页上,比如查询某类别的图书列表。而另外一些操作,比如计算定单中图书的总价并根据顾客的级别计算回扣等等,这部分往往有许多不同的功能的类,操作起来也比较复杂。如果采用传统的三层结构,这些商业逻辑一般是会放在中间层,那么对内部的这些大量种类繁多,使用方法也各异的不同的类的调用任务,就完全落到了表示层。这样势必会增加表示层的代码量,将表示层的任务复杂化,和表示层只负责接受用户的输入并返回结果的任务不太相称,并增加了层与层之间的耦合程度。于是就引入了一个Façade层,让这个Facade来负责管理系统内部类的调用,并为表示层提供了一个单一而简单的接口。看一下Duwamish结构图:

从图中可以看到,UI层将请求发送给业务外观层,业务外观层对请求进行初步的处理,判断是否需要调用业务规则层,还是直接调用数据访问层获取数据。最后由数据访问层访问数据库并按照来时的步骤返回结果到UI层,来看具体的代码实现。
在获取商品目录的时候,Web UI调用业务外观层:
productSystem = new ProductSystem(); categorySet = productSystem.GetCategories(categoryID);
业务外观层直接调用了数据访问层:
public CategoryData GetCategories(int categoryId) { // // Check preconditions // ApplicationAssert.CheckCondition(categoryId >= 0,"Invalid Category Id",ApplicationAssert.LineNumber); // // Retrieve the data // using (Categories accessCategories = new Categories()) { return accessCategories.GetCategories(categoryId); } }
在添加订单时,UI调用业务外观层:
public void AddOrder() { ApplicationAssert.CheckCondition(cartOrderData != null, "Order requires data", ApplicationAssert.LineNumber); //Write trace log. ApplicationLog.WriteTrace("Duwamish7.Web.Cart.AddOrder:\r\nCustomerId: " + cartOrderData.Tables[OrderData.CUSTOMER_TABLE].Rows[0][OrderData.PKID_FIELD].ToString()); cartOrderData = (new OrderSystem()).AddOrder(cartOrderData); }
业务外观层调用业务规则层:
public OrderData AddOrder(OrderData order) { // // Check preconditions // ApplicationAssert.CheckCondition(order != null, "Order is required", ApplicationAssert.LineNumber); (new BusinessRules.Order()).InsertOrder(order); return order; }
业务规则层进行复杂的逻辑处理后,再调用数据访问层:
public OrderData AddOrder(OrderData order) { // // Check preconditions // ApplicationAssert.CheckCondition(order != null, "Order is required", ApplicationAssert.LineNumber); (new BusinessRules.Order()).InsertOrder(order); return order; }
业务规则层进行复杂的逻辑处理后,再调用数据访问层:
public bool InsertOrder(OrderData order) { // // Assume it's good // bool isValid = true; // // Validate order summary // DataRow summaryRow = order.Tables[OrderData.ORDER_SUMMARY_TABLE].Rows[0]; summaryRow.ClearErrors(); if (CalculateShipping(order) != (Decimal)(summaryRow[OrderData.SHIPPING_HANDLING_FIELD])) { summaryRow.SetColumnError(OrderData.SHIPPING_HANDLING_FIELD, OrderData.INVALID_FIELD); isValid = false; } if (CalculateTax(order) != (Decimal)(summaryRow[OrderData.TAX_FIELD])) { summaryRow.SetColumnError(OrderData.TAX_FIELD, OrderData.INVALID_FIELD); isValid = false; } // // Validate shipping info // isValid &= IsValidField(order, OrderData.SHIPPING_ADDRESS_TABLE, OrderData.SHIP_TO_NAME_FIELD, 40); // // Validate payment info // DataRow paymentRow = order.Tables[OrderData.PAYMENT_TABLE].Rows[0]; paymentRow.ClearErrors(); isValid &= IsValidField(paymentRow, OrderData.CREDIT_CARD_TYPE_FIELD, 40); isValid &= IsValidField(paymentRow, OrderData.CREDIT_CARD_NUMBER_FIELD, 32); isValid &= IsValidField(paymentRow, OrderData.EXPIRATION_DATE_FIELD, 30); isValid &= IsValidField(paymentRow, OrderData.NAME_ON_CARD_FIELD, 40); isValid &= IsValidField(paymentRow, OrderData.BILLING_ADDRESS_FIELD, 255); // // Validate the order items and recalculate the subtotal // DataRowCollection itemRows = order.Tables[OrderData.ORDER_ITEMS_TABLE].Rows; Decimal subTotal = 0; foreach (DataRow itemRow in itemRows) { itemRow.ClearErrors(); subTotal += (Decimal)(itemRow[OrderData.EXTENDED_FIELD]); if ((Decimal)(itemRow[OrderData.PRICE_FIELD]) <= 0) { itemRow.SetColumnError(OrderData.PRICE_FIELD, OrderData.INVALID_FIELD); isValid = false; } if ((short)(itemRow[OrderData.QUANTITY_FIELD]) <= 0) { itemRow.SetColumnError(OrderData.QUANTITY_FIELD, OrderData.INVALID_FIELD); isValid = false; } } // // Verify the subtotal // if (subTotal != (Decimal)(summaryRow[OrderData.SUB_TOTAL_FIELD])) { summaryRow.SetColumnError(OrderData.SUB_TOTAL_FIELD, OrderData.INVALID_FIELD); isValid = false; } if ( isValid ) { using (DataAccess.Orders ordersDataAccess = new DataAccess.Orders()) { return (ordersDataAccess.InsertOrderDetail(order)) > 0; } } else return false; }
Facade模式的个要点:
从客户程序的角度来看,Facade模式不仅简化了整个组件系统的接口,同时对于组件内部与外部客户程序来说,从某种程度上也达到了一种“解耦”的效果----内部子系统的任何变化不会影响到Facade接口的变化。Facade设计模式更注重从架构的层次去看整个系统,而不是单个类的层次。Facdae很多时候更是一种架构设计模式。
注意区分Facade模式、Adapter模式、Bridge模式与Decorator模式。Facade模式注重简化接口,Adapter模式注重转换接口,Bridge模式注重分离接口(抽象)与其实现,Decorator模式注重稳定接口的前提下为对象扩展功能。
8、亨元模式(Flyweight Pattern)
面向对象的代价
面向对象很好地解决了系统抽象性的问题,同时在大多数情况下,也不会损及系统的性能。但是,在
某些特殊的应用中下,由于对象的数量太大,采用面向对象会给系统带来难以承受的内存开销。比如:
图形应用中的图元等对象、字处理应用中的字符对象等。
动机(Motivate):
采用纯粹对象方案的问题在于大量细粒度的对象会很快充斥在系统中,从而带来很高的运行时代价--------主要指内存需求方面的代价。
如何在避免大量细粒度对象问题的同时,让外部客户程序仍然能够透明地使用面向对象的方式来进行操作?
意图(Intent):
运用共享技术有效地支持大量细粒度的对象。 --摘自《设计模式》
结构(Struct):

适用性:
当以下所有的条件都满足时,可以考虑使用享元模式:
1、 一个系统有大量的对象。
2、 这些对象耗费大量的内存。
3、 这些对象的状态中的大部分都可以外部化。
4、 这些对象可以按照内蕴状态分成很多的组,当把外蕴对象从对象中剔除时,每一个组都可以仅用一个对象代替。
5、 软件系统不依赖于这些对象的身份,换言之,这些对象可以是不可分辨的。
满足以上的这些条件的系统可以使用享元对象。最后,使用享元模式需要维护一个记录了系统已有的所有享元的表,而这需要耗费资源。因此,应当在有足够多的享元实例可供共享时才值得使用享元模式。
生活中的例子:
享元模式使用共享技术有效地支持大量细粒度的对象。公共交换电话网(PSTN)是享元的一个例子。有一些资源例如拨号音发生器、振铃发生器和拨号接收器是必须由所有用户共享的。当一个用户拿起听筒打电话时,他不需要知道使用了多少资源。对于用户而言所有的事情就是有拨号音,拨打号码,拨通电话。

代码实现:
Flyweight在拳击比赛中指最轻量级,即“蝇量级”,这里翻译为“享元”,可以理解为共享元对象(细粒度对象)的意思。提到Flyweight模式都会一般都会用编辑器例子来说明,这里也不例外,但我会尝试着通过重构来看待Flyweight模式。考虑这样一个字处理软件,它需要处理的对象可能有单个的字符,由字符组成的段落以及整篇文档,根据面向对象的设计思想和Composite模式,不管是字符还是段落,文档都应该作为单个的对象去看待,这里只考虑单个的字符,不考虑段落及文档等对象,于是可以很容易的得到下面的结构图:
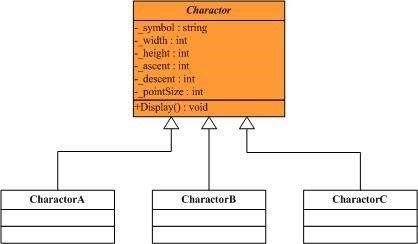
//"Charactor" public abstract class Charactor { //Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; protected int _pointSize; //Method public abstract void Display(); } // "CharactorA" public class CharactorA : Charactor { // Constructor public CharactorA() { this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; this._pointSize = 12; } //Method public override void Display() { Console.WriteLine(this._symbol); } } // "CharactorB" public class CharactorB : Charactor { // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; this._pointSize = 10; } //Method public override void Display() { Console.WriteLine(this._symbol); } } // "CharactorC" public class CharactorC : Charactor { // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; this._pointSize = 14; } //Method public override void Display() { Console.WriteLine(this._symbol); } }
好了,现在看到的这段代码可以说是很好地符合了面向对象的思想,但是同时我们也为此付出了沉重的代价,那就是性能上的开销,可以想象,在一篇文档中,字符的数量远不止几百个这么简单,可能上千上万,内存中就同时存在了上千上万个Charactor对象,这样的内存开销是可想而知的。进一步分析可以发现,虽然我们需要的Charactor实例非常多,这些实例之间只不过是状态不同而已,也就是说这些实例的状态数量是很少的。所以我们并不需要这么多的独立的Charactor实例,而只需要为每一种Charactor状态创建一个实例,让整个字符处理软件共享这些实例就可以了。看这样一幅示意图:
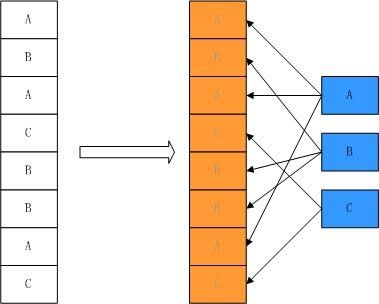
现在我们看到的A,B,C三个字符是共享的,也就是说如果文档中任何地方需要这三个字符,只需要使用共享的这三个实例就可以了。然而我们发现单纯的这样共享也是有问题的。虽然文档中的用到了很多的A字符,虽然字符的symbol等是相同的,它可以共享;但是它们的pointSize却是不相同的,即字符在文档中中的大小是不相同的,这个状态不可以共享。为解决这个问题,首先我们将不可共享的状态从类里面剔除出去,即去掉pointSize这个状态(只是暂时的J),类结构图如下所示:
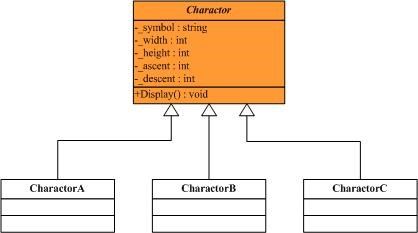
//"Charactor" public abstract class Charactor { //Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; //Method public abstract void Display(); } // "CharactorA" public class CharactorA : Charactor { // Constructor public CharactorA() { this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); } } // "CharactorB" public class CharactorB : Charactor { // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); } } // "CharactorC" public class CharactorC : Charactor { // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); } }
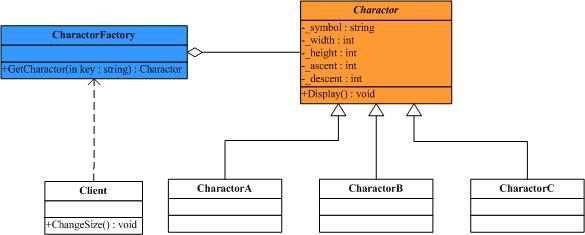
好,现在类里面剩下的状态都可以共享了,下面我们要做的工作就是控制Charactor类的创建过程,即如果已经存在了“A”字符这样的实例,就不需要再创建,直接返回实例;如果没有,则创建一个新的实例。如果把这项工作交给Charactor类,即Charactor类在负责它自身职责的同时也要负责管理Charactor实例的管理工作,这在一定程度上有可能违背类的单一职责原则,因此,需要一个单独的类来做这项工作,引入CharactorFactory类,结构图如下:

//"CharactorFactory" public class CharactorFactory { // Fields private Hashtable charactors = new Hashtable(); // Constructor public CharactorFactory() { charactors.Add("A", new CharactorA()); charactors.Add("B", new CharactorB()); charactors.Add("C", new CharactorC()); } // Method public Charactor GetCharactor(string key) { Charactor charactor = charactors[key] as Charactor; if (charactor == null) { switch (key) { case "A": charactor = new CharactorA(); break; case "B": charactor = new CharactorB(); break; case "C": charactor = new CharactorC(); break; // } charactors.Add(key, charactor); } return charactor; } }
到这里已经完全解决了可以共享的状态(这里很丑陋的一个地方是出现了switch语句,但这可以通过别的办法消除,为了简单期间我们先保持这种写法)。下面的工作就是处理刚才被我们剔除出去的那些不可共享的状态,因为虽然将那些状态移除了,但是Charactor对象仍然需要这些状态,被我们剥离后这些对象根本就无法工作,所以需要将这些状态外部化。首先会想到一种比较简单的解决方案就是对于不能共享的那些状态,不需要去在Charactor类中设置,而直接在客户程序代码中进行设置,类结构图如下:
public class Program { public static void Main() { Charactor ca = new CharactorA(); Charactor cb = new CharactorB(); Charactor cc = new CharactorC(); //显示字符 //设置字符的大小ChangeSize(); } public void ChangeSize() { //在这里设置字符的大小 } }
按照这样的实现思路,可以发现如果有多个客户端程序使用的话,会出现大量的重复性的逻辑,用重构的术语来说是出现了代码的坏味道,不利于代码的复用和维护;另外把这些状态和行为移到客户程序里面破坏了封装性的原则。再次转变我们的实现思路,可以确定的是这些状态仍然属于Charactor对象,所以它还是应该出现在Charactor类中,对于不同的状态可以采取在客户程序中通过参数化的方式传入。类结构图如下:

// "Charactor" public abstract class Charactor { //Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; protected int _pointSize; //Method public abstract void SetPointSize(int size); public abstract void Display(); } // "CharactorA" public class CharactorA : Charactor { // Constructor public CharactorA() { this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; } //Method public override void SetPointSize(int size) { this._pointSize = size; } public override void Display() { Console.WriteLine(this._symbol + "pointsize:" + this._pointSize); } } // "CharactorB" public class CharactorB : Charactor { // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; } //Method public override void SetPointSize(int size) { this._pointSize = size; } public override void Display() { Console.WriteLine(this._symbol + "pointsize:" + this._pointSize); } } // "CharactorC" public class CharactorC : Charactor { // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; } //Method public override void SetPointSize(int size) { this._pointSize = size; } public override void Display() { Console.WriteLine(this._symbol + "pointsize:" + this._pointSize); } } // "CharactorFactory" public class CharactorFactory { // Fields private Hashtable charactors = new Hashtable(); // Constructor public CharactorFactory() { charactors.Add("A", new CharactorA()); charactors.Add("B", new CharactorB()); charactors.Add("C", new CharactorC()); } // Method public Charactor GetCharactor(string key) { Charactor charactor = charactors[key] as Charactor; if (charactor == null) { switch (key) { case "A": charactor = new CharactorA(); break; case "B": charactor = new CharactorB(); break; case "C": charactor = new CharactorC(); break; // } charactors.Add(key, charactor); } return charactor; } } public class Program { public static void Main() { CharactorFactory factory = new CharactorFactory(); // Charactor "A" CharactorA ca = (CharactorA)factory.GetCharactor("A"); ca.SetPointSize(12); ca.Display(); // Charactor "B" CharactorB cb = (CharactorB)factory.GetCharactor("B"); ca.SetPointSize(10); ca.Display(); // Charactor "C" CharactorC cc = (CharactorC)factory.GetCharactor("C"); ca.SetPointSize(14); ca.Display(); } }
可以看到这样的实现明显优于第一种实现思路。好了,到这里我们就到到了通过Flyweight模式实现了优化资源的这样一个目的。在这个过程中,还有如下几点需要说明:
1.引入CharactorFactory是个关键,在这里创建对象已经不是new一个Charactor对象那么简单,而必须用工厂方法封装起来。
2.在这个例子中把Charactor对象作为Flyweight对象是否准确值的考虑,这里只是为了说明Flyweight模式,至于在实际应用中,哪些对象需要作为Flyweight对象是要经过很好的计算得知,而绝不是凭空臆想。
3.区分内外部状态很重要,这是享元对象能做到享元的关键所在。
到这里,其实我们的讨论还没有结束。有人可能会提出如下问题,享元对象(Charactor)在这个系统中相对于每一个内部状态而言它是唯一的,这跟单件模式有什么区别呢?这个问题已经很好回答了,那就是单件类是不能直接被实例化的,而享元类是可以被实例化的。事实上在这里面真正被设计为单件的应该是享元工厂(不是享元)类,因为如果创建很多个享元工厂的实例,那我们所做的一切努力都是白费的,并没有减少对象的个数。修改后的类结构图如下:
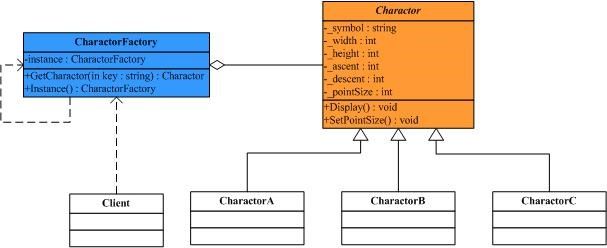
// "CharactorFactory" public class CharactorFactory { // Fields private Hashtable charactors = new Hashtable(); private CharactorFactory instance; // Constructor private CharactorFactory() { charactors.Add("A", new CharactorA()); charactors.Add("B", new CharactorB()); charactors.Add("C", new CharactorC()); } // Property public CharactorFactory Instance { get { if (instance != null) { instance = new CharactorFactory(); } return instance; } } // Method public Charactor GetCharactor(string key) { Charactor charactor = charactors[key] as Charactor; if (charactor == null) { switch (key) { case "A": charactor = new CharactorA(); break; case "B": charactor = new CharactorB(); break; case "C": charactor = new CharactorC(); break; // } charactors.Add(key, charactor); } return charactor; } }
.NET框架中的应用:
Flyweight更多时候的时候一种底层的设计模式,在我们的实际应用程序中使用的并不是很多。在.NET中的String类型其实就是运用了Flyweight模式。可以想象,如果每次执行string s1 = “abcd”操作,都创建一个新的字符串对象的话,内存的开销会很大。所以.NET中如果第一次创建了这样的一个字符串对象s1,下次再创建相同的字符串s2时只是把它的引用指向“abcd”,这样就实现了“abcd”在内存中的共享。可以通过下面一个简单的程序来演示s1和s2的引用是否一致:
public class Program { public static void Main(string[] args) { string s1 = "abcd"; string s2 = "abcd"; Console.WriteLine(Object.ReferenceEquals(s1,s2)); Console.ReadLine(); } }
Flyweight实现要点:
1.面向对象很好的解决了抽象性的问题,但是作为一个运行在机器中的程序实体,我们需要考虑对象的代价问题。Flyweight设计模式主要解决面向对象的代价问题,一般不触及面向对象的抽象性问题。
2.Flyweight采用对象共享的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。在具体实现方面,要注意对象状态的处理。
3.享元模式的优点在于它大幅度地降低内存中对象的数量。但是,它做到这一点所付出的代价也是很高的:享元模式使得系统更加复杂。为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化。另外它将享元对象的状态外部化,而读取外部状态使得运行时间稍微变长。
9、装饰模式(Decorator Pattern)
假如我们需要为游戏中开发一种坦克,除了各种不同型号的坦克外,我们还希望在不同场合中为其增加以下一种或多种功能;比如红外线夜视功能,比如水陆两栖功能,比如卫星定位功能等等。
按类继承的作法如下:
//抽象坦克 public abstract class Tank { public abstract void Shot(); public abstract void Run(); } //各种型号: //T50型号 public class T50 : Tank { public override void Shot() { Console.WriteLine("T50坦克平均每秒射击5发子弹"); } public override void Run() { Console.WriteLine("T50坦克平均每时运行30公里"); } } //T75型号 public class T75 : Tank { public override void Shot() { Console.WriteLine("T75坦克平均每秒射击10发子弹"); } public override void Run() { Console.WriteLine("T75坦克平均每时运行35公里"); } } //T90型号 public class T90 : Tank { public override void Shot() { Console.WriteLine("T90坦克平均每秒射击10发子弹"); } public override void Run() { Console.WriteLine("T90坦克平均每时运行40公里"); } }
各种不同功能的组合:比如IA具有红外功能接口、IB具有水陆两栖功能接口、IC具有卫星定位功能接口。
//T50坦克各种功能的组合 public class T50A : T50, IA { //具有红外功能 } public class T50B : T50, IB { //具有水陆两栖功能 } public class T50C : T50, IC { } public class T50AB : T50, IA, IB { } public class T50AC : T50, IA, IC { } public class T50BC : T50, IB, IC { } public class T50ABC : T50, IA, IB, IC { } //T75各种不同型号坦克各种功能的组合 public class T75A : T75, IA { //具有红外功能 } public class T75B : T75, IB { //具有水陆两栖功能 } public class T75C : T75, IC { //具有卫星定位功能 } public class T75AB : T75, IA, IB { //具有红外、水陆两栖功能 } public class T75AC : T75, IA, IC { //具有红外、卫星定位功能 } public class T75BC : T75, IB, IC { //具有水陆两栖、卫星定位功能 } public class T75ABC : T75, IA, IB, IC { //具有红外、水陆两栖、卫星定位功能 } //T90各种不同型号坦克各种功能的组合 public class T90A : T90, IA { //具有红外功能 } public class T90B : T90, IB { //具有水陆两栖功能 } public class T90C : T90, IC { //具有卫星定位功能 } public class T90AB : T90, IA, IB { //具有红外、水陆两栖功能 } public class T90AC : T90, IA, IC { //具有红外、卫星定位功能 } public class T90BC : T90, IB, IC { //具有水陆两栖、卫星定位功能 } public class T90ABC : T90, IA, IB, IC { //具有红外、水陆两栖、卫星定位功能 }
由此可见,如果用类继承实现,子类会爆炸式地增长。
动机(Motivate):
上述描述的问题根源在于我们“过度地使用了继承来扩展对象的功能”,由于继承为类型引入的静态物质,使得这种扩展方式缺乏灵活性;并且随着子类的增多(扩展功能的增多),各种子类的组合(扩展功能组合)会导致更多子类的膨胀(多继承)。
如何使“对象功能的扩展”能够根据需要来动态地实现?同时避免“扩展功能的增多”带来的子类膨胀问题?从而使得任何“功能扩展变化”所导致的影响将为最低?
意图(Intent):
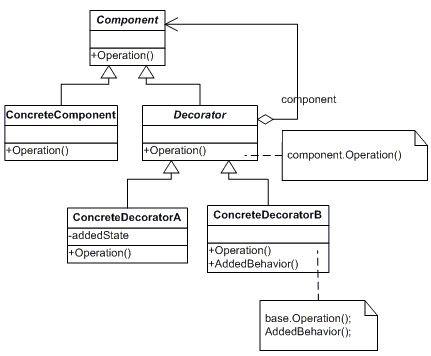
动态地给一个对象添加一些额外的职责。就增加功能来说,Decorator模式相比生成子类更为灵活。
--摘自《设计模式》
结构图(Struct):
生活中的例子:
适用性:
需要扩展一个类的功能,或给一个类增加附加责任。
需要动态地给一个对象增加功能,这些功能可以再动态地撤销。
需要增加由一些基本功能的排列组合而产生的非常大量的功能,从而使继承关系变得不现实。
实现代码:
namespace Decorator { public abstract class Tank { public abstract void Shot(); public abstract void Run(); } } namespace Decorator { public class T50 : Tank { public override void Shot() { Console.WriteLine("T50坦克平均每秒射击5发子弹"); } public override void Run() { Console.WriteLine("T50坦克平均每时运行30公里"); } } } namespace Decorator { public class T75 : Tank { public override void Shot() { Console.WriteLine("T75坦克平均每秒射击10发子弹"); } public override void Run() { Console.WriteLine("T75坦克平均每时运行35公里"); } } } namespace Decorator { public class T90 : Tank { public override void Shot() { Console.WriteLine("T90坦克平均每秒射击10发子弹"); } public override void Run() { Console.WriteLine("T90坦克平均每时运行40公里"); } } } namespace Decorator { public abstract class Decorator : Tank //Do As 接口继承 非实现继承 { private Tank tank; //Has a 对象组合 public Decorator(Tank tank) { this.tank = tank; } public override void Shot() { tank.Shot(); } public override void Run() { tank.Run(); } } } namespace Decorator { public class DecoratorA : Decorator { public DecoratorA(Tank tank) : base(tank) { } public override void Shot() { //Do some extension //功能扩展 且有红外功能 base.Shot(); } public override void Run() { base.Run(); } } } namespace Decorator { public class DecoratorB : Decorator { public DecoratorB(Tank tank) : base(tank) { } public override void Shot() { //Do some extension //功能扩展 且有水陆两栖功能 base.Shot(); } public override void Run() { base.Run(); } } } namespace Decorator { public class DecoratorC : Decorator { public DecoratorC(Tank tank) : base(tank) { } public override void Shot() { //Do some extension //功能扩展 且有卫星定位功能 base.Shot(); } public override void Run() { base.Run(); } } } class Program { static void Main(string[] args) { Tank tank = new T50(); DecoratorA da = new DecoratorA(tank); //且有红外功能 DecoratorB db = new DecoratorB(da); //且有红外和水陆两栖功能 DecoratorC dc = new DecoratorC(db); //且有红外、水陆两栖、卫星定们三种功能 dc.Shot(); dc.Run(); } }
Decorator模式的几个要点:
通过采用组合、而非继承的手法,Decorator模式实现了在运行时动态地扩展对象功能的能力,而且可以
根据需要扩展多个功能。避免了单独使用继承带来的“灵活性差"和"多子类衍生问题"。
Component类在Decorator模式中充当抽象接口的角色,不应该去实现具体的行为。而且Decorator类对于Component类应该透明---换言之Component类无需知道Decorator类,Decorator类是从外部来扩展Component类的功能。
Decorator类在接口上表现为is-a Component的继承关系,即Decorator类继承了Component类所且有的接口。但在实现上又表现has a Component的组合关系,即Decorator类又使用了另外一个Component类。我们可以使用一个或者多个Decorator对象来“装饰”一个Component对象,且装饰后的对象仍然是一个Component对象。
Decorator模式并非解决”多子类衍生的多继承“问题,Decorator模式应用的要点在于解决“主体
类在多个方向上的扩展功能”------是为“装饰”的含义。
Decorator在.NET(Stream)中的应用:
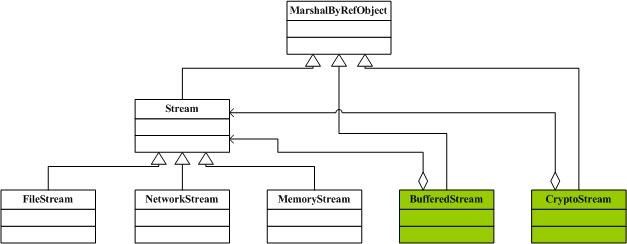
可以看到, BufferedStream和CryptoStream其实就是两个包装类,这里的Decorator模式省略了抽象装饰角色(Decorator),示例代码如下:
class Program { public static void Main(string[] args) { MemoryStream ms = new MemoryStream(new byte[] { 100, 456, 864, 222, 567 }); //扩展了缓冲的功能 BufferedStream buff = new BufferedStream(ms); //扩展了缓冲,加密的功能 CryptoStream crypto = new CryptoStream(buff); } }
通过反编译,可以看到BufferedStream类的代码(只列出部分),它是继承于Stream类:
public sealed class BufferedStream : Stream { // Methods private BufferedStream(); public BufferedStream(Stream stream); public BufferedStream(Stream stream, int bufferSize); // Fields private int _bufferSize; private Stream _s; }
10、组合模式(Composite Pattern)
动机(Motivate):
组合模式有时候又叫做部分-整体模式,它使我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以向处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
意图(Intent):
将对象组合成树形结构以表示“部分-整体”的层次结构。Composite模式使得用户对单个对象和组合对象的使用具有一致性。
--摘自《设计模式》
结构图(Struct):

生活中的例子:
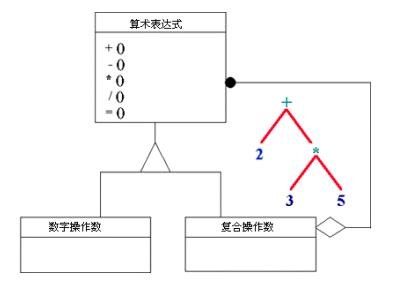
适用性:
1.你想表示对象的部分-整体层次结构
2.你希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
代码实现:
这里我们用绘图这个例子来说明Composite模式,通过一些基本图像元素(直线、圆等)以及一些复合图像元素(由基本图像元素组合而成)构建复杂的图形树。在设计中我们对每一个对象都配备一个Draw()方法,在调用时,会显示相关的图形。可以看到,这里复合图像元素它在充当对象的同时,又是那些基本图像元素的一个容器。先看一下基本的类结构图:

图中橙色的区域表示的是复合图像元素。
示意性代码:
public abstract class Graphics { protected string _name; public Graphics(string name) { this._name = name; } public abstract void Draw(); } public class Picture : Graphics { public Picture(string name) : base(name) { } public override void Draw() { // } public ArrayList GetChilds() { //返回所有的子对象 } }
而其他作为树枝构件,实现代码如下:
public class Line : Graphics { public Line(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } } public class Circle : Graphics { public Circle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } } public class Rectangle : Graphics { public Rectangle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } }
现在我们要对该图像元素进行处理:在客户端程序中,需要判断返回对象的具体类型到底是基本图像元素,还是复合图像元素。如果是复合图像元素,我们将要用递归去处理,然而这种处理的结果却增加了客户端程序与复杂图像元素内部结构之间的依赖,那么我们如何去解耦这种关系呢?我们希望的是客户程序可以像处理基本图像元素一样来处理复合图像元素,这就要引入Composite模式了,需要把对于子对象的管理工作交给复合图像元素,为了进行子对象的管理,它必须提供必要的Add(),Remove()等方法,类结构图如下:

示意代码:
public abstract class Graphics { protected string _name; public Graphics(string name) { this._name = name; } public abstract void Draw(); public abstract void Add(); public abstract void Remove(); } public class Picture : Graphics { protected ArrayList picList = new ArrayList(); public Picture(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); foreach (Graphics g in picList) { g.Draw(); } } public override void Add(Graphics g) { picList.Add(g); } public override void Remove(Graphics g) { picList.Remove(g); } } public class Line : Graphics { public Line(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } public override void Add(Graphics g) { } public override void Remove(Graphics g) { } } public class Circle : Graphics { public Circle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } public override void Add(Graphics g) { } public override void Remove(Graphics g) { } } public class Rectangle : Graphics { public Rectangle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } public override void Add(Graphics g) { } public override void Remove(Graphics g) { } }
这样引入Composite模式后,客户端程序不再依赖于复合图像元素的内部实现了。然而,我们程序中仍然存在着问题,因为Line,Rectangle,Circle已经没有了子对象,它是一个基本图像元素,因此Add(),Remove()的方法对于它来说没有任何意义,而且把这种错误不会在编译的时候报错,把错误放在了运行期,我们希望能够捕获到这类错误,并加以处理,稍微改进一下我们的程序:
public class Line : Graphics { public Line(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } public override void Add(Graphics g) { //抛出一个我们自定义的异常 } public override void Remove(Graphics g) { //抛出一个我们自定义的异常 } }
这样改进以后,我们可以捕获可能出现的错误,做进一步的处理。上面的这种实现方法属于透明式的Composite模式,如果我们想要更安全的一种做法,就需要把管理子对象的方法声明在树枝构件Picture类里面,这样如果叶子节点Line,Rectangle,Circle使用这些方法时,在编译期就会出错,看一下类结构图:

示意代码:
public abstract class Graphics { protected string _name; public Graphics(string name) { this._name = name; } public abstract void Draw(); } public class Picture : Graphics { protected ArrayList picList = new ArrayList(); public Picture(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); foreach (Graphics g in picList) { g.Draw(); } } public void Add(Graphics g) { picList.Add(g); } public void Remove(Graphics g) { picList.Remove(g); } } public class Line : Graphics { public Line(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } } public class Circle : Graphics { public Circle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } } public class Rectangle : Graphics { public Rectangle(string name) : base(name) { } public override void Draw() { Console.WriteLine("Draw a" + _name.ToString()); } }
这种方式属于安全式的Composite模式,在这种方式下,虽然避免了前面所讨论的错误,但是它也使得叶子节点和树枝构件具有不一样的接口。这种方式和透明式的Composite各有优劣,具体使用哪一个,需要根据问题的实际情况而定。通过Composite模式,客户程序在调用Draw()的时候不用再去判断复杂图像元素中的子对象到底是基本图像元素,还是复杂图像元素,看一下简单的客户端调用:
public class App { public static void Main() { Picture root = new Picture("Root"); root.Add(new Line("Line")); root.Add(new Circle("Circle")); Rectangle r = new Rectangle("Rectangle"); root.Add(r); root.Draw(); } }
Composite模式实现要点:
1.Composite模式采用树形结构来实现普遍存在的对象容器,从而将“一对多”的关系转化“一对一”的关系,使得客户代码可以一致地处理对象和对象容器,无需关心处理的是单个的对象,还是组合的对象容器。
2.将“客户代码与复杂的对象容器结构”解耦是Composite模式的核心思想,解耦之后,客户代码将与纯粹的抽象接口——而非对象容器的复内部实现结构——发生依赖关系,从而更能“应对变化”。
3.Composite模式中,是将“Add和Remove等和对象容器相关的方法”定义在“表示抽象对象的Component类”中,还是将其定义在“表示对象容器的Composite类”中,是一个关乎“透明性”和“安全性”的两难问题,需要仔细权衡。这里有可能违背面向对象的“单一职责原则”,但是对于这种特殊结构,这又是必须付出的代价。ASP.NET控件的实现在这方面为我们提供了一个很好的示范。
4.Composite模式在具体实现中,可以让父对象中的子对象反向追溯;如果父对象有频繁的遍历需求,可使用缓存技巧来改善效率。