离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析

[更新记录]
文章信息:Samin Yeasar Arnob, Riashat Islam, Doina Precup: “Importance of Empirical Sample Complexity Analysis for Offline Reinforcement Learning”, 2021; arXiv:2112.15578.
本文是由McGill和DeepMind合作,Samin Yeasar Arnob第一作者提出,文章发表在NeuraIPS2021 顶会workshop中, 是一篇关于offline RL数据样本复杂性相关的文章。
摘要:本文首先解释了样本复杂性的基本概念,并就其在监督学习中的应用进行阐述,其次推理了强化学习中样本数的复杂度,最后就论文中通过样本复杂度对函数的过拟合影响等进行分析总结。
1. Offline RL遇到的两个挑战
offline RL须解决由于缺乏主动探索而导致的关键问题,这部分属于老生常谈了
1.1 distribution shift
在大多数情况下,历史数据是由与最优行为策略不同的某种行为策略生成的。因此,离线RL的一个关键挑战来自数据的distribution shift:如何利用过去的数据发挥最大的效果,即使由目标策略引起的分布与我们所学习的策略不同?
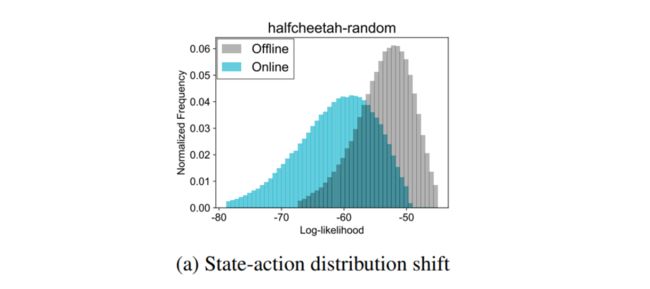
1.2 limited data coverage
理想情况下,如果数据集为每个状态操作对包含足够多的数据样本,那么就有希望同时学习每个策略的性能。然而,这种统一的覆盖要求往往不仅是不现实的(因为我们不能再改变过去的数据),而且也是不必要的(因为我们可能只对确定一个单一的最优政策感兴趣)。实际问题就是,在诸如机器人,无人驾驶等实际的环境中也不可能收集到全部的数据集,所以很难覆盖全部,其实在先前的博客离线强化学习(Offline RL)系列4:(数据集)Offline数据集特征及对离线强化学习算法的影响中已经说过,即:SACo(Relative State-Action Coverage, 状态-动作对覆盖范围) 指标问题。
这里引用Gen Li的一句话, 抛出问题:
Can we develop an offline RL algorithm that achieves near-optimal sample complexity without burn-in cost? If so, can we accomplish this goal by means of a simple algorithm without resorting to sophisticated schemes like variance reduction?
在这里,我们假设可以访问一个offline或者是batch数据集(或历史数据集) D D D ,它包含一个由 k k k 个独立的样本轨迹 π b = { π h b } 1 ≤ h ≤ H \pi^{b}=\left\{\pi_{h}^{b}\right\} 1 \leq h \leq H πb={πhb}1≤h≤H 。更具体地说,第 k k k 个样本轨迹由一个数据序列组成
( s 1 k , a 1 k , s 2 k , a 2 k , … , s H k , a H k , s H + 1 k ) \left(s_{1}^{k}, a_{1}^{k}, s_{2}^{k}, a_{2}^{k}, \ldots, s_{H}^{k}, a_{H}^{k}, s_{H+1}^{k}\right) (s1k,a1k,s2k,a2k,…,sHk,aHk,sH+1k)
然而,有多少个样本可以让训练消除 distribution shift、满足data coverage问题。以及在Online训练中可以实现SOTA的环境中如何采集样本、采集多少样本,特别是对于real world中的一些采集昂贵、风险系数比较高的环境(下图),我们到底该需要多少样本呢?(What if sample/trial is costly and limited? Sample Size/Complexity is essential!)
这就是我们本篇博文要阐述的样本复杂性(Sample complexity) 问题。

2. 样本复杂性(Sample complexity)
2.1 什么是样本复杂性?
在机器学习中,学习的复杂性主要沿着两个轴衡量:信息(Information) 和 计算(computation), 在维基中关于sample complexity是这样定义的:

本文主要针对第一个衡量指标 信息 开展,本质上样本复杂度与学习的泛化性能有关,而样本复杂性主要解决了数据分析中的以下三个问题:
- 数据(训练集)是否包含足以做出有效预测(或修复模型)的信息?
- 样本是否足够大?
- 从给定大小的样本中推断出的预测(模型)有多准确?
2.2 监督学习中的sample complexity
下面以监督学习为例子开始分析:

这里定义了一个假设 h, 最终的问题变成了对 S S S 的优化可否能找到 h h h ?右边是具体的数学描述,作者得出的理论是样本(sample)的个数 m m m
m ≥ 1 ε [ ln ( ∣ H ∣ ) + ln ( 1 δ ) ] m \geq \frac{1}{\varepsilon}\left[\ln (|H|)+\ln \left(\frac{1}{\delta}\right)\right] m≥ε1[ln(∣H∣)+ln(δ1)]
下面举一个例子:

那么为什么我们要研究采样复杂性呢? 先看这张图,图中的sample的数量直接决定了拟合曲线的效果。
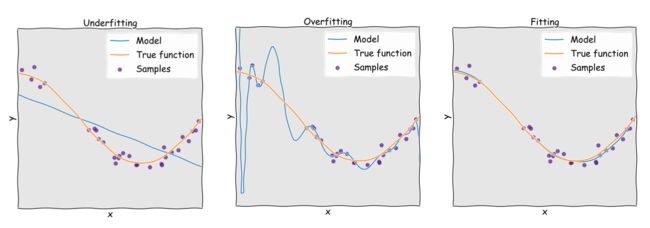
其实说白了就是和模型的收敛有关
2.3 强化学习中的sample complexity
回到之前的问题上,对于轨迹(trajectory)来说,采集多少样本合适呢?以Q-learning为例子我们分析,每个epoch收集 m m m 个sample, 通过构造经验结构以及强阿虎学习的值函数,得到值函数为:
v s ← max a [ r ( s , a ) + γ P ( s ′ / s , a ) T v ] for all s w h e r e P ^ ( s ′ ∣ s , a ) = # ( s , a ) → s ′ # ( s , a ) v_{s} \leftarrow \max _{a}\left[r(s, a)+\gamma P\left(s^{\prime} / s, a\right)^{T} v\right] \text { for all } s \\ where \quad \widehat{P}\left(s^{\prime} \mid s, a\right)=\frac{\#(s, a) \rightarrow s^{\prime}}{\#(s, a)} vs←amax[r(s,a)+γP(s′/s,a)Tv] for all swhereP (s′∣s,a)=#(s,a)#(s,a)→s′
通过先抽样后计算的方式,样本的个数大约为: m ≥ ( 1 − γ ) − 5 m \geq(1-\gamma)^{-5} m≥(1−γ)−5 , 也就是说: γ = 0.95 , m ≥ 3 , 000 , 000 \gamma=0.95, m \geq 3,000,000 γ=0.95,m≥3,000,000

同样的过程,Gen Li给出了一个有限MDP和无限MDP问题的样本复杂度上下界,如下所示:

下图是关于model-free的样本复杂度上下界

3. Offline RL 中的经验样本复杂度分析
3.1 Offline RL 性能如何根据数据集大小而变化?
作者通过了不同的样本数(5000~1000000)去测试,大多数算法还是随着样本增大normalization score也增大(除了(a)中的DAC等)。
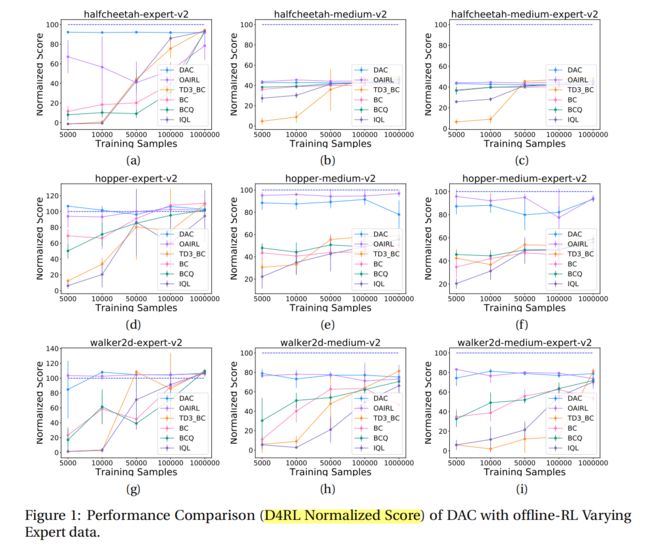
思考:这里应该是在样本质量和丰富性保证的前提下去说样本的size,不然就成之前说过BEAR中的样本数增大,并没有收敛的问题了。
3.2 现有的Offline RL是否存在过拟合现象?
3.2.1 评估离线 RL 中的过拟合
这里,作者提供了一个测量离线RL中的训练和验证性能的指标(类似于在监督学习中通常研究的标准损失):
使用专家行动 a V a_{V} aV 和策略行动 π θ ( S V ) \pi_{\theta}\left(S_{V}\right) πθ(SV) 之间的均方误差(MSE)损失来衡量行为者与专家的偏差。
在这里使用MSE而不是KL散度度量,因为我们研究的大多数离线RL算法都是基于确定性策略的,就像BCQ[6]和其他算法一样。
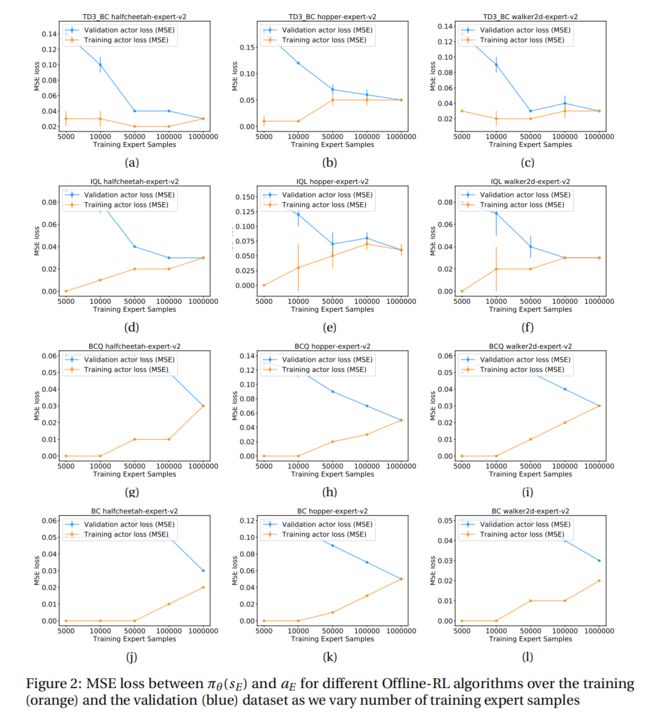
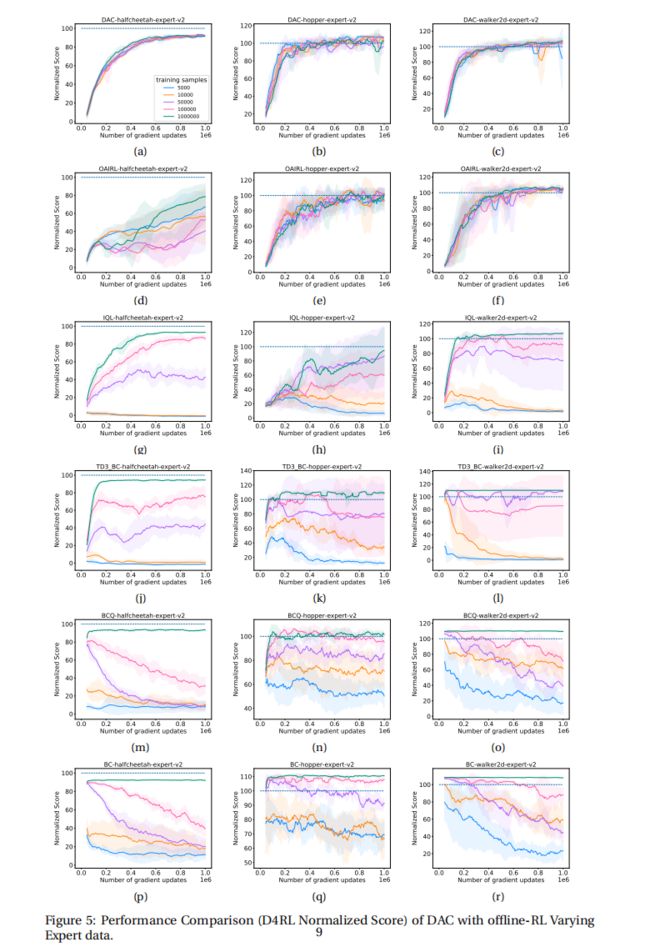
结论: 图 2 显示了不同离线 RL 算法的过拟合现象。 对于每种算法训练 1M 次迭代, 由于样本大小不同,随着样本量的减少,训练和验证误差之间的差异显着增加,这表明算法更容易过拟合(由于与数据集大小相比更复杂的策略类)。
3.2.2 离线 RL 算法的性能验证
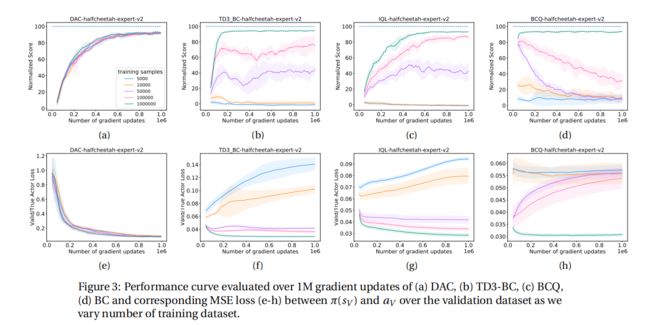
结论: 图3(b)和3(f)中,对于TD3-BC算法,当验证损失最低时,性能改进最高;同样,对于5000的样本量,TD3-BC的验证误差最高,这导致该算法的性能最低,以累积回报衡量。没有在训练之间进行评估,这里我们可以根据训练的智能体是正在改善还是偏离做出训练指导。
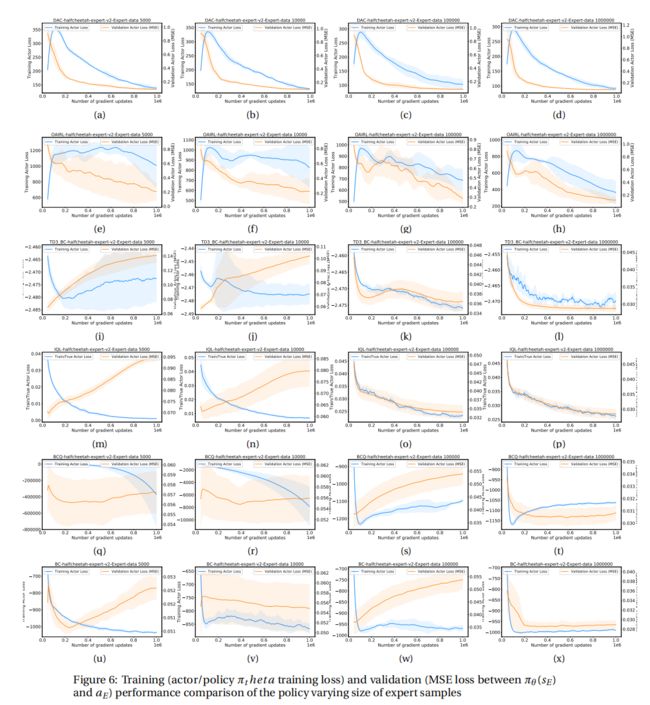
结论: 在标准离线 RL 算法中通常显示的超过 1M 数据集大小的累积回报性能并不总是衡量算法在较小数据集下是否稳健的良好指示性指标。

参考文献
[1]. Samin Yeasar Arnob, Riashat Islam, Doina Precup: “Importance of Empirical Sample Complexity Analysis for Offline Reinforcement Learning”, 2021; arXiv:2112.15578.
[2]. Gen Li, Laixi Shi, Yuxin Chen, Yuejie Chi, Yuting Wei: “Settling the Sample Complexity of Model-Based Offline Reinforcement Learning”, 2022; arXiv:2204.05275.
[3].Sample complexity, https://en.wikipedia.org/wiki/Sample_complexity
[4]. https://www.cs.cmu.edu/~ninamf/courses/315sp19/lectures/2_25-SampleComplexity.pdf
[5]. https://web.stanford.edu/~yyye/MostOM2019Final.pdf
OfflineRL推荐阅读
离线强化学习(Offline RL)系列4:(数据集)Offline数据集特征及对离线强化学习算法的影响
离线强化学习(Offline RL)系列3: (算法篇) AWR(Advantage-Weighted Regression)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) CQL 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) TD3+BC 算法详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇) REM(Random Ensemble Mixture)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BEAR算法原理详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BCQ算法详解与实现
离线强化学习(Offline RL)系列2: (环境篇)D4RL数据集简介、安装及错误解决
离线强化学习(Offline RL)系列1:离线强化学习原理入门