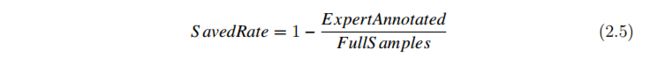【Active Learning - 10】图像分类技术和主动学习方法概述
主动学习系列博文:
【Active Learning - 00】主动学习重要资源总结、分享(提供源码的论文、一些AL相关的研究者):https://blog.csdn.net/Houchaoqun_XMU/article/details/85245714
【Active Learning - 01】深入学习“主动学习”:如何显著地减少标注代价:https://blog.csdn.net/Houchaoqun_XMU/article/details/80146710
【Active Learning - 02】Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally:https://blog.csdn.net/Houchaoqun_XMU/article/details/78874834
【Active Learning - 03】Adaptive Active Learning for Image Classification:https://blog.csdn.net/Houchaoqun_XMU/article/details/89553144
【Active Learning - 04】Generative Adversarial Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89631986
【Active Learning - 05】Adversarial Sampling for Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89736607
【Active Learning - 06】面向图像分类任务的主动学习系统(理论篇):https://blog.csdn.net/Houchaoqun_XMU/article/details/89717028
【Active Learning - 07】面向图像分类任务的主动学习系统(实践篇 - 展示):https://blog.csdn.net/Houchaoqun_XMU/article/details/89955561
【Active Learning - 08】主动学习(Active Learning)资料汇总与分享:https://blog.csdn.net/Houchaoqun_XMU/article/details/96210160
【Active Learning - 09】主动学习策略研究及其在图像分类中的应用:研究背景与研究意义:https://blog.csdn.net/Houchaoqun_XMU/article/details/100177750
【Active Learning - 10】图像分类技术和主动学习方法概述:https://blog.csdn.net/Houchaoqun_XMU/article/details/101126055
【Active Learning - 11】一种噪声鲁棒的半监督主动学习框架:https://blog.csdn.net/Houchaoqun_XMU/article/details/102417465
【Active Learning - 12】一种基于生成对抗网络的二阶段主动学习方法:https://blog.csdn.net/Houchaoqun_XMU/article/details/103093810
【Active Learning - 13】总结与展望 & 参考文献的整理与分享(The End...):https://blog.csdn.net/Houchaoqun_XMU/article/details/103094113
2.1 导言
机器学习方法根据模型在训练过程中是否使用标注样本,可进一步细分为监督学习和无监督学习等训练方式。监督学习利用大量的高质量标注样本训练模型,在计算机视觉领域中取得了许多显著的成绩。近几年,大量以监督学习为训练方式的机器学习算法不断被提出并应用到不同的领域中,同时产生了对大量标注样本的高度需求。因此,如何在保证不降低模型性能的情况下,显著地减少标注成本是个亟待解决的挑战,并逐渐引起了业界的广泛关注。无监督学习旨在挖掘未标注样本之间的内在联系,如 K-Means 聚类算法[54]。此外,半监督学习是介于监督学习和无监督学习的一种学习方式,基本思想是使用少量的标注样本进行预训练,并充分利用未标注样本训练模型,如自训练算法[55]。主动学习方法和图像分类技术都能够以上述三种训练方法应用到不同的需求中,本章将分别详细地概述。
2.2 图像分类技术
目前,主流的图像分类技术可划分为基于传统机器学习的方法以及基于深层网络模型的深度学习方法。如图2.1所示,传统机器学习方法首先对预处理完后的数据进行特征提取;紧接着,分类器基于提取后的特征进行训练。由于手工提取特征(Hand-crafted)方法和分类器都是基于一定的理论基础进行设计,因此具有较好的可解释性。但是,传统机器学习方法的效果过度依赖于特征,而手工设计的特征具有较大的局限性且难于设计,因此仍无法胜任一些复杂的任务。深度学习算法通过深层的网络结构将特征提取任务和分类器以端到端的方式整合到同一个网络中,并使用大量的标注样本通过反向传播机制不断更新模型参数,从而同时提升模型的特征提取和分类的能力。目前,深度学习方法在实际应用方面取得了很多突破性的成绩,逐渐成为了人工智能的重要工具。本节将围绕传统机器学习方法和深度学习方法对图像分类技术展开介绍。值得一提的是,数据预处理对图像分类任务同样至关重要,由于不是本文的重点,因此不展开详细地讨论。
2.2.1 基于传统机器学习的图像分类技术
传统的机器学习方法主要由两个核心部分组成,即特征提取和分类器。数据和特征工程决定了机器学习相关模型的上限,并通过合适的算法不断地逼近上限。本节将分别对当前部分主流的手工提取特征方法和分类器展开介绍。手工提取特征方法主要介绍局部二值模式(Local Binary Pattern, LBP) [56],方向梯度直方图(Histogram of Oriented Gradient, HOG) [57]以及尺度不变特征变换(Scale-Invariant Feature Transform, SIFT) [58]等。
(1)局部二值模式(Local Binary Pattern, LBP) : Ojala 等[56] 于 1994 年提出了 LBP 特征,并将其用于提取局部纹理特征。 LBP 的核心思想定义在一个像素大小为 3x3 的邻域中,将中心位置(2, 2)的像素值设置为阈值;邻域内的其余 8个位置的值取决于各自的像素值,若像素值大于阈值则为 1,否则为 0;最终将得到一个 8 位数的二进制值(代表中心位置的 LBP 值),并且能够反映该像素周围的纹理信息。随后,大量基于 LBP 的改进算法层出不穷。例如, Ojala 等[59] 尝试将 3×3邻域扩展到任意邻域,使其能够适应不同尺度的纹理特征,具有灰度和旋转不变性的特点。如图2.2(a)和(b)分别表示原图及其对应的 LBP 特征示意图。在实际应用中, LBP 及其改进方法常用于纹理分类,人脸识别[60]以及目标检测[61]等领域。
(2)方向梯度直方图(Histogram of Oriented Gradient, HOG) : Dalal等[57]认为梯度或边缘的方向密度分布能够较好的表达局部目标的表象和形状,提出了 HOG 特征并将其应用在静态图像行人检测任务中。 HOG 特征对图像几何的形变以及光学的形变都具有良好的不变性,常与 SVM 分类器结合并应用在图像的行人检测任务中。如图2.2(c)展示了 HOG 特征示意图。
(3)尺度不变特征变换(Scale-Invariant Feature Transform, SIFT) :Lowe 等[58] 于 1999 年提出了 SIFT 特征,并于 2004 年进一步完善。 SIFT 特征被广泛应用于关键点检测,具有旋转、尺度、平移、视角和亮度不变性等特点。 SIFT特征提取的核心步骤包括: 1)检测尺度空间中的极值; 2)定位特征点; 3)赋值特征方向; 4)描述特征点。如图2.2(d)展示了 SIFT 特征示意图。
模型的学习能力关系到分类器在目标领域数据的拟合程度,比如,学习能力较弱的模型容易发生欠拟合情况。因此,在不同任务中,分类器的选择也至关重要。下文将围绕 K 邻近算法(K-Nearest Neighbor, KNN) [62] 和支持向量机(SupportVector Machine, SVM) [63]等部分主流的分类器展开介绍。
(1) K 邻近算法(K-Nearest Neighbor, KNN) : KNN 是一种常用的监督学习方法。其思想是基于某种合适的距离度量算法找出待测样本与训练集中最相近的 k 个样本,并根据这 k 个样本对待测样本进行预测。例如,通过投票的方式对 k个训练样本进行统计,并将票数最多的类别作为待测样本的类别。此外, KNN 是“懒惰学习”(Lazy Learning)的著名代表,它不需要像其他的监督模型进行前向和反向训练,即没有显式的训练过程,训练时间成本为零。如图2.3(a)所示,对于一组给定的训练数据集(三角形和圆形表示不同的类别)并指定 k 值,分类的过程中需要找到与待分类样本最相邻的 k 个样本,然后进行投票并统计,最后直接将票数最多的类别作为待分类样本的类别。值得注意的是,不同的 k 值可能得到不一样的预测结果。例如:当 k 等于图2.3(a)中的 k1 时,待分类样本的类别为圆形;当 k 等于 k2 时,则类别为三角形。由于简易性和有效性, KNN 及其改进方法常与主动学习方法结合应用到图像识别和分类任务中[64,65]。
(2)支持向量机(Support Vector Machine, SVM) :基本的 SVM 是一种线性分类器,旨在从特征空间中寻找出潜在的最优超平面 !Tx + b = 0,并以最大间隔将两个类分开。其中, ! 表示法向量, b 表示超平面到原点之间的距离。式(2.1)表示样本空间中任意样本 x 到超平面之间的距离。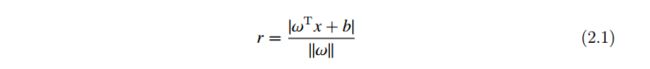
如图2.3(b)所示,中间的实线表示所要寻找的最优超平面(Optimal Hyper Plane),超平面到两条虚线的距离 margin 相等,虚线上的训练样本表示支持向量。此外,核函数通过将数据映射到高维空间,从而将 SVM 推广到非线性分类问题。SVM 及其改进算法凭借较好的分类性能,被广泛应用到主动学习中[66,67]。
2.2.2 基于卷积神经网络的图像分类技术
Hubel 和 Wiesel 在 20 世纪 60 年代提出了卷积神经网络(Convolutional Neural Networks, CNNs),在研究猫脑皮层中用于局部敏感和方向选择的神经元时,发现其独特的网络结构可以有效地降低反馈神经网络的复杂性。 CNNs 经过数十年的发展,性能及其实际应用价值发生了质的飞跃,特别是在图像处理任务中取得了大量卓越的成果。值得一提的是, CNNs 在图像处理领域中取得的效果,可以进一步总结为如下原因: 1)挖掘一张图像中潜在的模式(patterns)只需要让模型观察局部区域,不需要像全连接层与图像中所有的像素点都相连; 2)同一种模式可能出现在同一张图像中的不同区域,模型学习到的同一种模式可以应用到图像的不同区域,能够减少模型的参数量; 3)视觉对来自于图像物体的理解中,下采样处理对其影响很小,同样能够减少大量的参数量。目前主流的 CNNs 架构中,上述前两点观察主要体现在卷积层(下文将围绕卷积的“权值共享机制”展开讨论)。第三点观察主要体现在 CNNs 网络结构中的池化层,属于一种特殊的卷积下采样层。
CNNs 直接将图像作为模型的输入,在一定程度上避免了图像前期复杂的预处理,引起大量研究员的广泛关注。 1994 年, LeCun 提出了 LeNet[68],并将其应用于银行识别和分类手写体字符。如图2.4所示, LeNet 的诞生奠定了当代 CNNs 的基础,但由于当时计算能力和数据量的限制, CNNs 又经历了一次寒冬期。直到 2012 年,比 LeNet 更深层的 AlexNet[69] 模型以决定性的优势取得 ImageNet 竞赛的冠军,证明了 CNNs 应用于复杂模型的有效性,确立了 CNNs 在计算机视觉中的地位。随后,大量不同形式的改进模型层出不穷并应用于不同的领域。例如, ZFNet[70] 采用DeconvNet 和可视化(Visualization)技术监控学习过程; VGGNet[71] 采用大小为3x3 的滤波器去取代大小为 5x5 和 7x7 的滤波器从而降低计算复杂度; GoogleNet[72]推广了 NIN(Network in Network) [73]的思路并定义 Inception 模块,采用多尺度变换和不同尺寸(1x1, 3x3, 5x5)的滤波器构建网络模型; Highway Networks[74]借鉴了 LSTM[75] 的 gaiting 单元; ResNet[76] 借鉴了 Highway Networks 的跳跃连接(Skip Connection)思想,通过训练更深层的模型提升性能,并且计算复杂度变小;Inception-V3 和 V4 用 1x7 和 1x5 取代大滤波器 5x5 和 7x7, 1x1 滤波器做之前的特征瓶颈,使得卷积操作变成像跨通道(Cross Channel)的相关操作; DenseNet[77]主要通过跨层链接缓解了梯度消失(Vanishing Gradient)问题。综上所述, CNNs取得显著成绩的原因,除了计算能力的提升以及大数据等外界因素以外,网络模型的设计同样是重要因素之一。本节将结合 AlexNet 模型,重点围绕卷积及其权值共享机制展开讨论。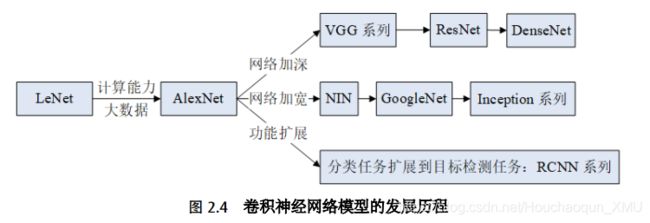
卷积及其权值共享机制:CNNs 的权值共享机制减少了大量的参数,为处理更复杂的图像和网络模型带来了可能性。如图2.5(a)为全连接层和卷积层的对比。在全连接层中,图像的每个像素都与全连接层中的每个神经元通过权值连接。卷积层通过滑动窗口的形式提取图像的局部特征,每个卷积核都会关注一种图像特征,如边缘、颜色和纹理等常见的图像特征。如图2.5(b)展示了 Sobel 滤波器提取边缘特征的示意图,原图像经过与 3x3 的 Sobel 滤波器进行卷积操作后,得到了提取后的边缘特征。每个滤波器的权值通过卷积操作同时作用到图像的所有像素上,所需参数量不随图像的尺寸改变,这就是权值共享机制的基本思想。举例说明:假设需要处理一张像素为 100x100 的图像,与之连接的全连接层中有 100 个神经元,总共需要一百万个参数。相较之下,使用一个 10x10 的卷积核也能够表示边缘等底层特征并且仅需 100 个参数。我们可以通过增加卷积核的数量得到不同的特征, 10 个10x10 的卷积核仅需 1000 个参数。由此可见,以卷积滑动窗口的连接形式相较于全连接方式能够显著地减少参数量。

基于 PyTorch 框架的 AlexNet 模型: Krizhevsky 在 2012 年使用 AlexNet 模型[69]赢得了 ImageNet 竞赛的冠军。 AlexNet 模型的网络结构主要包括卷积层、池化层、激活函数、全连接层、 Dropout 层以及连接输出层的 softmax 函数。当时Krizhevsky 在两块 GPU 上进行训练,使用 ReLU 作为激活函数缓解深层网络带来的梯度弥散问题,并利用数据增强技术和 LRN 层防止模型学习过程中的过拟合问题。本文第三章和第四章使用 PyTorch 框架提供的 AlexNet 模型[78],如图2.6所示的网络结构中,包括 5 个卷积层, 3 个最大池化层(MaxPooling)和 2 个全连接层。图2.6将分布在两块 GPU 上的结构整合到同一块 GPU 上进行展示,与最原始的 AlexNet 示意图有细微的区别。
CNNs 的设计过程中,通常需要将卷积层提取的图像特征与若干个全连接层相连,使其映射到一个固定大小的特征向量。以本文使用的 AlexNet 模型为例,表2.1展示了卷积核参数(例如, 64@11x11x3 表示有 64 组大小为 11x11x3 的卷积核, 3为通道数),移动步长及其移动方式,以及输入图像依次经过卷积操作和最大池化操作后输出图像的大小。

此外,式(2.2)给出了输入图像(InputSize)经过卷积层后对应输出图像大小(OutputSize)的计算方式。其中, KernelSize 表示卷积核的大小, Padding 表示步长的移动方式(0 表示不在原始图像周围添加像素点, 1、 2分别表示在所有通道周围添加 1 或者 2 圈像素点), Stride 为卷积核滑动窗口的移动步长(数值代表每次窗口滑动时跳跃的像素个数)。
2.3 主动学习方法
如图2.7(a)所示,红色实线表示理想情况下模型性能随着训练标注样本数量的增多而无限地提升。然而,实际情况下往往是如图2.7(b)的红色实线所示,模型的性能不是随着标注数据量的增多而无限地提升。此外,每个模型都会有与之对应的瓶颈性能(peak performance),研究者通过增加训练数据以及调参使之不断逼近瓶颈性能。主动学习关注的正是如何使用尽可能少的标注数据达到模型的瓶颈性能,从而减少不必要的标注成本。如图2.7(b)的蓝色虚线所示,主动学习根据合适的策略筛选出最具有价值的样本优先标注并给模型训练,从而以更少的标注样本达到模型的瓶颈性能。
2.3.1 主动学习基本框架
随着互联网的普及和数据采集技术提升,使得很多领域能够以廉价的成本获取大量未标注数据。基于未标注样本池的主动学习方法成为目前最流行且应用最广泛的场景。基本的主动学习方法主要由五个核心部分组成,包括: 1)未标注样本池U(图2.8中的第 1 部分), 2)筛选策略 Q(图2.8中的第 2 部分), 3)相关领域的标注专家 S(图2.8中的第 3 部分), 4)标注数据集 L(图2.8中的第 4 部分), 5)目标模型 G(图2.8中的第 5 部分)。主动学习方法将上述五个部分组合到一个框架中,并通过如图2.8所示的顺序,以不断迭代的训练方式更新模型性能、未标注样本池以及标注数据集,直到目标模型达到预设的性能或者不再提供标注数据为止。本节将围绕主动学习的基本框架展开讨论。
在实际应用中,首先需要根据特定领域的数据采集方法收集到大量的未标注样本,经过数据清洗后组成未标注样本池 U。一般情况下,为了验证模型的性能,将划分部分数据集作为模型的验证集和测试集,剩余的样本作为训练集。因此,首先,可以通过随机抽样法从未标注样本池 U 中选择部分样本给相关领域的专家 S 进行标注,并将其作为模型的验证集和测试集。然后,选择合适的模型作为分类器 G,例如基于传统机器学习算法的 SVM 或者基于深度学习方法的 AlexNet 模型。紧接着,根据具体应用场景选择合适的策略 Q(例如,不确定性策略)作为筛选样本的依据,从而产生一批待标注样本集 X 并交给相关领域的专家进行标注。值得注意的是,标注者在主动学习环节中至关重要,应该尽量保证提供准确性较高的样本标签。但是,一个鲁棒的主动学习算法需要考虑标注过程中不可避免的意外因素,比如产生少量的错误标签等因素,因此设计算法的时候也应考虑到模型的抗噪能力。最后,待标注样本集 X 将以增量式的方式加入标注数据集 L 中并提供给模型 G 进行训练,同时根据未被选中的样本更新未标注样本集合 U。至此,完成了主动学习的一次迭代过程,模型 G 将通过新增的标注样本不断提升性能,标注数据集 L 也将不断增加,未标注样本数据集 U 将不断减少。通过反复执行上述的迭代过程,直到满足预期设定的条件,比如模型达到预定的准确率或者标注成本达到上限等条件。算法2-1给出了基于未标注样本池的主动学习方法的基本框架。
2.3.2 主动学习基本策略
样本的筛选策略直接关系到模型能够节约标注成本的程度。例如,使用不确定性策略比随机采样策略能够节约更多的标注样本[4,5]。因为随机采样策略既没有利用到模型的预测信息,也没有利用到大量未标注样本池的结构信息,仅凭随机采样决定优先标注的样本。而不确定性策略通过与模型的预测信息进行交互,优先筛选出相对当前模型最有价值的样本。本节将围绕部分经典的筛选策略展开讨论。
(1)随机采样策略(Random Sampling, RS) : RS 不需要跟模型的预测结果做任何交互,直接通过随机数从未标注样本池筛选出一批样本给专家标注,常作为主动学习算法中最基础的对比实验。
(2)不确定性策略(Uncertainty Strategy, US) : US 假设最靠近分类超平面的样本相对分类器具有较丰富的信息量,根据当前模型对样本的预测值筛选出最不确定的样本。 US 包含了一些基础的衡量指标: 1)最不确定指标(LeastConfdence, LC)将预测概率的最大值的相反数作为样本的不确定性分数。 2)边缘采样(Margin Sampling, MS)认为距离分类超平面越近的样本具有越高的不确定性,常与 SVM 结合并用于解决二分类任务,但在多分类任务上的表现不佳。3)多类别不确定采样(Multi-Class Level Uncertainty, MCLU)是 MS 在多分类问题上的扩展, MCLU 选择离分类界面最远的两个样本,并将它们的距离差值作为评判标准。 MCLU 能够在混合类别区域中筛选出最不确信度的样本,如式(2.3)所示。其中, x j 表示被选中的样本, C 表示样本 xi 所属的类别集合, c+ 表示最大预测概率对应的类别, f (xi; c) 表示样本 xi 到分类超平面的距离。 4)熵值最大化(Maximize Entropy, ME)优先筛选具有更大熵值的样本,熵值可以通过计算 EntropyS core = - ∑Ci=1 pi × log(pi) 得到,其中 pi 表示第 i 个类别的预测值。 5)样本最优次优类别(Best vs Second Best, BvSB) [79]主要是针对多分类问题的一种衡量指标,并且能够缓解 ME 在多分类问题上效果不佳的情况。 BvSB 只考虑样本预测值最大的两个类别,忽略了其他预测类别的影响,从而在多分类问题上的效果更佳。
(3)委员会投票(Query by Committee, QBC) : QBC[31]是一种基于版本空间缩减的采样策略,核心思想是优先选择能够最大程度缩减版本空间的未标记样本。 QBC 包括两个基本步骤: 1)使用多个模型构成委员会; 2)委员会中所有的模型依次对未标注样本进行预测并优先筛选出投票最不一致的样本进行标注。由于QBC 在实际应用的过程中需要训练若干个模型,导致具有较高的计算复杂度。基于此,熵值装袋算法(Entropy Query-By-Bagging, EQB) [80]和自适应不一致最大化(Adaptive Maximize Disagree, AMD)被提出并缓解了计算复杂度问题。其中,EQB 同时引入了 bagging 继承方法以及 bootstrap 采样; AMD 主要针对高维数据,将特征空间划分为一定数量的子集并构造委员会。
(4)部分其他经典的策略:梯度长度期望(Expected Gradient Length, EGL)策略根据未标注样本对当前模型的影响程度优先筛选出对模型影响最大的样本;EGL[4]是代表性方法之一,能够应用在任意基于梯度下降方法的模型中。方差最小(Variance Reduction, VR)策略通过减少输出方差能够降低模型的泛化误差[81,82];Ji 等[82]提出了一种基于图的 VR 衡量指标的主动学习方法,通过将所有未标注样本构建在同一个图中,每个样本分布在图中每个结点上。紧接着,通过调和高斯随机场分类器直接预测未标注样本所属的标签;在优化的过程中,通过挑选一组未标注样本进行预测并获得对应的预测类别,使得未标注样本的预测类别方差最小。
2.3.3 主动学习的扩展方法
近年来,主动学习策略在很多实际应用场景中取得显著的效果。但同时也存在一些亟需解决的挑战。例如,不确定性策略只关注样本的不确定性,在 BMAL 场景下会产生大量具有冗余信息的样本。因此,仅使用单一的策略尚未能最大程度地节约标注成本。本节将围绕本文的核心工作简要地介绍几种主动学习的扩展方法。
(1)组合多种基本策略的主动学习方法:组合策略将多个基本策略以互补的方式进行融合,广泛应用于图像分类任务中[36,37,38,83]。其中, Li 等[36]基于概率分类模型提出一种自适应的组合策略框架。 Li 等[36]通过信息密度指标(Information DensityMeasure)将未标注样本的信息考虑在内,弥补了不确定性策略的不足。如算法2-2所示,该框架能够扩展到更多的组合策略,本文第三章借鉴了组合策略的思想。
(2)结合半监督学习(Semi-Supervised Learning)的主动学习方法:自训练(Self-training)算法作为半监督学习的一种基础方法,其核心步骤如算法 2-3所示。

由于自训练算法在训练过程中会根据模型的预测信息,挑选合适的样本及其对应的预测标签加入训练集,而且初始化少量的标注样本能够保证模型的初始性能,因此初始化训练环节对其后续的学习过程至关重要。半监督学习算法需要解决的挑战之一是:在训练的过程中容易引入大量的噪声样本,导致模型学习不到正确的信息。部分研究员们通过构建多个分类器的协同训练算法缓解噪声样本,如Co-Training[84] 和 Tri-Training[85]。本文在第三章从另一种思路入手,提出了一个噪声鲁棒的半监督主动学习框架,分别从减少噪声样本数量以及自动调整噪声样本等角度进行了充分地考虑,并将其与主动学习算法结合。此外,半监督学习方法与主动学习方法结合的相关工作已介绍于第一章,此处不再赘述。
(3)结合生成对抗网络的主动学习方法:生成对抗网络(Generative Adversarial Networks, GAN)模型以无监督的训练方式对大量未标注样本进行训练,并通过生成器产生新的样本。经典的 GAN[15] 主要包括生成器和判别器等两个核心部分,两者以互相博弈的方式进行对抗训练,直到两者达到一个动态均衡的状态。 GAN 的目标函数如式(2.4)所示,其中, V (G; D) = Ex∼Pdata [logD (x)] + Ex∼PG [log (1 - D (x))] 表示数据真实分布 x ∼ Pdata 与生成模型得到的分布 x ∼ PG 之间的差异。文献[19,50]将生成器和主动学习策略进行融合并构建目标函数,通过解决优化问题控制生成器产生的样本。本文第四章将重点介绍上述两种方法及其对应的目标函数,并在此基础上提出一个基于生成对抗网络的二阶段主动学习方法。
2.3.4 主动学习方法的基本评价指标
本文使用的评价指标:本文侧重研究主动学习方法在保证不损失模型准确率的情况下,节约标注成本的性能,评价指标如式(2.5)所示。其中, S avedRate 表示主动学习方法相对于全样本训练减少的标注成本; ExpertAnnotated 表示当模型达到预定的目标性能时专家标注的样本数量; FullS amples 表示当前数据集提供的未标注样本数量,即全样本训练时所使用的标注样本数量。本文的第三章将对上述五组数据集进行全样本训练,并分别记录最佳验证集准确率作为主动学习相关算法的目标准确率。例如,在某组数据集中使用 AlexNet 模型对 FullS amples 张标注图像进行训练,记录训练过程中最佳的验证准确率(best accuracy)并将其作为主动学习的目标准确率(target accuracy);随后,模型通过迭代过程不断提升性能,当达到目标准确率时,记录专家所标注的样本数量 ExpertAnnotated;此时,就可以算出SavedRate 的值,即该方法能够节约多少标注成本。此外,我们也会将主动学习方法与一些常见的方法进行比较,比如 RS 策略常用于基准对比实验(baseline)。