TransTrack: Multiple Object Tracking with Transformer论文阅读笔记
TransTrack阅读笔记
-
- (一) Title
- (二) Summary
- (三) Research Object
- (四) Problem Statement
- (五) Method
-
- 5.1 模型结构
- 5.2 Training
- 5.3 Inference
- (六) Experiments
-
- 6.1 实验设置
- 6.2 MOT17上的结果
- 6.3 消融实验
-
- 6.3.1 Transformer结构
- 6.3.2 解码器中的Query
- 6.3.3 tracking boxes的matching策略
- 6.3.4 边界框的关联
- 6.4 同其他trackers的比较
- (七) Conclusions
- (八) Notes
-
- 8.1 Transformer在Vision Tasks中的应用
(一) Title

论文地址:https://arxiv.org/abs/2012.15460
代码地址:https://github.com/PeizeSun/TransTrack
前言: 本文建立了一种novel joint-detection-and-tracking模型,在一个框架中完成目标检测和跟踪。这是首篇将Transformer引入到MOT任务中
(二) Summary
研究背景
目前MOT中主要有两种方式:tracking-by-detection以及joint-detection-and-tracking方式。
- 目前SOTA的多目标Trackers采用tracking-by-detection的方式。首先通过目标检测器,接着利用Re-ID特征以及边界框信息(IoU)进行关联。在SORT中通过卡尔曼滤波器以及匈牙利算法进行关联。DeepSORT中将SORT中的association cost替换成了从deep convolutional network中提取的Appearance特征。POI通过高性能的检测以及deep learning-based appearance取得了SOTA。Lifted-Multicut中结合deep representation以及body pose feature。STRN中提出了跟踪轨迹和目标之间的一个相似性学习框架,能够编码时空关系。虽然Tracking-by-detection方式取得了SOTA的性能,但是模型复杂度和计算cost都非常大。
- Joint-detection-and-tracking方式希望通过a single stage完成检测和跟踪任务。D&T中提出了一个多任务框架用于frame-based object detection以及across-frame track regression.Integrated-Detection中通过将当前帧的检测同之间帧的跟踪结合起来来改善检测性能。Tracktor中将之前帧的tracking boxes作为region proposals进行边界框回归来输出当前帧的跟踪结果。JDE和FairMOT中通过一个共享的骨干网络学习目标检测任务以及appearance embedding task。CenterTrack中通过tracking-conditioned detection定位目标,并且预测他们同上一帧的偏移。ChainedTracker中chains paired bounding boxes estimated from overlapping nodes in which each node covers two adjacent frames没看懂,直接把原文搬过来的,回头有时间看下这篇论文。
本文工作
本文提出TransTrack,采用Transformer架构,是一个基于注意力的query-key机制,它利用来自前一帧object特征并且同时引入了一个learnd object queries(为什么是learned不是learnable?).完成了在single shot中同时解决目标检测和跟踪问题。也就是端到端的tracking方式。具体来讲就是:
基于DETR的object query的思想。这里将所有的query分成两部分:一部分叫做Object Queries,用来提供a sense of new-coming的目标。另一部分叫做Track Queries用来maintain 目标轨迹。两个query分别进行预测,并且TransTrack使用简单的IoU 匹配来生成最终的结果,并且不需要使用NMS
实验结果
在MOT17和MOT20上分别达到了74.5%和64.5%的MOTA,能够同SOTA一较高下
(三) Research Object
本文在目前tracking-by-detection方式占主导地位的情况下,将SOT中query-key机制引入到多目标跟踪中,构建了基于注意力机制的query-key多目标跟踪框架,博主觉得对于多目标跟踪任务来说是相当有创新的事情。
(四) Problem Statement
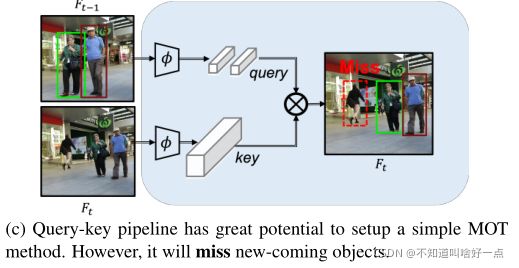
目前在MOT任务中通常采用tracking-by-detection的方式,如下图所示:
通过检测器分别在 t − 1 t-1 t−1和 t t t帧将所有的目标检测出来,然后基于数据关联方式将 t t t帧的检测结果关联到 t − 1 t-1 t−1帧基于检测边界框构建的跟踪轨迹上去。也就是目标检测任务,同re-identification分别进行两者不能同时收益(注:这里应该说的是检测+deepsort的方式,re-identification是单独训练的网络)。在JDE和FairMOT中是将目标检测和Re-identification通过整个网络构建起来,通过多任务学习来同时收益。在前后帧的数据关联是基于kalman滤波以及匈牙利匹配实现。
Siamese networks在解决SOT问题中取得了重大突破,本文在SOT基础上,引入Query-Key机制来构建一个joint-detection-and-tracking框架,并指出这种框架是promising的。在SOT任务中是怎么利用query-key的方式来构建跟踪呢?
其中目标对象作为query,图像区域作为key,如上图所示,对于同一个对象在不同帧中的特征是高度相似的,这使得query-key的机制能够处理SOT问题。直接将普通query-key机制从SOT迁移到MOT任务会发生什么呢?
会出现很多检测不到的情况,也就是说我们上一帧的对象能够查询到,但是当前帧新出现的对象怎么查询到呢?也就是怎么能够更好地捕获新出现的对象呢?并且怎么将上一帧的检测结果传递到下一帧呢?也就是怎么设计Query-Key的机制来解决当前的问题呢?


(五) Method
TransTrack的整体思路
从上图中的疑问是:
- backbone 的 F t − 1 F_{t-1} Ft−1和 F t F_t Ft是怎么送到编码器的?
- 为什么最右侧的track query采用的是 F t F_t Ft时刻,
- track query是怎么得到的呢?
整体框架的相关描述:通过object query来得到目标检测的结果,利用前一帧的检测目标构建track query用来得到同track query关联上的目标,在这个方案下,形成了两组检测框,分别对应着检测框以及跟踪框。然后结合IoU信息通过匈牙利匹配形成最终的有序边界框,有序边界框实际上就是对应着检测结果。
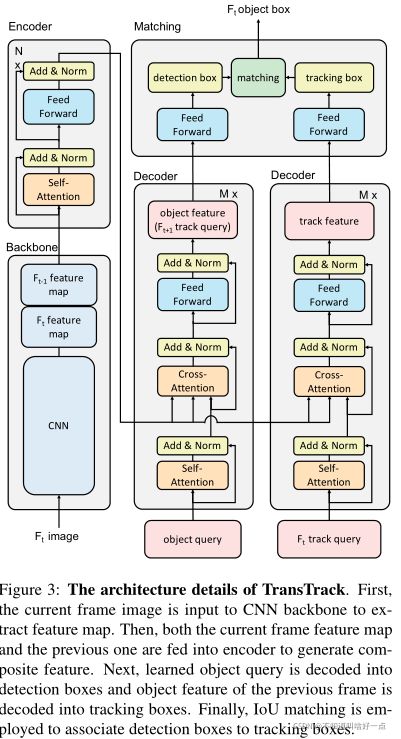
5.1 模型结构
TransTrack基于transformer,通过编码-解码方式构建,依赖于堆叠multi-head attention layers以及feed-forward networks.Multi-head Attention分为self-attention(输入的query和key相同)和cross-attention(输入的query和key不同),通过encoder生成keys,解码器可以看成task-specific的queries。
编码器将两个连续帧的特征映射 F t − 1 F_{t-1} Ft−1和 F t F_t Ft作为输入。这边两帧同时输入到编码器是会有提升嘛?为什么仅仅输入当前帧呢?。在解码器这边采用了两个并行的decoder分别用于目标检测以及object propagationobject propagation按道理将应该通过关联的方式进行propagation的呀。从原理上来讲,这里分别使用track query和detect query来构建跟踪的方式非常合理啊。
- 其中左边的那个解码器和DETR的思想相同,通过encoder的信息以及object query输出最终的检测预测,得到检测框
- 右边的解码器,说实话同左边几乎完全一样,只不过更换了query,通过query来继承之前的appearance以及location信息,通过query表示之前的appearance以及location信息够用嘛?,所以能够很好地跟踪上。
将detect boxes同track boxes使用匈牙利匹配起来,没有匹配上的detect boxes作为新的轨迹。
这里的疑问就是到底什么是Transformer MOT的问题呢?能够提升的地方在哪里?
5.2 Training
训练数据
- 两个来源构建数据集,训练数据可以是两个连续的帧,也可以是两个从真实片段中随机选取的帧。此外,训练数据也可以是static image,相邻帧通过随机缩放和转换静态图像来模拟。首先第一个问题,为什么两个从真实片段中随机抽出的帧可以呢?第二个问题:为什么随机缩放和转换的static image也能用来训练呢?
训练损失
tracking boxes和detect boxes的损失是同一张图像中对目标边界框的预测,显然这个地方有重复啊!,允许我们通过两个相同的损失来训练这两个decoders?这里应该说的是损失函数相同,难道两个detector对应的预测最终结果是相同的嘛?也就是detect queries和track queries都需要预测图像中所有的边界框嘛?好像不是这样的。对应的set prediction损失为:
L = λ cls ⋅ L cls + λ L 1 ⋅ L L 1 + λ giou ⋅ L giou \mathcal{L}=\lambda_{\text {cls }} \cdot \mathcal{L}_{\text {cls }}+\lambda_{L 1} \cdot \mathcal{L}_{L 1}+\lambda_{\text {giou }} \cdot \mathcal{L}_{\text {giou }} L=λcls ⋅Lcls +λL1⋅LL1+λgiou ⋅Lgiou
其中 L cls \mathcal{L}_{\text {cls }} Lcls 是预测类别和真实类别的focal loss损失。 L L 1 \mathcal{L}_{L 1} LL1和 L giou \mathcal{L}_{\text {giou }} Lgiou 是预测框和真实框normalized center coordinates,width和height之间的 L 1 L1 L1损失以及GIoU损失。这里弄成normlization,之前faster R-CNN也是类似normlization的方式,是不是全连接层这边适合normalization的形式?
注意这里的matching cost和training loss一定要一样嘛?如果不相同的话,会怎么样?
5.3 Inference
首先检测第一帧对象,feature maps是第一帧的两个拷贝,也就是说这里的feature maps不是 F t − 1 F_{t-1} Ft−1和 F t F_t Ft,而是两个相同的特征图。接着对帧进行object propagation以及box association。为了能够使得模型对遮挡鲁棒,当一个跟踪框未匹配,将其设置成"inactive"模式,接着保留 K = 32 K=32 K=32帧。
(六) Experiments
6.1 实验设置
数据集:
- MOT17和MOT20,使用MOTA作为衡量整体性能的主要指标
模型设置
- 骨干网络ResNet50
- 学习器AdamW
- 批大小16
- 对于Transformer,初始学习率2e-4。对于骨干网络初始学习率为2e-5
- Transformer 权重衰减1e-4,使用Xavier-init
- 骨干网络在ImageNet上预训练,并且冻结了BN层
- 数据增强方式包括随机水平翻转,随机crop,scale augmentation。随机缩放。训练了150个epoch,在第100个epoch时学习率下降了10倍。
- 模型首先在CrowdHuman上pre-trained。接着在MOT上进行了fine-tune。
6.2 MOT17上的结果
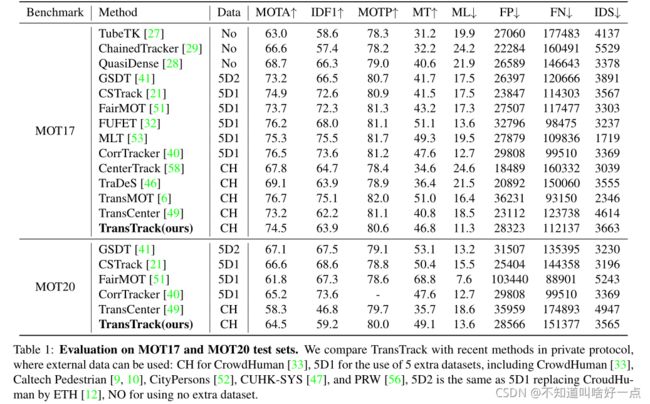
在MOTP和FN上,TransTrack的表现效果很好,MOTP表示TransTrack能够能够准确定位目标中的物体,FN表示大多数对象都能够成功检测到。ID-switch上同样能够和FairMOT以及CenterTrack相当,尽管ID-switch分数要比SOTA低,但是端到端的方式还是相当有前景的。到底是什么影响跟踪性能的主要因素呢?
MOT20中比MOT17多了更多的拥挤场景,目标遮挡更严重,目标尺寸更小。所有方法在MOT20上的性能都低于MOT17,但是TransTrack在detection metrics以及association metrics上表现能比得上SOTA。
6.3 消融实验
6.3.1 Transformer结构
四种用于实验的Transformer
- Transformer同DETR中的设置一样,基于res5 stage构建。
- Transformer-DC5增加了feature maps的分辨率,在res5 stage的输出增加了dilation卷积,并且remove a stride from the first covolution of this stage。
- Transformer-P3采用FPN对输入feature map进行特征融合,并删除掉encoder,将骨干网络的学习率代称和Transformer相同的学习率。
- Deformable Transformer,解决了transformer中limited resolution。在合理内容使用的情况下,将多尺度特征融合到整个编码器和解码器pipeline中,并且提供了优异的性能。

6.3.2 解码器中的Query
这里分别考虑object query,track query在当前任务中的作用:
- 仅仅使用object query,只将可学习的object query作为decoder query时,通过在输出set中的次序进行关联,令人惊讶的是这种方式能够到58.3的MOTA,这是因为object query预测的目标仅仅是images上的certain area这里是真的嘛?。而序列图像中目标的位置仅仅发生了轻微的变化。然而这里其实也会导致不可忽略的错误匹配。
- 仅仅使用track query时,从前一帧中产生track query,能够将大范围的运动关联起来。但是只有出现在第一帧中的对象才能够实现连续跟踪。对于整个视频序列来说,大多数对象将被遗漏。
- object query+track query。同时使用效果好。


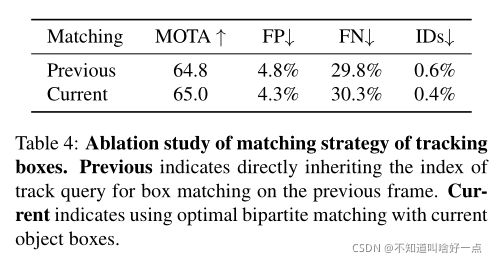
6.3.3 tracking boxes的matching策略
matching tracking boxes with prebious frame objects的两种方式注意这里没有想明白这两种到底是怎么回事儿?:
- Previous:通过将initial tracking boxes同之前的object boxes通过二部matching进行匹配,也就是说matching index是直接从对应的track queries中得到的。是不是说对tracking boxes同当前的gt boxes进行二部匹配的那个index再对应到object boxes同gt boxes进行二部匹配的那个上?好像不是欸
- supervise跟踪边界框的输出通过和当前object boxes的最优二分匹配得到。是不是说当检测出边界框之后,再将tracking boxes同检测出的detect boxes进行二部匹配得到最终的预测边界框?好像不是欸
6.3.4 边界框的关联
不同的边界框关联后处理方式,是将detect boxes同tracking boxes合并成一个集合,Hungarian algorithm和 Kuhn-Munkres (KM) algorithm有区别嘛?

6.4 同其他trackers的比较
同detector+motion model以及detector+Re-ID相比,TransTrack到底改变了什么?
Motion Model
将DETR加上kalman滤波器构建了一个detector+motion model。kalman滤波器方法和本文方法提供了相似的ID性能,MOT17数据集是高帧率视频序列,不同的关联方法并没有带来太大的区别。但是当每4帧采样一次时,也就是物体的运动变大,采用track query的方式能够带来更加明显的提升。
Re-ID 特征
这里采用的是检测器+Re-ID分支来构建的跟踪器,通过一下两种方式来构建Re-ID分支。
这种Re-ID的特征能够通过track query的方式学习到,感觉真牛啊。


(七) Conclusions
本文构建了首个基于Transformer的MOT pipeline,引入了track query的思想。
(八) Notes
8.1 Transformer在Vision Tasks中的应用
detection,segmentation,3D data processing,backbone construction,video segmentation
Transformer对视觉数据进行不同时空处理任务的能力能够取代RNN模型。