71.转置卷积以及代码实现
到目前为止,我们所见到的卷积神经网络层,通常会减少下采样输入图像的空间维度(高和宽)。如果输入和输出图像的空间维度相同,在以像素级分类的语义分割中将会很方便。 例如,输出像素所处的通道维可以保有输入像素在同一位置上的分类结果。
为了实现这一点,尤其是在空间维度被卷积神经网络层缩小后,我们可以使用另一种类型的卷积神经网络层,它可以增加上采样中间层特征图的空间维度。 本节将介绍 转置卷积(transposed convolution), 用于逆转下采样导致的空间尺寸减小。
1. 转置卷积
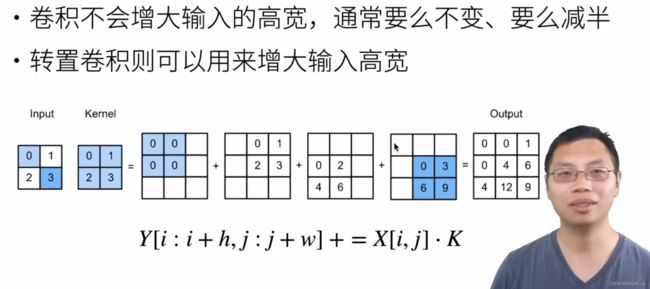
2. 为什么称之为“转置”
3. 重新排列输入和核
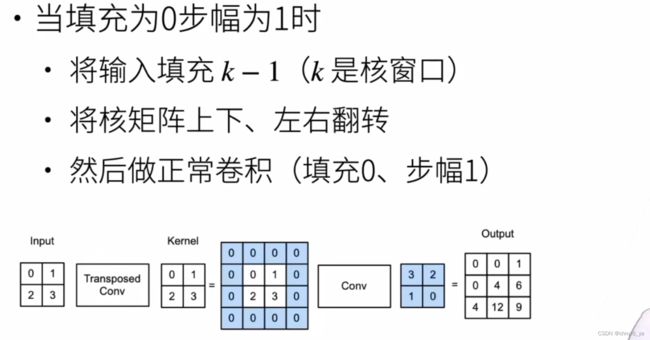
接下来看一个复杂一点的:

再考虑一个一般情况的例子:
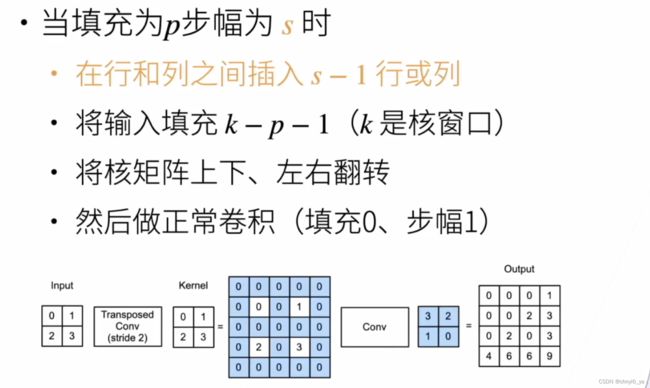
4. 形状换算

在FCN中p=16的原因就是依据k=2p+s,且s=32,k=64。
5. 同反卷积的关系

5. 总结
- 转置卷积是一种变化了输入和核的卷积,来得到上采样的目的
- 不同于数学上的反卷积操作
6. 代码实现
import torch
from torch import nn
from d2l import torch as d2l
6.1 基本操作
让我们暂时忽略通道,从基本的转置卷积开始,设步幅为1且没有填充。 假设我们有一个 ℎ× 的输入张量和一个 ℎ× 的卷积核。 以步幅为1滑动卷积核窗口,每行 次,每列 ℎ 次,共产生 ℎ 个中间结果。 每个中间结果都是一个 (ℎ+ℎ−1)×(+−1) 的张量,初始化为0。 为了计算每个中间张量,输入张量中的每个元素都要乘以卷积核,从而使所得的 ℎ× 张量替换中间张量的一部分。 请注意,每个中间张量被替换部分的位置与输入张量中元素的位置相对应。 最后,所有中间结果相加以获得最终结果。
例如,下图解释了解释了如何为 2×2 的输入张量计算卷积核为 2×2 的转置卷积。
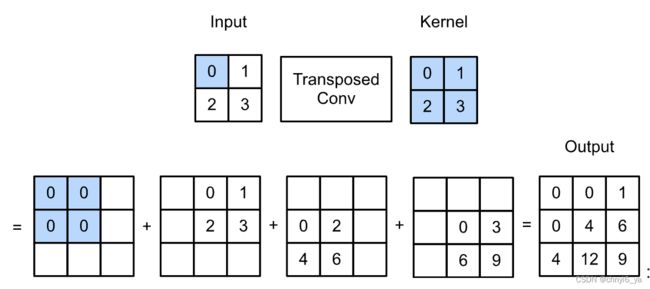
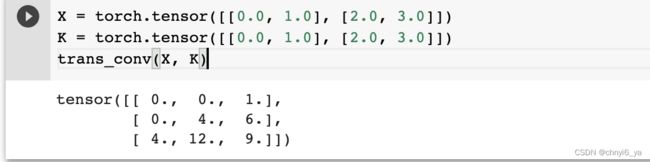
我们可以对输入矩阵X和卷积核矩阵K(实现基本的转置卷积运算)trans_conv:
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
与通过卷积核“减少”输入元素的常规卷积相比,转置卷积通过卷积核“广播”输入元素,从而产生大于输入的输出。 我们可以通过构建输入张量X和卷积核张量K从而验证上述实现输出。 此实现是基本的二维转置卷积运算。
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
trans_conv(X, K)
运行结果:
或者,当输入X和卷积核K都是四维张量时,我们可以使用高级API获得相同的结果。
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
tconv(X)
运行结果:

6. 2填充、步幅和多通道
与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。 例如,当将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv.weight.data = K
tconv(X)
运行结果:

在转置卷积中,步幅被指定为中间结果(输出),而不是输入。 将步幅从1更改为2会增加中间张量的高和权重。
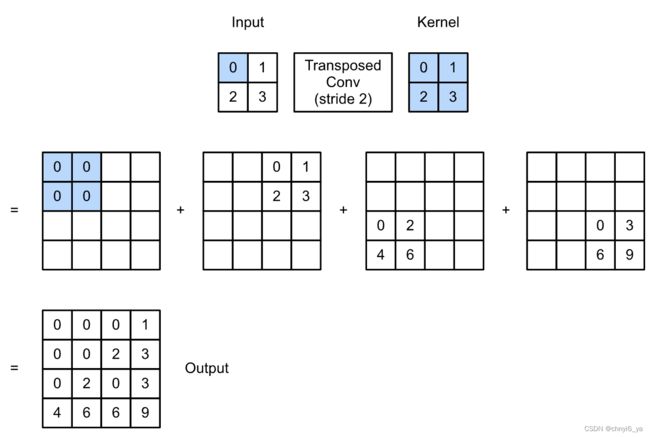
以下代码可以验证图中步幅为2的转置卷积的输出。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
tconv.weight.data = K
tconv(X)
运行结果:

(图高+核高-步长) x 步长 ,正好与卷积输出的公式的符号全相反
对于多个输入和输出通道,转置卷积与常规卷积以相同方式运作。 假设输入有 个通道,且转置卷积为每个输入通道分配了一个 ℎ× 的卷积核张量。 当指定多个输出通道时,每个输出通道将有一个 ×ℎ× 的卷积核。
同样,如果我们将 代入卷积层 来输出 =() ,并创建一个与 具有相同的超参数、但输出通道数量是 中通道数的转置卷积层 ,那么 () 的形状将与 相同。 下面的示例可以解释这一点。
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
tconv(conv(X)).shape == X.shape
运行结果:

6.3 与矩阵变换的联系
转置卷积为何以矩阵变换命名呢? 让我们首先看看如何使用矩阵乘法来实现卷积。 在下面的示例中,我们定义了一个 3×3 的输入X和 2×2 卷积核K,然后使用corr2d函数计算卷积输出Y。
X = torch.arange(9.0).reshape(3, 3)
K = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
Y = d2l.corr2d(X, K)
Y
运行结果:

接下来,我们将卷积核K重写为包含大量0的稀疏权重矩阵W。 权重矩阵的形状是( 4 , 9 ),其中非0元素来自卷积核K。
def kernel2matrix(K):
k, W = torch.zeros(5), torch.zeros((4, 9))
k[:2], k[3:5] = K[0, :], K[1, :]
W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k
return W
W = kernel2matrix(K)
W
运行结果:

逐行连结输入X,获得了一个长度为9的矢量。 然后,W的矩阵乘法和向量化的X给出了一个长度为4的向量。 重塑它之后,可以获得与上面的原始卷积操作所得相同的结果Y:我们刚刚使用矩阵乘法实现了卷积。
Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)
运行结果:

我的理解如下:
同样,我们可以使用矩阵乘法来实现转置卷积。 在下面的示例中,我们将上面的常规卷积 2×2 的输出Y作为转置卷积的输入。 想要通过矩阵相乘来实现它,我们只需要将权重矩阵W的形状转置为 (9,4) 。
Z = trans_conv(Y, K)
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3)
运行结果:

可以得出:在正向卷积时,是3x3的矩阵和2x2的核做卷积操作,得到2x2的输出。而在做反向卷积时,把上面正向卷积的输出当作输入为2x2,和2x2的转置卷积,就能得到3x3的输出,这个输出和正向卷积的输入形状一样。但是要注意:数值不同!

7. Q&A
Q1:转置卷积是为了还原图片吗?
A1:不是的,转置卷积是为了用在语义分割上,预测每一个像素对应的标号,而不是去得到每个像素对应的RGB值。
Q2:卷积不断做压缩提取特征,然后用转置卷积恢复到与输出大小一样,这样局部信息不都丢掉了吗?
A2: 卷积不断做压缩提取特征,空间分辨率是变小了,但是通道数变多了,因此总的来说没有丢失掉很多信息。如果还原,也可以减小通道数,增大feature map的高宽。
Q3:卷积+转置卷积 是不是有一点 encoder-decoder的感觉?
A3:是的,可以这么理解。
Q4:转置卷积核PixShuffle上采样有区别吗?
A4:转置卷积不是做上采样,它只是为了得到像素级的输出而已。