百度BML-飞桨服务器以及Jetson nano部署实战案例(下)
百度BML-飞桨服务器以及Jetson nano部署实战案例(下)
这次我们直接把模型部署到公有云和Jetson nano的实战训练,首先说下用的是公有云部署,然后再说下Jetson nano。首先说下这里采用的百度的公有的服务器的部署,因为我自己是没买服务器资源的,所以这里就使用百度的公有云。
第二个是自己的端侧设备部署,可以有很多的选择,百度自己家的硬件会好部署一些,但是这里还是考虑到大多数人都是使用自己的一些端侧设备,所以这次就拿Jetson nano来部署为案例。
在这里具体模型怎么训练、数据怎么标注、怎么调参这里就不具体来写了,可以看下我前面写的博客,这里直接拿一个已经训练好的模型来进行部署。
公有云部署
首先这个平台主要是在百度BML平台训练,因为我手上没有显卡,所以通过他门的平台的云资源显卡,首先需要登录BML平台,首先我们直接跳到模型部署这部,我们的训练好的模型已经在模型仓库里面了。
然后我们随便挑选一个训练好的模型
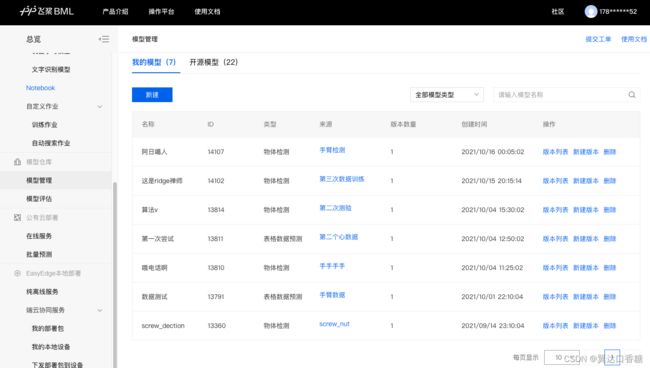
点右侧的版本列表,可以进入到如下的界面
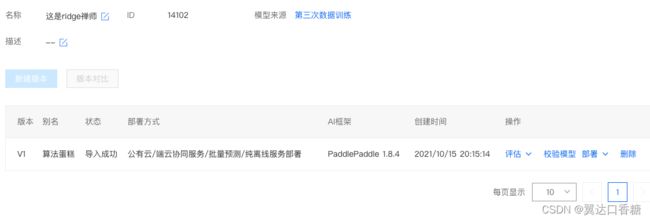
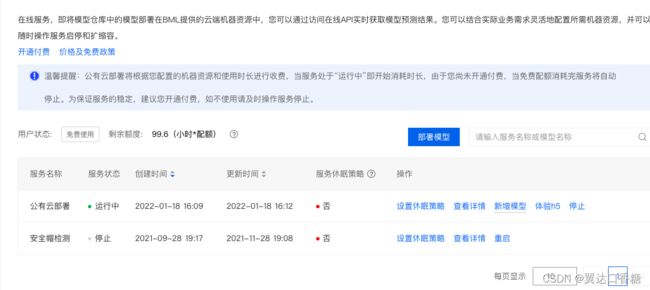
现在支持的部署方式主要有在线服务(公有云)、端云协同服务部署、批量预测、纯离线服务(端侧部署)
四类部署

点开在线服务,因为这里我们没有自己的服务器,使用的是百度的云服务器,但是给点钱。接口地址可以填上自己的服务器,在下面我们写下怎么自己申请百度的公有云接口。
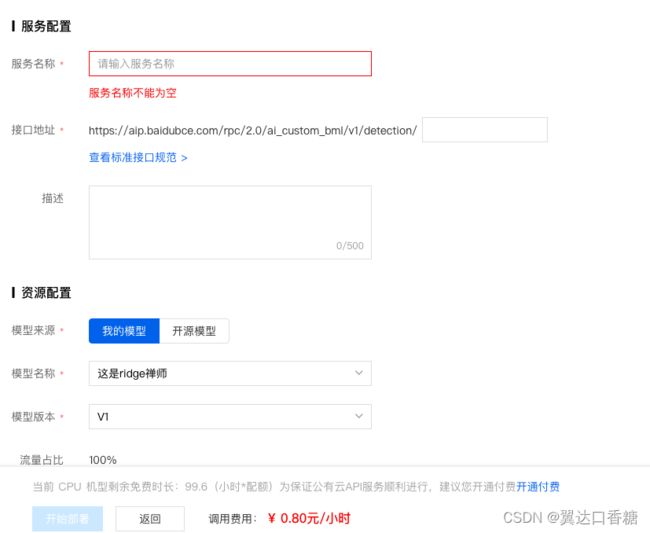
下面还有部署的服务器的资源,越好肯定价格越高。

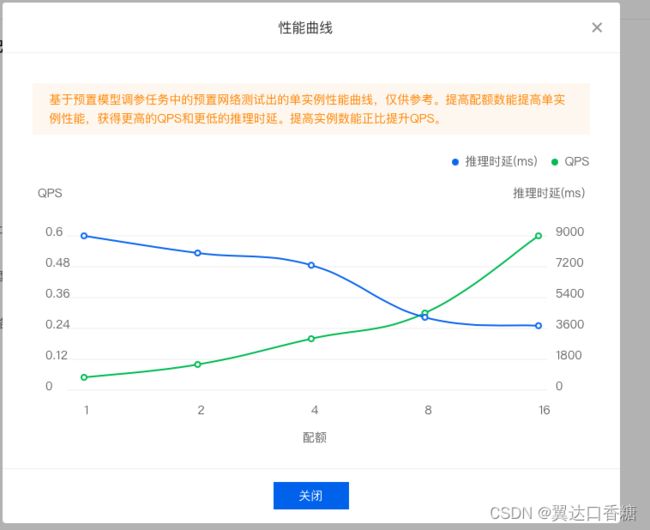
点击查看性能曲线还可以查看资源的延时和QPS。
怎么去开一个自己的公有云接口,首先需要点开自己的头像,然后你会进入到个人中心,点开左侧列表,那里有个全功能AI开发平台BML,点进去就可以看到下面那个页面。

在在线服务中找到应用列表,点个创建应用,然后开始申请用一个公有云服务器。
应用归属写个人,其他的就是补充一些自定义资料,然后就可以
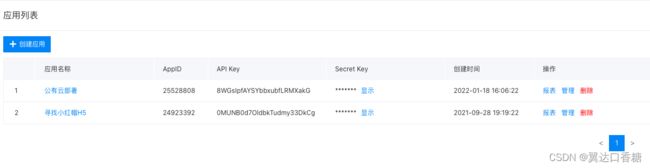
然后可以获得一个AppID,把这个填入到上面的借口地址中,就可以调用百度的公有云服务器。
部署完后就可以运行了,这样子就完成了一次公有云部署。
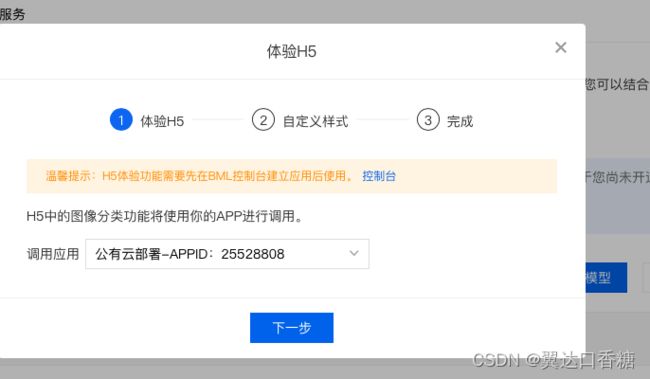
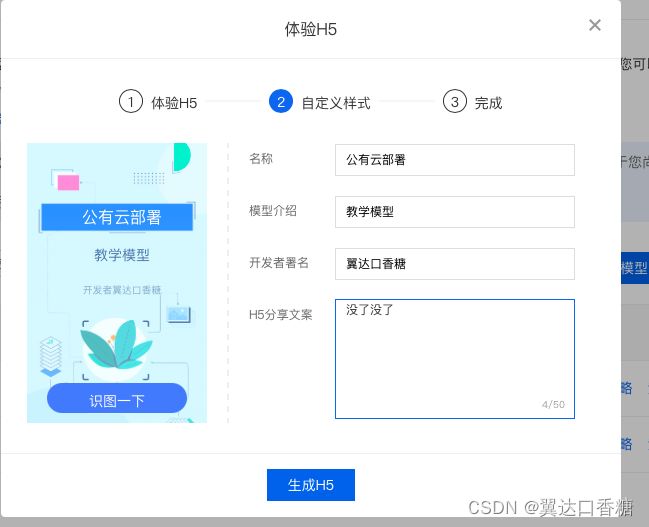
一旁有一个体验H5,你可以设置一个二维码,让人可以在线使用这个莫心,比如说你做了个质量检测的模型,然后你把二维码给了别人以后别人扫下二维码上传照片就可以在线质检。

上面的公有云部署比较简单,接下来说下端侧部署,这个复杂一些。以Jetson nano为例子,当然这里不限于这个,飞桨事实上可以更多的是部署在像win、OS、Linux和MIPS、X86、ARM等诸多环境都是完全没问题
纯离线端侧部署
首先我们可以点开纯离线部署
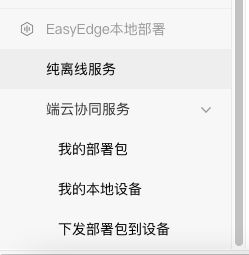
然后你会发现有服务器(私有API和服务器端SDK)、通用小型设备(我们用的是这个)、专项适配配件三种
私有API是以docker的形式部署在本地服务器上,目的是为了和公有云的显示进行兼容,相关的硬件包括有GPU 和CPU。
另一个SDK是把模型
封装成适配本地的SDK,可以供用户进行二次开发,非常灵活
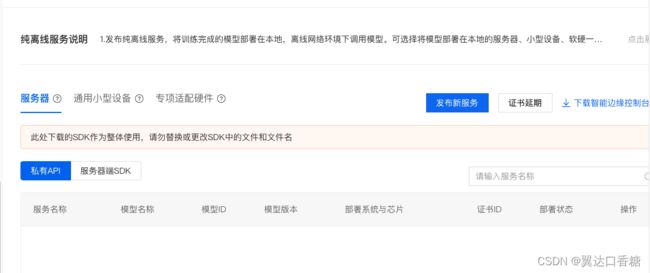
这是第一种,服务器部署,基本上和各大厂商都兼容
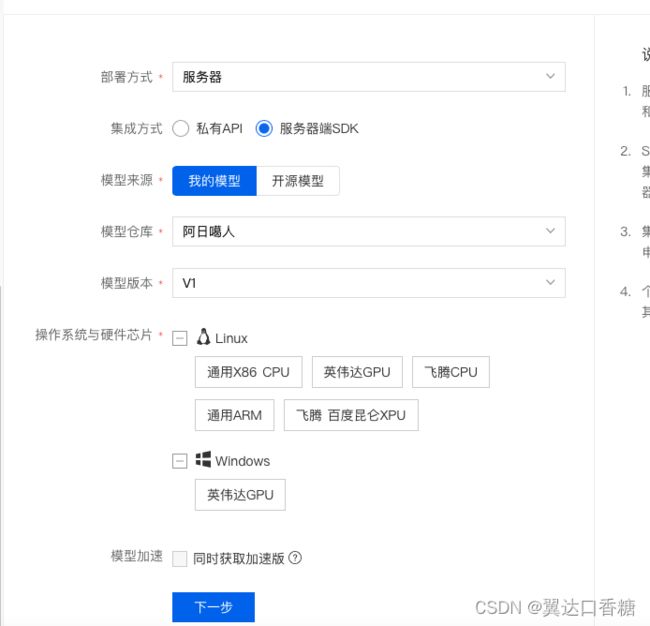
第二种是通用小型设备
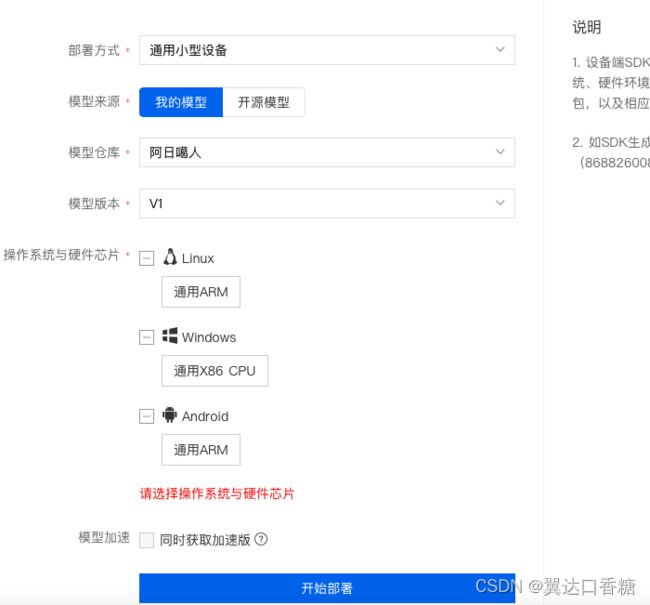
第三种是百度自家的硬件,我也没有就不看了。
我们针对第二个通用小型设备进行部署。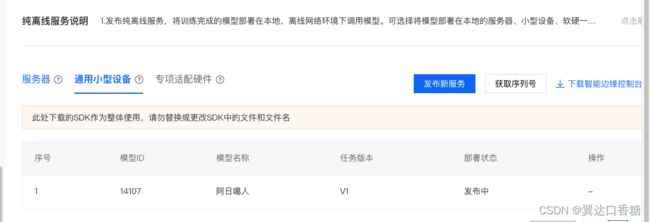
点击部署后,你可以看到正在发布中
好,接下来我们上我们自己的Jetson nano,

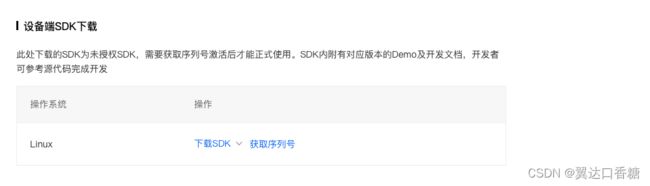
这里有两个选择,一个下载SDK,这个可以获取zip 压缩包,另一个是获取序列号,用于激活。你可以这么理解,就是你在百度这边训练模型后做出一个压缩包,然后下载到设备中去,解压后在部署过程中你得用序列号去激活,第一次使用要联网激活。然后官方在这里收取一定的费用。
这里我们使用的是独立的jetson nano ,但是工业上一般都是不用屏幕的,一般都是把设备作为电脑的随从设备去调的。这里用这套的东西给配了屏幕和键盘是我自己学习用的哈哈哈。
由于屏幕太小了Linux截图互传太麻烦,所以这里直接用官方的代码就不截图了。


安装 paddlepaddle
使用x86_64 CPU 基础版预测时必须安装:
pip3 install -U paddlepaddle==1.8.5
大家看版本,下面这个版本没问题,可以随时更新最新的版本
使用NVIDIA GPU 基础版预测时必须安装:
pip3 install -U paddlepaddle-gpu==1.8.5.post107
pip3 install -U paddlepaddle-gpu==1.8.5.post97
同时有几个注意的地方:
如果你使用的是Nvidia GPU 加速版预测时必须安装cuda、cudnn。 依赖的版本为 cuda9.0、cudnn7。版本号必须正确。
安装 pytorch(torch >= 1.7.0)
目标跟踪模型的预测必须安装pytorch版本1.7.0及以上(包含:Nvidia GPU 基础版、x86_64 CPU 基础版)。
目标跟踪模型Nvidia GPU 基础版也需安装依赖cuda、cudnn。
关于不同版本的pytorch和CUDA版本的对应关系:pytorch官网 目标跟踪模型还有一些列举在requirements.txt里的依赖(包括torch >= 1.7.0),均可使用pip下载安装。
pip3 install -r requirements.txt
- 安装 easyedge python wheel 包
pip3 install -U BaiduAI_EasyEdge_SDK-{版本号}-cp36-cp36m-linux_x86_64.whl
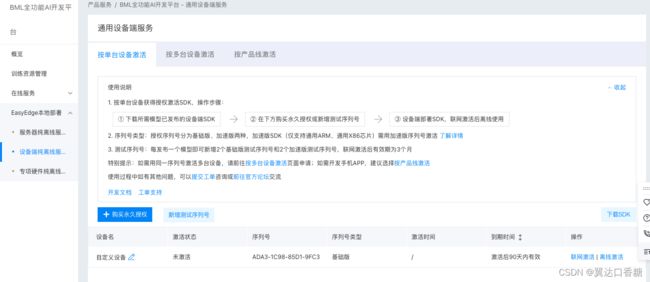
接下里就是使用序列号激活啦,这个需要点开上面的那个获取序列号,然后选择联网激活,那里有一个序列号的号码,等会就用。

修改demo.py 填写序列号
pred = edge.Program()
pred.set_auth_license_key("这里填写序列号")
然后接下来是测试 Demo
图片预测的话是需要找到你要输入对应的模型文件夹(默认为RES)和测试图片路径,运行:
python3 demo.py {model_dir} {image_name.jpg}
除此之外也可以试下视频预测,
输入对应的模型文件夹(默认为RES)和测试视频文件路径 / 摄像头id / 网络视频流地址
video_type指的是输入源类型,主要有本地视频文件、摄像头的index、网络视频流
video_src里面写的是输入源地址,如视频文件路径、摄像头index等等
然后运行下面这个代码
python3 demo.py {model_dir} {video_type} {video_src}
就可以跑起来了
在联网的状态的下你甚至可以直接在电脑端登录来用我们的模型
- 测试Demo HTTP 服务
输入对应的模型文件夹(默认为RES)、序列号、设备ip和指定端口号,运行:
python3 demo_serving.py {model_dir} {serial_key} {host, default 0.0.0.0} {port, default 24401}
然后就会显示:
Running on http://0.0.0.0:24401/
字样,此时,开发者可以打开浏览器,http://{设备ip}:24401,选择图片或者视频来进行测试。
详细的使用代码说明
demo.py
import BaiduAI.EasyEdge as edge
pred = edge.Program()
pred.set_auth_license_key("这里填写序列号")
pred.init(model_dir={RES文件夹路径}, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID)
pred.infer_image({numpy.ndarray的图片})
pred.close()
demo_serving.py
import BaiduAI.EasyEdge as edge
from BaiduAI.EasyEdge.serving import Serving
server = Serving(model_dir={RES文件夹路径}, license=serial_key)
# 请参考同级目录下demo.py里:
# pred.init(model_dir=xx, device=xx, engine=xx, device_id=xx)
# 对以下参数device\device_id和engine进行修改
server.run(host=host, port=port, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID)
初始化
接口
def init(self,
model_dir,
device=Device.LOCAL,
engine=Engine.PADDLE_FLUID,
config_file='conf.json',
preprocess_file='preprocess_args.json',
model_file='model',
params_file='params',
graph_file='graph.ncsmodel',
label_file='label_list.txt',
device_id=0
):
"""
Args:
device: Device.CPU
engine: Engine.PADDLE_FLUID
model_dir: str
model dir
preprocess_file: str
model_file: str
params_file: str
graph_file: str
label_file: str
device_id: int
Raises:
RuntimeError, IOError
Returns:
bool: True if success
"""
使用 NVIDIA GPU 预测时,必须满足:
机器已安装 cuda, cudnn
已正确安装对应 cuda 版本的 paddle 版本
通过设置环境变量FLAGS_fraction_of_gpu_memory_to_use设置合理的初始内存使用比例
使用 CPU 预测时,可以通过在 init 中设置 thread_num 使用多线程预测。如:
pred.init(model_dir=_model_dir, device=edge.Device.CPU, engine=edge.Engine.PADDLE_FLUID, thread_num=1)
预测图像
接口
快捷键目录标题文本样式列表链接代码片表格注脚注释自定义列表LaTeX 数学公式插入甘特图插入UML图插入Mermaid流程图插入Flowchart流程图插入类图
代码片复制
下面展示一些 内联代码片。
// A code block
var foo = 'bar';
def infer_image(self, img,
threshold=0.3,
channel_order='HWC',
color_format='BGR',
data_type='numpy'):
"""
Args:
img: np.ndarray or bytes
threshold: float
only return result with confidence larger than threshold
channel_order: string
channel order HWC or CHW
color_format: string
color format order RGB or BGR
data_type: string
image data type
Returns:
list
"""

x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
可以参考 demo 文件中使用 opencv 绘制矩形的逻辑。
结果示例
i) 图像分类
{
“index”: 736,
“label”: “table”,
“confidence”: 0.9
}
ii) 物体检测
{
“y2”: 0.91211,
“label”: “cat”,
“confidence”: 1.0,
“x2”: 0.91504,
“index”: 8,
“y1”: 0.12671,
“x1”: 0.21289
}
iii) 图像分割
{
“name”: “cat”,
“score”: 1.0,
“location”: {
“left”: …,
“top”: …,
“width”: …,
“height”: …,
},
“mask”: …
}
mask字段中,data_type为numpy时,返回图像掩码的二维数组
{
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
}
其中1代表为目标区域,0代表非目标区域
data_type为string时,mask的游程编码,解析方式可参考 demo
预测视频(目前仅限目标跟踪模型调用)
接口
def infer_frame(self, frame, threshold=None):
"""
视频推理(抽帧之后)
:param frame:
:param threshold:
:return:
"""
