《A Multi-task Learning Model for Chinese-oriented Aspect Polarity Classification and Aspect Term》笔记
A Multi-task Learning Model for Chinese-oriented Aspect Polarity Classification and Aspect Term Extraction(面向中文的方位极性分类和方位项提取的多任务学习模型) 学习笔记
论文亮点
- 本文提出了一个联合模型用于aspect term extraction(方面项提取) 和 aspect polarity classification (aspect极性分类)。
- 论文中提出的模型面向中文,也适应于英文,能同时处理中英文评论。
- 该模型还集成了域自适应的 BERT模型以进行增强(每一个数据集使用一个bert)。
- 模型在七个基准数据集中实现了最先进的性能。
1. 摘要
基于方面的情感分析(ABSA)任务是一个多粒度的自然语言处理任务, 现有的研究大多集中在方面项极性推断的子任务上,忽略了方面项提取的重要意义。此外,现有的研究还没有注意到面向汉语的ABSA任务的研究。
基于局部上下文焦点(LCF)机制,论文首次提出了面向中文的方面级情绪分析的多任务学习模型(LCF-ATEPC),该模型能够同时进行aspect term extraction(ATE)和aspect polarity classification(APC)两个子任务,能够同时对中英文评论进行分析,该模型集成了自适应领域的BERT模型,在四个中文评论数据集和SemEval-2014上取得了最优性能。
2.Introduction
在以往的研究中,主要关注的APC的精度,而忽略了对于ATE的研究,因此,在基于方面的情感分析进行迁移学习时,往往会因为缺少aspect term提取方法而陷入困境。
因此,为了有效的从文本中提取aspect,同时分析情感极性,提出了一种基于方面情绪分析的多任务多语言学习模型(LCF-ATEPC)。该模型基于Multi-head self-attention,集成预训练的bert和局部上下文焦点机制(LCF)。
通过对少量带有aspect和aspect极性的数据进行训练,该模型可以适应于大规模的数据集,可以自动提取各方面信息,预测情绪极值。通过这种方法,模型可以发现未知的方面,避免了手工注释所有方面和极性的繁琐和巨大的成本。基于领域特定方面的情绪分析具有重要意义。
2.1 创新点
- 首次研究了面向多语种评论的结合APC子任务和ATE子任务的多任务模型,为中文方面项提取的研究提供了一种新的思路。
- 第一次将self-attention和局部语境聚焦技术应用到APC中,充分挖掘他们在APC中的潜力。
- 分别设计并应用了双标签输入序列(方面术语标签和情感极性标签),分别适用于ABSA联合任务的SemEval-2014和中文评论数据集。 双重标记提高了模型的学习效率。
- LCF-ATEPC集成了预训练的bert模型。
3.模型
为了提出一种有效的基于多任务学习的方面级情感分析模型,我们采用了BERT-ADA中的域自适应BERT模型,并将局部上下文聚焦机制集成到该模型中。本节介绍LCF-ATEPC的体系结构和方法。
3.1 问题描述
ATE:序列标注任务。{Basp,Iasp,O}
例如“The price is reasonable although the service is poor.“ S={w1,w2…wn} ,其中 S 表示的是这个句子,w 表示的是单词经过Word embedding 之后的向量表示,这里把他叫做token(令牌),这句话的标注是 Y={O,Basp,O,O,O,O,Basp,O,O,O} 。
APC:情感极性分类是情绪分析的一个多粒度子任务,目的是预测方面项的情绪极性。St={wi,wi+1 … wj} ,St 表示句子中的方面项 ,其中 i 是起始位置, j 是结束位置。
3.2模型架构
该模型将ATE和APC任务相结合,采用两个独立的BERT层分别对全局上下文和局部上下文进行建模。为了同时进行多任务训练,输入序列被标记成不同的标记,每个单词(token)有两种不同的label:第一种标签指示令牌是否是方面词,第二种标签标记方面词的情感极性。

在上图中,左边是局部上下文特征生成器(LCFG),右边是全局上下文特征生成器(GCFG)。两个特征生成单元主要包含一个独立的预训练bert层,分别是 BERTl 和 BERTg 。
LCFG通过 local context focus layer 和一个MHSA(Multi-head self-attention) 提取 局部上下文特征。
GCFG只部署了一个MHSA来学习全局上下文特征(在代码中没有找到)。
特征交互学习层(The feature interactive learning 简称FIL):结合局部上下文特征和全局上下文特征之间的交互学习,预测aspect的情感极性。
并且基于全局上下文特征(GCFG部分)提取aspect。
3.2.1 BERT-Shared 层
预训练的BERT模型是为了提高大多数NLP任务的性能而设计的。LCF-ATEPC使用两个独立的BERT共享层,用于提取局部和全局上下文。对于预训练的bert模型,微调学习是必不可少的。两个bert的分享层都是被认为是嵌入层,并根据多任务学习的联合损失独立进行微调。
注释:
-
多任务fine-tuning:使用Bert去训练除最后一层之外的其他任务,在不同任务之间共享参数。
-
迁移学习不是一种算法而是一种机器学习思想,应用到深度学习就是微调(Fine-tune)。通过修改预训练网络模型结构(如修改样本类别输出个数),选择性载入预训练网络模型权重(通常是载入除最后的全连接层的之前所有层 ,也叫瓶颈层) (本文无关,没用到)
Xl 和 Xg 分别表示LCFG和GCFG的标记化输入(输入句子是相同的,但是对句子的标注是不同的,看3.8节),可以得到局部和全局上下文特征的初步输入。

其中 O 分别表示LCFG和GCFG的输出特征。BERTl 和 BERT g 分别表示嵌入到LCFG和GCFG中的对应的bert共享层。
3.3 MHSA(Multi-head self-attention)
Multi-head self-attention是基于multiple scale-dot attention(多重缩放点积注意力 SDA),我认为就是多个self-attention同时工作,将获得的结果进行处理,这样获得的信息比较全面,可以用来提取语境中的深层语义特征。最后获得的是注意力分数矩阵。
MHSA在学习特征时可以避免上下文的长距离依赖带来的负面影响。
假设XSDA是LCFG学习到的输入特征,则scale-dot attention计算如下:
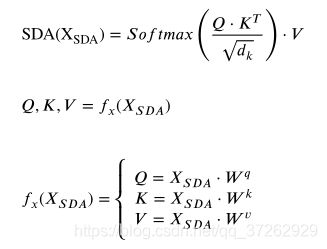
MHSA 并行执行多个缩放的点注意力(SDA),并将输入特征串联起来,然后乘以一个权重矩阵WMH进行转换特征。其中h表示attention heads的数量。文中用的是12。

使用了tanh激活函数,显著增强了特征捕捉能力。其中 WMH 的向量表示如下:
![]()
说明经过MHSA之后,输出的结果维度是 n * dh 。n是单词的数量,dh 是一个单词隐层向量表示的维度。
3.4 Local Context Focus
3.4.1 语义相对距离(SRD)
局部上下文的确定依赖于语义相对距离,SRD用来判断上下文是否属于目标方面的局部上下文,以帮助模型捕捉局部上下文。局部上下文是一个新的概念,可以适应大多数细粒度的NLP任务。
在现有的ABSA中,现有的模型通常是把输入序列分为方面序列和上下文序列,将方面和上下文视为单独的片段,分别进行建模。
目标方面的局部上下文包含了更重要的信息,所以本文跟以往的模型不同,没有将aspect作为单独的输入,而是挖掘方面及其局部上下文(重点)。
SRD 是基于token-aspect对的概念,描述token与aspect之间的距离,就是token与aspect之间隔了几个token,作为所有token-aspect对的SRD,计算过程如下:
![]()
i 是特定令牌的位置,Pa 是aspect的中心位置,m 是目标aspect的长度,所以SRD表示第i个令牌和目标方面之间的距离。
通过MHSA编码器计算出所有令牌的输出后,除了与目标相关的局部上下文之外,其他的未知的输出特征都将被屏蔽(CDM)或者衰减(CDW)。
3.4.2 上下文特征动态掩码(CDM)
除了局部上下文特征,CDM将屏蔽 BERTl 层学习到的非局部上下文特征。

CDM的实施,将非局部上下文的所有位置的特征设置为零向量。为了避免CDM操作后特征分布的不均衡性,利用MHSA编码器学习并重新平衡被屏蔽的局部上下文特征。
假设Obert是BERTl的初始输出特征,那我们可以得到如下的局部上下文特征。

M是用于屏蔽非局部上下文特征的屏蔽矩阵,Vmi 是输入序列中每个token的掩码向量。α 是SRD阈值(文中是5),n是包括方面的输入序列的长度。其中与目标aspect相关的SRD小于阈值 α 表示的是局部上下文。E是一个1向量,O是一个零向量(长度是n)
将学习到的局部特征放到一个MHSA层(求局部上下文中的注意力)中,就得到了局部上下文表示 Ol 。

3.4.3 上下文特征动态加权(CDW)
CDM层完全放弃了非局部上下文特征,与CDM层相比,CDW采用了一种更加温和的策略,对目标aspect的非局部上下文特征根据SRD进行加权衰减。局部上下文特征保持不变。
设置权重,对非局部上下文的token设置一个很小的权重,降低影响力
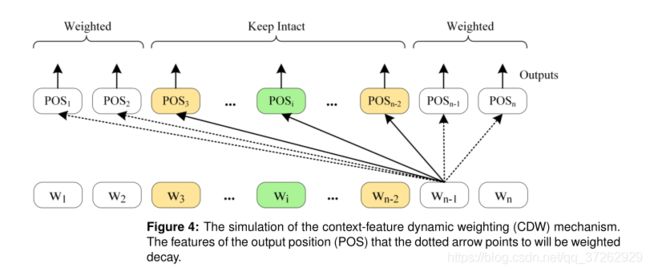

W 是权重矩阵, Vwi 表示的是权重向量。
![]()
CDM和CDW层是独立的,这就意味着他们是可选的,他们的输出特征均是Ol。此外,我们还尝试将CDM和CDW层的学习特征串联起来,并将他们的线性变换作为局部上下文的特征。

Wf , Of 表示的是权重矩阵,bf 表示的是偏移矩阵
3.5 特征交流学习
LCF-ATEPC结合和学习局部上下文特征和全局上下文特征进行极性分类。
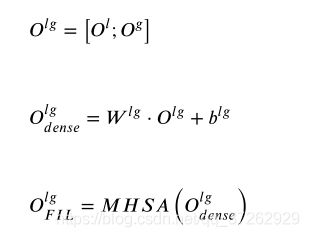
Ol 和 Og (Og 是Ogbert ) 分别表示局部上下文特征和全局上下文特征,为了获得连接向量的特征,使对 Olgdense 进行MHSA编码。
3.6 情感极性分类
方面级情感分类器对学习到的连接上下文特征执行head-pooling。
head-pooling指的是在输入序列中第一个token的对应位置提取隐藏状态。
求得head-pooling之后,把他放到了一个线性层,映射成1 * 3 (中文数据集是1 * 2)的形状(相当于一个三分类问题,文中没有进行介绍,代码中给出来的)。
然后应用softmax操作预测情绪极性(这里没有特别理解为什么要用head-pooling)。
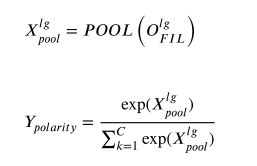
其中 C 是情绪极性的数量,Ypolarity 表示预测的情感极性。
3.7 aspect 项提取
方面项提取器首先对每个token(单词)执行token-level分类,假设 Ti 是令牌T对应位置上的特征(Og 通过一个线性层分类器,转换成n*3)。
每个位置都相当于一个三分类问题。
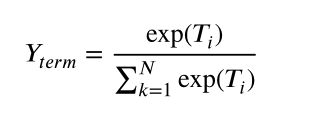
这里N是令牌类别的数量。Yterm 表示方面极性分类器推断的令牌类别。
这里简单的取每个位置上的最大概率的标签,没有考虑标签之间的相关性。
3.8 训练细节
对于LCFG和GCFG都是基于BERT-BASE模型的,然后BERT-SPC模型的提出显著的改善了APC的性能,而且与BERT-BASE相比,BERT-SPC只修改了输入序列的标注形式。
BERT-BASE: [CLS]+sequence+[SEP]

BERT-SPC: [CLS]+sequence+[SEP]+aspect+[SEP]

因为LCF-ATEPC是一个多任务模型,我们重新设计了数据输入的形式,并采用了情绪极性分析和token类别的双重标签。第一行评论标签序列,第二行是输入的评论(标明情感词),第三行是方面词的情感极性。
损失函数:使用交叉熵损失函数。

C 是情感极性种类的数量。λ 是正则化参数,θ 是模型的参数集。yi 冒是方面词的情感极性,yi 是预测的方面词的情感极性。
在标注数据集是,作者用-1表示除方面词之外的其他词,所以在损失函数前不用添加负号。目的是缩小损失函数。

(这里N,k的位置写反了)
N 是单词标签的种类,k 是每个输入序列的长度。ti 冒 是单词的标签,ti 是预测单单词的标签。

文中隐层的数量数768。
通过误差反向传播完成多任务之间的交互,这种交互方法是内隐式的,不可控的。
4 实验
4.1数据集
数据集:SemEval-2014和四个中文数据集。
数据集展示:


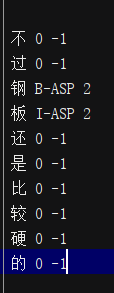
其中,第一列是评论数据,第二列是标签序列(B-ASP,I-ASP,O),第三列表示的是表达的情感极性。
多语言混合数据集

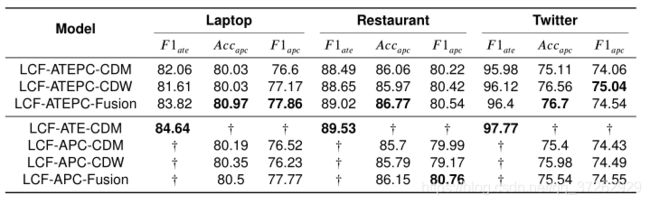
4.2实验结果:
- 在中文数据集上的表现。
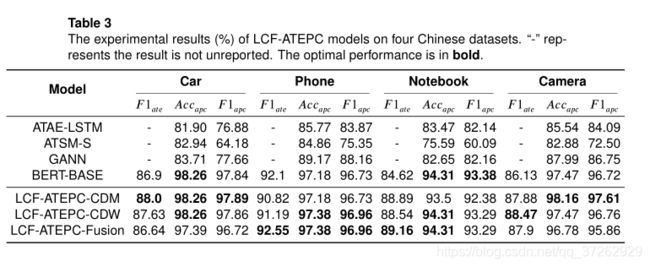
- 在SemEval-2014 task4上的表现

- 在混合模型上的表现