【Uplift】因果推断基础篇
https://zhuanlan.zhihu.com/p/362311467
文章目录
-
- Uplift与因果推断
- 相关、因果、辛普森悖论
- 因果图
-
- 基本结构
- 前门、后门准则
- 基本假设
- 关键指标
- 倾向性得分、Matching等
- 增量建模面临的问题
- 符号、名词定义梳理
- 参考文献
Uplift与因果推断
因果推断(Causal Inference)研究如何更加科学识别变量间的因果关系,是Uplift Modeling的理论基础。
在通常的预测任务中,我们拟合的实际是Y与X的相关关系,X甚至可以是Y的结果,如GDP和发电量之间可能有一系列复杂的关系,但只要二者相关就可以互相预测。
在另一些场景中则有所区别,如预测任务要指导干预(Treatment)决策时,我们所能掌控的只有Treatment变量,此时我们希望知道的是执行干预与否的效果差异(通常看增量,uplift),目的是决策是否执行或执行何种干预。如在“发券&下单”的问题中,用户的历史订单数对下单率预估有较大帮助,但对是否发券的指导意义可能会大打折扣。
本文概述与Uplift相关或有助于理解Uplift Modeling的因果推断相关的理论知识。
相关、因果、辛普森悖论
**相关和因果:**理解因果关系首先是和相关关系做区分,因果关系要求“原因”先于并导致“结果”,而相关关系对顺序不做要求。参考材料中提到了很多示例,如“溺水死亡人数与冰激凌销量正相关”,显然二者不是因果关系,而是由“气温(或季节)”联系起来的相关关系。
另一个很有名的现象是辛普森悖论(Simpson Paradox)。下面是[1]中一个例子,看“吃药”和“康复”二者的关系。如下表,从男性或女性分别看,都可以观察到吃药是有效的,但整体看会得到吃药是无效的结论。

导致该问题的原因是这里“是否康复”除了受到“吃药”的影响,也会受到“性别”的影响,此时“性别”就是一个混淆变量(Confounder)。
用一个直观的几何表示如下,“Men”整体的康复率高于“Women”,且“Women+Treat”的康复率低于“Men+No Treat”,因此当“吃药”组中“Women”比例高而“安慰剂”组中“Men”比例高时,可能出现这样的结果。
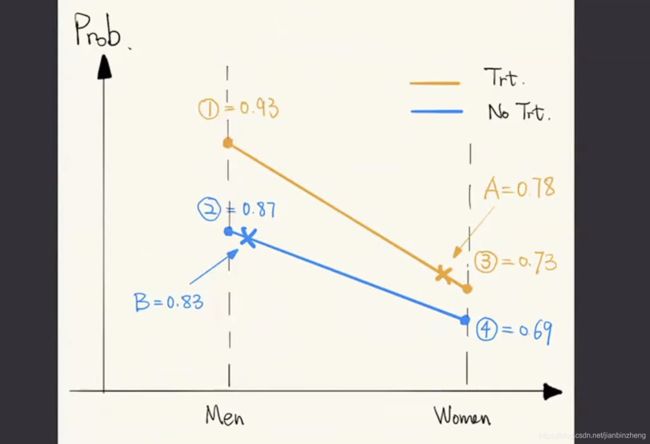
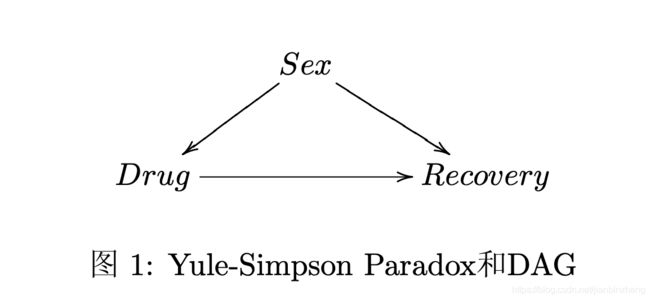
用下文提到的因果图表示为,此时单独一个Drug判断康复是不准确的
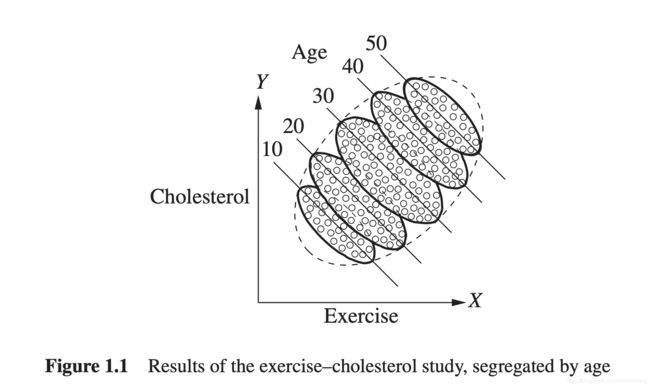
再扩展一个例子,X是运动量,Y是胆固醇量,每个实线椭圆表示一个年龄组,分组看运动有效减少了胆固醇;而从虚线的全局数据看则相反。此时“年龄”变为一个混淆变量,干扰估计结果。
因果图
因果图对于理解因果关系很有帮助,这里列举三个基本结构。同样取自[1]中的一些例子(注:极端情况相关性可能有差异)。最后简单介绍前门准则和后门准则。
基本结构
链状结构(Chain):XY、XZ、YZ都相关;给定Y时,XZ无关。
P ( Z = z ∣ X = x , Y = c ) = P ( Z = z ∣ Y = c ) P(Z=z|X=x,Y=c)=P(Z=z|Y=c) P(Z=z∣X=x,Y=c)=P(Z=z∣Y=c)
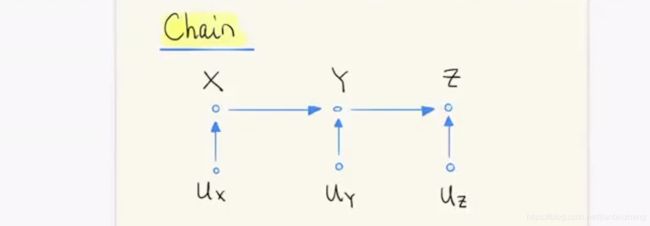
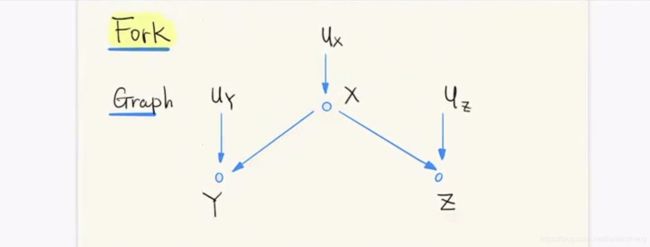
叉状结构(Fork):XY、XZ、YZ都相关,但YZ不为因果;给定X时,YZ不相关。
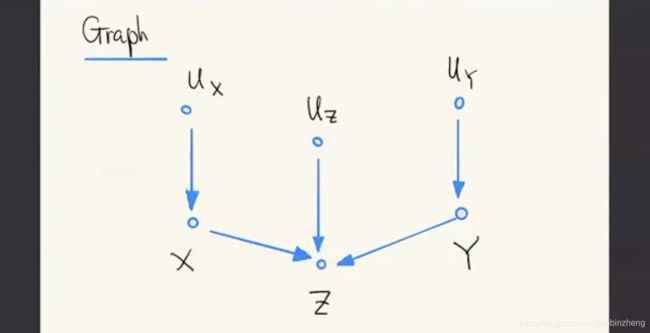
对撞结构(Collider):XZ、YZ相关,XY不相关;给定Z时,XY相关
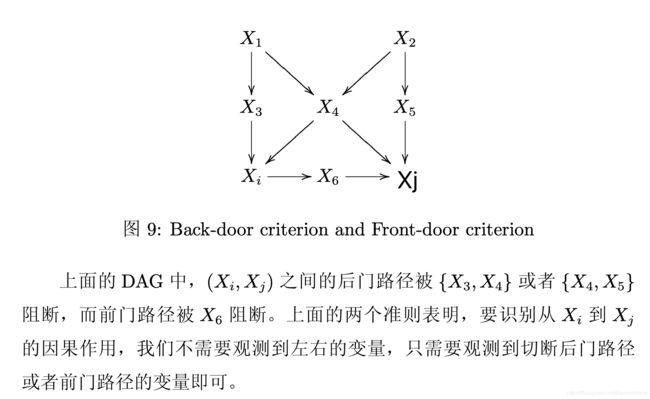
前门、后门准则
后门准则(back-door):存在变量集合Z,①Z中节点不为X的后代;②Z阻断所有XY之间指向X的路径。此时XY的因果作用可识别
P ( y ∣ d o ( X ) = x ) = ∑ z P ( y ∣ x , z ) P ( z ) P(y|do(X)=x)=\sum_{z}P(y|x,z)P(z) P(y∣do(X)=x)=z∑P(y∣x,z)P(z)
前门准则(front-door):存在变量集合Z,①Z切断所有X到Y的直接路径;②X到Z无后门路径;③所有Z到Y的后门路径被X切断。此时,若P(x,z)>0,则XY的因果作用可识别
P ( y ∣ d o ( X ) = x ) = ∑ z P ( z ∣ x ) ∑ x ′ P ( y ∣ x ′ , z ) P ( x ′ ) P(y|do(X)=x)=\sum_{z}P(z|x)\sum_{x'}P(y|x',z)P(x') P(y∣do(X)=x)=z∑P(z∣x)x′∑P(y∣x′,z)P(x′)
示例如下[3]
基本假设
在进行因果效应估计前,有3个常用的基本假设。
假设1:SUTVA(Stable Unit Treatment Value Assumption),样本之间独立、每种Treatment只有单版本(一个干预手段有多种选择的算多个Treatment)
假设2:Ignorability(可忽略性假设),给定背景变量X下,Treatment的分配W与潜在结果Y无关,即
W ⊥ ( Y ( W = 0 ) , Y ( W = 1 ) ) ∣ X W\perp(Y(W=0),Y(W=1))|X W⊥(Y(W=0),Y(W=1))∣X
假设3:Positivity,对每个值X,Treatment的分配概率非确定性的
P ( W = w ∣ X = x ) > 0 , ∀ w a n d x P(W=w|X=x)>0,\forall\ w\ and\ x P(W=w∣X=x)>0,∀ w and x
关键指标
本节介绍几个因果效应估计的常用指标。当我们要评估treatment的整体效应时,通常看ATE、CATE指标;当我们要具体到个体去评估干预效应时,看ITE,Uplift Modeling通常就是建模ITE。
ATE(Average Treatment Effect,平均干预效应),定义为treated和control的潜在结果之差的均值。注:ACE(Average Causal Effect,平均因果效应)含义类似。
ATE = E [ Y ( W = 1 ) − Y ( W = 0 ) ] \text{ATE}=\mathbb{E}[Y(W=1)-Y(W=0)] ATE=E[Y(W=1)−Y(W=0)]
CATE(Conditional Average Treatment Effect,条件平均干预效应),定义为给定 X = x X=x X=x时的分组中,treated和control的潜在结果的期望之差。
CATE = E [ Y ( W = 1 ) ∣ X = x ] − E [ Y ( W = 0 ) ∣ X = x ] \text{CATE}=\mathbb{E}[Y(W=1)|X=x]-\mathbb{E}[Y(W=0)|X=x] CATE=E[Y(W=1)∣X=x]−E[Y(W=0)∣X=x]
ITE(Individual Treatment Effect,个体干预效应),定义为独立样本的treated和control的潜在结果的差值。
ITE i = Y i ( W = 1 ) − Y i ( W = 0 ) \text{ITE}_i=Y_i(W=1)-Y_i(W=0) ITEi=Yi(W=1)−Yi(W=0)
倾向性得分、Matching等
Propensity score(倾向性得分),为了消除Confounder的影响,准确估计因果效应,此时我们可以依据X做数据分层再评估ATE,但当X为连续变量时则很难分层,或分层后数据不足以估计。对该问题Rosenbaum and Rubin提出了倾向性得分的概念[3],实际是一种降维手段,定义为:
e ( X ) = P ( W = 1 ∣ X ) e(X)=P(W=1|X) e(X)=P(W=1∣X)
其中:
① X ⊥ W ∣ e ( X ) X\perp W|e(X) X⊥W∣e(X);
②若X能够满足强可忽略性假定,且 0 < e ( X ) < 1 0
其含义是若给定X能够满足Ignorability,则给定一个一维变量 e ( X ) e(X) e(X)也可以,倾向得分是最“粗糙”的变量。最后,对得到的倾向性得分可以做“分层”,评估每一层的因果效应并加权平均即可。
ATE ^ = 1 N ∑ i = 1 n [ Y i W i e ^ ( X i ) − Y i ( 1 − W i ) 1 − e ^ ( X i ) ] \widehat{\text{ATE}}=\frac{1}{N}\sum_{i=1}^{n}[\frac{Y_iW_i}{\hat{e}(X_i)}-\frac{Y_i(1-W_i)}{1-\hat{e}(X_i)}] ATE =N1i=1∑n[e^(Xi)YiWi−1−e^(Xi)Yi(1−Wi)]
Matching,估计ATE首先碰到的问题是“counterfactual(反事实)”的问题,我们可以通过集合之间的统计差异来代替,即在理想状态时选择随机试验得到的数据直接计算;而另一个问题是“confounder bias(混淆变量偏差)”的问题,在无随机试验数据或无法进行随机试验时,可以利用Matching得到相近的样本以减少偏差问题。
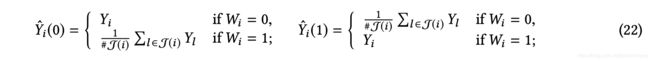
Matching方法就是“采样”相似样本,利用与目标样本最相似的几个样本聚合作为该样本的“反事实”结果。具体实施中,首先选择一个距离度量方法(如欧式距离、马氏距离、倾向性得分距离),然后采样并计算ATE。
如采用最近邻方法,在control组样本中,为每个treated样本采样一个最相似样本组成新control组,再根据上述公式计算ATE。
增量建模面临的问题
上面有提到过,因果效应估计或增量建模时,我们会遇到两个问题。
反事实(counterfactual)。实际数据中,我们只有真实发生的样本结果,而缺失了其他treatment的结果,此时我们只能通过既有数据集,通过数据集整体来估计因果效应。
混淆变量偏差(confounder bias)。实际数据大多并非来源于随机试验,此时我们需要利用倾向性得分分层、Matching等方法来减少偏差。
符号、名词定义梳理
最后摘录综述论文中的一些名词定义
1. Unit,指因果效应研究中的原子个体
2. Treatment,指施加在unit上的行为
3. Potential outcome,指对每个unit-treatment对的潜在结果
4. Observed outcome,指实际观察到的结果
5. Conterfactual outcome,指unit在施加其他(非实际)treatment时会得到的结果
6. Pre-treatment variables,指不受treatment影响的变量,也称为背景变量
7. Post-treatment variables,指受treatment影响的变量,如中间结果
8. Confounders,指同时影响treatment分配及结果的变量,如开头例子中的性别
9. Propensity score,倾向性得分,定义为给定 X = x X=x X=x时,treatment的概率
参考文献
[1]B站【因果推断入门】:https://www.bilibili.com/video/BV15J411L7xW
[2]Causal Inference in Statistics: A Primer :http://bayes.cs.ucla.edu/PRIMER/primer-ch1.pdf
[3]因果推断简介(丁鹏):https://yao-lab.github.io/2009.fall.pku/lecture10_DingP_causal091101.pdf
[4]A Survey on Causal Inference:https://arxiv.org/abs/2002.02770
[5]更多参考资料:https://zhuanlan.zhihu.com/p/358582762