ResNet 调制识别+Network 剪枝
基于ResNet 的调制方式识别,并应用网络剪枝技术给模型瘦身的Keras实现。参考论文
1.Learning Efficient Convolutional Networks through Network Slimming
2.Over the Air Deep Learning Based Radio Signal Classification
调制识别网络结构:
训练数据:RML2016.10a.tar.bz2
输入数据维度为(100000,128,2),长度为128点的调制信号,分为I/Q两路。
Xm_input=Input(X.shape[1:])
Xm=Reshape([X.shape[1],X.shape[2],1],input_shape=X.shape[1:])(Xm_input)
Xm = residual_stack(Xm,kennel_size=(5,2),Seq="ReStk0",pool_size=(2,2),sparse_factor=sparse_factor) #shape:(64,1,32)
Xm = residual_stack(Xm,kennel_size=(5,1),Seq="ReStk1",pool_size=(2,1),sparse_factor=sparse_factor) #shape:(32,1,32)
Xm = residual_stack(Xm,kennel_size=(5,1),Seq="ReStk2",pool_size=(2,1),sparse_factor=sparse_factor) #shape:(16,1,32)
Xm = Flatten()(Xm)
Xm = Dense(32, activation='selu', kernel_initializer='glorot_normal', name="dense1")(Xm)
Xm = AlphaDropout(0.3)(Xm)
Xm = Dense(16, activation='selu', kernel_initializer='glorot_normal', name="dense2")(Xm)
Xm = AlphaDropout(0.3)(Xm)
#Full Con 2
Xm = Dense(len(M_old), kernel_initializer='glorot_normal', name="dense3")(Xm)
#SoftMax
Xm = Activation('softmax')(Xm)
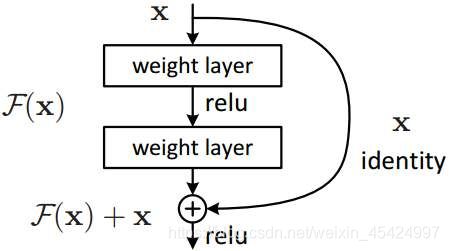
每个residual_stack由两个ResNet模块组成
def residual_stack(Xm,kennel_size,Seq,pool_size,sparse_factor):
#1*1 Conv Linear
Xm = Conv2D(32, (1, 1), padding='same', name=Seq+"_conv1", kernel_initializer='glorot_normal')(Xm)
Xm = BatchNormalization(name=Seq + "batch1")(Xm)
Xm = Activation('relu')(Xm)
#Residual Unit 1
Xm_shortcut = Xm
Xm = Conv2D(32, kennel_size, padding='same',name=Seq+"_conv2", kernel_initializer='glorot_normal')(Xm)
Xm = BatchNormalization(name=Seq + "batch2")(Xm)
Xm = Activation("relu")(Xm)
Xm = Conv2D(32, kennel_size, padding='same', name=Seq+"_conv3", kernel_initializer='glorot_normal')(Xm)
Xm = BatchNormalization(name=Seq + "batch3")(Xm)
Xm = Activation("relu")(Xm)
Xm = Conv2D(32, kennel_size, padding='same', name=Seq + "_conv4", kernel_initializer='glorot_normal')(Xm)
Xm = layers.add([Xm,Xm_shortcut])
Xm = Activation("relu")(Xm)
#Residual Unit 2
Xm_shortcut = Xm
Xm = Conv2D(32, kennel_size, padding='same',name=Seq+"_conv5", kernel_initializer='glorot_normal')(Xm)
Xm = BatchNormalization(name=Seq + "batch4")(Xm)
Xm = Activation("relu")(Xm)
Xm = Conv2D(32, kennel_size, padding='same', name=Seq+"_conv6", kernel_initializer='glorot_normal')(Xm)
Xm = BatchNormalization(name=Seq + "batch5")(Xm)
Xm = Activation("relu")(Xm)
Xm = Conv2D(32, kennel_size, padding='same', name=Seq + "_conv7", kernel_initializer='glorot_normal')(Xm)
Xm = layers.add([Xm,Xm_shortcut])
Xm = Activation("relu")(Xm)
#MaxPooling
Xm = MaxPooling2D(pool_size=pool_size, strides=pool_size, padding='valid')(Xm)
return Xm
训练中有几个需要注意的问题
1.上面设计的网络比较深,而数据量比较小(只有10w条),因此会出现train_loss不断下降,val_loss却抖动很大的情况,增加数据量到百万级别,比如用数据集
2018.01.OSC.0001_1024x2M.h5.tar.gz
就可以解决这个问题。(也可以去DeepSig的官网下:https://www.deepsig.ai/datasets)
2.学习率对网络性能的影响非常大。
网络瘦身
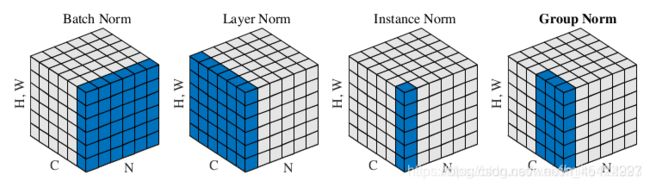
Network Slimming 可以在 不同粒度下进行。一般有kernel 维,channel维和layer维。“Learning Efficient Convolutional Networks through Network Slimming”就是在channel维进行卷积。在channel维进行剪枝的意思就是赋予每层的所有channel一个权重来衡量其重要程度。这个权重当然还得再loss里添加l1正则约束,使其稀疏。然后剪掉权值比较小的channel,同时被剪去的channel对应的输入输出卷积核的channel维同样也剪去。
在channel维进行剪枝有一个天然的优势,那就是BatchNormalization层的参数 γ \gamma γ,本身就可以作为上面提到的权重。
y ( k ) = γ ( k ) x ^ ( k ) + β ( k ) y^{(k)}=\gamma^{(k)} \hat{x}^{(k)}+\beta^{(k)} y(k)=γ(k)x^(k)+β(k)
而且在2D卷积里,BatchNormalization本身就是在channel维进行的即每个 γ \gamma γ值就对应一个channel。
而且Keras里对于BN层的 γ \gamma γ直接可以设置其正则化方式
Xm = BatchNormalization(axis=-1, name=Seq + "batch1",gamma_regularizer=l1(sparse_facor))(Xm)
sparser_factor越大表示对 γ \gamma γ的惩罚越大
贴一张论文中的图
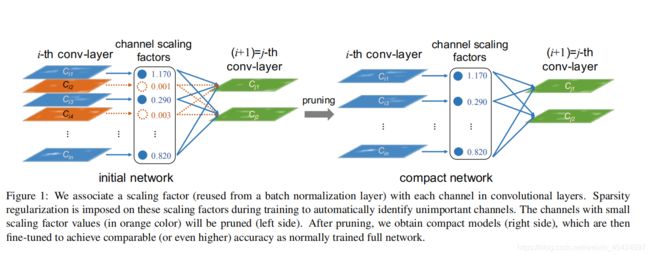
剪枝的代码实现
-
对于已经训练好的模型,称之为origin_net。剪枝的比例是基于全部Layer的数值大小,如果某一BN层的 γ \gamma γ都特别大,那这层的channel就都保持不动,如果某一BN层的 γ \gamma γ都非常小,那么可能这层的channel只会留下一个。因此首先遍历layers,获取所有BN层的channel 对应的 γ \gamma γ,然后对其从小到大排序。再根据剪枝比例(percent),去确定 γ \gamma γ的阈值。然后再遍历一遍layers,将每一BN层 γ \gamma γ小于阈值的置为0,大于的置为1。上述操作封装在函数freeze_build_cap(model,percent) 中,返回每一BN层剩余的channel数量 cap(channel after pruning),以及指示哪些channel被保留的cap_mask.
-
根据cap新建一个剪枝后的网络compact_net,其与origin_net结构完全一致,只是每层的维度不一致,其每一层的输入输出维度对应于origin_model剩余的channel数量。
-
给compact_net的Conv2D与BN层权重赋origin_net对应的值。
a) BN层赋值很简单,直接根据cap_mask把origin_net BN 层对应的 γ \gamma γ, β \beta β,均值,方差复制过来就行。(Keras里给某个layer的权重赋值使用的是set_weights(w)操作,w是一个list,必须包含layer的所有权重的值,比如BN层的参数就有四个,那么w就必须包含四个array)。
b) 给Conv2D层赋值比较麻烦。Conv2D的参数有卷积核的权重以及偏差,卷积核的维度为[height,weight,in_channel,out_channel],所以其不仅要考虑上一个layer剪掉了哪些channel,还要考虑下一个layer剪掉了哪些channel。因此需要把网络每一层剪枝后的维度列出来再去分析。因此对于不同网络,给Conv2D赋值的策略是不一样的。这里只针对本文提出的网络进行分析。
c) 本文的网络一共由6个ResNet单元组成。其一共有15个常规Conv2D和BN层,每个Conv2D层后面都会跟一个BN层。同时还有6个KeepDim Conv2D卷积层。
因为经过裁剪后,ResNet的输出维度可能无法与输入x的维度相对应,这样F(x)+x的时候维度就对不上,所以在相加的前一步添加一个KeepDim Conv2D卷积层来对齐输入x的维度。
d)首先,遍历所有层,定义变量count,每次发现Conv2D层就加1,发现KeepDim Conv2D层不计数。并且将每个卷积核输入和输出连接的BN层列出来,如下表所示
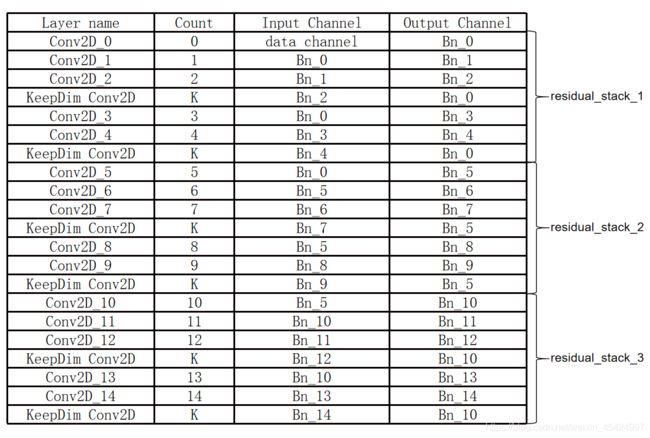
然后对compact_net的每个Conv2D根据其 Input/Output Channel 对应的Bn通道,去将origin_net的权重复制过来。比如对于第一个Conv2D_0,其输入channel对应原始数据,所以将origin_net的Conv2D_0的 in_channel维全部复制过来。其输出channel则由第零个BN层的 γ \gamma γ值决定。 γ \gamma γ是一个向量。比如Bn_0的 γ \gamma γ只有1,3,4,5处为1,呢么就将origin_net的Conv2D_0的[:,:,:,[1,3,4,5]]的值赋给compact_net的第一个Conv2D_0。
e) 个人认为对所有compact_net卷积核赋值的策略有两种.- 列出上表,然后根据表创建一个字典,比如count等于2的时候,Input Channel对应Bn_0,Out Channel对应Bn_1。再比如对于第一个出现的K,Input Channel对应Bn_2,Out Channel对应Bn_0.
- 寻找规律写出算法。比如Conv2D_x的Bn_x对应的x值,就为count值。本文采取的就是这种类似找规律的方法来赋值。
-
compact_net的全连接层开放,重新训练。
Result
剪枝50%
原始模型
Total params: 105,989
Trainable params: 103,749
Non-trainable params: 2,240
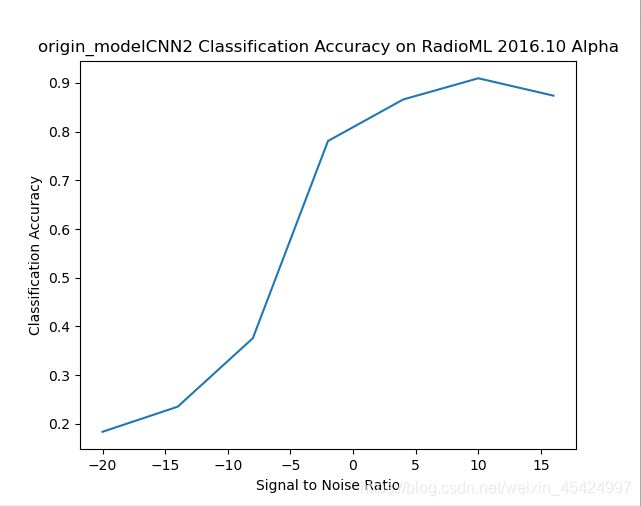
剪枝后模型
Total params: 74,625
Trainable params: 73,963
Non-trainable params: 662
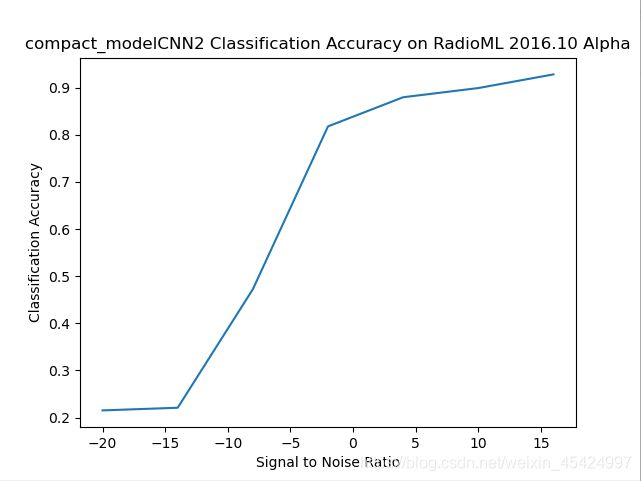
代码看这里
https://github.com/Woshiwzl1997/Network-Slimming-Using-Keras
有时候模型在测试集合效果很差,但训练集很稳定,推测与数据太少有关。多运行几次会得到比较好的结果。
有朋友反应数据集下载不了,我这里只有RML2016的数据。
链接:https://pan.baidu.com/s/1jTEF-uF9osM01746vZKHcg
提取码:ir1d