second.pytorch安装踩坑实录
写在前面
下载的时候一定要注意second.pytorch的版本,不然安装完spconv后,尝试Kitti Viewer Web的时候可能会一直报错“cannot import name 'rbbox_intersection'”,附上没有此问题的代码仓库:https://github.com/traveller59/second.pytorch/tree/v1.5.1
后续我又尝试了second.pytorch1.6版本,附上仓库链接:https://github.com/traveller59/second.pytorch,当我安装成功spconv1.2之后准备训练时,总是报错cannot import name 'non_max_suppression' from 'spconv.utils',暂时没有解决办法。。后面又新建conda环境从新来过,pytorch1.3.1,torch0.4.2,开始并不行。报错libcudart.so.9.0: cannot open shared object file: No such file or directory,这里说torchvision版本不对,换成0.2.2,也不行。又pip install torchvision==0.4.2换回来。然后重新clone了仓库,改了改数据路径,居然能跑了。唉,跑吧,反正可以抓耗子了。。。
安装步骤
安装
- 克隆代码
###如果克隆失败,可以手动进入仓库网址下载,再上传服务器### git clone https://github.com/traveller59/second.pytorch/tree/v1.5.1 cd ./second.pytorch/second ###这里是1.6版本,由于需要使用pointpillars,我又踩了一遍坑 git clone https://github.com/traveller59/second.pytorch cd ./second.pytorch/second - 安装依赖包(对1.6版本和1.5.1版本都是一样的)
###如果有Anaconda### conda install scikit-image scipy numba pillow matplotlib pip install fire tensorboardX protobuf opencv-python ###如果没有Anaconda### pip install numba scikit-image scipy pillow pip install fire tensorboardX protobuf opencv-python - 安装spconv
参考我的博客安装spconv踩坑实录,这里需要注意,如果使用second.pytorch1.6版本,需要安装spconv1.2。second.pytorch1.5.1对应spconv1.0 - 设置环境变量(
需要换成你自己second.pytorch1.6版本或者second.pytorch-1.5.1的所在路径) export NUMBAPRO_CUDA_DRIVER=/usr/lib/x86_64-linux-gnu/libcuda.so export NUMBAPRO_NVVM=/usr/local/cuda/nvvm/lib64/libnvvm.so export NUMBAPRO_LIBDEVICE=/usr/local/cuda/nvvm/libdevice ###如果用的是1.6版本,添加下面这行 export PYTHONPATH=/second.pytorch:$PYTHONPATH ###如果用的是1.5.1版本,添加下面这行 export PYTHONPATH= /second.pytorch-1.5.1:$PYTHONPATH
准备数据集
问题记录
1. ModuleNotFoundError: No module named 'second.core.point_cloud'
在create_data.py中搜索发现并没有用到下面这行导入的bound_points_jit,直接注释掉即可。
#from second.core.point_cloud.point_cloud_ops import bound_points_jit2.image file is truncated
我下载了kitti 3D目标检测数据集之后,解压的时候发现test集中有一张000683是损坏的,从test.txt中将此序号删除,该编号对应的calib和velodyne中的文件也一并删除,但是删除后仍然报错image file is truncated,参考这里,在create_data.py的开头添加了两行如下,问题解决。
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True目录结构
└── KITTI_DATASET_ROOT <-- 在second/data/目录下
├── training <-- 7481 train data
| ├── image_2 <-- for visualization
| ├── calib
| ├── label_2
| ├── velodyne
| └── velodyne_reduced <-- empty directory
└── testing <-- 7517 test data
├── image_2 <-- for visualization
├── calib
├── velodyne
└── velodyne_reduced <-- empty directory1.1.5.1版本做如下操作
###创建kitti infos
python create_data.py create_kitti_info_file --data_path=data/KITTI_DATASET_ROOT
###创建reduced point cloud
python create_data.py create_reduced_point_cloud --data_path=data/KITTI_DATASET_ROOT
###创建groundtruth数据库信息
python create_data.py create_groundtruth_database --data_path=data/KITTI_DATASET_ROOT2.1.6版本做如下操作
python create_data.py kitti_data_prep --root_path=data/KITTI_DATASET_ROOT3.修改配置信息
second/configs中有每个训练参数文件的配置。打开文件找到下面对应的部分,将数据路径修改成自己的数据路径即可,比如我的是''../data/KITTI_DATASET_ROOT/dataset_infos_train.pkl''。
train_input_reader: {
...
database_sampler {
database_info_path: "/path/to/dataset_dbinfos_train.pkl"
...
}
dataset: {
dataset_class_name: "DATASET_NAME"
kitti_info_path: "/path/to/dataset_infos_train.pkl"
kitti_root_path: "DATASET_ROOT"
}
}
...
eval_input_reader: {
...
dataset: {
dataset_class_name: "DATASET_NAME"
kitti_info_path: "/path/to/dataset_infos_val.pkl"
kitti_root_path: "DATASET_ROOT"
}
}尝试Kitti Viewer Web
问题记录
1.如果使用的是1.5.1版本,先修改backend.py中的一行代码,否则会出现加载数据失败的问题。
#将以下代码
app.run(host='127.0.0.1', threaded=True, port=port)
#改为
app.run(host='0.0.0.0', threaded=True, port=port)2.版本1.6报错RuntimeError: Working outside of request context.根据报错位置,将/home/gye/anaconda3/envs/pointpillars/lib/python3.7/site-packages/werkzeug/local.py的306行return self.__local()的括号去掉
#将return self.__local()改为
return self.__local
步骤
- 服务器上运行一下命令backend.py(端口号默认是为16666)
#1.5.1版本运行(端口号默认是16666) python backend.py main #1.6版本运行,1.6暂时有点问题,不能正确显示,搞好了再回来填坑 python main.py main
- 服务器上启动Web服务器
python -m http.server
- 本机连接服务器指定端口(servername和serverIP分别是你的服务器用户名和IP)
ssh -L xxxx:0.0.0.0:8000 servername@serverIP
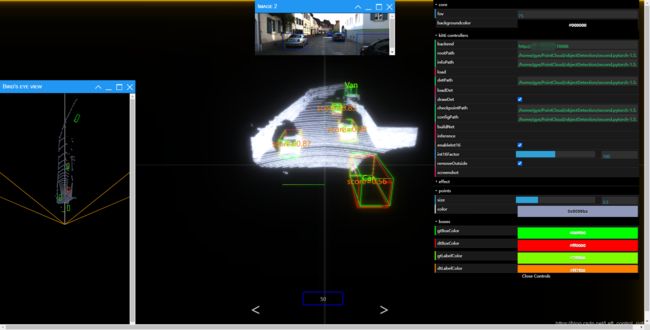
- 本机浏览器打开网页http://127.0.0.1:16666(不要刷新这个网页,我刷新了一次就崩溃了,然后从头来过。。。)打开界面之后,在右侧输入自己文件所对应的路径,下面是我的路径。
backend:http://serverIP:16666 rootPath:/home/gye/PointCloud/objectDetection/second.pytorch-1.5.1/second/data/KITTI_DATASET_ROOT infoPath:/home/gye/PointCloud/objectDetection/second.pytorch-1.5.1/second/data/KITTI_DATASET_ROOT/kitti_infos_val.pkl load DetPath:/home/gye/PointCloud/objectDetection/second.pytorch-1.5.1/second/pytorch/allKindsOutput/results/step_74240/result.pkl loadDet checkpointPath:/home/gye/PointCloud/objectDetection/second.pytorch-1.5.1/second/pytorch/allKindsOutput/voxelnet-74240.tckpt configPath:/home/gye/PointCloud/objectDetection/second.pytorch-1.5.1/second/configs/all.fhd.config buildNet inference - 路径补全之后,依次点击load等按钮即可。我的在最后inference的时候报了inference fail的错误,但是尝试点击下一张时,能正常显示ground truth和预测框,没有去深究。
附录
另一位博主的全套配置史
https://blog.csdn.net/r1141207831/article/details/103756292