PyTorch-Kaldi工具箱简介及核心代码注解
PyTorch-Kaldi简介
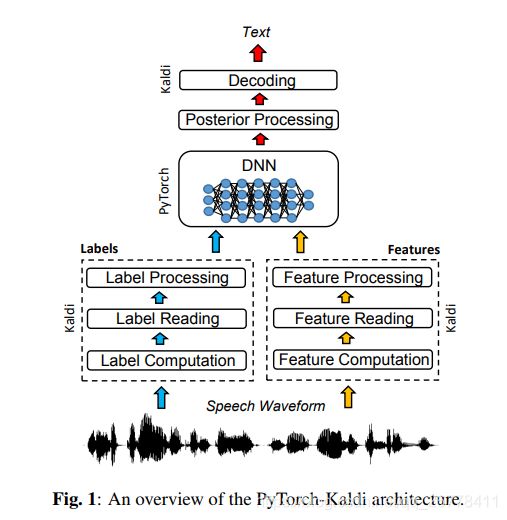
PyTroch-Kaldi是一款新推出的语音识别工具箱。由名字可以看出来,它是pytroch和kaldi的混合体。由于Kaldi内部的DNN拓展性较差(若需要添加新的网络Component,需要自己添加propagate和backpropagate),所以作者构建了一个PyTroch-Kaldi工具箱,工具箱的框架如下图所示。
该工具箱依然使用DNN-HMM混合模型进行声学模型的建模,但其DNN部分由Pytorch实现,而特征提取、标签/对齐计算和和解码则使用依旧使用Kaldi完成。这大大简化了声学模型中DNN的构造难度。
该项目在Github上的地址为:项目地址
arxiv上论文地址为:论文地址
PyTorch-Kaldi核心逻辑
PyTorch-Kaldi的核心逻辑如下图所示。图中的虚线框表示一个Python文件。虚线箭头表示某步需要一个调用一个新的Python文件。

核心代码注释
为了更为全面的理解PyTorch-Kaldi的代码逻辑、方便进行大家对框架进行修改,这里选取了一些PyTorch-Kaldi中最重要的代码进行了注释。下列代码的注释可以直接点击百度云链接进行下载。
run_exp.py
# Reading global cfg file (first argument-mandatory file)
cfg_file=sys.argv[1]
if not(os.path.exists(cfg_file)):
sys.stderr.write('ERROR: The config file %s does not exist!\n'%(cfg_file))
sys.exit(0)
else:
config = configparser.ConfigParser()
config.read(cfg_file)
# Reading and parsing optional arguments from command line (e.g.,--optimization,lr=0.002)
[section_args,field_args,value_args]=read_args_command_line(sys.argv,config)
# Output folder creation
out_folder=config['exp']['out_folder']
if not os.path.exists(out_folder):
os.makedirs(out_folder+'/exp_files')
# Log file path
log_file=config['exp']['out_folder']+'/log.log'
# Read, parse, and check the config file
cfg_file_proto=config['cfg_proto']['cfg_proto']
[config,name_data,name_arch]=check_cfg(cfg_file,config,cfg_file_proto)
# Read cfg file options
is_production=strtobool(config['exp']['production']) #“产品” 模式 不训练模型,只使用之前训练好的模型进行正向传播和解码
cfg_file_proto_chunk=config['cfg_proto']['cfg_proto_chunk']
cmd=config['exp']['cmd']
N_ep=int(config['exp']['N_epochs_tr'])
N_ep_str_format='0'+str(max(math.ceil(np.log10(N_ep)),1))+'d'
tr_data_lst=config['data_use']['train_with'].split(',')
valid_data_lst=config['data_use']['valid_with'].split(',')
forward_data_lst=config['data_use']['forward_with'].split(',')
max_seq_length_train=config['batches']['max_seq_length_train']
forward_save_files=list(map(strtobool,config['forward']['save_out_file'].split(',')))
print("- Reading config file......OK!")
# Copy the global cfg file into the output folder
cfg_file=out_folder+'/conf.cfg'
with open(cfg_file, 'w') as configfile:
config.write(configfile)
# Load the run_nn function from core libriary
# The run_nn is a function that process a single chunk of data #run_nn是用来处理单个块数据的函数
run_nn_script=config['exp']['run_nn_script'].split('.py')[0]
module = importlib.import_module('core')
run_nn=getattr(module, run_nn_script)
# Splitting data into chunks (see out_folder/additional_files)
create_lists(config)
# Writing the config files
create_configs(config)
print("- Chunk creation......OK!\n")
# create res_file
res_file_path=out_folder+'/res.res' #文件res.res总结了各个时期的训练和评估表现。
res_file = open(res_file_path, "w")
res_file.close()
# Learning rates and architecture-specific optimization parameters
arch_lst=get_all_archs(config) #获得所有层模型的cfg数据
lr={}
auto_lr_annealing={}
improvement_threshold={}
halving_factor={}
pt_files={}
for arch in arch_lst:
lr[arch]=expand_str_ep(config[arch]['arch_lr'],'float',N_ep,'|','*') #学习率
if len(config[arch]['arch_lr'].split('|'))>1:
auto_lr_annealing[arch]=False
else:
auto_lr_annealing[arch]=True
improvement_threshold[arch]=float(config[arch]['arch_improvement_threshold'])
halving_factor[arch]=float(config[arch]['arch_halving_factor']) #对半影响
pt_files[arch]=config[arch]['arch_pretrain_file'] #pre-train模型
# If production, skip training and forward directly from last saved models
if is_production:
ep = N_ep-1 #跳过TRAINING LOOP
N_ep = 0
model_files = {}
for arch in pt_files.keys():
model_files[arch] = out_folder+'/exp_files/final_'+arch+'.pkl' #.pkl模型是用于语音解码的最终模型
op_counter=1 # used to dected the next configuration file from the list_chunks.txt
# Reading the ordered list of config file to process
cfg_file_list = [line.rstrip('\n') for line in open(out_folder+'/exp_files/list_chunks.txt')]
cfg_file_list.append(cfg_file_list[-1])
# A variable that tells if the current chunk is the first one that is being processed:
processed_first=True
data_name=[]
data_set=[]
data_end_index=[]
fea_dict=[]
lab_dict=[]
arch_dict=[]
# --------TRAINING LOOP--------#
for ep in range(N_ep):
tr_loss_tot=0
tr_error_tot=0
tr_time_tot=0
print('------------------------------ Epoch %s / %s ------------------------------'%(format(ep, N_ep_str_format),format(N_ep-1, N_ep_str_format)))
for tr_data in tr_data_lst:
# Compute the total number of chunks for each training epoch
N_ck_tr=compute_n_chunks(out_folder,tr_data,ep,N_ep_str_format,'train')
N_ck_str_format='0'+str(max(math.ceil(np.log10(N_ck_tr)),1))+'d'
# ***Epoch training***
for ck in range(N_ck_tr): #训练模型
# paths of the output files (info,model,chunk_specific cfg file)
info_file=out_folder+'/exp_files/train_'+tr_data+'_ep'+format(ep, N_ep_str_format)+'_ck'+format(ck, N_ck_str_format)+'.info' #train.info文件报告每个训练块的损失和错误性能。
if ep+ck==0:
model_files_past={}
else:
model_files_past=model_files
model_files={}
for arch in pt_files.keys():
model_files[arch]=info_file.replace('.info','_'+arch+'.pkl')
config_chunk_file=out_folder+'/exp_files/train_'+tr_data+'_ep'+format(ep, N_ep_str_format)+'_ck'+format(ck, N_ck_str_format)+'.cfg'
# update learning rate in the cfg file (if needed)
change_lr_cfg(config_chunk_file,lr,ep)
# if this chunk has not already been processed, do training...
if not(os.path.exists(info_file)):
print('Training %s chunk = %i / %i' %(tr_data,ck+1, N_ck_tr))
# getting the next chunk
next_config_file=cfg_file_list[op_counter]
# run chunk processing #训练模型
[data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict]=run_nn(data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict,config_chunk_file,processed_first,next_config_file)
# update the first_processed variable
processed_first=False
if not(os.path.exists(info_file)):
sys.stderr.write("ERROR: training epoch %i, chunk %i not done! File %s does not exist.\nSee %s \n" % (ep,ck,info_file,log_file))
sys.exit(0)
# update the operation counter
op_counter+=1
# update pt_file (used to initialized the DNN for the next chunk)
for pt_arch in pt_files.keys():
pt_files[pt_arch]=out_folder+'/exp_files/train_'+tr_data+'_ep'+format(ep, N_ep_str_format)+'_ck'+format(ck, N_ck_str_format)+'_'+pt_arch+'.pkl'
# remove previous pkl files
if len(model_files_past.keys())>0:
for pt_arch in pt_files.keys():
if os.path.exists(model_files_past[pt_arch]):
os.remove(model_files_past[pt_arch])
# Training Loss and Error
tr_info_lst=sorted(glob.glob(out_folder+'/exp_files/train_'+tr_data+'_ep'+format(ep, N_ep_str_format)+'*.info'))
[tr_loss,tr_error,tr_time]=compute_avg_performance(tr_info_lst)
tr_loss_tot=tr_loss_tot+tr_loss
tr_error_tot=tr_error_tot+tr_error
tr_time_tot=tr_time_tot+tr_time
# ***Epoch validation***
if ep>0:
# store previous-epoch results (useful for learnig rate anealling)
valid_peformance_dict_prev=valid_peformance_dict
valid_peformance_dict={}
tot_time=tr_time
for valid_data in valid_data_lst: #验证数据集
# Compute the number of chunks for each validation dataset
N_ck_valid=compute_n_chunks(out_folder,valid_data,ep,N_ep_str_format,'valid')
N_ck_str_format='0'+str(max(math.ceil(np.log10(N_ck_valid)),1))+'d'
for ck in range(N_ck_valid):
# paths of the output files
info_file=out_folder+'/exp_files/valid_'+valid_data+'_ep'+format(ep, N_ep_str_format)+'_ck'+format(ck, N_ck_str_format)+'.info'
config_chunk_file=out_folder+'/exp_files/valid_'+valid_data+'_ep'+format(ep, N_ep_str_format)+'_ck'+format(ck, N_ck_str_format)+'.cfg'
# Do validation if the chunk was not already processed
if not(os.path.exists(info_file)):
print('Validating %s chunk = %i / %i' %(valid_data,ck+1,N_ck_valid))
# Doing eval
# getting the next chunk
next_config_file=cfg_file_list[op_counter]
# run chunk processing
[data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict]=run_nn(data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict,config_chunk_file,processed_first,next_config_file)
# update the first_processed variable
processed_first=False
if not(os.path.exists(info_file)):
sys.stderr.write("ERROR: validation on epoch %i, chunk %i of dataset %s not done! File %s does not exist.\nSee %s \n" % (ep,ck,valid_data,info_file,log_file))
sys.exit(0)
# update the operation counter
op_counter+=1
# Compute validation performance
valid_info_lst=sorted(glob.glob(out_folder+'/exp_files/valid_'+valid_data+'_ep'+format(ep, N_ep_str_format)+'*.info'))
[valid_loss,valid_error,valid_time]=compute_avg_performance(valid_info_lst)
valid_peformance_dict[valid_data]=[valid_loss,valid_error,valid_time]
tot_time=tot_time+valid_time
# Print results in both res_file and stdout #打印结果到输出文件中
dump_epoch_results(res_file_path, ep, tr_data_lst, tr_loss_tot, tr_error_tot, tot_time, valid_data_lst, valid_peformance_dict, lr, N_ep)
# Check for learning rate annealing 学习率退火处理
if ep>0:
# computing average validation error (on all the dataset specified)
err_valid_mean=np.mean(np.asarray(list(valid_peformance_dict.values()))[:,1])
err_valid_mean_prev=np.mean(np.asarray(list(valid_peformance_dict_prev.values()))[:,1])
for lr_arch in lr.keys():
# If an external lr schedule is not set, use newbob learning rate anealing
if ep str to bool
for data in forward_data_lst:
for k in range(len(forward_outs)):#支持多个forward选项
if forward_dec_outs[k]:#如果需要进行forward
print('Decoding %s output %s' %(data,forward_outs[k]))
info_file=out_folder+'/exp_files/decoding_'+data+'_'+forward_outs[k]+'.info'
# create decode config file
config_dec_file=out_folder+'/decoding_'+data+'_'+forward_outs[k]+'.conf'
config_dec = configparser.ConfigParser()
config_dec.add_section('decoding') #添加一个decoding的section
for dec_key in config['decoding'].keys(): #将总的cfg文件的decoding块写入decoding过程的cfg文件中
config_dec.set('decoding',dec_key,config['decoding'][dec_key])
# add graph_dir, datadir, alidir
lab_field=config[cfg_item2sec(config,'data_name',data)]['lab']
# Production case, we don't have labels 没有标签
if not is_production:
pattern='lab_folder=(.*)\nlab_opts=(.*)\nlab_count_file=(.*)\nlab_data_folder=(.*)\nlab_graph=(.*)'
alidir=re.findall(pattern,lab_field)[0][0] #配对的第0个 lab_folder
config_dec.set('decoding','alidir',os.path.abspath(alidir))
datadir=re.findall(pattern,lab_field)[0][3] #配对的第三行 lab_data_folder
config_dec.set('decoding','data',os.path.abspath(datadir))
graphdir=re.findall(pattern,lab_field)[0][4] #配对的第四行 lab_graph
config_dec.set('decoding','graphdir',os.path.abspath(graphdir))
else:#有标签
pattern='lab_data_folder=(.*)\nlab_graph=(.*)'
datadir=re.findall(pattern,lab_field)[0][0]
config_dec.set('decoding','data',os.path.abspath(datadir))
graphdir=re.findall(pattern,lab_field)[0][1]
config_dec.set('decoding','graphdir',os.path.abspath(graphdir))
# The ali dir is supposed to be in exp/model/ which is one level ahead of graphdir
alidir = graphdir.split('/')[0:len(graphdir.split('/'))-1]
alidir = "/".join(alidir)
config_dec.set('decoding','alidir',os.path.abspath(alidir))
with open(config_dec_file, 'w') as configfile:
config_dec.write(configfile)
out_folder=os.path.abspath(out_folder)
files_dec=out_folder+'/exp_files/forward_'+data+'_ep*_ck*_'+forward_outs[k]+'_to_decode.ark' # .ark文件,该文件将作为第三个参数传入decode_dnn.sh 数据文件 本文件在下一步中可能会被删除
out_dec_folder=out_folder+'/decode_'+data+'_'+forward_outs[k] #decoding输出的文件夹
if not(os.path.exists(info_file)):
# Run the decoder #首先调用kaldi_decoding_scripts文件夹中的decode_dnn.sh
cmd_decode=cmd+config['decoding']['decoding_script_folder'] +'/'+ config['decoding']['decoding_script']+ ' '+os.path.abspath(config_dec_file)+' '+ out_dec_folder + ' \"'+ files_dec + '\"'
run_shell(cmd_decode,log_file)
# remove ark files if needed
if not forward_save_files[k]:
list_rem=glob.glob(files_dec)
for rem_ark in list_rem:
os.remove(rem_ark)
# Print WER results and write info file
cmd_res='./check_res_dec.sh '+out_dec_folder#然后调用本地文件夹下的check_res_dec.sh
wers=run_shell(cmd_res,log_file).decode('utf-8')
res_file = open(res_file_path, "a")
res_file.write('%s\n'%wers)
print(wers)
# Saving Loss and Err as .txt and plotting curves
if not is_production:
create_curves(out_folder, N_ep, valid_data_lst)
core.py
def run_nn(data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict,cfg_file,processed_first,next_config_file):
# This function processes the current chunk using the information in cfg_file. In parallel, the next chunk is load into the CPU memory
# Reading chunk-specific cfg file (first argument-mandatory file)
if not(os.path.exists(cfg_file)):
sys.stderr.write('ERROR: The config file %s does not exist!\n'%(cfg_file))
sys.exit(0)
else:
config = configparser.ConfigParser()
config.read(cfg_file)
# Setting torch seed
seed=int(config['exp']['seed'])
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
# Reading config parameters
output_folder=config['exp']['out_folder']
use_cuda=strtobool(config['exp']['use_cuda'])
multi_gpu=strtobool(config['exp']['multi_gpu'])
to_do=config['exp']['to_do']
info_file=config['exp']['out_info']
model=config['model']['model'].split('\n') #模型参数
forward_outs=config['forward']['forward_out'].split(',')
forward_normalize_post=list(map(strtobool,config['forward']['normalize_posteriors'].split(',')))
forward_count_files=config['forward']['normalize_with_counts_from'].split(',')
require_decodings=list(map(strtobool,config['forward']['require_decoding'].split(',')))
use_cuda=strtobool(config['exp']['use_cuda'])
save_gpumem=strtobool(config['exp']['save_gpumem'])
is_production=strtobool(config['exp']['production'])
if to_do=='train':
batch_size=int(config['batches']['batch_size_train'])
if to_do=='valid':
batch_size=int(config['batches']['batch_size_valid'])
if to_do=='forward':
batch_size=1
# ***** Reading the Data********
if processed_first:
# Reading all the features and labels for this chunk
shared_list=[]
p=threading.Thread(target=read_lab_fea, args=(cfg_file,is_production,shared_list,output_folder,)) #多线程读取cfg_file文件内指向的内容,并存入shared_list中,output_folder为log记录输出文件夹
p.start()
p.join()
data_name=shared_list[0]
data_end_index=shared_list[1]
fea_dict=shared_list[2]
lab_dict=shared_list[3]
arch_dict=shared_list[4]
data_set=shared_list[5]
# converting numpy tensors into pytorch tensors and put them on GPUs if specified
if not(save_gpumem) and use_cuda:
data_set=torch.from_numpy(data_set).float().cuda() #使用cuda
else:
data_set=torch.from_numpy(data_set).float()
# Reading all the features and labels for the next chunk #多线程读取下个特征数据块
shared_list=[]
p=threading.Thread(target=read_lab_fea, args=(next_config_file,is_production,shared_list,output_folder,))
p.start()
# Reading model and initialize networks #阅读模型参数,初始化模型
inp_out_dict=fea_dict
[nns,costs]=model_init(inp_out_dict,model,config,arch_dict,use_cuda,multi_gpu,to_do) #初始化模型 在utils.py中 调用neural_networks.py形成模型 nns为总网络 costs为开销
# optimizers initialization
optimizers=optimizer_init(nns,config,arch_dict) #初始化优化器 在untils.py中
# pre-training 在已经有上一步的过程(train\vaild\test)中,将模型变成上一步已经完成的模型
for net in nns.keys():
pt_file_arch=config[arch_dict[net][0]]['arch_pretrain_file'] #得到cfg文件的arch_pertrain_file
if pt_file_arch!='none':
checkpoint_load = torch.load(pt_file_arch)
nns[net].load_state_dict(checkpoint_load['model_par'])
optimizers[net].load_state_dict(checkpoint_load['optimizer_par'])
optimizers[net].param_groups[0]['lr']=float(config[arch_dict[net][0]]['arch_lr']) # loading lr of the cfg file for pt
if to_do=='forward': #对forward过程来说,需要进行 只有在forward中才会形成ark文件
post_file={}
for out_id in range(len(forward_outs)): #这个for循环是对所有输出来说(可能有多个输出的网络)
if require_decodings[out_id]:
out_file=info_file.replace('.info','_'+forward_outs[out_id]+'_to_decode.ark')#输出的ark位置
else:
out_file=info_file.replace('.info','_'+forward_outs[out_id]+'.ark')
post_file[forward_outs[out_id]]=open_or_fd(out_file,output_folder,'wb') #Open file, gzipped file, pipe, or forward the file-descriptor. 返回的是句柄?
# check automatically(自动的) if the model is sequential(连续的) 得到cfg文件中该层的arch_seq_model的值
seq_model=is_sequential_dict(config,arch_dict) #RNN LSTM GRU 等与输入顺序有关的架构,该处设为True CNN.MLP等与输入顺序无关的架构 该处设为False false会随机化特征
# ***** Minibatch Processing loop********
if seq_model or to_do=='forward':
N_snt=len(data_name)
N_batches=int(N_snt/batch_size)
else:
N_ex_tr=data_set.shape[0]
N_batches=int(N_ex_tr/batch_size)
beg_batch=0
end_batch=batch_size
snt_index=0
beg_snt=0
start_time = time.time()
# array of sentence lengths 得到表示句子长度的数组
arr_snt_len=shift(shift(data_end_index, -1,0)-data_end_index,1,0)
arr_snt_len[0]=data_end_index[0]
loss_sum=0
err_sum=0
inp_dim=data_set.shape[1]
for i in range(N_batches): #对分块进行循环
max_len=0
if seq_model: #如果是顺序输入的架构 需要保留序列的顺序
max_len=int(max(arr_snt_len[snt_index:snt_index+batch_size]))
inp= torch.zeros(max_len,batch_size,inp_dim).contiguous() # inp.shape[0]表示最长序列的长度 inp.shap[1]表示batch大小 inp.shap[2]表示特征维数
for k in range(batch_size): #对这一块的每个序列进行循环
snt_len=data_end_index[snt_index]-beg_snt #句子长度 等于 句子末尾的序列号-开头的序列号
N_zeros=max_len-snt_len #该序列需要添加的零的个数
# Appending a random number of initial zeros, tge others are at the end. 随机生成一个位置,它之前都是0,特征都在它之后。 特征添加完以后再补零至max_len。
N_zeros_left=random.randint(0,N_zeros) #随机序列开始的位置
# randomizing could have a regularization effect 随机化可能具有regularization效应 inp随机取得了数据(将特征放置到了随机的地方)
inp[N_zeros_left:N_zeros_left+snt_len,k,:]=data_set[beg_snt:beg_snt+snt_len,:] #inp为三维tensor
beg_snt=data_end_index[snt_index]
snt_index=snt_index+1
else:
# features and labels for batch i
if to_do!='forward':#当训练或者验证时,不变数据,因为有batch
inp= data_set[beg_batch:end_batch,:].contiguous()
else:#当 当前 的过程是forward时,batch=1,按顺序获取特征序列(并没有补0)
snt_len=data_end_index[snt_index]-beg_snt
inp= data_set[beg_snt:beg_snt+snt_len,:].contiguous() #这里的inp仅为二维tensor,无batch
beg_snt=data_end_index[snt_index]
snt_index=snt_index+1
# use cuda
if use_cuda:
inp=inp.cuda()
if to_do=='train':
# Forward input, with autograd graph active 调用 utils.py 内的forward_model函数
outs_dict=forward_model(fea_dict,lab_dict,arch_dict,model,nns,costs,inp,inp_out_dict,max_len,batch_size,to_do,forward_outs)
for opt in optimizers.keys():
optimizers[opt].zero_grad()
outs_dict['loss_final'].backward()#反向传播
# Gradient Clipping (th 0.1)
#for net in nns.keys():
# torch.nn.utils.clip_grad_norm_(nns[net].parameters(), 0.1)
for opt in optimizers.keys():
if not(strtobool(config[arch_dict[opt][0]]['arch_freeze'])):
optimizers[opt].step()
else:# forward or vaild 这两个过程均不需要反向传播。为了节约内存,均不使用autgrad graph。
with torch.no_grad(): # Forward input without autograd graph (save memory)
outs_dict=forward_model(fea_dict,lab_dict,arch_dict,model,nns,costs,inp,inp_out_dict,max_len,batch_size,to_do,forward_outs)
if to_do=='forward': #保存ark文件 ark文件保存的是loglikelihood
for out_id in range(len(forward_outs)):
out_save=outs_dict[forward_outs[out_id]].data.cpu().numpy()
if forward_normalize_post[out_id]:
# read the config file
counts = load_counts(forward_count_files[out_id])
out_save=out_save-np.log(counts/np.sum(counts))
# save the output 保存输出的ark文件 极为重要
write_mat(output_folder,post_file[forward_outs[out_id]], out_save, data_name[i])
else:
loss_sum=loss_sum+outs_dict['loss_final'].detach()
err_sum=err_sum+outs_dict['err_final'].detach()
# update it to the next batch
beg_batch=end_batch
end_batch=beg_batch+batch_size
# Progress bar 进度条
if to_do == 'train':
status_string="Training | (Batch "+str(i+1)+"/"+str(N_batches)+")"+" | L:" +str(round(outs_dict['loss_final'].detach().item(),3))
if i==N_batches-1:
status_string="Training | (Batch "+str(i+1)+"/"+str(N_batches)+")"
if to_do == 'valid':
status_string="Validating | (Batch "+str(i+1)+"/"+str(N_batches)+")"
if to_do == 'forward':
status_string="Forwarding | (Batch "+str(i+1)+"/"+str(N_batches)+")"
progress(i, N_batches, status=status_string)
elapsed_time_chunk=time.time() - start_time
loss_tot=loss_sum/N_batches
err_tot=err_sum/N_batches
# clearing memory
del inp, outs_dict, data_set
# save the model
if to_do=='train':
for net in nns.keys():
checkpoint={}
checkpoint['model_par']=nns[net].state_dict()
checkpoint['optimizer_par']=optimizers[net].state_dict()
out_file=info_file.replace('.info','_'+arch_dict[net][0]+'.pkl')
torch.save(checkpoint, out_file)#保存模型文件
if to_do=='forward':#关闭所有的输出ark文件的句柄 只有在forward中才会形成ark文件
for out_name in forward_outs:
post_file[out_name].close()
# Write info file 这里写了info文件
with open(info_file, "w") as text_file:
text_file.write("[results]\n")
if to_do!='forward':
text_file.write("loss=%s\n" % loss_tot.cpu().numpy())
text_file.write("err=%s\n" % err_tot.cpu().numpy())
text_file.write("elapsed_time_chunk=%f\n" % elapsed_time_chunk)
text_file.close()
# Getting the data for the next chunk (read in parallel)
p.join()
data_name=shared_list[0]
data_end_index=shared_list[1]
fea_dict=shared_list[2]
lab_dict=shared_list[3]
arch_dict=shared_list[4]
data_set=shared_list[5]
# converting numpy tensors into pytorch tensors and put them on GPUs if specified
if not(save_gpumem) and use_cuda:
data_set=torch.from_numpy(data_set).float().cuda()
else:
data_set=torch.from_numpy(data_set).float()
return [data_name,data_set,data_end_index,fea_dict,lab_dict,arch_dict]
utils.py 选取了一些utils.py中较为重要的工具。
def run_shell(cmd,log_file): #执行cmd 并返回未编码的output
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE,shell=True)
(output, err) = p.communicate()
p.wait()
with open(log_file, 'a+') as logfile:
logfile.write(output.decode("utf-8")+'\n')
logfile.write(err.decode("utf-8")+'\n')
#print(output.decode("utf-8"))
return output
def read_args_command_line(args,config): #读取command中输入的里面的参数
sections=[]
fields=[]
values=[]
for i in range(2,len(args)):
# check if the option is valid for second level
r2=re.compile('--.*,.*=.*')
# check if the option is valid for 4 level
r4=re.compile('--.*,.*,.*,.*=".*"')
if r2.match(args[i]) is None and r4.match(args[i]) is None:
sys.stderr.write('ERROR: option \"%s\" from command line is not valid! (the format must be \"--section,field=value\")\n' %(args[i]))
sys.exit(0)
sections.append(re.search('--(.*),', args[i]).group(1))
fields.append(re.search(',(.*)', args[i].split('=')[0]).group(1))
values.append(re.search('=(.*)', args[i]).group(1))
# parsing command line arguments
for i in range(len(sections)):
# Remove multi level is level >= 2
sections[i] = sections[i].split(',')[0]
if sections[i] in config.sections():
# Case of args level > than 2 like --sec,fields,0,field="value"
if len(fields[i].split(',')) >= 2:
splitted = fields[i].split(',')
#Get the actual fields
field = splitted[0]
number = int(splitted[1])
f_name = splitted[2]
if field in list(config[sections[i]]):
# Get the current string of the corresponding field
current_config_field = config[sections[i]][field]
# Count the number of occurence of the required field
matching = re.findall(f_name+'.', current_config_field)
if number >= len(matching):
sys.stderr.write('ERROR: the field number \"%s\" provided from command line is not valid, we found \"%s\" \"%s\" field(s) in section \"%s\"!\n' %(number, len(matching), f_name, field ))
sys.exit(0)
else:
# Now replace
str_to_be_replaced = re.findall(f_name+'.*', current_config_field)[number]
new_str = str(f_name+'='+values[i])
replaced = nth_replace_string(current_config_field, str_to_be_replaced, new_str, number+1)
config[sections[i]][field] = replaced
else:
sys.stderr.write('ERROR: field \"%s\" of section \"%s\" from command line is not valid!")\n' %(field,sections[i]))
sys.exit(0)
else:
if fields[i] in list(config[sections[i]]):
config[sections[i]][fields[i]]=values[i]
else:
sys.stderr.write('ERROR: field \"%s\" of section \"%s\" from command line is not valid!")\n' %(fields[i],sections[i]))
sys.exit(0)
else:
sys.stderr.write('ERROR: section \"%s\" from command line is not valid!")\n' %(sections[i]))
sys.exit(0)
return [sections,fields,values]
def compute_avg_performance(info_lst):
losses=[]
errors=[]
times=[]
for tr_info_file in info_lst:
config_res = configparser.ConfigParser()
config_res.read(tr_info_file)
losses.append(float(config_res['results']['loss']))
errors.append(float(config_res['results']['err']))
times.append(float(config_res['results']['elapsed_time_chunk']))
loss=np.mean(losses)
error=np.mean(errors)
time=np.sum(times)
return [loss,error,time]
def check_cfg(cfg_file,config,cfg_file_proto): #检查参数,并转换某些特殊参数
# Check consistency between cfg_file and cfg_file_proto 检查一致性
[config_proto,name_data,name_arch]=check_consistency_with_proto(cfg_file,cfg_file_proto)
# Reload data_name because they might be altered by arguments name_data是所有[dataset]里面设置的dataname的list
name_data=[]
for sec in config.sections():
if 'dataset' in sec:
name_data.append(config[sec]['data_name'])
# check consistency between [data_use] vs [data*]
sec_parse=True
data_use_with=[]
for data in list(dict(config.items('data_use')).values()):
data_use_with.append(data.split(','))
data_use_with=sum(data_use_with, [])
if not(set(data_use_with).issubset(name_data)):
sys.stderr.write("ERROR: in [data_use] you are using a dataset not specified in [dataset*] %s \n" % (cfg_file))
sec_parse=False
# Set to false the first layer norm layer if the architecture is sequential (to avoid numerical instabilities) 如果架构是时序( sequential)的,则将第一层norm层设置为false(以避免数值不稳定性)
seq_model=False
for sec in config.sections():
if "architecture" in sec:
if strtobool(config[sec]['arch_seq_model']):
seq_model=True
break
if seq_model:
for item in list(config['architecture1'].items()):
if 'use_laynorm' in item[0] and '_inp' not in item[0]:
ln_list=item[1].split(',')
if ln_list[0]=='True':
ln_list[0]='False'
config['architecture1'][item[0]]=','.join(ln_list)
# Parse fea and lab fields in datasets*
cnt=0
fea_names_lst=[]
lab_names_lst=[]
for data in name_data:
# Check for production case 'none' lab name
[lab_names,_,_]=parse_lab_field(config[cfg_item2sec(config,'data_name',data)]['lab'])
config['exp']['production']=str('False')
if lab_names== ["none"] and data == config['data_use']['forward_with']: #必须要在验证的时候才可能会改为True
config['exp']['production']=str('True')
continue
elif lab_names == ["none"] and data != config['data_use']['forward_with']:
continue
[fea_names,fea_lsts,fea_opts,cws_left,cws_right]=parse_fea_field(config[cfg_item2sec(config,'data_name',data)]['fea'])
[lab_names,lab_folders,lab_opts]=parse_lab_field(config[cfg_item2sec(config,'data_name',data)]['lab']) #从[dataset]里面读到lab_names,lab_folders,lab_opts
fea_names_lst.append(sorted(fea_names)) #此步在循环内,向fea_names_lst中添加fea的名字
lab_names_lst.append(sorted(lab_names))#此步在循环内,向lab_names_lst中添加lab的名字
# Check that fea_name doesn't contain special characters
for name_features in fea_names_lst[cnt]:
if not(re.match("^[a-zA-Z0-9]*$", name_features)):
sys.stderr.write("ERROR: features names (fea_name=) must contain only letters or numbers (no special characters as \"_,$,..\") \n" )
sec_parse=False
sys.exit(0)
if cnt>0:
if fea_names_lst[cnt-1]!=fea_names_lst[cnt]:#数据集的fea一定需要是相同的
sys.stderr.write("ERROR: features name (fea_name) must be the same of all the datasets! \n" )
sec_parse=False
sys.exit(0)
if lab_names_lst[cnt-1]!=lab_names_lst[cnt]: #数据集的lab_name一定需要相同的
sys.stderr.write("ERROR: labels name (lab_name) must be the same of all the datasets! \n" )
sec_parse=False
sys.exit(0)
cnt=cnt+1
# Create the output folder
out_folder=config['exp']['out_folder']
if not os.path.exists(out_folder) or not(os.path.exists(out_folder+'/exp_files')) :
os.makedirs(out_folder+'/exp_files')
# Parsing forward field
model=config['model']['model']
possible_outs=list(re.findall('(.*)=',model.replace(' ','')))
forward_out_lst=config['forward']['forward_out'].split(',')
forward_norm_lst=config['forward']['normalize_with_counts_from'].split(',')
forward_norm_bool_lst=config['forward']['normalize_posteriors'].split(',')
lab_lst=list(re.findall('lab_name=(.*)\n',config['dataset1']['lab'].replace(' ',''))) #lab_lst是[dataset]里lab_name=?内 ?的lst
lab_folders=list(re.findall('lab_folder=(.*)\n',config['dataset1']['lab'].replace(' ','')))
N_out_lab=['none'] * len(lab_lst)
for i in range(len(lab_opts)):
# Compute number of monophones if needed #ali是对齐的意思
if "ali-to-phones" in lab_opts[i]:
log_file=config['exp']['out_folder']+'/log.log'
folder_lab_count=lab_folders[i]
cmd="hmm-info "+folder_lab_count+"/final.mdl | awk '/phones/{print $4}'"
output=run_shell(cmd,log_file)
if output.decode().rstrip()=='':
sys.stderr.write("ERROR: hmm-info command doesn't exist. Make sure your .bashrc contains the Kaldi paths and correctly exports it.\n")
sys.exit(0)
N_out=int(output.decode().rstrip())
N_out_lab[i]=N_out
for i in range(len(forward_out_lst)):
if forward_out_lst[i] not in possible_outs:
sys.stderr.write('ERROR: the output \"%s\" in the section \"forward_out\" is not defined in section model)\n' %(forward_out_lst[i]))
sys.exit(0)
if strtobool(forward_norm_bool_lst[i]):
if forward_norm_lst[i] not in lab_lst:
if not os.path.exists(forward_norm_lst[i]):
sys.stderr.write('ERROR: the count_file \"%s\" in the section \"forward_out\" is does not exist)\n' %(forward_norm_lst[i]))
sys.exit(0)
else:
# Check if the specified file is in the right format
f = open(forward_norm_lst[i],"r")
cnts = f.read()
if not(bool(re.match("(.*)\[(.*)\]", cnts))):
sys.stderr.write('ERROR: the count_file \"%s\" in the section \"forward_out\" is not in the right format)\n' %(forward_norm_lst[i]))
else:
# Try to automatically retrieve the count file from the config file 尝试从配置文件自动检索计数文件
# Compute the number of context-dependent phone states 计算上下文相关的phone状态数
if "ali-to-pdf" in lab_opts[lab_lst.index(forward_norm_lst[i])]:
log_file=config['exp']['out_folder']+'/log.log'
folder_lab_count=lab_folders[lab_lst.index(forward_norm_lst[i])]
cmd="hmm-info "+folder_lab_count+"/final.mdl | awk '/pdfs/{print $4}'" #number of pdfs
output=run_shell(cmd,log_file)
if output.decode().rstrip()=='':
sys.stderr.write("ERROR: hmm-info command doesn't exist. Make sure your .bashrc contains the Kaldi paths and correctly exports it.\n")
sys.exit(0)
N_out=int(output.decode().rstrip()) #rstrip:用来去除结尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
N_out_lab[lab_lst.index(forward_norm_lst[i])]=N_out #上下文相关的phone状态数 number of pdfs
count_file_path=out_folder+'/exp_files/forward_'+forward_out_lst[i]+'_'+forward_norm_lst[i]+'.count'
cmd="analyze-counts --print-args=False --verbose=0 --binary=false --counts-dim="+str(N_out)+" \"ark:ali-to-pdf "+folder_lab_count+"/final.mdl \\\"ark:gunzip -c "+folder_lab_count+"/ali.*.gz |\\\" ark:- |\" "+ count_file_path
run_shell(cmd,log_file)
forward_norm_lst[i]=count_file_path
else:
sys.stderr.write('ERROR: Not able to automatically retrieve count file for the label \"%s\". Please add a valid count file path in \"normalize_with_counts_from\" or set normalize_posteriors=False \n' %(forward_norm_lst[i]))
sys.exit(0)
# Update the config file with the count_file paths
config['forward']['normalize_with_counts_from']=",".join(forward_norm_lst)
# When possible replace the pattern "N_out_lab*" with the detected number of output 尽可能的用检测输出的数字替换掉cfg文件中的N_out_lab_* lab_*必须是[dataset]里面的lab_name=? (lab_*==?)
for sec in config.sections():
for field in list(config[sec]):
for i in range(len(lab_lst)):
pattern='N_out_'+lab_lst[i]
if pattern in config[sec][field]:
if N_out_lab[i]!='none':
config[sec][field]=config[sec][field].replace(pattern,str(N_out_lab[i])) #替换 也就是用lab里面的个数替换掉N_out_lab*
else:
sys.stderr.write('ERROR: Cannot automatically retrieve the number of output in %s. Please, add manually the number of outputs \n' %(pattern))
sys.exit(0)
# Check the model field
parse_model_field(cfg_file)
# Create block diagram picture of the model
create_block_diagram(cfg_file)
if sec_parse==False:
sys.exit(0)
return [config,name_data,name_arch]
#
def cfg_item2sec(config,field,value): #找到cfg文件内第一个包含field=data的section,并返回section eg:cfg_item2sec(config,'data_name',data)
for sec in config.sections():#轮询每一个sections
if field in list(dict(config.items(sec)).keys()):#如果sec有field这个域
if value in list(dict(config.items(sec)).values()):#且这个field的值刚好等于value eg: data_name = data
return sec#返回该section
sys.stderr.write("ERROR: %s=%s not found in config file \n" % (field,value))
sys.exit(0)
return -1
def compute_n_chunks(out_folder,data_list,ep,N_ep_str_format,step): #在exp_files文件中找到该step(train\vaild\forward)的轮此ep下,总共有多少个chunk
list_ck=sorted(glob.glob(out_folder+'/exp_files/'+step+'_'+data_list+'_ep'+format(ep, N_ep_str_format)+'*.lst'))
last_ck=list_ck[-1]#找到最末位的chunk的序号
N_ck=int(re.findall('_ck(.+)_', last_ck)[-1].split('_')[0])+1 #序号+1 从0开始变成从1开始
return N_ck
def dict_fea_lab_arch(config):#读取数据
model=config['model']['model'].split('\n')#模型结构参数
fea_lst=list(re.findall('fea_name=(.*)\n',config['data_chunk']['fea'].replace(' ','')))# fea_name = mfcc
lab_lst=list(re.findall('lab_name=(.*)\n',config['data_chunk']['lab'].replace(' ','')))# lab_name = lab_cd
fea_lst_used=[]
lab_lst_used=[]
arch_lst_used=[]
fea_dict_used={}
lab_dict_used={}
arch_dict_used={}
fea_lst_used_name=[]
lab_lst_used_name=[]
arch_lst_used_name=[]
fea_field=config['data_chunk']['fea'] #读取fea块
lab_field=config['data_chunk']['lab']#读取lab块
pattern='(.*)=(.*)\((.*),(.*)\)'
for line in model:
[out_name,operation,inp1,inp2]=list(re.findall(pattern,line)[0])
if inp1 in fea_lst and inp1 not in fea_lst_used_name : #inp1=GRU_layers pass
pattern_fea="fea_name="+inp1+"\nfea_lst=(.*)\nfea_opts=(.*)\ncw_left=(.*)\ncw_right=(.*)"
if sys.version_info[0]==2:#python2
fea_lst_used.append((inp1+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).encode('utf8').split(','))
fea_dict_used[inp1]=(inp1+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).encode('utf8').split(',')
else:#python3
fea_lst_used.append((inp1+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).split(','))
fea_dict_used[inp1]=(inp1+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).split(',')
fea_lst_used_name.append(inp1) #it has mfcc
if inp2 in fea_lst and inp2 not in fea_lst_used_name: #inp2=mfcc in
pattern_fea="fea_name="+inp2+"\nfea_lst=(.*)\nfea_opts=(.*)\ncw_left=(.*)\ncw_right=(.*)"
if sys.version_info[0]==2:
fea_lst_used.append((inp2+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).encode('utf8').split(',')) #添加所有特性到list之中
fea_dict_used[inp2]=(inp2+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).encode('utf8').split(',')
else:
fea_lst_used.append((inp2+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).split(','))
fea_dict_used[inp2]=(inp2+","+",".join(list(re.findall(pattern_fea,fea_field)[0]))).split(',')
fea_lst_used_name.append(inp2)
if inp1 in lab_lst and inp1 not in lab_lst_used_name:#inp1=GRU_layers pass
pattern_lab="lab_name="+inp1+"\nlab_folder=(.*)\nlab_opts=(.*)"
if sys.version_info[0]==2:
lab_lst_used.append((inp1+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).encode('utf8').split(','))
lab_dict_used[inp1]=(inp1+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).encode('utf8').split(',')
else:
lab_lst_used.append((inp1+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).split(','))
lab_dict_used[inp1]=(inp1+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).split(',')
lab_lst_used_name.append(inp1)
if inp2 in lab_lst and inp2 not in lab_lst_used_name:#inp2=lab_cd in
pattern_lab="lab_name="+inp2+"\nlab_folder=(.*)\nlab_opts=(.*)"
if sys.version_info[0]==2:
lab_lst_used.append((inp2+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).encode('utf8').split(',')) #添加所有特性到list之中
lab_dict_used[inp2]=(inp2+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).encode('utf8').split(',')
else:
lab_lst_used.append((inp2+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).split(','))
lab_dict_used[inp2]=(inp2+","+",".join(list(re.findall(pattern_lab,lab_field)[0]))).split(',')
lab_lst_used_name.append(inp2) # it has lab_cd
if operation=='compute' and inp1 not in arch_lst_used_name:
arch_id=cfg_item2sec(config,'arch_name',inp1)
arch_seq_model=strtobool(config[arch_id]['arch_seq_model'])
arch_lst_used.append([arch_id,inp1,arch_seq_model])
arch_dict_used[inp1]=[arch_id,inp1,arch_seq_model]
arch_lst_used_name.append(inp1)# it has GRU_layers\MLP_layers\
# convert to unicode (for python 2)
for i in range(len(fea_lst_used)):
fea_lst_used[i]=list(map(str, fea_lst_used[i]))
for i in range(len(lab_lst_used)):
lab_lst_used[i]=list(map(str, lab_lst_used[i]))
for i in range(len(arch_lst_used)):
arch_lst_used[i]=list(map(str, arch_lst_used[i]))
return [fea_dict_used,lab_dict_used,arch_dict_used] #返回的是字典 fea_dict_used为输入数据(mfcc)的配置 lab_dict_used为lab(lab_cd)的配置 arch_dict_used为网络结构的配置(块section name 是否为序列输入)
def is_sequential(config,arch_lst): # To cancel
seq_model=False
for [arch_id,arch_name,arch_seq] in arch_lst:
if strtobool(config[arch_id]['arch_seq_model']):
seq_model=True
break
return seq_model
def is_sequential_dict(config,arch_dict):
seq_model=False
for arch in arch_dict.keys():
arch_id=arch_dict[arch][0]
if strtobool(config[arch_id]['arch_seq_model']):
seq_model=True
break
return seq_model
def compute_cw_max(fea_dict): #计算两边最大的cw
cw_left_arr=[]
cw_right_arr=[]
for fea in fea_dict.keys():
cw_left_arr.append(int(fea_dict[fea][3]))
cw_right_arr.append(int(fea_dict[fea][4]))
cw_left_max=max(cw_left_arr)
cw_right_max=max(cw_right_arr)
return [cw_left_max,cw_right_max]
def model_init(inp_out_dict,model,config,arch_dict,use_cuda,multi_gpu,to_do): #读取配置文件中的model.model下的每一行,形成网络
pattern='(.*)=(.*)\((.*),(.*)\)'
nns={}
costs={}
for line in model: #读每一行
[out_name,operation,inp1,inp2]=list(re.findall(pattern,line)[0]) # out_name输出 operation操作名称 inp1该层的名称 inp2输入
if operation=='compute':
# computing input dim
inp_dim=inp_out_dict[inp2][-1]#得到上一层网络的输出维数
# import the class
module = importlib.import_module(config[arch_dict[inp1][0]]['arch_library'])
nn_class=getattr(module, config[arch_dict[inp1][0]]['arch_class'])#导入neural_network.py里面定义的模块。
# add use cuda and todo options
config.set(arch_dict[inp1][0],'use_cuda',config['exp']['use_cuda'])
config.set(arch_dict[inp1][0],'to_do',config['exp']['to_do'])
arch_freeze_flag=strtobool(config[arch_dict[inp1][0]]['arch_freeze'])
# initialize the neural network
net=nn_class(config[arch_dict[inp1][0]],inp_dim) #初始化该层网络
if use_cuda:
net.cuda()
if multi_gpu:
net = nn.DataParallel(net)
if to_do=='train':
if not(arch_freeze_flag):
net.train()
else:
# Switch to eval modality if architecture is frozen (mainly for batch_norm/dropout functions)
net.eval()
else:
net.eval()
# addigng nn into the nns dict
nns[arch_dict[inp1][1]]=net
if multi_gpu:
out_dim=net.module.out_dim
else:
out_dim=net.out_dim
# updating output dim
inp_out_dict[out_name]=[out_dim]
if operation=='concatenate':
inp_dim1=inp_out_dict[inp1][-1]
inp_dim2=inp_out_dict[inp2][-1]
inp_out_dict[out_name]=[inp_dim1+inp_dim2]
if operation=='cost_nll':
costs[out_name] = nn.NLLLoss() #nn.NLLLoss()负对数似然损失函数
inp_out_dict[out_name]=[1]
if operation=='cost_err':
inp_out_dict[out_name]=[1]
if operation=='mult' or operation=='sum' or operation=='mult_constant' or operation=='sum_constant' or operation=='avg' or operation=='mse':
inp_out_dict[out_name]=inp_out_dict[inp1]
return [nns,costs]
def forward_model(fea_dict,lab_dict,arch_dict,model,nns,costs,inp,inp_out_dict,max_len,batch_size,to_do,forward_outs):
# Forward Step
outs_dict={} #output的字典(包含了每个输出的特性)
pattern='(.*)=(.*)\((.*),(.*)\)'
# adding input features to out_dict:
for fea in fea_dict.keys(): #支持特性多输入
if len(inp.shape)==3 and len(fea_dict[fea])>1: # len(inp.shape)==3都是arch_seq_model=True的网络 []
outs_dict[fea]=inp[:,:,fea_dict[fea][5]:fea_dict[fea][6]]
if len(inp.shape)==2 and len(fea_dict[fea])>1: # len(inp.shape)==2都是arch_seq_model=False的网络
outs_dict[fea]=inp[:,fea_dict[fea][5]:fea_dict[fea][6]]
for line in model: #model是cfg文件内的model块
[out_name,operation,inp1,inp2]=list(re.findall(pattern,line)[0]) #读取model各行的cfg字符
if operation=='compute':#如果进行的操作是计算
if len(inp_out_dict[inp2])>1: # if it is an input feature 如果输入的是特征(如mfcc)
# Selection of the right feature in the inp tensor 在inp tensor里选择正确的特性
if len(inp.shape)==3:
inp_dnn=inp[:,:,inp_out_dict[inp2][-3]:inp_out_dict[inp2][-2]]
if not(bool(arch_dict[inp1][2])):
inp_dnn=inp_dnn.view(max_len*batch_size,-1)
if len(inp.shape)==2:
inp_dnn=inp[:,inp_out_dict[inp2][-3]:inp_out_dict[inp2][-2]]
if bool(arch_dict[inp1][2]):
inp_dnn=inp_dnn.view(max_len,batch_size,-1)
outs_dict[out_name]=nns[inp1](inp_dnn) #进行计算
else:#如果输入的不是特性
if not(bool(arch_dict[inp1][2])) and len(outs_dict[inp2].shape)==3:
outs_dict[inp2]=outs_dict[inp2].view(max_len*batch_size,-1)
if bool(arch_dict[inp1][2]) and len(outs_dict[inp2].shape)==2:
outs_dict[inp2]=outs_dict[inp2].view(max_len,batch_size,-1)
outs_dict[out_name]=nns[inp1](outs_dict[inp2])
if to_do=='forward' and out_name==forward_outs[-1]: #若to_do是forward,只进行到[forward]块中 forward_out = out_dnn2 的这一步(out_dnn2)
break
if operation=='cost_nll':#损失函数
# Put labels in the right format
if len(inp.shape)==3:
lab_dnn=inp[:,:,lab_dict[inp2][3]]
if len(inp.shape)==2:
lab_dnn=inp[:,lab_dict[inp2][3]]
lab_dnn=lab_dnn.view(-1).long()
# put output in the right format
out=outs_dict[inp1]
if len(out.shape)==3:
out=out.view(max_len*batch_size,-1)
if to_do!='forward':
outs_dict[out_name]=costs[out_name](out, lab_dnn)
if operation=='cost_err':#损失的误差值
if len(inp.shape)==3:
lab_dnn=inp[:,:,lab_dict[inp2][3]]
if len(inp.shape)==2:
lab_dnn=inp[:,lab_dict[inp2][3]]
lab_dnn=lab_dnn.view(-1).long()
# put output in the right format
out=outs_dict[inp1]
if len(out.shape)==3:
out=out.view(max_len*batch_size,-1)
if to_do!='forward':
pred=torch.max(out,dim=1)[1]
err = torch.mean((pred!=lab_dnn).float())
outs_dict[out_name]=err
#print(err)
if operation=='concatenate':#串联
dim_conc=len(outs_dict[inp1].shape)-1
outs_dict[out_name]=torch.cat((outs_dict[inp1],outs_dict[inp2]),dim_conc) #check concat axis cat的作用是拼接
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='mult':#相乘
outs_dict[out_name]=outs_dict[inp1]*outs_dict[inp2]
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='sum':#相加
outs_dict[out_name]=outs_dict[inp1]+outs_dict[inp2]
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='mult_constant':#乘以常数
outs_dict[out_name]=outs_dict[inp1]*float(inp2)
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='sum_constant':#加上常数
outs_dict[out_name]=outs_dict[inp1]+float(inp2)
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='avg':#两数取平均
outs_dict[out_name]=(outs_dict[inp1]+outs_dict[inp2])/2
if to_do=='forward' and out_name==forward_outs[-1]:
break
if operation=='mse':#求mse
outs_dict[out_name]=torch.mean((outs_dict[inp1] - outs_dict[inp2]) ** 2)
if to_do=='forward' and out_name==forward_outs[-1]:
break
return outs_dict
neural_networks.py 只选取了LSTM进行注释
class LSTM(nn.Module):
def __init__(self, options,inp_dim):
super(LSTM, self).__init__()
# Reading parameters
self.input_dim=inp_dim #输入的维数
self.lstm_lay=list(map(int, options['lstm_lay'].split(','))) #每个lay的神经元个数
self.lstm_drop=list(map(float, options['lstm_drop'].split(','))) #dropout
self.lstm_use_batchnorm=list(map(strtobool, options['lstm_use_batchnorm'].split(','))) #use laynorm bool变量组
self.lstm_use_laynorm=list(map(strtobool, options['lstm_use_laynorm'].split(','))) #use batchnorm bool变量组
self.lstm_use_laynorm_inp=strtobool(options['lstm_use_laynorm_inp']) #use laynorm input bool变量
self.lstm_use_batchnorm_inp=strtobool(options['lstm_use_batchnorm_inp']) #use batchnorm input bool变量
self.lstm_act=options['lstm_act'].split(',') #lstm Activation function 激活函数
self.lstm_orthinit=strtobool(options['lstm_orthinit']) #是否使用正交初始化
self.bidir=strtobool(options['lstm_bidir']) #是否使用双向
self.use_cuda=strtobool(options['use_cuda']) #是否使用cuda
self.to_do=options['to_do']
if self.to_do=='train':
self.test_flag=False
else:
self.test_flag=True
# List initialization
self.wfx = nn.ModuleList([]) # Forget 权重(输入值)
self.ufh = nn.ModuleList([]) # Forget 权重(上一时刻状态值)
self.wix = nn.ModuleList([]) # Input
self.uih = nn.ModuleList([]) # Input
self.wox = nn.ModuleList([]) # Output
self.uoh = nn.ModuleList([]) # Output
self.wcx = nn.ModuleList([]) # Cell state
self.uch = nn.ModuleList([]) # Cell state
self.ln = nn.ModuleList([]) # Layer Norm
self.bn_wfx = nn.ModuleList([]) # Batch Norm
self.bn_wix = nn.ModuleList([]) # Batch Norm
self.bn_wox = nn.ModuleList([]) # Batch Norm
self.bn_wcx = nn.ModuleList([]) # Batch Norm
self.act = nn.ModuleList([]) # Activations
# Input layer normalization
if self.lstm_use_laynorm_inp:
self.ln0=LayerNorm(self.input_dim) # 输入层normalliaztion
# Input batch normalization
if self.lstm_use_batchnorm_inp:
self.bn0=nn.BatchNorm1d(self.input_dim,momentum=0.05)
self.N_lstm_lay=len(self.lstm_lay) #层数
current_input=self.input_dim #当前的输入维数
# Initialization of hidden layers
for i in range(self.N_lstm_lay):
# Activations
self.act.append(act_fun(self.lstm_act[i])) #添加该层的激活函数
add_bias=True #是否添加偏置
if self.lstm_use_laynorm[i] or self.lstm_use_batchnorm[i]: #如果使用了laynorm 或者 batchnorm,则偏置无效 因为使用了norm以后,数据的分布已经改变为正态分布,故偏置已经无意义
add_bias=False
# Feed-forward connections 前向连接
self.wfx.append(nn.Linear(current_input, self.lstm_lay[i],bias=add_bias))
self.wix.append(nn.Linear(current_input, self.lstm_lay[i],bias=add_bias))
self.wox.append(nn.Linear(current_input, self.lstm_lay[i],bias=add_bias))
self.wcx.append(nn.Linear(current_input, self.lstm_lay[i],bias=add_bias))
# Recurrent connections 循环连接
self.ufh.append(nn.Linear(self.lstm_lay[i], self.lstm_lay[i],bias=False))
self.uih.append(nn.Linear(self.lstm_lay[i], self.lstm_lay[i],bias=False))
self.uoh.append(nn.Linear(self.lstm_lay[i], self.lstm_lay[i],bias=False))
self.uch.append(nn.Linear(self.lstm_lay[i], self.lstm_lay[i],bias=False))
if self.lstm_orthinit: #正交初始化
nn.init.orthogonal_(self.ufh[i].weight) #将权重进行正交初始化
nn.init.orthogonal_(self.uih[i].weight)
nn.init.orthogonal_(self.uoh[i].weight)
nn.init.orthogonal_(self.uch[i].weight)
# batch norm initialization
self.bn_wfx.append(nn.BatchNorm1d(self.lstm_lay[i],momentum=0.05)) #batch normalization
self.bn_wix.append(nn.BatchNorm1d(self.lstm_lay[i],momentum=0.05))
self.bn_wox.append(nn.BatchNorm1d(self.lstm_lay[i],momentum=0.05))
self.bn_wcx.append(nn.BatchNorm1d(self.lstm_lay[i],momentum=0.05))
self.ln.append(LayerNorm(self.lstm_lay[i]))
if self.bidir: #是否是双向的LSTM
current_input=2*self.lstm_lay[i]
else:
current_input=self.lstm_lay[i]
self.out_dim=self.lstm_lay[i]+self.bidir*self.lstm_lay[i] #输出的维数 self.bidir是bool值
def forward(self, x): #计算前向
# Applying Layer/Batch Norm
if bool(self.lstm_use_laynorm_inp):
x=self.ln0((x))
if bool(self.lstm_use_batchnorm_inp):
x_bn=self.bn0(x.view(x.shape[0]*x.shape[1],x.shape[2])) #首先展开x成为一个二维数组,并进行batch normalization
x=x_bn.view(x.shape[0],x.shape[1],x.shape[2]) #然后将x变成原先的shape
for i in range(self.N_lstm_lay): #每一层
# Initial state and concatenation
if self.bidir:
h_init = torch.zeros(2*x.shape[1], self.lstm_lay[i])
x=torch.cat([x,flip(x,0)],1) #cat为拼接函数 1表示横向拼接 0表示纵向拼接
else:
h_init = torch.zeros(x.shape[1],self.lstm_lay[i])
# Drop mask initilization (same mask for all time steps)
if self.test_flag==False:
drop_mask=torch.bernoulli(torch.Tensor(h_init.shape[0],h_init.shape[1]).fill_(1-self.lstm_drop[i])) #bernoulli 伯努利分布(两点分布) drop_mask首先是一个全部都为0.8,shape=(shape[0],shape[1])的矩阵 然后经过伯努利分布得到各点值为0或1的矩阵
else:
drop_mask=torch.FloatTensor([1-self.lstm_drop[i]])
if self.use_cuda:
h_init=h_init.cuda()
drop_mask=drop_mask.cuda()
# Feed-forward affine transformations (all steps in parallel) 前馈仿射变换 y=WX+b
wfx_out=self.wfx[i](x)#计算前馈
wix_out=self.wix[i](x)
wox_out=self.wox[i](x)
wcx_out=self.wcx[i](x)
# Apply batch norm if needed (all steps in parallel)
if self.lstm_use_batchnorm[i]:
wfx_out_bn=self.bn_wfx[i](wfx_out.view(wfx_out.shape[0]*wfx_out.shape[1],wfx_out.shape[2]))
wfx_out=wfx_out_bn.view(wfx_out.shape[0],wfx_out.shape[1],wfx_out.shape[2])
wix_out_bn=self.bn_wix[i](wix_out.view(wix_out.shape[0]*wix_out.shape[1],wix_out.shape[2]))
wix_out=wix_out_bn.view(wix_out.shape[0],wix_out.shape[1],wix_out.shape[2])
wox_out_bn=self.bn_wox[i](wox_out.view(wox_out.shape[0]*wox_out.shape[1],wox_out.shape[2]))
wox_out=wox_out_bn.view(wox_out.shape[0],wox_out.shape[1],wox_out.shape[2])
wcx_out_bn=self.bn_wcx[i](wcx_out.view(wcx_out.shape[0]*wcx_out.shape[1],wcx_out.shape[2]))
wcx_out=wcx_out_bn.view(wcx_out.shape[0],wcx_out.shape[1],wcx_out.shape[2])
# Processing time steps
hiddens = []
ct=h_init
ht=h_init
for k in range(x.shape[0]):
# LSTM equations
ft=torch.sigmoid(wfx_out[k]+self.ufh[i](ht)) #wx_out之前已经计算过了 uh还没有计算过
it=torch.sigmoid(wix_out[k]+self.uih[i](ht))
ot=torch.sigmoid(wox_out[k]+self.uoh[i](ht))
ct=it*self.act[i](wcx_out[k]+self.uch[i](ht))*drop_mask+ft*ct
ht=ot*self.act[i](ct)
if self.lstm_use_laynorm[i]:
ht=self.ln[i](ht)
hiddens.append(ht)
# Stacking hidden states 合并隐藏状态,将不同时刻得到的隐藏状态合并成同一个tensor,沿时间轴
h=torch.stack(hiddens)
# Bidirectional concatenations 双向
if self.bidir:
h_f=h[:,0:int(x.shape[1]/2)]
h_b=flip(h[:,int(x.shape[1]/2):x.shape[1]].contiguous(),0)
h=torch.cat([h_f,h_b],2)
# Setup x for the next hidden layer
x=h
return x