论文阅读“PICO: CONTRASTIVE LABEL DISAMBIGUATION FOR PARTIAL LABEL LEARNING”(ICLR2022)
论文标题
PICO: CONTRASTIVE LABEL DISAMBIGUATION FOR PARTIAL LABEL LEARNING
论文作者、链接
作者:Wang, Haobo and Xiao, Ruixuan and Li, Yixuan and Feng, Lei and Niu, Gang and Chen, Gang and Zhao, Junbo
链接:https://arxiv.org/abs/2201.08984
代码:https://github.com/hbzju/PiCO
预备知识
Partial label learning (PLL):部分标签学习,配备一组候选标签,而不是确切的真实标签

Introduction逻辑
深度学习需要大量标签,但是很少有研究关心标签的歧义问题。现有的方法要求有比较好的特征表示,并且假设在特征空间中相近的样本点更有可能有相同的真实标签。固有标签中的不确定性会对特征学习有负面影响,并且也阻碍标签消歧。
论文动机&现有工作存在的问题
标签消歧问题,即如何从候选标签中选出真实标签
固有标签中的不确定性会对特征学习有负面影响,并且也阻碍标签消歧
论文核心创新点
特征学习和标签消歧
对比学习+基于类原型的标签消歧算法
为分配在同一个类中的样本进行特征对齐,有助于标签消歧
(1)精选的伪标签可以给对比学习提供更好的正样本对
(2)更好的对比学习性能可以使得模型学到更好的特征,有助于标签消歧
相关工作
Partial label learning (PLL):
 代表输入空间,
代表输入空间,![]() 代表输出空间。
代表输出空间。
训练数据集![]() ,其中每个元组由图像
,其中每个元组由图像![]() 和候选标签集
和候选标签集![]() 组成
组成
PLL的目标是预测与输入图像相关联的真实标签,但将PLL转移到标签空间由于标签的模糊会带来不确定性。
PLL的一个基本假设是真实标签存在于候选集中,即![]() ,所以特征学习过程中总存在固有歧义,候选集中所有标签的概率和为1
,所以特征学习过程中总存在固有歧义,候选集中所有标签的概率和为1
对于每一个样本点的损失计算

Contrastive Learning (CL)
论文方法

对比学习
目标函数
给公式(1)添加了一个对比学习的项,主要问题是如何构建正样本集。
对于每一个样本![]() ,通过随机数据增广生成两个视图,一个队列视图和一个关键视图。
,通过随机数据增广生成两个视图,一个队列视图和一个关键视图。
将生成的视图输入队列网络 和关键网络
和关键网络![]() ,生成一对
,生成一对 归一化嵌入向量
归一化嵌入向量![]() 以
以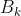 及
及![]() ,
,![]() 代表数据增广。队列网络中使用相同的卷积块和分类器,后接一个预测头。与MOCO相同,关键网络使用动量更新参数。
代表数据增广。队列网络中使用相同的卷积块和分类器,后接一个预测头。与MOCO相同,关键网络使用动量更新参数。
维护一个队列来存储最新的key embeding k,并按时间顺序更新队列。即对比嵌入向量池contrastive embedding pool:

![]() 和是每个当前batch的队列和关键视图的垂直嵌入向量
和是每个当前batch的队列和关键视图的垂直嵌入向量
对于一个样本点 的对比损失:
的对比损失:
 是正样本集并且
是正样本集并且![]()
如何确定正样本集
使用分类器预测的标签![]() ,将预测标签限制在候选集合
,将预测标签限制在候选集合 中。
中。
根据下列公式选择正样本
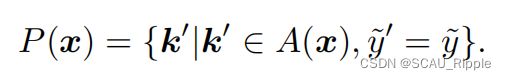
其中,![]() 是
是![]() 的预测标签。本文还维护一个标签队列。样本点x的正样本集合的定义,是那些携带相同或近似标签,即
的预测标签。本文还维护一个标签队列。样本点x的正样本集合的定义,是那些携带相同或近似标签,即 相同或近似,的样本点。
相同或近似,的样本点。
总的目标函数:

尽管如此,通过CL学习高质量特征表示的目标依赖于对正样本集选择的准确预测,但在存在标签歧义的情况下,这一问题仍未得到解决,为此本文提出了一种新颖的标签消歧机制。
基于原型的标签消歧
对每一个类![]() ,维护一个原型嵌入向量
,维护一个原型嵌入向量![]() ,可以看作是一组具有代表性的嵌入向量。伪目标分配是为了找到当前嵌入向量的最接近的原型向量,类似聚类步骤。通过一个平均动量式的函数进行硬标签分配。为此,我们可以直观地假设,原型向量的使用与对比项建立了一种联系
,可以看作是一组具有代表性的嵌入向量。伪目标分配是为了找到当前嵌入向量的最接近的原型向量,类似聚类步骤。通过一个平均动量式的函数进行硬标签分配。为此,我们可以直观地假设,原型向量的使用与对比项建立了一种联系
伪目标更新
用一种平均移动式的策略去更新伪目标
用一个独特的分布对伪目标进行初始化:![]()
然后使用下列的平均移动机制进行交替更新

其中,![]() 是一个正的常数,
是一个正的常数, 是对第j个类的原型向量。按直觉来说,拟合一致的伪目标可以为分类器带来良好的初始化,因为在一开始对比嵌入向量就不太容易区分。采用平均移动策略将伪目标平滑地更新到正确的目标。原型向量:对于给定的输入x,最接近的原型向量表示它的ground-truth标签。由式6可知,s都有向z定义的one-hot分布略微移动的趋势。如果一个样本始终指向一个原型向量,那么伪目标可以(几乎)收敛到一个比较高置信的one-hot向量。
是对第j个类的原型向量。按直觉来说,拟合一致的伪目标可以为分类器带来良好的初始化,因为在一开始对比嵌入向量就不太容易区分。采用平均移动策略将伪目标平滑地更新到正确的目标。原型向量:对于给定的输入x,最接近的原型向量表示它的ground-truth标签。由式6可知,s都有向z定义的one-hot分布略微移动的趋势。如果一个样本始终指向一个原型向量,那么伪目标可以(几乎)收敛到一个比较高置信的one-hot向量。
原型更新
为了提高训练效率,放弃了每一轮都更新原型向量,转而也是使用平均移动的方式更新
![]()
![]() 代表c类的动量原型向量,由正则化的队列嵌入向量
代表c类的动量原型向量,由正则化的队列嵌入向量 定义,向量的预测结果为c类。
定义,向量的预测结果为c类。
对比学习与标签消歧之间的协同作用
首先,由于对比项在嵌入空间中表现出良好的聚类效应,而更好的聚类结果可以得到更好的原型向量,由此进一步发挥标签消歧模块的作用。其次,精调后的消歧标签可以反过来对构建正样本集产生作用,进而影响到对比学习阶段学到的特征。
消融实验设计
![]() 和标签消歧的效果
和标签消歧的效果
不同的消歧策略
平均移动因子 的影响
的影响
一句话总结
本文,通过一个自己设计的标签消歧算法,对标签筛选过后得到更好的正样本集,并由此得到更好的对比学习效果。