【Spark】Spark的机器学习算法库——Spark MLilb
文章目录
- 1 导入
-
- 1.1 基本概念
- 1.2 spark.mlib和spark.ml
- 2 机器学习工作流(ML Pipelines)
-
- 2.1 基本概念
- 2.2 工作流的构建
-
-
- 构建SparkSession对象
- 引入要包含的包
- 构建训练数据集
- 定义Pipeline中的各个工作流阶段PipelineStage
- 创建一个Pipeline
- 构建测试数据
- 预测
-
- 3 特征抽取、转化和选择
-
- 3.1. 特征抽取TF-IDF (HashingTF and IDF)
- 3.2 特征变换–标签和索引的转化
-
- StringIndexer
- IndexToString
- OneHotEncoder
- 4 分类和回归
-
- 4.1 决策树分类器
1 导入
1.1 基本概念
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
- 算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
- 特征化工具:特征提取、转化、降维,和选择的工具;
- 管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
- 持久性:保存和加载算法,模型和管道;
- 实用工具:线性代数,统计,数据处理等工具。
1.2 spark.mlib和spark.ml
Spark机器学习库从1.2版本以后被分为两个包:
- spark.mllib 包含基于RDD的原始算法API。Spark MLlib历史比较长,在1.0以前的版本即已经包含了,提供的算法实现都是基于原始的RDD。
- spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline弥补了原始MLlib库的不足,向用户提供了一个基于DataFrame的机器学习工作流式API套件。
2 机器学习工作流(ML Pipelines)
2.1 基本概念
1、DataFrame:使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。 较之RDD,包含了schema信息,更类似传统数据库中的二维表格。它被ML Pipeline用来存储源数据。例如,DataFrame中的列可以是存储的文本,特征向量,真实标签和预测的标签等。
2、Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个Transformer。它可以把一个不包含预测标签的测试数据集DataFrame打上标签,转化成另一个包含预测标签的DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
3、Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在Pipeline里通常是被用来操作DataFrame数据,并生产一个Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
4、Parameter:Parameter被用来设置Transformer或者Estimator的参数。现在所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对。
5、PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
2.2 工作流的构建
下面以逻辑斯蒂回归为例,构建一个典型的机器学习过程,来具体介绍一下工作流是如何应用的。
我们的目的是查找出所有包含“spark”的句子,即将包含“spark”的句子的标签设为1,没有“spark”的句子的标签设为0。
Spark2.0以上版本的spark-shell在启动时会自动创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来,如下代码段所示:
构建SparkSession对象
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().
master("local").
appName("my App Name").
getOrCreate()
引入要包含的包
import org.apache.spark.ml.feature._
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
构建训练数据集
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
定义Pipeline中的各个工作流阶段PipelineStage
包括转换器和评估器,具体的包含tokenizer, hashingTF和lr三个步骤
val tokenizer = new Tokenizer().
setInputCol("text").
setOutputCol("words")
val hashingTF = new HashingTF().
setNumFeatures(1000).
setInputCol(tokenizer.getOutputCol).
setOutputCol("features")
val lr = new LogisticRegression().
setMaxIter(10).
setRegParam(0.01)
创建一个Pipeline
val pipeline = new Pipeline().
setStages(Array(tokenizer, hashingTF, lr))
现在构建的Pipeline本质上是一个Estimator,在它的fit()方法运行之后,它将产生一个PipelineModel,它是一个Transformer
val model = pipeline.fit(training)
构建测试数据
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark a"),
(7L, "apache hadoop")
)).toDF("id", "text")
预测
model.transform(test).
select("id", "text", "probability", "prediction").
collect().
foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double)
=>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
3 特征抽取、转化和选择
3.1. 特征抽取TF-IDF (HashingTF and IDF)
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
TF: HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
IDF: IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
在下面的任务中,我们以一组句子开始,完成句子的特征提取与转换。
1、首先,导入TFIDF所需要的包:
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
2、开启RDD的隐式转换导入包:
import spark.implicits._
3、准备工作完成后,我们创建一个简单的DataFrame,每一个句子代表一个文档。
val sentenceData = spark.createDataFrame(Seq(
(0, "I heard about Spark and I love Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat")
)).toDF("label", "sentence")
4、在得到文档集合后,即可用tokenizer对句子进行分词。
val tokenizer = new Tokenizer().
setInputCol("sentence").
setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
wordsData.show(false)

5、得到分词后的文档序列后,即可使用HashingTF的transform()方法把句子哈希成特征向量,这里设置哈希表的桶数为2000。
val hashingTF = new HashingTF().
setInputCol("words").
setOutputCol("rawFeatures").
setNumFeatures(2000)
val featurizedData = hashingTF.transform(wordsData)
featurizedData.select("rawFeatures").show(false)

可以看到,分词序列被变换成一个稀疏特征向量,其中每个单词都被散列成了一个不同的索引值,特征向量在某一维度上的值即该词汇在文档中出现的次数。
6、最后,使用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力,IDF是一个Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel。
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
很显然,IDFModel是一个Transformer,调用它的transform()方法,即可得到每一个单词对应的TF-IDF度量值。
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features", "label").take(3).foreach(println)

3.2 特征变换–标签和索引的转化
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数索引,或是在计算结束后将整数索引还原为相应的标签。
Spark ML包中提供了几个相关的转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下。
1、SparkSession由其伴生对象的builder()方法创建
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().
master("local").
appName("my App Name").
getOrCreate()
2、开启RDD的隐式转换:
import spark.implicits._
StringIndexer
StringIndexer转换器可以把一列类别型的特征(或标签)进行编码,使其数值化,索引的范围从0开始,该过程可以使得相应的特征索引化,使得某些无法接受类别型特征的算法可以使用,并提高诸如决策树等机器学习算法的效率。
1、首先,引入必要的包,并创建一个简单的DataFrame,它只包含一个id列和一个标签列category:
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel}
val df1 = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c"))).toDF("id", "category")
2、随后,我们创建一个StringIndexer对象,设定输入输出列名,其余参数采用默认值,并对这个DataFrame进行训练,产生StringIndexerModel对象:
val indexer = new StringIndexer().
setInputCol("category").
setOutputCol("categoryIndex")
val model = indexer.fit(df1)
3、随后即可利用该对象对DataFrame进行转换操作,可以看到StringIndexerModel依次按照出现频率的高低,把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为2。
val indexed1 = model.transform(df1)
indexed1.show()

IndexToString
与StringIndexer相对应,IndexToString的作用是把标签索引的一列重新映射回原有的字符型标签。
其主要使用场景一般都是和StringIndexer配合,先用StringIndexer将标签转化成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转化成原有的字符标签。当然,也可以另外定义其他的标签。
1、首先,和StringIndexer的实验相同,我们用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上,构建出新的DataFrame。
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
val model = new StringIndexer().
setInputCol("category").
setOutputCol("categoryIndex").
fit(df)
val indexed = model.transform(df)
2、随后,创建IndexToString对象,读取“categoryIndex”上的标签索引,获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。最后,通过输出“originalCategory”列,可以看到数据集中原有的字符标签。
import org.apache.spark.ml.feature.{IndexToString}
val converter = new IndexToString().
setInputCol("categoryIndex").
setOutputCol("originalCategory")
val converted = converter.transform(indexed)
converted.select("id", "originalCategory").show()
OneHotEncoder
独热编码(One-Hot Encoding)是指把一列类别性特征(或称名词性特征,nominal/categorical features)映射成一系列的二元连续特征的过程,原有的类别性特征有几种可能取值,这一特征就会被映射成几个二元连续特征,每一个特征代表一种取值,若该样本表现出该特征,则取1,否则取0。
1、首先创建一个DataFrame,其包含一列类别性特征,需要注意的是,在使用OneHotEncoder进行转换前,DataFrame需要先使用StringIndexer将原始标签数值化:
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c"),
(6, "d"),
(7, "d"),
(8, "d"),
(9, "d"),
(10, "e"),
(11, "e"),
(12, "e"),
(13, "e"),
(14, "e")
)).toDF("id", "category")
val indexer = new StringIndexer().
setInputCol("category").
setOutputCol("categoryIndex").
fit(df)
val indexed = indexer.transform(df)
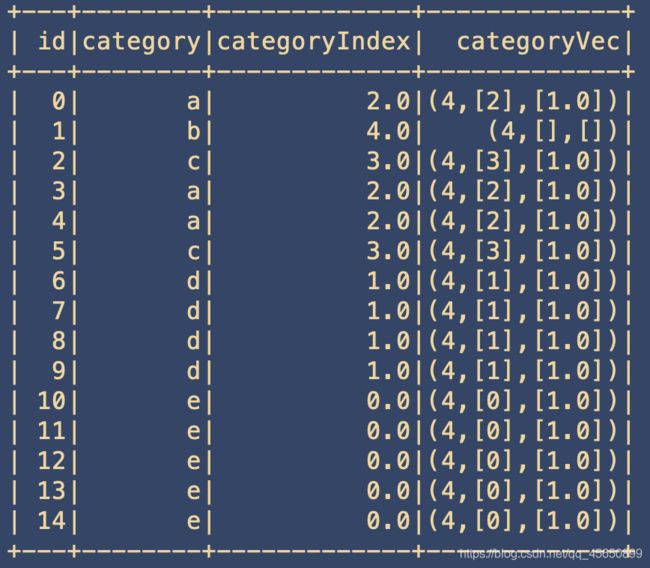
2、随后,我们创建OneHotEncoder对象对处理后的DataFrame进行编码,可以看见,编码后的二进制特征呈稀疏向量形式,与StringIndexer编码的顺序相同,需注意的是最后一个Category(”b”)被编码为全0向量,若希望”b”也占有一个二进制特征,则可在创建OneHotEncoder时指定setDropLast(false)。
val encoder = new OneHotEncoder().
setInputCol("categoryIndex").
setOutputCol("categoryVec")
val encoded = encoder.fit(indexed).transform(indexed)
encoded.show()
4 分类和回归
4.1 决策树分类器
我们以iris数据集(iris)为例进行分析。iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。决策树可以用于分类和回归,接下来我们将在代码中分别进行介绍。
1、导入包
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.{IndexToString,StringIndexer,VectorIndexer}
2、读取数据
import spark.implicits._
case class Iris(features: org.apache.spark.ml.linalg.Vector, label: String)
// 读取文本文件,第一个map把每行的数据用“,”隔开,比如在我们的数据集中,每行被分成了5部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的分类;我们这里把特征存储在Vector中,创建一个Iris模式的RDD,然后转化成dataframe;
val data = spark.sparkContext.textFile("file:///usr/local/spark/data/iris.data").map(_.split(",")).map(p => Iris(Vectors.dense(p(0).toDouble,p(1).toDouble,p(2).toDouble, p(3).toDouble),p(4).toString())).toDF()
// 然后把刚刚得到的数据注册成一个表iris,
data.createOrReplaceTempView("iris")
val df = spark.sql("select * from iris")
df.map(t => t(1)+":"+t(0)).collect().foreach(println)
3、进一步处理特征和标签,以及数据分组
//分别获取标签列和特征列,进行索引,并进行了重命名。
val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(df)
val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(df)
// 这里我们设置一个labelConverter,目的是把预测的类别重新转化成字符型的。
val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labels)
// 接下来,我们把数据集随机分成训练集和测试集,其中训练集占70%
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
4、构建决策树分类模型
// 导入所需要的包
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
// 训练决策树模型,这里我们可以通过setter的方法来设置决策树的参数
val dtClassifier = new DecisionTreeClassifier().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures")
// 在pipeline中进行设置
val pipelinedClassifier = new Pipeline().setStages(Array(labelIndexer, featureIndexer, dtClassifier, labelConverter))
// 训练决策树模型
val modelClassifier = pipelinedClassifier.fit(trainingData)
// 进行预测
val predictionsClassifier = modelClassifier.transform(testData)
// 查看部分预测的结果
predictionsClassifier.select("predictedLabel", "label", "features").show(20)
+---------------+---------------+-----------------+
| predictedLabel| label| features|
+---------------+---------------+-----------------+
| Iris-setosa| Iris-setosa|[4.4,2.9,1.4,0.2]|
| Iris-setosa| Iris-setosa|[4.6,3.6,1.0,0.2]|
| Iris-virginica|Iris-versicolor|[4.9,2.4,3.3,1.0]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[5.0,3.5,1.6,0.6]|
| Iris-setosa| Iris-setosa|[5.2,3.5,1.5,0.2]|
| Iris-setosa| Iris-setosa|[5.2,4.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[5.4,3.4,1.7,0.2]|
| Iris-setosa| Iris-setosa|[5.4,3.7,1.5,0.2]|
| Iris-setosa| Iris-setosa|[5.4,3.9,1.7,0.4]|
|Iris-versicolor|Iris-versicolor|[5.5,2.3,4.0,1.3]|
| Iris-setosa| Iris-setosa|[5.7,4.4,1.5,0.4]|
| Iris-virginica|Iris-versicolor|[5.9,3.2,4.8,1.8]|
|Iris-versicolor|Iris-versicolor|[6.1,2.8,4.0,1.3]|
|Iris-versicolor|Iris-versicolor|[6.2,2.2,4.5,1.5]|
| Iris-virginica|Iris-versicolor|[6.3,2.5,4.9,1.5]|
|Iris-versicolor|Iris-versicolor|[6.3,3.3,4.7,1.6]|
|Iris-versicolor|Iris-versicolor|[6.4,2.9,4.3,1.3]|
|Iris-versicolor|Iris-versicolor|[6.5,2.8,4.6,1.5]|
+---------------+---------------+-----------------+
only showing top 20 rows
5、评估决策树分类模型
val evaluatorClassifier = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("accuracy")
//进行精度评估
val accuracy = evaluatorClassifier.evaluate(predictionsClassifier)
println("Test Error = " + (1.0 - accuracy))
Test Error = 0.1351351351351351
val treeModelClassifier = modelClassifier.stages(2).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + treeModelClassifier.toDebugString)
Learned classification tree model:
DecisionTreeClassificationModel (uid=dtc_029ea28aceb1) of depth 5 with 13 nodes
If (feature 2 <= 1.9)
Predict: 2.0
Else (feature 2 > 1.9)
If (feature 2 <= 4.7)
If (feature 0 <= 4.9)
Predict: 1.0
Else (feature 0 > 4.9)
Predict: 0.0
Else (feature 2 > 4.7)
If (feature 3 <= 1.6)
If (feature 2 <= 4.8)
Predict: 0.0
Else (feature 2 > 4.8)
If (feature 0 <= 6.0)
Predict: 0.0
Else (feature 0 > 6.0)
Predict: 1.0
Else (feature 3 > 1.6)
Predict: 1.0
6、构建决策树回归模型
// 导入所需要的包
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.regression.DecisionTreeRegressionModel
import org.apache.spark.ml.regression.DecisionTreeRegressor
// 训练决策树模型
val dtRegressor = new DecisionTreeRegressor().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures")
// 在pipeline中进行设置
val pipelineRegressor = new Pipeline().setStages(Array(labelIndexer, featureIndexer, dtRegressor, labelConverter))
// 训练决策树模型
val modelRegressor = pipelineRegressor.fit(trainingData)
// 进行预测
val predictionsRegressor = modelRegressor.transform(testData)
// 查看部分预测结果
predictionsRegressor.select("predictedLabel", "label", "features").show(20)
+---------------+---------------+-----------------+
| predictedLabel| label| features|
+---------------+---------------+-----------------+
| Iris-setosa| Iris-setosa|[4.4,2.9,1.4,0.2]|
| Iris-setosa| Iris-setosa|[4.6,3.6,1.0,0.2]|
| Iris-virginica|Iris-versicolor|[4.9,2.4,3.3,1.0]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[4.9,3.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[5.0,3.5,1.6,0.6]|
| Iris-setosa| Iris-setosa|[5.2,3.5,1.5,0.2]|
| Iris-setosa| Iris-setosa|[5.2,4.1,1.5,0.1]|
| Iris-setosa| Iris-setosa|[5.4,3.4,1.7,0.2]|
| Iris-setosa| Iris-setosa|[5.4,3.7,1.5,0.2]|
| Iris-setosa| Iris-setosa|[5.4,3.9,1.7,0.4]|
|Iris-versicolor|Iris-versicolor|[5.5,2.3,4.0,1.3]|
| Iris-setosa| Iris-setosa|[5.7,4.4,1.5,0.4]|
| Iris-virginica|Iris-versicolor|[5.9,3.2,4.8,1.8]|
|Iris-versicolor|Iris-versicolor|[6.1,2.8,4.0,1.3]|
|Iris-versicolor|Iris-versicolor|[6.2,2.2,4.5,1.5]|
| Iris-virginica|Iris-versicolor|[6.3,2.5,4.9,1.5]|
|Iris-versicolor|Iris-versicolor|[6.3,3.3,4.7,1.6]|
|Iris-versicolor|Iris-versicolor|[6.4,2.9,4.3,1.3]|
|Iris-versicolor|Iris-versicolor|[6.5,2.8,4.6,1.5]|
+---------------+---------------+-----------------+
only showing top 20 rows
7、评估决策树回归模型
val evaluatorRegressor = new RegressionEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("rmse")
val rmse = evaluatorRegressor.evaluate(predictionsRegressor)
println("Root Mean Squared Error (RMSE) on test data = " + rmse)
Root Mean Squared Error (RMSE) on test data = 0.3676073110469039
val treeModelRegressor = modelRegressor.stages(2).asInstanceOf[DecisionTreeRegressionModel]
println("Learned regression tree model:\n" + treeModelRegressor.toDebugString)
Learned regression tree model:DecisionTreeRegressionModel (uid=dtr_358e08c37f0c) of depth 5 with 13 nodes
If (feature 2 <= 1.9)
Predict: 2.0
Else (feature 2 > 1.9)
If (feature 2 <= 4.7)
If (feature 0 <= 4.9)
Predict: 1.0
Else (feature 0 > 4.9)
Predict: 0.0
Else (feature 2 > 4.7)
If (feature 3 <= 1.6)
If (feature 2 <= 4.8)
Predict: 0.0
Else (feature 2 > 4.8)
If (feature 0 <= 6.0)
Predict: 0.5
Else (feature 0 > 6.0)
Predict: 1.0
Else (feature 3 > 1.6)
Predict: 1.0