Apache Spark 机器学习 管道 3
Apache Spark的机器学习管道提供一个统一的、高级的APIs集合,该APIs集合是以数据框架(Datagrams)为基础,帮助开发人员创建或者优化一个用于实际环境的机器学习的管道。
管道(Pipeline)的基本概念
Spark机器学习类库MLlib提供丰富的用于机器学习的算法,使得机器学习更加容易地在一个管道、工作流程中综合多种不同的算法,以提供更加强大的机器学习能力,管道的基本概念如下所示:
|
数据框架
机器学习能被广泛地运用于各种不同的数据类型,例如,文本、向量集、图像以及结构化的数据,Spark机器学习的API适配Spark SQL的DataFrame就是为了支持各种不同的数据类型。
管道的组件
如前面所述,管道包括的组件是Transformers、Estimators。
转换器(Transformers)
该组件是用于对DataFrame执行转换,是一个抽象的结构,其具体实现包括特征转换器以及学习的模型,在技术上,一个转换器Transformer实现了其方法transform,该方法对输入的DataFrame执行转换成另外一个DataFrame输出,一般情况下,输出的DataFrame增加了列或者减少了列,其特性描述如下所示:
|
估算器(Estimators)
估算器是一个学习算法或者任何算法的抽象,是用于拟合(fit)数据或者训练(train)数据,技术上,一个估算器Estimator实现了方法fit,该方法接受一个DataFrame作为输入,然后,产生一个模型作为输出,其对应一个已学习的模型的Transformer,例如,LogisticRegression逻辑回归类是一个估算器Estimator,其调用fit方法,训练成一个LogisticRegressionModel逻辑回归模型类,这是一个模型、也是一个Transformer转换器。
管道组件的属性
目前转换器的Transformer.transform()方法以及估算器的Estimator.fit()方法都是无状态的,在未来的版本中,可能会提供有状态算法的支持。
然而,每个转换器实例、每个估算器实例都包括一个唯一性的ID,该机制在指定参数的时候发生非常大的作用。
管道(Pipeline)
机器学习通常会按照顺序地运行一系列的算法处理数据以及从数据中学习,例如,一个简单的文本文档的处理包括如下所示的阶段:
|
机器学习类库MLlib将这些阶段的工作流程定义成一个管道,管道中包括一系列的PipelineStages(管道阶段,Transformers或者Estimators),其按照指定的顺序执行。
工作原理
如前面所述,一个管道是由一连串的阶段组成,每个阶段是一个Transformer转换器或者是一个Estimator估算器,这些阶段是按照指定的顺序执行,输入的数据框架DataFrame经过每个阶段,都会被转换成新的数据框架DataFrame,如果是Transformer 阶段,则执行其transform方法,如果Estimator阶段,则执行其fit方法、并且生成一个Transformer(是一个已经训练完成、已拟合的模型,PipelineModel),最后,调用输出模型的transfrom方法对全新的样本数据进行预测。
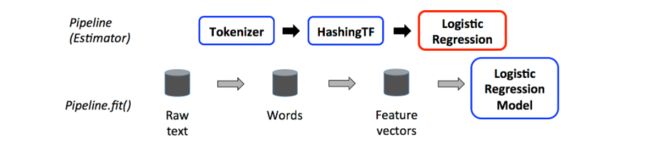
如上所示,蓝色框内指的是Transformer、红色框内指的是Estimator,圆柱表示数据框架DataFrame用于存储数据集。
其中,上层的Tokenizer以及HashingTF表示两个Transformer,LogisticRegression表示一个Estimator,下层表示通过管道的数据流。
首先,调用的是Pipeline的fit方法,该方法处理原始输入的DataFrame(数据样本),其包括文本文档及其对应的标签,调用Tokenizer的transform方法将上一步骤的文本文档分割成单词,输出包括新列单词词汇的新DataFrame,调用HashingTF的transform方法将上一步骤的新列单词词汇转换成特征向量集,输出包括新列特征向量集的新DataFrame,调用LogisticRegression的fit方法对上一步骤的特征向量集进行模型训练,输出一个LogisticRegressionModel已经拟合的、训练完成的模型。
由以上的分析可知,Pipeline管道是一个Transformer转换器,调用其fit方法,可以输出一个训练完成的PipelineModel模型。

如上所示,模型训练完成之后,调用PipelineModel的transform方法执行数据样本测试阶段,并用于对全新的数据进行预测。其中,PipelineModel与Pipeline包含的阶段保持一致。
其中,上层显示,Tokenizer、HashingTF以及LogisticRegressionModel这些蓝色框内的组件已经全部是Transformer。
其中,下层显示,调用PipelineModel的transform方法对测试样本数据集进行预测分析,随着数据流的流向,按照阶段的顺序执行每个阶段,每个阶段的transform方法更新DataFrame数据框架中的数据集,最后,输出特征向量集对应的预测结果Predictions标签数据集。
由以上的分析可知,Pipeline管道以及PipelineModel管道模型分别用于训练数据以及测试数据,两者的数据流都经历了相同的处理步骤。
管道其他性质
为了提高管道的执行效率以及管道的可用性,管道也提供以下的属性支持:
| DAG管道 管道包括的阶段是以一个顺序的数组结构进行存储,如前面所述的管道类型是线性管道,其以固定顺序执行管道中的阶段,非线性管道包括的阶段对应的数据流图形成一个DAG(Directed Acyclic Graph),该图是有向非循环图,也就是,所有阶段对应的数据流不会形成一个闭环,该图是以每个阶段中的列的名称进行隐式地指定,如果管道形成一个DAG,则管道包括的阶段是拓扑(图理论)的顺序指定 |
| 运行时检查 由于管道是对包括不同数据类型的数据框架DataFrame进行操作,所以,管道做不到在编译阶段就对数据类型进行合法性校验,Pipeline与PipelineModel是在执行管道阶段之前对数据类型进行运行时的合法性校验,开发者可以在数据框架DataFrame中定义对列的合法性校验规则 |
| 唯一性管道阶段 管道包括的每个阶段在整个机器学习过程中必须保持唯一性的实例,相同的实例不能在相同的管道中使用两次,但是相同类型的两个不同实例可以在管道重复使用,因为不同的实例具有不同的唯一性ID |
管道的实例代码1



如上所示,创建了两个模型,分别对模型设置最大迭代次数以及设置参数,使用模型2进行测试数据集的预测分析。
管道的实例代码2


如上所示,创建了一个管道,使用管道对测试数据集进行预测分析。
(未完待续)