Bootstrapping的意义
一、原理解释
Bootstrapping 方法是种集成方法,通俗解释就是盲人摸象,很多盲人摸一头象,各自摸到的都不一样,但是都比较片面,当他们在一起讨论时,就得到了象的整体。
Bootstrap的过程,类似于重采样,如下图所示:
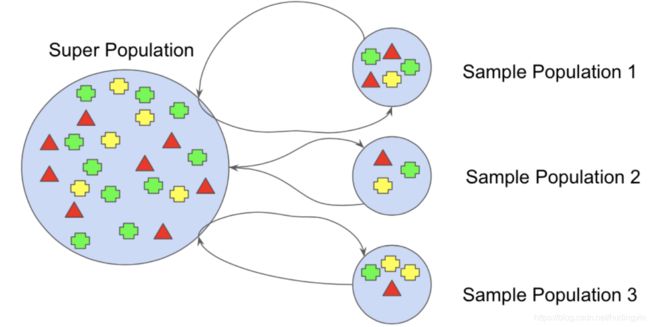
对于小数据集的鲁棒性特别有用。
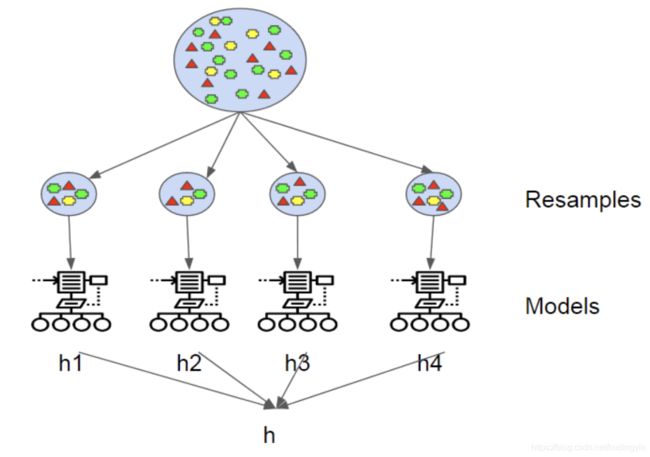
每个模型得到一些结果之后,bagging方法最后是取均值或投票,来确定最后的模型参数(这样合理吗?),如下图所示:
在另一种集群方法中,bootstrap方法是串联型的,如下图所示
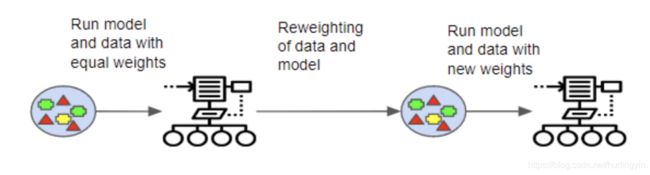
二、Adaboost实践
Adaboost类库在scikit-learn中,有两个,分别是AdaboostClassifier和AdaboostRegressor两个,从名字就可以看出,一个用于分类,一个用于回归。
- 载入库类
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
- 生成一些随机数据来做二元分类
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征,协方差系数为2
X1, y1 = make_gaussian_quantiles(cov=2.0,n_samples=500, n_features=2,n_classes=2, random_state=1)
# 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3,协方差系数为2
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,n_samples=400, n_features=2, n_classes=2, random_state=1)
#讲两组数据合成一组数据
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
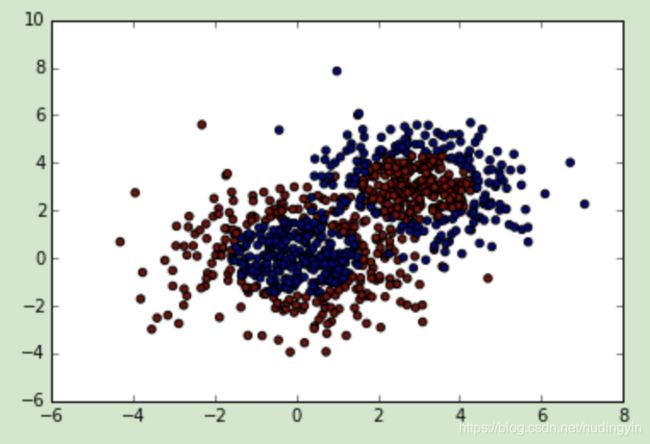
- 数据可视化
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
4. 基于决策树的Adaboost来做分类拟合,这里我们选择了SAMME算法,最多200个弱分类器,步长0.8,在实际运用中你可能需要通过交叉验证调参而选择最好的参数。拟合完了后,我们用网格图来看看它拟合的区域。
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5),
algorithm="SAMME",
n_estimators=200, learning_rate=0.8)
bdt.fit(X, y)
- 可视化输出数据
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
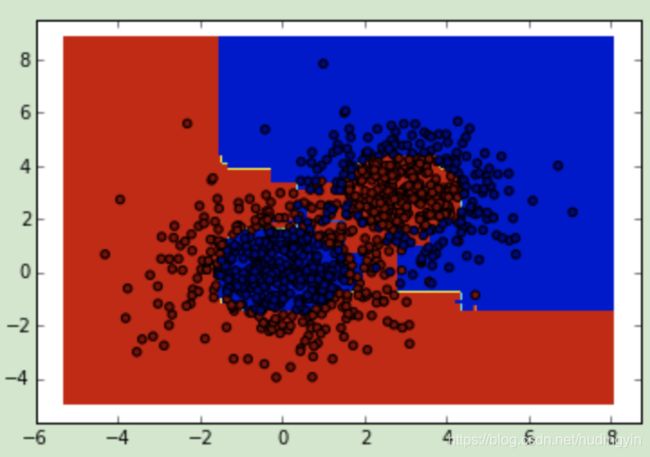
- 从图中可以看出,Adaboost的拟合效果还是不错的,现在我们看看拟合分数:
print "Score:", bdt.score(X,y)
Score: 0.913333333333
也就是说拟合训练集数据的分数还不错。当然分数高并不一定好,因为可能过拟合。
- 现在我们将最大弱分离器个数从200增加到300。再来看看拟合分数。
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5),
algorithm="SAMME",
n_estimators=300, learning_rate=0.8)
bdt.fit(X, y)
print "Score:", bdt.score(X,y)
此时的输出为Score: 0.962222222222
这印证了我们前面讲的,弱分离器个数越多,则拟合程度越好,当然也越容易过拟合。
- 现在我们降低步长,将步长从上面的0.8减少到0.5,再来看看拟合分数。
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5),
algorithm="SAMME",
n_estimators=300, learning_rate=0.5)
bdt.fit(X, y)
print "Score:", bdt.score(X,y)
此时的输出为:
Score: 0.894444444444
可见在同样的弱分类器的个数情况下,如果减少步长,拟合效果会下降。
- 最后我们看看当弱分类器个数为700,步长为0.7时候的情况:
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5),
algorithm="SAMME",
n_estimators=600, learning_rate=0.7)
bdt.fit(X, y)
print "Score:", bdt.score(X,y)
此时的输出为:
Score: 0.961111111111
此时的拟合分数和我们最初的300弱分类器,0.8步长的拟合程度相当。也就是说,在我们这个例子中,如果步长从0.8降到0.7,则弱分类器个数要从300增加到700才能达到类似的拟合效果。
注:在深度学习中,由于神经网络已经够大,所以不建议进行bootstrapping操作,没什么特别的意义和作用。