RepPoints: Point Set Representation for Object Detection解读
摘要
现代的检测器很依赖矩形框bbox,比如anchors,proposals和final predictions,呈现在不同的识别阶段里。bbox虽然很方便,但它只能提供粗糙的目标定位和特征提取。
注:final predictions如何理解呢,在引言里说了from anchors and proposals to final predictions,就很明白了,它的意思是最终的输出结果。
为什么bbox只是提供粗糙的目标定位和特征提取呢?文章的后面简单的说明了,bbox只是提取了4个边界点,并不能体现目标的形状,因为这个差异,导致提取到的特征有很多背景图或遮挡前景的图。
我们的RepPoints,使用了新的目标表现形式,即采样集合,它能够用于定位和识别。RepPoints能够自动化学习到bbox的空间位置和局部的有意义的语义特征。它们是不需要anchors的,也是anchor-free的一种目标检测的方法,也能够和anchor-base的方法一样有效。
注:
图1
它的方法,使用了9个点,通过这9个点找到一个外截框作为bbox。原则上这9个点代表目标上的点,主要集中于边缘,利用这9个点,使用deformable ROI pooling的方式取得特征,这样减小了背景的干扰。这9个点是学出来了,并没有标注出来。从后面结果来看,实际中,9个点很多在边缘,也有些在图像内部。
图2
引言
在目标检测的pipeline中,bbox作为一个最基本的处理方式,它体现在检测器的各个阶段里。一方面,bbox是评估检测器性能的一个通用的测量方式。另一方面,它能够方便的提取特征。
虽然bbox方便了计算,但它只提供了粗糙的目标位置,没有目标的形状和方向。由于特征是从bbox是提取的,所有其很受背景和遮挡物的影响,这样就得到低质量的特征,降低了分类的性能
注:道理是这么讲,但如何才能做到呢,有旋转的bbox也是解决这类似的问题,这个论文他会怎么解决呢?
本论文中,提供了一种新的表达形式,叫RepPoints,它提供了更加细颗粒的定位和分类。图1中,RepPoints所表现形式,是由一堆点组成,能够表达目标的空间内容和局部的语义信息,而这些点是自己学出来的,并没有做标注。而且还不需要基于bbox的anchor了。
注:从图1可以看到,点都在目标的边缘,又是自已学出来的,那就有很强的语义感,由9个点,能形成一个外截伪框,通过这个伪框与groundtruth进行loss就能够进行训练。但是否能够学习到边缘信息,还是未知的。
RepPoints不同于现在的非矩形框的表现方式的目标检测器。它们(像cornernet那样的方法)是依赖于手工聚类,生成目标框。他们的表现形式,还是与坐标轴对齐的bbox。相反,RepPoints是自顶向下的从图像中学习到细颗粒的定位,还无需对点进行监督。
注:一直在强调细颗粒和自适应学习9个点。这个很好奇,是怎么做到的。真会写文章
在传统bbox表现形式的两阶段检测器,包括anchor,proposal和final localization targets,我们发展出一个简洁高效无anchor的检测器,没有多尺度训练和测试,就能够达到42.8AP.
Related work
bbox是主流检测器的表现形式,一方面方便标注,主流的benchmark也是这个表现形式。另一方面,bbox也是图像特征提取的主流形式,不管是现在的深度学习,还是以前传统方法(使用bbox分块提取特征),很方便提取特征。
虽然我们的RepPoints是一个无规则的形式,但我们也能够方便的提取特征。我们的系统结合形变卷积来从采集点是提取特征。另外,使用伪框也能够在benchmark上进行评估。
RepPoints将各个阶段的bbox的形式都替代了。特别是使用中心点替代了anchor,可以在RepPoints中进行配制的。这里我们是无anchor的,使用中心点集,来初始化目标的形式。
注 :它这里说是无anchor,只是将anchor换了一种形式,以前的anchor有宽高比,scale,现在直接在中心邻域内撒9个点,然后让其学习到bbox的特性,也是一种anchor的思想。后面我还要将它的方法进一步的发展。
还有些行人检测的椭圆形式,旋转bbox。
注:旋转bbox倒是很常见
另一些,自底向上的表示形式,比如DPM,Poselet,还有最近的cornernet,extremenet,它们都需要人工的后处理,得到bbox。
而RepPoints无需这些,能够自动学习到极限点和语义关键点,通过对groundtruth bbox进行学习。而不像extremenet那样,需要mask监督。
注:看到这里,非常好奇,它是怎么做到的,如果要学习到边缘信息,那么我们是不是应该学习到向目标靠拢的行为,不然它怎么知道朝哪个方向去优化。没有mask,怎么知道哪个地方是目标呢?
视觉学习中的一个挑战是识别到目标的几何变量。为了高效的学习到这些东西,一个可能的解决办法是充分利用low-level的部分。比较典型的是DPM和poselet。
RepPoints受到这些工作的inspire,我们发展了一个灵活的目标检测形式,能够精确到几何定位和特征提取。这样,形变卷积和deformable ROI Pooling能够利用上,达到我们的目标。
注:它的意思是,通过9个点,能够学习到目标的外边缘和主要语义关键点,同时提取特征时,像deformable ROI Pooling那样,只要取出落入9个点的块,通过offset组合成特征。
看下面的图,很快就明白了

3. The RepPoints Representation
我们先看看检测器中的多阶段中的bbox的情况,然后引出RepPoints的描述
3.1. Bounding Box Representation
bbox由(x,y,w,h)4维组成,其中x,y为中心点,w,h为宽和高。由于它的简化和方便,它拿到在检测pipeline中的各个地方。
多阶段的检测器的pipeline:

注:这个图是多阶段的,每个阶段都会生成bbox,只是输送到下一个阶段的质量越来越高,三阶段有cascade RCNN。
在刚开始,anchor是建立在bbox的尺度和宽高比能够覆盖到目标的假设。一般来讲,高覆盖意味着是把高稠密的anchors,比如RetinaNet在每个位置有45个anchor。
注:更多的anchor,意味着样本不均衡越严重,反而影响训练。针对anchor分析的文章很多
对于一个anchor,在中心点的图像特征,能够作为目标的特征,用来作为分类的分数,来判断是否有目标,同时也能回归位置。这个bbox,被称为“bbox proposals)
在第二阶段,经过挑选出来的bbox,通过RoI pooling或RoI Align来提取目标的特征。对于二阶段,这里输出最终的bbox。对于多阶段,继续生成bbox proposals,经过多次,得到最终的bbox。
在这种框架中,bbox回归在不断的refine目标的位置和特征占有很重要的位置。
传统中,网络预测的回归量为![]() ,映射到当前的bbox proposal
,映射到当前的bbox proposal![]() ,refined后为
,refined后为
![]()
考虑到ground truth 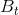 ,训练的过程是让
,训练的过程是让![]() 与尽可能的靠拢。在训练阶段,使用smoth
与尽可能的靠拢。在训练阶段,使用smoth 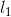 loss:
loss:

这种bbox的处理方式,广泛地用在目前的检测方法中。在实践中,当两者初始值距离比较小时,性能会很好,但当两者的初始距离更大时,性能会大大减弱。另一个因素是它们之间的scale差异导致效果不好。
注:想起我们人脸检测,由于大小和位置相对固定,那么初始值和scale才可以做的非常好,其性能应该可以优化到非常棒。同时把模型可以做的更小。
3.2. RepPoints
根据前面的分析,4-d的bbox,对目标的位置是一个粗糙的表达形式。bbox只考虑了目标的空间矩形范围,没有考虑形状、姿态和一些局部重要的语义位置信息,这些会更好定位和特征提取。
注:怎么样才能考虑形状,姿态呢,这个可以由形变卷积做到,姿态用旋转的bbox可以做到,而局部的语义特征的位置,这个只有传统的角点检测了。角点检测要引入到目标检测当中吗?
为了克服上面的限制,RepPoints采用一堆自适应的点集:
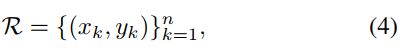
其中n为点集中点的个数,在我们的工作中,默认值为9。
注:这里写了bbox的表现形式,就是一堆点组成。那么一堆点如何表示bbox,如果去学习训练,初始值应该是多少呢?
为了更好的回归bbox的位置和特征提取,RepPoints使用如下形式,进行refine
![]()
其中的变化量为相对老点的offset。注意,我们不会面临scale问题
注:从它的表达的意思上看,是要学习每个点的offset,根据前面的意思,让点向目标边缘去学,如何才能学习呢?
为了充分利用好bbox的标注,同时也能评价我们的检测器,我们将点集转换成bbox,这里有三种形式:
1)最小最大。就是找出点集左右上下的边界值,作为bbox。
2)局部的最小最大。选择子集,以1)方式得到bbox
3)没看懂。
这些函数是可微的,能够插入到目标检测器中,端到端的学习。作者通过实验发现,他们都能够正常工作。
注:
大概是将点集生成伪框,作为bbox与ground truth进行loss学习吧。这里的结果显示,第三种效果要好。

通过目标的位置loss和识别loss,来学习。对于位置的学习,将点集转换为伪框后,那一般的基于bbox的检测器的方法是一样的。
注:通过这个,就能够学习到边缘信息,就能够学习到局部语义信息强的点?那9个点的初始值怎么设置呢?
4. RPDet: an Anchor Free Detector
我们的方法,也是可以做多阶段的pipeline的,如下

在yolo和densebox使用中心点进行初始化目标的表现形式,它的一个重要的好处是,它相对anchor对,有更加紧凑的假设空间。当anchor需要大量的宽高比和尺度,导致了稠密的候选框。而基于中心点的,只有2-d的空间,同时所有的目标都有中心点。
注:这里的center points是有复数的。所以这里的9个点,指的是在中心点一定的邻域内撒点。
然而,中心点也要面临识别模糊的问题,当两个不同的目标在同一个位置,这个普遍限制了现代检测器。在之前的工作,主要是通过在同一个地方产生多个目标来解决,但它面临更大的问题。
在RPDet里,我们显示通过FPN结果,极大的解决这个问题。首先,目标有不同的尺度,能够分配到不同的feature level里,这样能够解决不同的尺度和在相同中心点位置的问题了。第二,FPN对小目标有高分辨率的feature map,这样减小了两个不同的目标,在同一个featuremap上同一个位置的可能性。实际中,使用FPN后,coco只有1.1%的目标在featuremap的同一位置上。
值得注意的是,中心点表示可以看作是一种特殊的RepPoints配置,其中只有一个固定的采样点被使用,从而在整个检测框架中保持一致的表示。
下面是网络:

从上图可以看到,从center points开始,通过相对中心点的offset,来回归出最终的9个点。其loss包括两个,一个是伪框,一个识别的loss。这样就能够自动化学习关键点了。第二组点,生成最终的目标的位置。
RepPoints是一个几何表达,能够更加精确的反应语义定位,同时deformable RoI pooling能够学习到更强的目标特征。然而在实际中,deformable RoI pooling不能够学习到精确的目标定位。
注:看上面网络,第一个改变的是对于每一个形变卷积,都会单独拉一个loss。另外有个疑问,在黄色的offset field和class score map的通道维度不一致。前面又没有卷积,实际上,使用蓝色的offset作为卷积后,两个通道维度应该一样才对,所以后面一定还有卷积的,从后面的表示也证明了这点。
如果不清楚这个offset是怎么用的,看下图
我们的FPN backbone,有选择3-7阶段的5个feature pyramid层(下采样128)。网络有两个分支,一个是定位,一个是分类。其结构如下:

在两个分支中,共享第一个deformable conv layer。
对于位置分支,它有两阶段,它们都只有在正样本时,才会参与训练。同时目标尺度与feature level有关,当gt的scale满足
![]() ,s就确定了是落入到哪个金字塔层上。IoU大于等于0.5才认为为正样本。
,s就确定了是落入到哪个金字塔层上。IoU大于等于0.5才认为为正样本。
分类中,IoU小于0.4为负样本,使用分类的loss进行训练。
5. 实验
我们的检测器,是使用4个GPU,batchsize=8(每个gpu只有2张图)来进行同步SGD(这里的同步意思是多卡训练)。使用imageNet进行初始化。
5.2消融实验

从上表可以看到使用点集,性能近有2个点提升。说明它是有效的。

从上面的表格,可以看出对于bbox任务,分类对位置没有影响。但对于RepPoints中,分类对bbox有较大的提升。

不清楚,上面的bbox box的center point是什么方法,从结果上看,center point都有很大提升,但RepPoints有更大的提升。
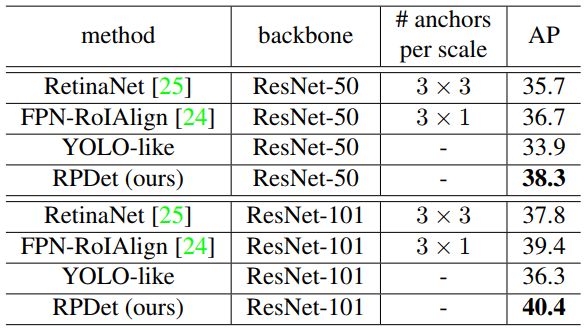

注:从上面的结果来看,在没有做多尺度训练和测试,它仅比CornerNet要高0.5个点,并没有强太多
整体效果图





注:从上面的结果来看,确实有很多是边缘点,但也有些目标内的点,同时也不是代表典型的特征,比如车那个,并没有在车灯那里