NLP实战 | BERT文本分类及其魔改(附代码)
每天给你送来NLP技术干货!
写在前面
本文主要介绍了两种文本分类模型:BERT文本分类基础模型,及基于Bert和TextCNN的魔改模型。在作者实际的有关文本分类的工作中取得了F1值超越Bert基础模型近4%的效果。
1. Baseline:Bert文本分类器
Bert模型是Google在2018年10月发布的语言模型,一经问世就横扫NLP领域11项任务的最优结果,可谓风头一时无二。
有关于Bert中transformer的模型细节,我们在此就不赘述了。感兴趣的朋友,可以看看《The Illustrated Transformer》[1]这篇文章。
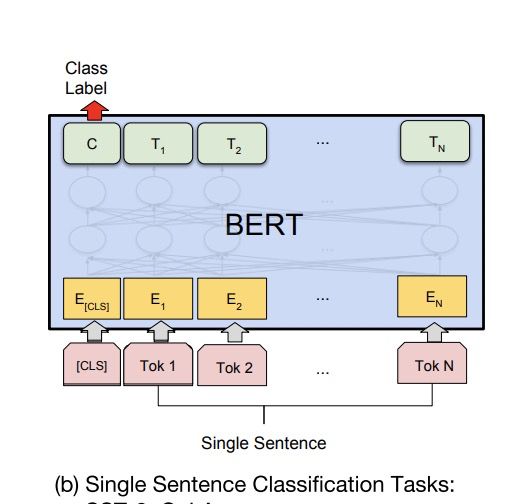 BERT单文本分类模型结构
BERT单文本分类模型结构
1.1 BERT文本分类模型
Bert文本分类模型常见做法为将Bert最后一层输出的第一个token位置(CLS位置)当作句子的表示,后接全连接层进行分类。模型很简单,我们直接看代码!
1.2 pytorch代码实现
# -*- coding:utf-8 -*-
# bert文本分类baseline模型
# model: bert
# date: 2021.10.10 10:01
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.utils.data as Data
import torch.optim as optim
import transformers
from transformers import AutoModel, AutoTokenizer
import matplotlib.pyplot as plt
train_curve = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义一些参数,模型选择了最基础的bert中文模型
batch_size = 2
epoches = 100
model = "bert-base-chinese"
hidden_size = 768
n_class = 2
maxlen = 8
# data,构造一些训练数据
sentences = ["我喜欢打篮球", "这个相机很好看", "今天玩的特别开心", "我不喜欢你", "太糟糕了", "真是件令人伤心的事情"]
labels = [1, 1, 1, 0, 0, 0] # 1积极, 0消极.
# word_list = ' '.join(sentences).split()
# word_list = list(set(word_list))
# word_dict = {w: i for i, w in enumerate(word_list)}
# num_dict = {i: w for w, i in word_dict.items()}
# vocab_size = len(word_list)
# 将数据构造成bert的输入格式
# inputs_ids: token的字典编码
# attention_mask:长度与inputs_ids一致,真实长度的位置填充1,padding位置填充0
# token_type_ids: 第一个句子填充0,第二个句子句子填充1
class MyDataset(Data.Dataset):
def __init__(self, sentences, labels=None, with_labels=True,):
self.tokenizer = AutoTokenizer.from_pretrained(model)
self.with_labels = with_labels
self.sentences = sentences
self.labels = labels
def __len__(self):
return len(sentences)
def __getitem__(self, index):
# Selecting sentence1 and sentence2 at the specified index in the data frame
sent = self.sentences[index]
# Tokenize the pair of sentences to get token ids, attention masks and token type ids
encoded_pair = self.tokenizer(sent,
padding='max_length', # Pad to max_length
truncation=True, # Truncate to max_length
max_length=maxlen,
return_tensors='pt') # Return torch.Tensor objects
token_ids = encoded_pair['input_ids'].squeeze(0) # tensor of token ids
attn_masks = encoded_pair['attention_mask'].squeeze(0) # binary tensor with "0" for padded values and "1" for the other values
token_type_ids = encoded_pair['token_type_ids'].squeeze(0) # binary tensor with "0" for the 1st sentence tokens & "1" for the 2nd sentence tokens
if self.with_labels: # True if the dataset has labels
label = self.labels[index]
return token_ids, attn_masks, token_type_ids, label
else:
return token_ids, attn_masks, token_type_ids
train = Data.DataLoader(dataset=MyDataset(sentences, labels), batch_size=batch_size, shuffle=True, num_workers=1)
# model
class BertClassify(nn.Module):
def __init__(self):
super(BertClassify, self).__init__()
self.bert = AutoModel.from_pretrained(model, output_hidden_states=True, return_dict=True)
self.linear = nn.Linear(hidden_size, n_class) # 直接用cls向量接全连接层分类
self.dropout = nn.Dropout(0.5)
def forward(self, X):
input_ids, attention_mask, token_type_ids = X[0], X[1], X[2]
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 返回一个output字典
# 用最后一层cls向量做分类
# outputs.pooler_output: [bs, hidden_size]
logits = self.linear(self.dropout(outputs.pooler_output))
return logits
bc = BertClassify().to(device)
optimizer = optim.Adam(bc.parameters(), lr=1e-3, weight_decay=1e-2)
loss_fn = nn.CrossEntropyLoss()
# train
sum_loss = 0
total_step = len(train)
for epoch in range(epoches):
for i, batch in enumerate(train):
optimizer.zero_grad()
batch = tuple(p.to(device) for p in batch)
pred = bc([batch[0], batch[1], batch[2]])
loss = loss_fn(pred, batch[3])
sum_loss += loss.item()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print('[{}|{}] step:{}/{} loss:{:.4f}'.format(epoch+1, epoches, i+1, total_step, loss.item()))
train_curve.append(sum_loss)
sum_loss = 0
# test
bc.eval()
with torch.no_grad():
test_text = ['我不喜欢打篮球']
test = MyDataset(test_text, labels=None, with_labels=False)
x = test.__getitem__(0)
x = tuple(p.unsqueeze(0).to(device) for p in x)
pred = bc([x[0], x[1], x[2]])
pred = pred.data.max(dim=1, keepdim=True)[1]
if pred[0][0] == 0:
print('消极')
else:
print('积极')
pd.DataFrame(train_curve).plot() # loss曲线1.3 结果与代码链接
单条样本测试结果:

loss曲线:

相关代码链接如下:
BERT文本分类jupyter版本[2]
BERT文本分类pytorch版本[3]
2.优化:基于Bert和TextCNN的魔改方法
2.1 TextCNN
在Bert问世前,TextCNN在文本分类模型中占据了举足轻重的位置。这源于CNN网络可以很有效的捕捉文本序列中的n-gram信息,而分类任务从本质上讲是捕捉n-gram排列组合特征。无论是关键词、内容,还是句子的上层语义,在句子中均是以n-gram特征的形式存在的。
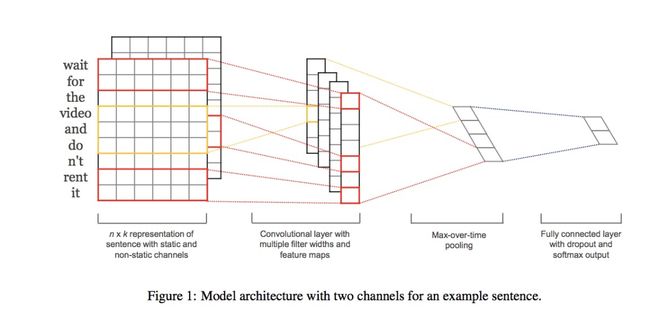 TextCNN模型结构
TextCNN模型结构
2.2 魔改思路
作者在做完Bert和TextCNN的实验惊奇的发现,Bert往往可以对一些表述隐晦的句子进行更好的分类,TextCNN往往对关键词更加敏感。所以作者魔改了一下模型,将Bert与TextCNN的思想融合在一起。
Bert-Base除去第一层输入层,有12个encoder层。每个encoder层的第一个token(CLS)向量都可以当作句子向量。我们可以抽象的理解为:
encode层越浅,句子向量越能代表低级别语义信息;
越深,代表更高级别语义信息。
我们的目的是既想得到有关词的特征,又想得到语义特征,模型具体做法是将第1层到第12层的CLS向量,作为CNN的输入然后进行分类。
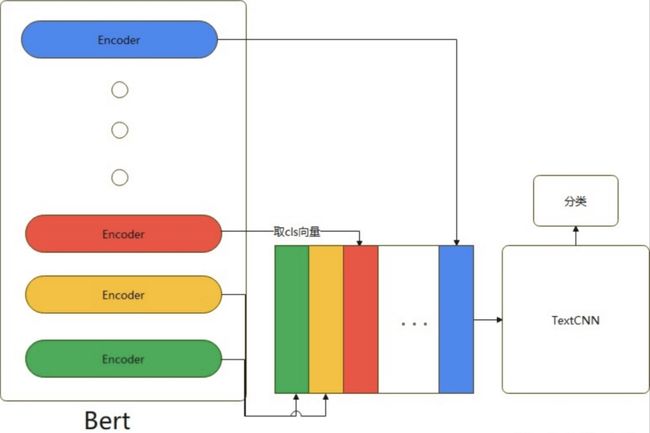 融合BERT-Blend-CNN
融合BERT-Blend-CNN
话不多说我们直接看代码!
2.3 pytorch代码实现
# -*- coding:utf-8 -*-
# bert融合textcnn思想的Bert+Blend-CNN
# model: Bert+Blend-CNN
# date: 2021.10.11 18:06:11
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.utils.data as Data
import torch.nn.functional as F
import torch.optim as optim
import transformers
from transformers import AutoModel, AutoTokenizer
import matplotlib.pyplot as plt
train_curve = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# # 定义一些参数,模型选择了最基础的bert中文模型
batch_size = 2
epoches = 100
model = "bert-base-chinese"
hidden_size = 768
n_class = 2
maxlen = 8
encode_layer=12
filter_sizes = [2, 2, 2]
num_filters = 3
# data,构造一些训练数据
sentences = ["我喜欢打篮球", "这个相机很好看", "今天玩的特别开心", "我不喜欢你", "太糟糕了", "真是件令人伤心的事情"]
labels = [1, 1, 1, 0, 0, 0] # 1积极, 0消极.
class MyDataset(Data.Dataset):
def __init__(self, sentences, labels=None, with_labels=True,):
self.tokenizer = AutoTokenizer.from_pretrained(model)
self.with_labels = with_labels
self.sentences = sentences
self.labels = labels
def __len__(self):
return len(sentences)
def __getitem__(self, index):
# Selecting sentence1 and sentence2 at the specified index in the data frame
sent = self.sentences[index]
# Tokenize the pair of sentences to get token ids, attention masks and token type ids
encoded_pair = self.tokenizer(sent,
padding='max_length', # Pad to max_length
truncation=True, # Truncate to max_length
max_length=maxlen,
return_tensors='pt') # Return torch.Tensor objects
token_ids = encoded_pair['input_ids'].squeeze(0) # tensor of token ids
attn_masks = encoded_pair['attention_mask'].squeeze(0) # binary tensor with "0" for padded values and "1" for the other values
token_type_ids = encoded_pair['token_type_ids'].squeeze(0) # binary tensor with "0" for the 1st sentence tokens & "1" for the 2nd sentence tokens
if self.with_labels: # True if the dataset has labels
label = self.labels[index]
return token_ids, attn_masks, token_type_ids, label
else:
return token_ids, attn_masks, token_type_ids
train = Data.DataLoader(dataset=MyDataset(sentences, labels), batch_size=batch_size, shuffle=True, num_workers=1)
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.num_filter_total = num_filters * len(filter_sizes)
self.Weight = nn.Linear(self.num_filter_total, n_class, bias=False)
self.bias = nn.Parameter(torch.ones([n_class]))
self.filter_list = nn.ModuleList([
nn.Conv2d(1, num_filters, kernel_size=(size, hidden_size)) for size in filter_sizes
])
def forward(self, x):
# x: [bs, seq, hidden]
x = x.unsqueeze(1) # [bs, channel=1, seq, hidden]
pooled_outputs = []
for i, conv in enumerate(self.filter_list):
h = F.relu(conv(x)) # [bs, channel=1, seq-kernel_size+1, 1]
mp = nn.MaxPool2d(
kernel_size = (encode_layer-filter_sizes[i]+1, 1)
)
# mp: [bs, channel=3, w, h]
pooled = mp(h).permute(0, 3, 2, 1) # [bs, h=1, w=1, channel=3]
pooled_outputs.append(pooled)
h_pool = torch.cat(pooled_outputs, len(filter_sizes)) # [bs, h=1, w=1, channel=3 * 3]
h_pool_flat = torch.reshape(h_pool, [-1, self.num_filter_total])
output = self.Weight(h_pool_flat) + self.bias # [bs, n_class]
return output
# model
class Bert_Blend_CNN(nn.Module):
def __init__(self):
super(Bert_Blend_CNN, self).__init__()
self.bert = AutoModel.from_pretrained(model, output_hidden_states=True, return_dict=True)
self.linear = nn.Linear(hidden_size, n_class)
self.textcnn = TextCNN()
def forward(self, X):
input_ids, attention_mask, token_type_ids = X[0], X[1], X[2]
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) # 返回一个output字典
# 取每一层encode出来的向量
# outputs.pooler_output: [bs, hidden_size]
hidden_states = outputs.hidden_states # 13*[bs, seq_len, hidden] 第一层是embedding层不需要
cls_embeddings = hidden_states[1][:, 0, :].unsqueeze(1) # [bs, 1, hidden]
# 将每一层的第一个token(cls向量)提取出来,拼在一起当作textcnn的输入
for i in range(2, 13):
cls_embeddings = torch.cat((cls_embeddings, hidden_states[i][:, 0, :].unsqueeze(1)), dim=1)
# cls_embeddings: [bs, encode_layer=12, hidden]
logits = self.textcnn(cls_embeddings)
return logits
bert_blend_cnn = Bert_Blend_CNN().to(device)
optimizer = optim.Adam(bert_blend_cnn.parameters(), lr=1e-3, weight_decay=1e-2)
loss_fn = nn.CrossEntropyLoss()
# train
sum_loss = 0
total_step = len(train)
for epoch in range(epoches):
for i, batch in enumerate(train):
optimizer.zero_grad()
batch = tuple(p.to(device) for p in batch)
pred = bert_blend_cnn([batch[0], batch[1], batch[2]])
loss = loss_fn(pred, batch[3])
sum_loss += loss.item()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print('[{}|{}] step:{}/{} loss:{:.4f}'.format(epoch+1, epoches, i+1, total_step, loss.item()))
train_curve.append(sum_loss)
sum_loss = 0
# test
bert_blend_cnn.eval()
with torch.no_grad():
test_text = ['我不喜欢打篮球']
test = MyDataset(test_text, labels=None, with_labels=False)
x = test.__getitem__(0)
x = tuple(p.unsqueeze(0).to(device) for p in x)
pred = bert_blend_cnn([x[0], x[1], x[2]])
pred = pred.data.max(dim=1, keepdim=True)[1]
if pred[0][0] == 0:
print('消极')
else:
print('积极')
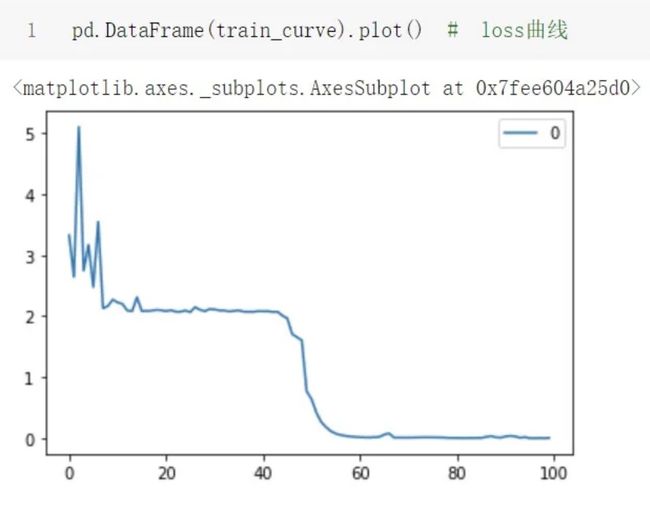
pd.DataFrame(train_curve).plot() # loss曲线2.4 测试结果及代码链接
测试单条样本结果:

loss曲线:
代码链接:
BERT-Blend-CNNjupyter版本[4]
BERT-Blend-CNNpytorch版本[5]
参考资料
[1]
《The Illustrated Transformer》: https://jalammar.github.io/illustrated-transformer/
[2]BERT文本分类jupyter版本: https://github.com/PouringRain/blog_code/blob/main/nlp/bert_classify.ipynb
[3]BERT文本分类pytorch版本: https://github.com/PouringRain/blog_code/blob/main/nlp/bert_classify.py
[4]BERT-Blend-CNNjupyter版本: https://github.com/PouringRain/blog_code/blob/main/nlp/Bert_Blend_CNN.ipynb
[5]BERT-Blend-CNNpytorch版本: https://github.com/PouringRain/blog_code/blob/main/nlp/bert_blend_cnn.py
文章来源:https://www.zhihu.com/people/sheng-jian-93-86
作者:盛小贱吖
编辑:@公众号 AI算法小喵
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
苏州大学NLP团队文本生成&预训练方向招收研究生/博士生(含直博生)
NIPS'22 | 重新审视区域视觉特征在基于知识的视觉问答中的作用
武汉大学提出:用于基于统一Aspect的情感分析的关系感知协作学习
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~