【论文精读】基于流序列的基于残差图卷积网络的匿名网络流量识别
Flow Sequence-Based Anonymity Network Traffic Identification with Residual Graph Convolutional Networks
基于流序列的基于残差图卷积网络的匿名网络流量识别
摘要
从网络流量中识别匿名服务是网络管理和安全的关键任务。
目前,一些基于深度学习的工作已经在流量分析方面取得了优异的性能,特别是那些基于流量序列(FS) 的工作,它利用了流的信息和特征。
然而,这些模型仍然面临着严峻的挑战,因为缺乏一种机制来考虑流之间的关系,导致错误地将 FS 中不相关的流识别为识别流量的线索。
在本文中,我们提出了一种新的基于 FS 的匿名网络流量识别框架来解决这个问题,它利用残差图卷积网络 (ResGCN) 来利用流之间的关系进行 FS 特征提取。 此外,我们设计了一种实用的方案来预处理真实世界流量的原始数据,进一步提高了识别性能和效率。 两个真实世界流量数据集的实验结果表明,我们的方法大大优于最先进的方法。
Ⅰ.引言
1. 匿名网络
由于对保护个人网络元数据的需求不断增加,匿名网络越来越受欢迎。 它们为用户提供了一种在线实现匿名的方式。 匿名网络在通信中使用加密和混淆的方法来隐藏传输内容和用户的真实身份。 然而,在使通信更难追踪和识别的同时,匿名网络也为非法和犯罪活动提供了隐藏空间 。 因此,有必要设计一个有效的流量分析系统来监督匿名网络。
2. 基于人工智能的流量分析
基于人工智能的流量分析方法通过监控流量数据的基本特征和统计特征,更好地应对复杂多变的网络流量。
此外,我们注意到许多研究表明流量数据具有明显的时空相关性。
例如,当用户使用匿名网络浏览网页时,短时间内会出现很多相关的应用请求。 这些应用请求会在流量中产生相应的多个流。 基于时空相关性,一些研究人员提出了方法来建立流序列以实现更好的流量分析性能。
但是,它们都忽略了流之间的一些关键关系,导致错误地将流序列中不相关的流作为流量识别的线索。因此,为了使识别更加准确,我们应该利用这些关系从流序列中提取特征。
3. 流之间的关系
- 属性关系。 同一个应用请求产生的正向流(F-flow)和对应的反向流(R-flow)具有属性关系。
- 时间关系。 时间关系表示流之间的时间间隔。 间隔越长,它们之间的相关性越低。
4. 能够在特征提取过程中考虑流之间的关系的 DL 算法:图卷积网络(GCN)
由于当前基于 DL 算法(例如 CNN 和 LSTM)实现的方法的结构限制,它们无法在特征提取过程中考虑这两种关系。
图卷积网络(GCN)通过不同权重的边连接相邻节点,并通过计算相邻节点的特征求和来更新特征表示,提供了一种根据它们的关系连接流来解决这个问题的方法。
5. 本文概述
在本文中,我们提出了一种基于 残差图卷积网络 (ResGCN) 的新型基于流序列的流量识别框架。 我们将连续的多个流(即流序列)作为输入特征。 每个流都是一个节点,根据流之间的关系设置边的权重。 为了更好地保留梯度的空间结构,我们采用残差结构来提取特征。
此外,作为识别真实世界流量的端到端框架,它根据流量分割方案从原始流量中提取丰富的特征(例如,统计特征、基本特征等),并使用Light Gradient Boosting Machine( LightGBM)算法选择最优的特征组合,提高模型性能和效率。
贡献如下:
-
我们提出利用流之间的属性和时间关系,实现更合理和有效的流序列特征提取以进行流量识别。
我们假设图卷积网络 (GCN) 适合我们的目的,并提出了一种新颖的 RESGCN 模型来识别不同的网络服务。 据我们所知,这是该方向的首次调查。
-
我们设计了一个实用的方案来处理真实世界的原始流量数据。 它考虑了流分割,用于生成和丰富原始流量的流特征,以及基于 LightGBM 的特征组合,避免了无关紧要的特征降低模型性能和效率。 【预处理】
-
我们评估了两个真实世界流量数据集的框架。 实验结果表明,我们的方法比其他方法具有更优异的分类性能,适用于识别不同的网络服务。
Ⅱ. 相关工作
匿名网络流量的识别是典型的流分类任务。
Ⅲ. 问题制定和方法概述
在本节中,我们首先提供流量中的流(flow)背景。 然后,我们介绍了 基于ML的特征选择算法 和 基于DL的特征提取算法 的预备知识。 最后,我们概述了我们识别网络流量中各种匿名服务的方法。
A. 流量生成
1. 流量
在分组交换网络中,「流量」是在两个主机之间携带信息的一系列分组。
「原始流量数据」被捕获并以 pcap(数据包捕获的缩写)格式存储。
2. 加密流量的统计特征
作为一种加密流量,直接分析匿名网络流量的pcap文件更难识别不同的服务。 因此,有必要对统计特征进行计算和提取,以丰富每个流的特征信息。
加密流量的统计特征是通过 Layer 2 到 Layer 4 的 header 特征计算出来的,不受 Layer 7 任何加密的影响。
这些统计特征从多方面反映了流量的特征。
到达间隔时间(IAT)表示数据包间隔; Layer 3的最大、最小和平均包大小反映了流量的包大小特征; packet length (PL) 表示每个流从头开始产生的数据包的长度。
3. 特征提取
统计特征是使用 轻量级流量特征提取工具 Tranalyzer2 计算。
(1)特征提取的流序列模型
为了保留原始流量的时空相关性,我们需要在提取期间根据时间戳顺序存储生成的流量。
-
如图1所示,我们将连续的 I 个流作为一个流序列,其中每个流总共包含 J 个特征。 原始流量由 K 个流序列组成,每个序列与前一个序列(Kh , Kh+1)在时间上是连续的。
由于同一类型的网络行为往往会持续一定时间,构建流序列进行分析成为提高分类性能的有效方法。

(2)流量提取要考虑的两个要素
① 流之间的「属性、时间」关系
显然,每个序列中的流(Ih, Ih+1)之间存在一些关系(即属性和时间关系)。
如果在特征提取过程中能够考虑到这些关系,分类器网络的设计就会更加合理有效。
② 变量
许多变量会影响流生成过程中生成的结果。
- 可以根据不同的持续时间或数据包大小对流进行分段,直接影响相关统计的计算结果。
- 生成的流包含不同的统计特征,但有些可能对流量识别没有意义。
(3) 性能评估:有效性和及时性
要达到最佳的流量生成效果,我们应该考虑以下两个方面:
- 有效性:指分类器可以通过使用生成的流来实现出色的分类性能。
- 及时性:意味着可以尽快识别匿名服务。
因此,基于有效性和及时性,不同分割方法和所选特征的性能将在第V-C节中进行综合评估。
B. 用于特征选择的 LightGBM
1. 特征选择的作用
特征选择是去除生成流中不重要的特征,可以使生成的结果更符合有效性和时效性。
「有效性」:不重要的特征在某些条件下可以被表征为噪声,对识别结果产生不利影响。
「时效性」:去除这些特征可以减少流生成过程中的统计计算,加快流生成速度。 此外,低维特征也会降低特征提取网络的复杂度和分类时间。
2. 特征选择算法:LightGBM
LightGBM 是一种基于梯度提升决策树 (GBDT) 的机器学习算法。
GBDT 算法在训练过程中对特征的重要性进行排序,因此适合特征选择任务。
(1)传统的 GBDT 算法耗时
传统的基于 GBDT 的算法(例如 PGBRT 和 XGBoost)取得了良好的性能。 然而非常耗时,因为它们必须扫描每个特征的所有样本点以选择最佳分割点。
(2)基于梯度的单边采样(GOSS)算法
LightGBM通过基于梯度的单边采样(GOSS)算法大大降低了处理样本的时间复杂度。
GOSS算法的主要思想是 「梯度大的样本贡献更多的信息增益」。
因此,为了保持信息增益评估的准确性,可以 在对样本进行降采样时保留梯度大的样本 ,而 梯度小的样本按比例随机采样 。 由于减少了大量梯度较小的数据样本,计算量大大减少。
C. 用于特征提取的 GCN
图卷积网络(GCN)源自图谱理论,将卷积运算从基于网格的数据扩展到图结构数据。
在本研究中,我们将流序列看作一个图,每个流是图中的一个节点。 根据不同流之间的关系形成连接关系。
(1)一般情况:图拉普拉斯矩阵分解
基于图拉普拉斯矩阵的分解,图 G 上的信号 x 通过核 gθ 进行滤波:
gθ ∗Gx = gθ (L)x = gθ(U Λ UT )x = U gθ (Λ) UT x
其中 *G 表示图形卷积运算。 L 是图拉普拉斯矩阵。 拉普拉斯矩阵的特征值分解为 L = U ΛUT ,其中 Λ 为对角矩阵,U 为傅里叶基。
(2)图规模很大:切比雪夫多项式
然而,当图的规模很大时,分解变得非常困难。 为此,采用切比雪夫多项式来解决这个计算问题:

D. 本文方法
我们的方法包括一个新颖的流量分类器和流量获取、流量生成和特征选择的方案。
-
配置交换机镜像端口,使用流量抓包工具tcpdump获取实时流量,保存为一系列pcap文件。 可以根据实际情况设置不同的流量获取频率。
-
其次,使用流发生器来实现对pcap文件的快速实时分析。
根据预设规则,提取 pcap文件中的流。 流序列由多个连续的流组成,不同流之间的关系图也会在这一步生成。
-
然后,使用基于LightGBM的特征选择方法来选择最优的特征组合。
-
最后,所提出的 RESGCN 分类器利用生成的关系图来实现有效的匿名网络流量识别。
Ⅳ. 匿名网络流量识别框架
本节介绍匿名网络流量识别方法。 对原始流量数据进行处理后,采用RESGCN实现匿名服务识别。
所提出方法的概述如图 2 所示。

算法 1 总结了我们方法的过程。

A. 原始流量数据处理方案
原始流量数据作为 pcap 文件获得,需要对其进行处理才能更有效地应用于 RESGCN 模型。
数据处理包括以下四个步骤。
1.生成流量
在现实世界的流量中,如果不对持续时间长的流进行分割,将会对分类效率产生不利影响。
流分割方案可以分为两类:基于时间和基于大小。
「基于时间」的分段方案设置了流持续时间的上限,
「基于大小」的分段方案设置了最大数据包大小的上限。
因此,我们首先使用生成器通过流量分割方案从原始流量中生成丰富的特征。
然后,采用标准归一化方法来提高数据的可靠性:z= (x−μ) / σ ,其中 μ 表示原始数据的均值,σ 表示原始数据的标准差。
2. 组成流序列
研究表明,使用流序列将显着提高分类性能。
但是,包含流太少的流序列信息不足,无法达到理想的分类性能; 过多的流会带来更多的计算负担并降低效率。
因此,我们将「每个流序列设置为包含八个连续流」。
3. 构建图结构
通过图结构实现更有效、更合理的流序列分析。
我们从以下两个方面构建图结构。
(1)属性关系图 (ARG)
应用请求产生的 F-flow【正向流】 和 R-flow【反向流】 之间的关系被定义为属性关系。 这两个流量具有很强的相关性。
我们通过三元组确定两个流之间的属性关系(即流索引、传输字节和接收字节)。
在流生成过程中,根据源/目的IP、源/目的端口、协议 生成「流索引」。
但是,分段方案将流进行了拆分,导致存在多个连续的具有相同索引的流的情况。
如果两个流具有相同的流索引并且交换发送字节数和接收字节数,则它们具有属性关系。
基于三元组,我们将 F-flow和R-flow 连接起来,并将它们的属性关系权重设置为 1。
Ga(V, E) = 3TupleMatching.
(2)时间关系图 (TRG)
连续的多个流按照 流的产生时间 依次排列。 根据生成时间为不同的流构建 TRG。
如果流量的产生时间越近,则设置的权重越高。
具体地,在每个流序列中,第 A 个流为 flowa,第 B 个流为 flowb。 两个流之间的距离为 |B − A|,初始权重 为 1 / |B−A| 。只会连接相同方向(即正向或反向)的流。
Gt(V, E) = distance−1
为了更合理地设置每个流的时间关系权重,将每个流的时间关系权重输入到 Softmax 函数中,使得新的权重之和为1。
假设我们在一个流中有 n 个时间关系权重,我们可以将过程表示为:
w′1, w′2, …, w′n = Softmax(w1, w2, …, wn)

如图 3 所示,流序列中的不同流通过属性关系和时间关系连接起来。 建立 ARG 和 TRG 后,我们对这两个图的邻接矩阵进行归一化,得到融合图。
(4)选择特征组合
基于 LightGBM 的特征选择方法旨在选择最优的特征组合,可以有效避免无关紧要的特征降低分类器的性能和效率。
为了评估图 1 中第 j 个特征的重要性,我们采用 LightGBM 来计算 每个样本的梯度。
对于每个样本的梯度计算,O 是决策树中固定节点上的流。 节点分裂特征 j 在 d点 的方差增益表示为:
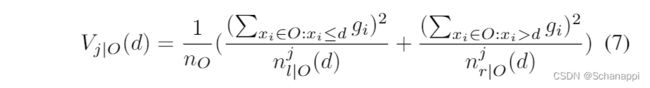

遍历每个特征的分割点,找到分割点 d*j = argmaxdVj(d) 并计算 最大信息增益 Vj(d*j), 然后根据分割点d *j 特征 j * 将数据分成左右子节点 。 经过排序和随机抽样操作后,信息增益由以下公式估算:

在后续的实验中,将采用不同的比较算法来实现特征选择,并对这些算法的性能进行比较。
B. 基于流序列的 RESGCN 分类器
我们在流的融合图上利用 GCN,它 允许流序列中的相关流交换信息。
RESGCN 的输入是 「经过特征选择后由八个连续流组成的流序列」,可以构造成上面提到的图。 每个流都被视为图中的一个节点。
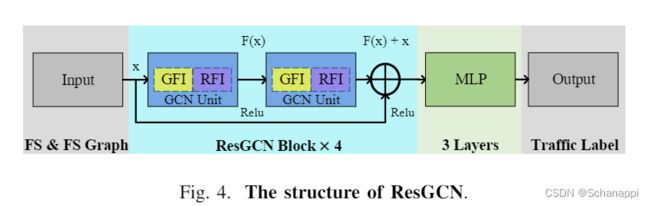
整个模型由四个 ResGCN 块和一个 3 层 MLP 组成。
1. ResGCN block
ResGCN block的结构如图4所示,它由两个GCN单元组成,中间使用了激活函数ReLU。
在ResGCN块中应用残差结构,可以解决随着网络深度增加而出现的退化问题。
GCN单元包括两个关键组件,即生成的特征交互模块(GFI)和相关流交互模块(RFI)。
-
GFI 是一个没有偏差的全连接层。它对每个流的特征(例如,数据包间隔、包大小等)进行线性变换,允许不同的特征进行交互。
-
RFI 使相关流能够基于关系图交换信息。
根据上面提到的融合图,这两个模块可以对不同的特征和相关的流进行有效的信息交互。
通过 4 个 ResGCN 块进行信息交互后,使用一个 dropout层 来提高模型泛化能力,减少过拟合。
2. MLP
最后,将 dropout 层的输出拉平,采用 2 隐藏层、1 输出层的 3 层 MLP 进行流量分类。
第一个隐藏层由一个输出大小为 220 的线性层组成,然后是整流线性单元 (ReLU)。
第二个隐藏层具有类似的结构,但输出大小为 110。隐藏层可以学习非线性函数以进行特征提取。
Ⅴ. 表现和评估
在本节中,我们将介绍并讨论我们的实验结果。
回答了以下三个研究问题:
- 流量数据处理方案在处理真实世界的原始流量时效果如何? (第 V-C 节)
- RESGCN 在真实世界网络流量上的表现如何,识别不同的网络服务? (第 V-D 节)
- RESGCN 是否比最先进的方法取得了更好的性能? (第 V-E 节)
A. 评估数据集
目前,用于匿名网络流量分析的主流数据集有两个(即 ISCXTor2016 和 Anon17 )。 由于多年来匿名网络的协议和通信机制发生了很多变化,这两个数据集已经不适合当前的匿名网络流量分析。
1. 数据集D1:SJTU-AN21 数据集
我们使用最新的 SJTU-AN21 数据集 (D1)。
其中包括「由十个匿名服务生成的三个最流行的匿名网络(即 Tor、I2P、JonDonym)的最新版本中的流量数据」。
训练和测试数据集中分别有 29,214 个流和 6,979 个流。
2. 对比数据集D2:ISCXVPN2016
为了评估分类器的通用性,引入了另一个真实世界的流量数据集 ISCXVPN2016 (D2) 。
该数据集提供了虚拟专用网络 (VPN) 上不同应用服务的流量。
VPN 还通过从公共互联网连接创建专用网络来提供匿名性。与速度慢且注重隐私的 Tor、I2P 和 JonDonym 不同,VPN 速度更快,更适合日常任务,如随意浏览和流媒体。
所选数据集中共包含 7 种应用服务(浏览、FTP、VoIP 等),并解析了 28,395 个流进行分类。 ISCXVPN2016数据集按照**80%和20%**的比例分为独立的训练数据集和测试数据集。
表 I 总结了这两个数据集的详细信息。

B. 实验设置
1. 实验设置
-
为了回答 RQ1,我们评估了所提出的原始流量数据处理方法在不同流量分割方案和特征选择方法上的性能,并确定了后续实验的最佳组合。
-
为了回答RQ2,我们分析了RESGCN的训练过程,并讨论了分类结果在测试数据集上的混淆矩阵。
-
为了回答 RQ3,我们比较了 RESGCN 的分类性能和测试数据集上流量分类方法的最新技术水平。
需要说明的是,AnonymityNet 和 ISCXVPN2016 数据集均用于进行上述评估实验。
2. 实验环境
所有评估均在 Python 3.7 和 1.9.0 版 PyTorch 框架中进行,并在配备 Intel® Core™ [email protected] GHz、64 GB RAM 和 NVIDIA GeForce RTX3090 GPU 的 PC 上运行。
3. 评价指标
为了衡量我们方法的分类性能,我们计算了真阳性 (Tp)、真阴性 (Tn)、假阳性 (Fp) 和假阴性 (Fn) 的数量。
根据以上定义,可以得到 Recall、Precision 和 F1 :

此外,浮点运算 (FLOPs) 用于评估模型的复杂性。
4. 超参数配置
使用超过 100 次的随机梯度下降 (SGD) 优化器来优化交叉熵损失。
初始学习率设置为 0.01,批量大小为 80,动量为 0.9。
C. 原始流量数据处理方案的有效性(对 RQ1)
捕获原始流量后,不同的流量数据处理方案会显着影响分类性能。
1. 流量数据处理方案设置
我们对以下三个主要影响因素进行研究:流分割、特征组合和流序列长度。
我们评估了 6 种分割方案(基于时间的 5s、10s、15s 和基于大小的 5MB、10MB 和 15MB)和 3 种特征选择方法(即基于 PCA、基于 XGBoost 和 基于LightGBM)。
- XGBoost 和 LightGBM 都是基于 GBDT 的 ML 算法,计算树中第 j 个特征的增益来反映特征重要性。
- PCA算法通过最大化目标维度的方差来降低数据维度。
我们使用训练数据集进行特征选择,并评估我们的方法在测试数据集上的准确性。
2. 分割方案的实验结果

(1)结论
从图5可以看出,10s 的特征分割方案在两个数据集上的分类性能都最好,15MB的分割方案性能最差。
通过对 15MB 流量切分方案的数据分析,发现很多采用该切分方案的流量持续时间很长,明显削弱了流量之间的时空相关性。
(2) 特征选择算法的比较
-
基于LightGBM 的方法和 基于XGBoost 的方法比基于PCA的方法实现了更高的最大准确度(MaxAcc)。
-
基于PCA的方法在特征数量较少时性能更好,这是因为PCA方法将原始的高维特征映射到低维,因此非常低维可以保留更多信息。
表二综合展示了三种特征选择方法的性能。
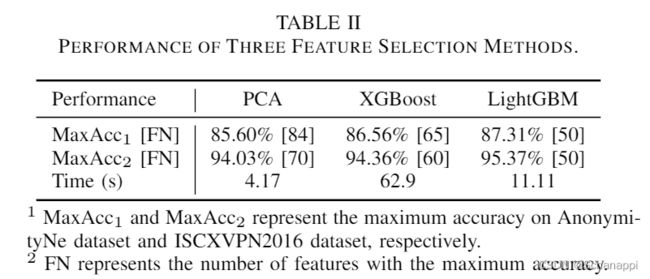
- 基于LightGBM的特征选择方法在两个数据集上均取得了最高的MaxAcc,特征个数为50。
- PCA方法在速度上取得了明显的优势,但在准确率上并不尽如人意。
可以得出结论,基于 LightGBM 的特征选择方法具有最佳的整体性能,因为它具有较高的准确性和计算效率。
因此,我们使用基于 LightGBM 的方法, 将 LightGBM 的特征数设置为 50 以进行后续实验。
D. RESGCN 分类器的性能(针对 RQ2)
(1)结论1:RESGCN模型在「训练精度和损失」上表现很好
使用RESGCN模型对两个数据集的 训练精度和损失 如图6所示。

(2)结论2:
为了全面评估 RESGCN 的分类性能,我们分析了测试数据集上分类结果的混淆矩阵。

如图 7 所示,我们的分类器可以有效地对不同服务产生的流量进行分类。
-
在 AnonymityNet 数据集上,三种匿名网络(即 I2P、Tor、JonDoNym)的流量被正确区分。
在识别匿名网络服务方面,I2P 网络上的服务是最难识别的,出现了误分类。 -
在 ISCXVPN2016 数据集上,我们可以看到分类器在 FTP 和聊天服务流量之间存在一些分类错误。
通过参考官方对ISCXVPN2016数据集的描述,我们发现这两个服务都包含了 Skype 应用产生的流量,这是造成误分类的主要原因。
(3)检查 RESGCN 的每个组件对性能的影响
对 RESGCN 进行了消融研究, 评估结果报告在表III中。

将 RESCNN 的结果作为基线,它使用与残差 GCN 块具有相似结构的残差 CNN 块。
- 去除 GFI :导致性能显着下降,说明了 GFI 对生成的特征之间进行信息交互的必要性。
- 去除 RFI :在两个数据集上的功能要弱得多,说明 RFI 在很大程度上有助于 RESGCN ,因为 RFI 利用流序列的关系图进行更合理和有效的特征提取。
- 去除RES (即保留 GCN 单元,但没有残差结构):表明残差结构可以通过直接信号传输有效避免网络退化。
- RESGCN w/o GCN 和 RESCNN 的实验结果都证明了 GCN 单元在流序列的特征提取中起着至关重要的作用。
E. 与其他方法的比较(针对 RQ3)
1. 其他方法介绍
为了全面评估我们的模型,我们将 RESGCN 与一系列基线和最先进的模型进行比较,如下所列:
- NB、SVM 和 C4.5 是基于流行的数据挖掘工具 Weka 实现的。
- CNN 和 LSTM 模型使用类似于 RESGCN 的结构(即相同的层数和输入/输出大小),并使用流序列作为分类输入。
- Wang 等人提出的2D-CNN ,直接读取流量 pcap 文件,转换成灰度图像(每张图像大小为28×28)进行分类。
- 3D-CNN 是Zhang 等人提出的2D-CNN 的改进模型。它在图像转换过程中使用多个通道来丰富特征信息。 模型输入是尺寸为 22×22×3 的 3D 张量,可以可视化为 24 位 RGB 图像。
- Yao 等人提出的 LSTM+Attn , 使用 LSTM 结合「自注意机制」来关注流序列中的重要流。
- FS-Net 是由 Liu 等人提出的基于 LSTM 的网络,用于加密流量分类。 该方法利用重建损失来确保 LSTM 提取的特征包含更多原始流序列的信息。
2. 其他方法的流量分类性能
表四显示了流量分类性能的结果。

-
RESGCN 在几乎所有的评估指标上都在两个数据集中取得了最好的性能。
-
传统的基于 ML 的方法的分类结果通常并不理想,这表明这些方法对复杂网络流量进行分类的能力有限。
-
2D-CNN 和 3D-CNN 模型的分类性能(即直接读取 pcap 文件而不计算统计特征;参见第 III-A 节)非常有限。
-
CNN、LSTM 和 LDAE 都使用统计特征和流序列来实现显着的性能提升。 然而,由于缺乏挖掘流序列的内在关系,它们仍然无法达到很高的准确性。
-
LAttn 模型通过 attention 机制学习流序列的内在关系,性能进一步提升。
-
FS-Net 通过引入重构损失实现了对加密流量更好的特征表示,有效提升了分类性能。 但是,这种模型结构也带来了更大的参数量。
-
RESGCN 从全新的角度设计模型结构。 它利用生成的关系图对流序列进行特征提取,显着提高了匿名网络流量的分类性能。
三种基于 LSTM 的模型(即 LSTM、LAttn 和 FS-Net)的速度非常慢。
3. RESGCN 优点
得益于GCN对流序列有效的特征提取,RESGCN 无需大参数即可实现准确分类。
RESGCN分类器实现了最高的分类精度,并且由于出色的结构设计而具有低复杂度和高速度。
Ⅵ. 结论
在本文中,我们提出了一种新颖的基于流序列的网络流量识别框架,该框架利用 RESGCN 来利用流之间的属性关系和时间关系,并成功识别不同的匿名网络服务。
此外,作为一种端到端的实时流量识别方法,我们的框架可以有效地处理真实世界的流量。
它考虑了流分割,用于从原始流量生成和丰富流特征,以及基于 LightGBM 的特征组合,避免了无关紧要的特征降低模型性能和效率。
我们的实验结果表明,RESGCN 分类器实现了最高的分类精度,并且由于出色的结构设计而具有低复杂度和高速度。
参考资料:
- 详解LightGBM两大利器:基于梯度的单边采样(GOSS)和互斥特征捆绑(EFB)
- LightGBM(lgb)详解