Predictive State Temporal Difference Learning 原文翻译预测状态时间差分学习
Predictive State Temporal Difference Learning
Byron Boots,Geoffrey J. Gordon,2010,nips
摘要
我们提出了一种新的价值函数逼近方法,它将线性时间差分强化学习与子空间识别相结合。在实际应用中,强化学习(RL)由于状态是高维的或部分可观察的这一事实而变得复杂。因此,RL方法被设计为与状态特征而不是状态本身一起工作,并且学习的成功或失败通常取决于所选特征的适合性。相比之下,子空间识别(SSID)方法被设计为选择一个特征集,该特征集尽可能多地保留关于状态的信息。在本文中,我们将两种方法联系起来,用大量特征来研究强化学习的问题,每一种特征对于价值函数近似都可能只是有一点用。我们为这种情况引入了一种新算法,称为预测状态时间差分(PSTD)学习。与用于预测状态表示的SSID一样,PSTD找到一个线性压缩运算符,它将大量特征投影到一个小集合,以保留最大量的预测信息。与RL一样,PSTD随后使用Bellman递归来估计值函数。我们讨论了PSTD与RL和SSID中的先前方法之间的联系。我们证明PSTD在统计上是一致的,执行几个实验来说明其性质,并证明其在困难的最佳停止问题上的潜力。
1 简介
我们希望在高维和部分可观察的环境中估计策略在未知决策过程中的价值函数。我们在线性架构中表示值函数,作为(序列)观察的特征的线性组合。一种流行的学习算法族称为时间差分(TD)方法[1],就是针对这种情况而设计的。特别地,最小二乘TD(LSTD)算法[2,3,4]利用值函数的线性来从采样轨迹(即,从访问状态的特征向量序列)通过求解一组线性方程来估计其参数。
最近,Parr等人从免模型和基于模型的强化学习的角度研究了价值函数估计的问题[5]。无模型方法(包括TD方法)直接从样本迹估计值函数。相比之下,基于模型的方法首先学习过程模型,然后从学习模型中计算价值函数。帕尔等人证明了这两种方法计算完全相同的值函数[5]。在本文中,我们建立在这种洞察的基础上,同时使用系统识别的强大方法找到一组紧凑的特征。
首先,我们从免模型预测瓶颈的角度来看待改进LSTD的问题:鉴于历史的大量特征,我们设计了一种称为预测状态时间差分(PSTD)学习的新TD方法。 PSTD通过仅保留预测信息的瓶颈来估计价值函数(第3节)。然后,我们从基于模型的角度来看价值函数估计问题(第4节)。不像在[5]中那样学习特征空间中的线性过渡模型,我们使用子空间识别[6,7]来从我们的样本中学习PSR。由于PSR至少与POMDP一样紧凑,因此我们的表示自然可以被视为对更大POMDP的值定向压缩。最后,我们表明我们的两种改进方法是等价的。这一结果产生了一些吸引人的理论上的好处:例如,PSTD特征可以明确地解释为对真实基础系统状态的统计一致性估计。并且,找到真值函数的可行性可以显示为取决于动态系统的线性维度,或者等效地,取决于预测状态表示的维度 - 而不取决于POMDP状态空间的基数。因此,我们的表示在[8]意义上自然地被“压缩”,加速了收敛。
我们通过几个实验证明了我们方法的实际好处:我们将PSTD与其他算法进行比较,在合成示例和困难的最优停止问题上。在后一个问题中,大量的先前工作已经用于手动调整函数。我们表明,如果我们为这些手动调整的特征添加大量弱相关特征,PSTD可以找到比其他方法更好的预测子空间,从而大大提高了此问题的先前报告的最佳结果。这里给出的理论和实证结果表明,对于使用LSTD计算值函数的许多应用,可以简单地替换PSTD以产生更好的结果。
2 值函数逼近
我们从具有一组状态S,一组动作A,初始状态π0的分布,转换函数T,奖励函数R和折扣因子![]() 。我们寻求策略,从状态到行动的映射。对于给定的策略
。我们寻求策略,从状态到行动的映射。对于给定的策略![]() ,状态s的值被定义为在状态s和后续策略
,状态s的值被定义为在状态s和后续策略![]() 中开始时的预期折扣的奖励总和,
中开始时的预期折扣的奖励总和,![]() 。值函数服从Bellman方程
。值函数服从Bellman方程
![]() (1)
(1)
如果我们知道转换函数T,并且如果状态集S足够小,我们可以使用策略迭代找到最优策略:选择初始策略![]() ,使用(1)求解值函数
,使用(1)求解值函数![]() ,计算对于
,计算对于![]() 的贪心策略(在每个状态以最大化(1)的右侧设置动作),并重复。然而,当s是部分可观察的潜变量时,以及当转移函数T未知时,我们考虑更难以估计值函数的问题。在这种情况下,我们通过有限集O中的观察得到关于s的信息。我们不能再根据S做出决策或预测奖励,而是必须使用历史(有序的动作观察对
的贪心策略(在每个状态以最大化(1)的右侧设置动作),并重复。然而,当s是部分可观察的潜变量时,以及当转移函数T未知时,我们考虑更难以估计值函数的问题。在这种情况下,我们通过有限集O中的观察得到关于s的信息。我们不能再根据S做出决策或预测奖励,而是必须使用历史(有序的动作观察对![]() :在时间t之前已经执行并观察到的情况):
:在时间t之前已经执行并观察到的情况):![]() 代替
代替![]() 。设
。设![]() 是所有可能历史的集合。
是所有可能历史的集合。 ![]() 通常是非常大或无限的,所以我们不是为每个历史分别找到一个值,而是专注于历史特征中线性的价值函数。
通常是非常大或无限的,所以我们不是为每个历史分别找到一个值,而是专注于历史特征中线性的价值函数。
![]() (2)
(2)
这里,![]() 是参数矢量,
是参数矢量,![]() 是历史h的特征矢量。因此,我们可以将贝尔曼方程重写为
是历史h的特征矢量。因此,我们可以将贝尔曼方程重写为
![]() (3)
(3)
其中![]() 是通过采取行动π(h)和观察o来扩展的历史h。
是通过采取行动π(h)和观察o来扩展的历史h。
2.1最小二乘时间差分学习
一般来说,我们不知道转移概率![]() ,但我们确实有状态特征的样本
,但我们确实有状态特征的样本![]() ,下一状态特征
,下一状态特征![]() ,并且立即奖励
,并且立即奖励![]() 。因此我们可以估计Bellman方程
。因此我们可以估计Bellman方程
![]() (4)
(4)
(这里我们使用![]() 表示矩阵,其列为
表示矩阵,其列为![]() ,对于t = 1 … k)我们可以通过在最小二乘意义上求解该线性系统来立即尝试估计参数
,对于t = 1 … k)我们可以通过在最小二乘意义上求解该线性系统来立即尝试估计参数![]() ,其中
,其中![]() 表示伪逆。然而,这个解是有偏差的[3],因为自变量
表示伪逆。然而,这个解是有偏差的[3],因为自变量![]() 是预期差值
是预期差值![]() 的噪声样本。换句话说,对值函数参数w进行估计是一个带误差变量问题。
的噪声样本。换句话说,对值函数参数w进行估计是一个带误差变量问题。
最小二乘时间差(LSTD)算法通过将近似Bellman方程(方程式4)乘以![]() 来找到w的一致估计:
来找到w的一致估计:
![]() (5)
(5)
在这里,![]() 可以被视为工具变量[3],即,与真实自变量相关但与我们对这些变量的估计中的噪声不相关的测量。
可以被视为工具变量[3],即,与真实自变量相关但与我们对这些变量的估计中的噪声不相关的测量。
随着数据量k的增加,经验协方差矩阵![]() 和
和![]() 以概率1收敛到它们的总体值,因此我们对要反转的矩阵的估计在(5)中是一致的。所以,只要这个矩阵是非奇异的,我们对逆的估计就也是一致的,并且我们对w的估计收敛到概率为1的真值。
以概率1收敛到它们的总体值,因此我们对要反转的矩阵的估计在(5)中是一致的。所以,只要这个矩阵是非奇异的,我们对逆的估计就也是一致的,并且我们对w的估计收敛到概率为1的真值。
3预测函数
LSTD提供值函数参数w的一致估计;但实际上,如果特征的数量相对于训练样本的数量很大,那么W的LSTD估计倾向于过拟合。通过选择仅包含与值函数近似相关的信息的一小组特征,可以减轻该问题。然而,除了LARS-TD [9]之外,当系统模型未知时,关于如何自动选择特征来进行值函数近似的研究很少;当然,人工特征选择取决于不常用的专家指导。我们从瓶颈角度解决了寻找一系列好的特征的问题。也就是说,给定历史的大量特征,我们希望找到仅保留用于预测值函数![]() 的相关信息的压缩。正如我们将在第4节中看到的,这种改进与PSR的谱识别直接相关。
的相关信息的压缩。正如我们将在第4节中看到的,这种改进与PSR的谱识别直接相关。
3.1通过瓶颈寻找预测特征
为了找到预测特征压缩,我们首先需要确定我们想要预测的内容。最相关的预测是价值函数本身;所以,我们可以简单地尝试预测未来的总折扣奖励。不幸的是,总折扣奖励的差异很大,所以除非我们有大量数据,否则学习将很困难。我们也可以通过包含其他预测任务来减少差异。例如,预测未来时间步的个体的奖励似乎高度相关,并为我们提供更多即时反馈。同样,未来的观察结果有望包含有关未来奖励的信息,因此尝试预测观察可以帮助我们预测奖励。
我们将这些预测任务统称为未来的特征。我们为“t时刻的未来”的所有特征的向量写入![]() ,即从t + 1时刻开始并继续向前的事件。现在,我们想要找到一个与预测未来特征相关的历史特征的小子空间,而不是记住历史的大量任意特征。我们将这个子空间称为预测压缩,我们将值函数写为仅预测压缩特征的线性函数。为了找到我们的预测压缩,我们将使用降阶退化[10]。我们定义了未来特征与历史特征之间的以下经验协方差矩阵:
,即从t + 1时刻开始并继续向前的事件。现在,我们想要找到一个与预测未来特征相关的历史特征的小子空间,而不是记住历史的大量任意特征。我们将这个子空间称为预测压缩,我们将值函数写为仅预测压缩特征的线性函数。为了找到我们的预测压缩,我们将使用降阶退化[10]。我们定义了未来特征与历史特征之间的以下经验协方差矩阵:
设LH为![]() 的下三角Cholesky因子。然后我们可以通过加权协方差的奇异值分解(SVD)找到历史的预测压缩:写入
的下三角Cholesky因子。然后我们可以通过加权协方差的奇异值分解(SVD)找到历史的预测压缩:写入![]()
![]() ,用于截断的SVD [11],其中U包含左奇异向量,V包含右奇异向量, D是奇异值的对角矩阵。 (我们可以通过保持更多或更少的奇异值,即U,V或D列来调整精度。)我们使用SVD定义从压缩空间到未来特征空间的映射
,用于截断的SVD [11],其中U包含左奇异向量,V包含右奇异向量, D是奇异值的对角矩阵。 (我们可以通过保持更多或更少的奇异值,即U,V或D列来调整精度。)我们使用SVD定义从压缩空间到未来特征空间的映射![]() ,我们将
,我们将![]() 定义为给定
定义为给定![]() 的最佳压缩算子(在最小二乘意义上,详见[12]):
的最佳压缩算子(在最小二乘意义上,详见[12]):
![]() (7)
(7)
通过不同地加权未来的不同特征,我们可以用有趣的方式改变近似压缩。例如,正如我们将在4.2节中看到的那样,通过常数因子扩展未来奖励会导致价值导向的压缩 - 但是,与之前找到价值导向压缩的方法不同[8],我们不需要提前知道我们的系统的一个模型。再举一个例子,让![]() 成为未来特征
成为未来特征![]() 的经验协方差的Cholesky因子。然后,如果我们通过
的经验协方差的Cholesky因子。然后,如果我们通过![]() 扩展未来的特征,SVD将在历史和未来之间保留尽可能多的互信息,从而产生规范相关分析[13,14]。
扩展未来的特征,SVD将在历史和未来之间保留尽可能多的互信息,从而产生规范相关分析[13,14]。
3.2 预测状态时间差异学习
现在我们已经通过公式7找到了预测压缩算子![]() ,我们可以用Bellman递归中的压缩特征
,我们可以用Bellman递归中的压缩特征![]() 替换历史
替换历史![]() 的特征,公式4:
的特征,公式4:
![]() (8)
(8)
w的最小二乘解仍然容易出现变量误差问题。工具变量![]() 仍然与真实的自变量相关并且与噪声不相关,因此我们可以再次使用它来消除w的估计偏差。定义附加的协方差矩阵:
仍然与真实的自变量相关并且与噪声不相关,因此我们可以再次使用它来消除w的估计偏差。定义附加的协方差矩阵:
![]() (9)
(9)
然后,校正的Bellman方程是![]() .
.
W的求解给我们提供了预测状态时间差分(PSTD)学习算法:
![]() (10)
(10)
到目前为止,我们已经提供了一些直觉,为什么预测特征应该优于时间差异学习的任意特征。下面我们将展示另一个好处:在某些情况下,等式10中的免模型算法等效于使用子空间识别来学习预测状态表示的基于模型的方法[6,7]。
4 预测状态表示
预测状态表示(PSR)[15]是动态系统的紧凑和完整的描述。 与POMDP不同,POMDP将状态表示为潜在变量的分布,PSR将状态表示为一组测试预测。 正如历史是在时刻t之前执行的有序动作 - 观察对序列一样,我们将长度为i的测试定义为动作观察对的有序序列![]() ,可以在一段时间后执行和观察 t [15]。 在历史h后对测试
,可以在一段时间后执行和观察 t [15]。 在历史h后对测试![]() 的预测写作
的预测写作![]() ,是假设我们干预[16]来执行测试动作
,是假设我们干预[16]来执行测试动作![]() ,我们将看到测试观察
,我们将看到测试观察![]() 的概率为
的概率为![]() 。 如果
。 如果![]() 是一个测试集合,我们将相应的测试预测向量写为
是一个测试集合,我们将相应的测试预测向量写为![]() 。
。
形式上,PSR由五个元素![]() 组成。 A是一组有限的可能动作,O是一组有限的可能观察。 Q是一组核心测试,即一组预测Q(h)是预测所有测试成功概率的充分统计量。 F是这些体现预测
组成。 A是一组有限的可能动作,O是一组有限的可能观察。 Q是一组核心测试,即一组预测Q(h)是预测所有测试成功概率的充分统计量。 F是这些体现预测![]() 的函数
的函数![]() 的集合。并且,
的集合。并且,![]() 是初始预测向量。在这项工作中,我们将自己局限于线性PSR,其中所有预测函数都是线性的:
是初始预测向量。在这项工作中,我们将自己局限于线性PSR,其中所有预测函数都是线性的:![]() 中的向量
中的向量![]() 。最后,如果核心集Q中的测试是线性无关的,则Q是最小的[17,18],即,没有一个测试的预测是其他测试的预测的线性函数。
。最后,如果核心集Q中的测试是线性无关的,则Q是最小的[17,18],即,没有一个测试的预测是其他测试的预测的线性函数。
由于Q(h)是所有测试的充分统计量,它是我们PSR的状态:即,我们只能记住Q(h)而不是h本身。在行动a和观察o之后,我们可以递归地更新Q(h):如果我们将![]() 行是
行是![]() 的矩阵写为矩阵
的矩阵写为矩阵![]() ,那么我们可以使用贝叶斯规则来表示:
,那么我们可以使用贝叶斯规则来表示:
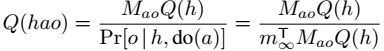 (11)
(11)
其中![]() 是一个归一化系数,由
是一个归一化系数,由![]() 定义。除了上述PSR参数之外,对于强化学习,我们需要一个奖励函数
定义。除了上述PSR参数之外,对于强化学习,我们需要一个奖励函数![]() 将预测状态映射到即时奖励,折扣因子
将预测状态映射到即时奖励,折扣因子![]() 衡量未来奖励与现有奖励的重要性,以及从预测状态到行动的策略π(Q(h))映射。
衡量未来奖励与现有奖励的重要性,以及从预测状态到行动的策略π(Q(h))映射。
我们将使用转换的PSR(TPSR)[6,7]而不是普通的PSR。 TPSR是常规PSR的一般化:TPSR维持少量的充分统计量,这些统计量是(可能非常大的)测试概率集的线性组合。也就是说,TPSR维持少量的特征预测而不是测试预测。 TPSR具有与常规PSR完全相同的预测能力,但在相似变换下是不变的:给定可逆矩阵S,我们可以做变换![]() ,而不改变相应的动力系统,因为在式11中
,而不改变相应的动力系统,因为在式11中![]() 消掉了. TPSR相比于常规PSR的主要好处是,给定任何核心测试集,可以使用谱矩阵分解和回归而不是组合搜索找到低维参数。在这方面,TPSR与通过子空间识别发现的LDS和HMM的变换表示密切相关[19,20,14,21]。
消掉了. TPSR相比于常规PSR的主要好处是,给定任何核心测试集,可以使用谱矩阵分解和回归而不是组合搜索找到低维参数。在这方面,TPSR与通过子空间识别发现的LDS和HMM的变换表示密切相关[19,20,14,21]。
4.1 学习转化的PSR
设Q是最小核心测试集,因此![]() 是系统的线性维度。然后,让
是系统的线性维度。然后,让![]() 成为一个更大的核心测试集(不一定是最小的),让
成为一个更大的核心测试集(不一定是最小的),让![]() 成为所有可能历史的集合。如前所述,时刻t的历史特征向量写为
成为所有可能历史的集合。如前所述,时刻t的历史特征向量写为![]() ,并在时间t的未来特征向量写为
,并在时间t的未来特征向量写为![]() 。由于T是一组核心测试,根据定义,我们可以将任何测试预测
。由于T是一组核心测试,根据定义,我们可以将任何测试预测![]() 计算为T(h)的线性函数。而且,由于特征预测是测试预测的线性组合,我们也可以将任何特征预测
计算为T(h)的线性函数。而且,由于特征预测是测试预测的线性组合,我们也可以将任何特征预测![]() 计算为T(h)的线性函数。我们定义矩阵
计算为T(h)的线性函数。我们定义矩阵![]() 以体现我们对未来特征的预测:
以体现我们对未来特征的预测:![]() 的条目是T中的一个测试的权重,用于计算
的条目是T中的一个测试的权重,用于计算![]() 中的一个特征的预测。下面我们根据可观察量
中的一个特征的预测。下面我们根据可观察量![]()
![]() 定义几个协方差矩阵,等式12(a-d),并显示这些矩阵如何与基础PSR的参数相关。这些关系随后推出我们的学习算法,下面的Eq. 14。
定义几个协方差矩阵,等式12(a-d),并显示这些矩阵如何与基础PSR的参数相关。这些关系随后推出我们的学习算法,下面的Eq. 14。
首先,我们定义![]() ,即历史特征的协方差矩阵,如
,即历史特征的协方差矩阵,如![]() 。给定k个样本,我们可以近似这个协方差:
。给定k个样本,我们可以近似这个协方差:
![]() (12a)
(12a)
作为![]() 以概率1收敛到真实的方差
以概率1收敛到真实的方差![]() 接下来我们定义
接下来我们定义![]() ,状态的交叉协方差和历史的特征。从状态a时间t写入(未观察到的)b的s = Q(h),令
,状态的交叉协方差和历史的特征。从状态a时间t写入(未观察到的)b的s = Q(h),令![]() 。我们不能从数据直接估计
。我们不能从数据直接估计![]() ,但是这个矩阵将作为我们在下面定义的几个矩阵中的一个因子出现。接下来我们定义
,但是这个矩阵将作为我们在下面定义的几个矩阵中的一个因子出现。接下来我们定义![]() ,测试和历史特征的交叉协方差矩阵(参见[12]的推导):
,测试和历史特征的交叉协方差矩阵(参见[12]的推导):
![]() (12b)
(12b)
其中矩阵R的行![]() 是
是![]() ,线性函数指定测试
,线性函数指定测试![]() 的预测给出核心集Q中的测试的预测。通过
的预测给出核心集Q中的测试的预测。通过![]() ,我们意图近似执行所有所需的所有动作序列的效果一次测试或未来的特征。这在我们的实验中并不困难(其中所有测试都使用兼容的动作序列);但请参阅[12]进一步讨论。式12b告诉我们,由于我们对线性维数的假设,矩阵
,我们意图近似执行所有所需的所有动作序列的效果一次测试或未来的特征。这在我们的实验中并不困难(其中所有测试都使用兼容的动作序列);但请参阅[12]进一步讨论。式12b告诉我们,由于我们对线性维数的假设,矩阵![]() 具有因子
具有因子![]() 和
和![]() 。因此,
。因此,![]() 的秩不大于n,即系统的线性维数。我们还可以看到,由于
的秩不大于n,即系统的线性维数。我们还可以看到,由于![]() 的大小是固定的,随着样本数k的增加,
的大小是固定的,随着样本数k的增加,![]() 以1的概率。
以1的概率。
接下来,我们定义![]() ,一组矩阵,每个动作观察对一个矩阵,表示在采取动作a和观察o之前和之后的历史特征之间的协方差。在下文中,
,一组矩阵,每个动作观察对一个矩阵,表示在采取动作a和观察o之前和之后的历史特征之间的协方差。在下文中,![]() 是我们是否在步骤t看到观察o的指示变量。
是我们是否在步骤t看到观察o的指示变量。
![]() (12c)
(12c)
由于每个![]() 的维数是固定的,因此对于
的维数是固定的,因此对于![]() 这些经验协方差会收敛到真正的协方差
这些经验协方差会收敛到真正的协方差![]() 以概率1.最后我们定义
以概率1.最后我们定义![]() ,并逼近协方差(在这种情况下是一个向量)奖励和历史特征:
,并逼近协方差(在这种情况下是一个向量)奖励和历史特征:
![]() (12d)
(12d)
再次,对于![]() ,
,![]() 收敛于
收敛于![]() 以概率1。
以概率1。
我们现在希望使用上面定义的矩阵从数据中学习TPSR。为此,我们需要做一个有限制性的假设:我们假设我们的历史特征足够丰富以确定系统的状态,即从![]() 到s的回归是准确的:
到s的回归是准确的:![]() 。我们在[12]中讨论如何放松这个假设。我们还需要一个矩阵U,使得
。我们在[12]中讨论如何放松这个假设。我们还需要一个矩阵U,使得![]() 是可逆的;以概率1,随机矩阵满足这个条件,但正如我们将在下面看到的,有理由通过SVD选择U的缩放版本的
是可逆的;以概率1,随机矩阵满足这个条件,但正如我们将在下面看到的,有理由通过SVD选择U的缩放版本的![]() ,如第2节所述。第 3.1节使用我们的假设,我们可以显示
,如第2节所述。第 3.1节使用我们的假设,我们可以显示![]() 的有用特性(有关证明细节,请参阅[12]):
的有用特性(有关证明细节,请参阅[12]):
![]() (13)
(13)
这个特性是我们学习算法的核心:它表明![]() 包含着
包含着![]() 的隐藏副本,这是我们需要学习的主要TPSR参数。我们想通过Eq.13恢复
的隐藏副本,这是我们需要学习的主要TPSR参数。我们想通过Eq.13恢复![]() ,
,![]() ;但我们当然不知道
;但我们当然不知道![]() .幸运的是,事实证明我们可以使用
.幸运的是,事实证明我们可以使用![]() 作为替代,因为这个矩阵仅通过可逆变换(方程12b)而不同。我们现在说明如何从矩阵T恢复
作为替代,因为这个矩阵仅通过可逆变换(方程12b)而不同。我们现在说明如何从矩阵T恢复![]() ,和U.由于TPSR的预测是不变的相似性及其参数的变换,我们的算法只在相似变换内[7,12]恢复TPSR参数。
,和U.由于TPSR的预测是不变的相似性及其参数的变换,我们的算法只在相似变换内[7,12]恢复TPSR参数。
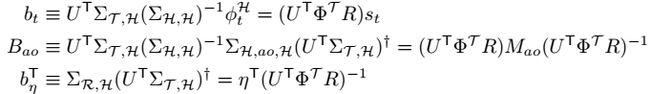

我们的PSR学习算法很简单:通过其经验估计,替换Eq 14中的每个真正的协方差矩阵。由于随着样本量的增加,经验估计会以概率1收敛到其真实值,因此我们的学习算法显然具有统计学上的一致性。
4.2预测状态时间差分学习(重访)
最后,我们准备证明3.2节中介绍的无模型PSTD学习算法等同于围绕PSR学习构建的基于模型的算法。对于固定策略,PSR或TPSR的值函数是状态的线性函数,![]() ,并且是PSR Bellman方程[22]的解:对于所有s,
,并且是PSR Bellman方程[22]的解:对于所有s,![]() ,或者等价地,
,或者等价地,![]()
![]() 。用我们从公式14(a-c)中学习的PSR参数代替,得到
。用我们从公式14(a-c)中学习的PSR参数代替,得到

因为,通过比较方程式。在图12c和9中,我们可以看到![]() 。现在,将
。现在,将![]() 和
和![]() 定义为Eq.7,并按照上面第4.1节中的建议设
定义为Eq.7,并按照上面第4.1节中的建议设![]() .。然后
.。然后![]() ,和
,和
![]() (15)
(15)
Eq. 15就是Eq. 10,PSTD算法。 因此,我们已经证明,如果我们通过Sec的子空间识别算法学习PSR,然后通过Bellman方程计算其值函数,得到完全相同的答案,好像我们通过无模型PSTD方法直接学习了值函数。除了增加对两种方法的理解之外,该结果的一个重要推论是PSTD是PSR值函数近似的统计一致算法 - 据我们所知,这是TD方法的第一个这样的结果。
5 实验结果
5.1 估计RR-POMDP的价值函数
我们根据[23]得出的合成例子评估了PSTD学习算法。问题是在部分可观察的马尔可夫决策过程(POMDP)中找到策略的价值函数。 POMDP有4个潜在状态,但策略的转移矩阵是低秩:得到的信念分布位于原始信念单形的三维子空间中(详见[12])。
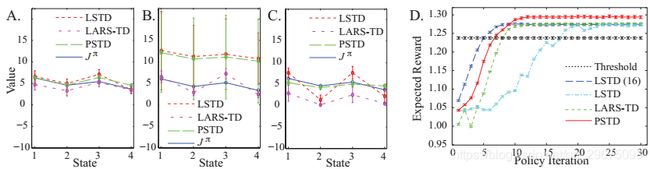
图1:实验结果。误差条表示标准差。 (A)用少量信息特征估算价值函数。这三种方法都做得很好。 (B)使用一小组信息特征和大量随机特征估计价值函数。 LARS-TD专为此场景而设计,并且远远优于PSTD和LSTD。 (C)使用大量半信息特征估计价值函数。 PSTD能够确定一小组压缩特征,这些特征保留了关于值函数的最大信息量,优于LSTD和LARS-TD。 (D)通过策略迭代定价高维衍生品。最优阈值策略(价格高于阈值[24]出售)为黑色,LSTD(16个典型特征)为蓝色,LSTD(完整220个特征)为青色,LARS-TD(特征选择自220的集合为绿色,PSTD(16维,压缩220个特征)为红色。
我们进行了3次实验,比较了使用不同特征集时LSTD,LARS-TD和PSTD的性能。在每种情况下,我们将每个算法估计的值函数与由![]() 计算的真值函数进行比较。在第一个实验中,我们执行1000个时间步长的策略 π 。我们将数据分成长度为5的重叠历史和测试,并将这些历史和测试的样本10分别作为高斯径向基函数的中心。然后,我们评估每个剩余样本的每个基函数。然后,使用这些特征,我们使用线性尺寸为3的LSTD,LARS-TD和PSTD学习了值函数(图1(A))。每种方法估计合理的价值函数。对于第二个实验,我们在10个良好特征中添加了490个随机,无信息特征,然后尝试用3种算法中的每一种学习值函数(图1(B))。在这种情况下,由于大量不相关的特征,LSTD和PSTD都难以拟合值函数。 LARS-TD专为这种情况而设计,能够选择10个相关特征并以较大幅度更好地估算价值函数。对于第三个实验,我们将采样特征的数量从10增加到500.在这种情况下,每个特征都有些相关,但与训练数据量相比,特征的数量很大。这种情况在实践中经常发生:通常很容易找到至少与状态有关的大量特征。通过总结这些特征并有效地估计值函数,PSTD优于LSTD和LARS-TD(图1(C))。
计算的真值函数进行比较。在第一个实验中,我们执行1000个时间步长的策略 π 。我们将数据分成长度为5的重叠历史和测试,并将这些历史和测试的样本10分别作为高斯径向基函数的中心。然后,我们评估每个剩余样本的每个基函数。然后,使用这些特征,我们使用线性尺寸为3的LSTD,LARS-TD和PSTD学习了值函数(图1(A))。每种方法估计合理的价值函数。对于第二个实验,我们在10个良好特征中添加了490个随机,无信息特征,然后尝试用3种算法中的每一种学习值函数(图1(B))。在这种情况下,由于大量不相关的特征,LSTD和PSTD都难以拟合值函数。 LARS-TD专为这种情况而设计,能够选择10个相关特征并以较大幅度更好地估算价值函数。对于第三个实验,我们将采样特征的数量从10增加到500.在这种情况下,每个特征都有些相关,但与训练数据量相比,特征的数量很大。这种情况在实践中经常发生:通常很容易找到至少与状态有关的大量特征。通过总结这些特征并有效地估计值函数,PSTD优于LSTD和LARS-TD(图1(C))。
5.2 高维金融衍生品定价
衍生工具是与基本资产(如股票,债券和商品)的未来价格相关的收益的金融合约。在某些衍生工具中,合约持有人没有选择权,但在更复杂的情况下,持有人必须作出决定,而合约的价值取决于持有人的行为 - 例如,通过提前行使,持有人可以随时决定终止合同并根据当时的市场情况接收付款,因此决定何时行使是最佳停止问题。停止问题为策略评价方法提供了理想的测试平台,因为我们可以收集单个数据集,让我们评估任何策略:我们只是永远选择“继续”操作。 (然后我们可以在任何结果状态中轻松评估“停止”动作。)
我们考虑Tsitsiklis和Van Roy [24]引入的金融衍生品。该衍生工具产生的收益取决于单一股票的价格。在每一天结束时,持有人可以选择使用。在使用时,持有人获得的收益等于股票的当前价格除以100天之前的价格。我们可以将这种衍生物视为“通灵呼叫”:持有者可以决定他/她是否愿意以100天前的当时市场价格购买普通的100天欧洲看涨期权。在我们的模拟中(投资者不知道),标的股票价格遵循几何布朗运动,波动率![]() 并且连续复合短期增长率
并且连续复合短期增长率![]() 。假设股票价格仅在市场开放的几天波动,这些参数对应的年增长率为10%。更详细地,如果wt是标准布朗运动,那么股票价格pt演变为
。假设股票价格仅在市场开放的几天波动,这些参数对应的年增长率为10%。更详细地,如果wt是标准布朗运动,那么股票价格pt演变为![]() ,并且我们可以在每天结束时将相关状态概括为向量
,并且我们可以在每天结束时将相关状态概括为向量![]() ,其中
,其中![]() 。这个过程是马尔可夫且遍历的[24,25]:
。这个过程是马尔可夫且遍历的[24,25]: 和
和![]() 是独立且相同的分布。行使期权的直接奖励是G(x)= x(100),继续持有期权的直接奖励是0。折扣因子
是独立且相同的分布。行使期权的直接奖励是G(x)= x(100),继续持有期权的直接奖励是0。折扣因子![]() 由增长率决定;这相当于假设无风险利率等于股票的增长率,这意味着投资者通过持有股票本身而无法获得任何期望。
由增长率决定;这相当于假设无风险利率等于股票的增长率,这意味着投资者通过持有股票本身而无法获得任何期望。
如果当前状态是x,则导数的值由![]() 给出。我们的目标是计算近似值函数
给出。我们的目标是计算近似值函数![]() ,然后使用该值函数生成停止时间
,然后使用该值函数生成停止时间![]() 。为此,我们采样1,000,000个状态
。为此,我们采样1,000,000个状态![]() 的序列并计算每个状态的特征
的序列并计算每个状态的特征![]() .然后,我们对此样本执行策略迭代,交替估计给定策略下的值函数,然后使用此值函数定义新的贪婪策略“如果
.然后,我们对此样本执行策略迭代,交替估计给定策略下的值函数,然后使用此值函数定义新的贪婪策略“如果![]() 则停止”。
则停止”。
在上述策略中,我们有两个主要选择:我们使用哪些函数,以及如何根据这些功能估计值函数。对于价值函数估计,我们使用LSTD,LARS-TD或PSTD。在每种情况下,我们重新使用我们的1,000,000状态样本轨迹用于所有迭代:只要策略选择“继续”操作,我们就从头开始并遵循轨迹,每一步都有奖励0。当策略执行“停止”动作时,奖励为G(x),下一个状态的特征均为全0;然后,在流程完全混合之后,我们将来重启策略100步。对于特征选择,我们很幸运:以前的研究人员通过反复试错人工地为这个数据集选择了一组“好的”16个特征(见[12]和[24,25])。我们大大扩展了这组函数,然后使用PSTD来合成一小组高质量的组合函数。具体来说,我们添加整个100步状态向量,状态向量组件的平方和几个额外的非线性特征,将特征总数从16增加到220.我们使用长度为1的历史,长度为5的测试和(为了比较)我们选择16的线性维度。通过将除奖励之外的所有特征的方差减少100倍,测试(但不是历史)是价值导向的。
图1D显示了结果。我们将LSTD的PSTD(减少220到16个特征)与16个手动选择的特征或完整的220个特征以及LARS-TD(220个特征)和简单的阈值策略[24]进行了比较。在每种情况下,我们都评估了10,000个新的随机轨迹的最终策略。 PSTD的表现优于其每一个竞争对手,将下一个最佳方法LARS-TD提高1.75个百分点。实际上,PSTD的性能优于之前最佳的移植方法[24,25],提高了1.24个百分点。这些改进对应于无风险利率的可观部分(在合约的100天窗口中约为4个百分点),因此对于重大套利机会:不了解最佳策略的投资者将持续低估安全性,允许知情的投资者以低于其预期价值购买它。
六 结论
在本文中,我们攻击时间差异学习的特征选择问题。尽管众所周知的时间差分算法(如LSTD)可以在线性体系结构中提供渐近无偏的值函数参数估计,但它们在有限样本中可能会出现问题:如果特征的数量相对于训练样本的数量很大,那么它们的价值函数估计值可能有很大的差异。出于这个原因,在实际问题中,通常通过反复试验,花费大量时间来选择一小组特征[24,25]。为了解决这个问题,我们提出了PSTD算法,这是TD方法特征选择的一种新方法,它演示了系统识别的见解如何有助于强化学习。 PSTD自动选择一组与预测和值函数近似相关的特征。它通过查找仅保留预测信息的一小组特征,从瓶颈角度进行特征选择。由于专注于预测信息,PSTD方法与PSR密切相关:在适当的假设下,PSTD的压缩特征集渐近地等同于TPSR状态,而PSTD是PSR值函数的一致估计。
我们在一个合成示例中证明了PSTD与两种流行的替代算法LARS-TD和LSTD相比的优点,并且认为PSTD在从大量特征中近似值函数时最有效,每个特征至少包含一个关于状态的一点信息。最后,我们将PSTD应用于困难的最优停止问题,并通过超越几种替代方法并超过最佳报告的先前结果来证明该算法的实际效用。