paddlehub利用自有数据集进行训练和微调
使用paddlehub进行自有数据集的训练和微调(NLP)
- paddlehub利用自有数据集进行训练和微调
-
- 1.基本骨架-Transformer Encoder
- 2.ERNIE基本原理
- 3.ERNIE自定义数据集
- 4.ERNIE训练和Fine-tuning
- 5.用best_model进行预测并保存预测结果
- 6.总结
paddlehub利用自有数据集进行训练和微调
本文通过调用百度的持续学习语义理解框架ERNIE模型,实现NLP任务,并导入自有数据集进行训练和微调,以达到实现情感分类的目的。
1.基本骨架-Transformer Encoder
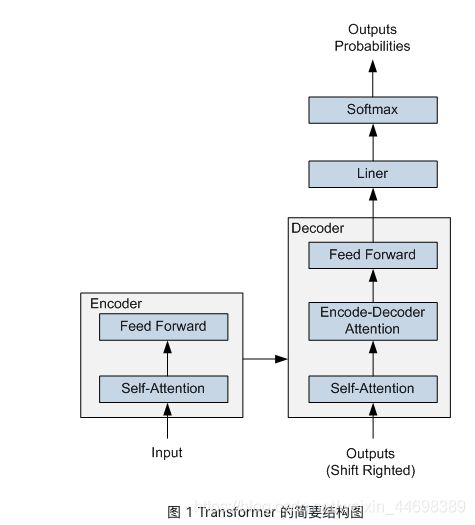
ERNIE 采用了 Transformer Encoder 作为其语义表示的骨架。Transformer 是由论文Attention is All You Need 首先提出的机器翻译模型,在效果上比传统的 RNN 机器翻译模型更加优秀。Transformer 的简要结构如图1所示,基于 Encoder-Decoder 框架, 其主要结构由 Attention(注意力) 机制构成:
Encoder 由全同的多层堆叠而成,每一层又包含了两个子层:一个Self-Attention层和一个前馈神经网络。Self-Attention 层主要用来输入语料之间各个词之间的关系(例如搭配关系),其外在体现为词汇间的权重,此外还可以帮助模型学到句法、语法之类的依赖关系的能力。
Decoder 也由全同的多层堆叠而成,每一层同样包含了两个子层。在 Encoder 和 Decoder 之间还有一个Encoder-Decoder Attention层。Encoder-Decoder Attention层的输入来自于两部分,一部分是Encoder的输出,它可以帮助解码器关注输入序列哪些位置值得关注。另一部分是 Decoder 已经解码出来的结果再次经过Decoder的Self-Attention层处理后的输出,它可以帮助解码器在解码时把已翻译的内容中值得关注的部分考虑进来。例如将“read a book”翻译成中文,我们把“book”之所以翻译成了“书”而没有翻译成“预定”就是因为前面Read这个读的动作。
在解码过程中 Decoder 每一个时间步都会输出一个实数向量,经过一个简单的全连接层后会映射到一个词典大小、被称作对数几率(logits)的向量,再经过 softmax 归一化之后得到当前时间步各个词出现的概率分布。
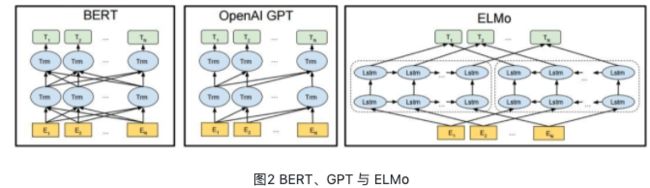
Transformer 在机器翻译任务上面证明了其超过 LSTM/GRU 的卓越表示能力。从 RNN 到 Transformer,模型的表示能力在不断的增强,语义表示模型的骨架也经历了这样的一个演变过程。如图2所示,该图为BERT、GPT 与 ELMo的结构示意图,可以看到 ELMo 使用的就是 LSTM 结构,接着 GPT 使用了 Transformer Decoder。进一步 BERT 采用了 Transformer Encoder,从理论上讲其相对于 Decoder 有着更强的语义表示能力,因为Encoder接受双向输入,可同时编码一个词的上下文信息。最后在NLP任务的实际应用中也证明了Encoder的有效性,因此ERNIE也采用了Transformer Encoder架构。
2.ERNIE基本原理
ERNIE 分为 1.0 版和 2.0 版,其中ERNIE 1.0是通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于BERT学习原始语言信号,ERNIE 1.0 可以直接对先验语义知识单元进行建模,增强了模型语义表示能力。例如对于下面的例句:“哈尔滨是黑龙江的省会,国际冰雪文化名城”。
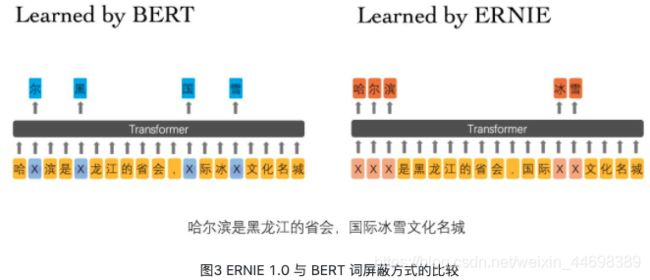
BERT在预训练过程中使用的数据仅是对单个字符进行屏蔽,例如图3所示,训练Bert通过“哈”与“滨”的局部共现判断出“尔”字,但是模型其实并没有学习到与“哈尔滨”相关的知识,即只是学习到“哈尔滨”这个词,但是并不知道“哈尔滨”所代表的含义;而ERNIE在预训练时使用的数据是对整个词进行屏蔽,从而学习词与实体的表达,例如屏蔽“哈尔滨”与“冰雪”这样的词,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市这样的含义。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 1.0 还引入了论坛对话类数据,利用对话语言模式(DLM, Dialogue Language Model)建模Query-Response对话结构,将对话Pair对作为输入,引入Dialogue Embedding标识对话的角色,利用对话响应丢失(DRS, Dialogue Response Loss)学习对话的隐式关系,进一步提升模型的语义表示能力。
因为 ERNIE 1.0 对实体级知识的学习,使得它在语言推断任务上的效果更胜一筹。ERNIE 1.0 在中文任务上全面超过了 BERT 中文模型,包括分类、语义相似度、命名实体识别、问答匹配等任务,平均带来 1~2 个百分点的提升。
我们可以发现 ERNIE 1.0 与 BERT 相比只是学习任务 MLM 作了一些改进就可以取得不错的效果,那么如果使用更多较好的学习任务来训练模型,那是不是会取得更好的效果呢?因此 ERNIE 2.0 应运而生。ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。如图4所示,在ERNIE 2.0中,大量的自然语言处理的语料可以被设计成各种类型的自然语言处理任务(Task),这些新构建的预训练类型任务(Pre-training Task)可以无缝的加入图中右侧的训练框架,从而持续让ERNIE 2.0模型进行语义理解学习,不断的提升模型效果。
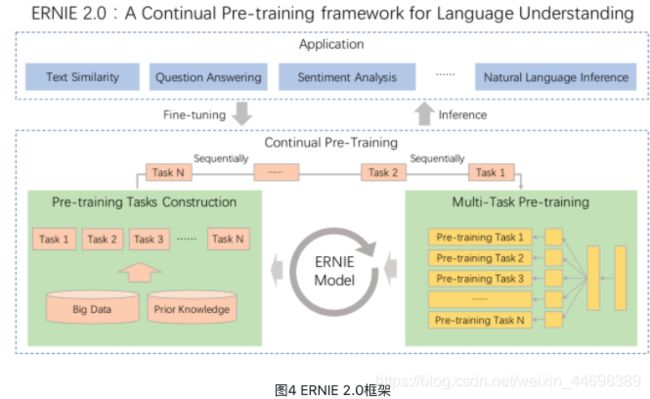
ERNIE 2.0 的预训练包括了三大类学习任务,分别是:
词法层任务:学会对句子中的词汇进行预测。
语法层任务:学会将多个句子结构重建,重新排序。
语义层任务:学会判断句子之间的逻辑关系,例如因果关系、转折关系、并列关系等。
通过这些新增的语义任务,ERNIE 2.0语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。ERNIE 2.0模型在英语任务上几乎全面优于BERT和XLNet,在7个GLUE任务上取得了最好的结果;中文任务上,ERNIE 2.0模型在所有9个中文NLP任务上全面优于BERT。
完成预训练后,如何用 ERNIE 来解决具体的 NLP 问题呢?下面以单句分类任务(如情感分析)为例,介绍下游 NLP 任务的解决过程:
基于tokenization.py脚本中的Tokenizer对输入的句子进行token化,即按字粒度对句子进行切分;
分类标志符号[CLS]与token化后的句子拼接在一起作为ERNIE模型的输入,经过 ERNIE 前向计算后得到每个token对应的embedding向量表示;
在单句分类任务中,[CLS]位置对应的嵌入式向量会用来作为分类特征。只需将[CLS]对应的embedding抽取出来,再经过一个全连接层得到分类的 logits 值,最后经过softmax归一化后与训练数据中的label一起计算交叉熵,就得到了优化的损失函数;
经过几轮的fine-tuning,就可以训练出解决具体任务的ERNIE模型。
持续学习语义理解框架ERNIE—飞桨官网解释
3.ERNIE自定义数据集
导入相关包
import codecs
import os
import csv
import paddlehub as hub
module = hub.Module(name="ernie")
from paddlehub.dataset import InputExample
from paddlehub.dataset.base_nlp_dataset import BaseNLPDataset
inputs, outputs, program = module.context(trainable="True", max_seq_len=128) # 此时数据的最大长度为128
#通过创建Dataset对象加载自定义文本数据集
# 此时根据不同的任务,继承不同的Dataset,本文为nlp任务,所以继承BaseNLPDataset
class DemoDataset(BaseNLPDataset):
def __init__(self):
# 数据集实际路径
self.dataset_dir = "work" # 此时为所有数据集的上一层目录
self._load_train_examples()
self._load_test_examples()
self._load_dev_examples()
def _load_train_examples(self): # 导入训练集代码
self.train_file = os.path.join(self.dataset_dir, "train.tsv") # 此时为文件名
self.train_examples = self._read_tsv_train(self.train_file)
def _load_test_examples(self): # 导入测试集代码
self.test_file = os.path.join(self.dataset_dir, "dev.tsv")
self.test_examples = self._read_tsv_dev(self.test_file)
def _load_dev_examples(self): # 导入评估集代码
self.dev_file = os.path.join(self.dataset_dir, "dev.tsv")
self.dev_examples = self._read_tsv_dev(self.dev_file)
# 此时以下代码无需修改
def get_train_examples(self):
return self.train_examples
def get_test_examples(self):
return self.test_examples
def get_dev_examples(self):
return self.dev_examples
def get_labels(self):
"""define it according the real dataset"""
return ["0", "1"]
@property
def num_labels(self):
"""
Return the number of labels in the dataset.
"""
return len(self.get_labels())
# 此时写导入训练集的代码
# label=line[0] 标签为第一列,text_a=line[1] 数据为第二列
def _read_tsv_train(self, input_file, quotechar=None):
"""Reads a tab separated value file."""
with codecs.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
examples = []
seq_id = 0
header = next(reader) # skip header
for line in reader:
example = InputExample(
guid=seq_id, label=line[0], text_a=line[1])
seq_id += 1
examples.append(example)
return examples
# 此时写导入测试集和验证集的代码
# label=line[1] 标签为第二列,text_a=line[2] 数据为第三列
def _read_tsv_dev(self, input_file, quotechar=None):
"""Reads a tab separated value file."""
with codecs.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
examples = []
seq_id = 0
header = next(reader) # skip header
for line in reader:
example = InputExample(
guid=seq_id, label=line[1], text_a=line[2])
seq_id += 1
examples.append(example)
return examples
综上,只需要修改所继承的父类:class DemoDataset(父类),对应的文件路径: self.dataset_dir = 文件夹, 文件名 :self.train_file = os.path.join(self.dataset_dir)
数据所在列: label=line[1] 标签为第二列,text_a=line[2] 数据为第三列。
4.ERNIE训练和Fine-tuning
ds = DemoDataset()
pooled_output = outputs["pooled_output"]
sequence_output = outputs["sequence_output"]
reader = hub.reader.ClassifyReader(dataset=ds, vocab_path=module.get_vocab_path(), max_seq_len=128)
for e in ds.get_train_examples():
strategy = hub.AdamWeightDecayStrategy(
learning_rate=1e-4,
lr_scheduler="linear_decay", #linear_decay策略学习率会在最高点后以线性方式衰减;
warmup_proportion=0.0, #Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps,再修改为预先设置的学习来进行训练
weight_decay=0.01, # L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化
optimizer_name="adam"
)
config = hub.RunConfig(
use_cuda=True,
num_epoch=30,
batch_size=128,
eval_interval=90,
strategy=strategy
)
feed_list = [
inputs["input_ids"].name, inputs["position_ids"].name,
inputs["segment_ids"].name, inputs["input_mask"].name
]
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
feed_list=feed_list,
num_classes=ds.num_labels,
config=config)
cls_task.finetune_and_eval()
5.用best_model进行预测并保存预测结果
# 待预测数据
import pandas as pd
from pandas.core.frame import DataFrame
# 导入自有数据并进行处理
def read_tsv_predict(input_file, quotechar=None):
with codecs.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
examples = []
header = next(reader) # skip header
for line in reader:
example =line[1] # 此时选择数据为第几列
examples.append([example])
return examples
data=read_tsv_predict('work/train.tsv')
#predict the label and add a new column to data
t=list() # t为待预测文本
s=list() # s为预测结果
index=0
run_states = cls_task.predict(data=data)
results = [run_state.run_results for run_state in run_states]
for batch_result in results:
# get predict index
batch_result = np.argmax(batch_result, axis=2)[0]
for result in batch_result:
t.append(data[index][0])
s.append(result)
index += 1
test_results=DataFrame(s)
df=DataFrame(t)
print(df.shape)
print("-------")
print(test_results.shape)
data=np.hstack((test_results,df))
# Generate a new list of misjudgments based on real_label and test_label and Calculate the accuracy
frame = pd.DataFrame(data, columns=[ 'test_label','text'])
# saving the final text
np.savetxt(r'work/train_new.tsv',frame, fmt='%s',delimiter = '\t') # 最后为data label的格式
print('Finish saving tsv file')
6.总结
此时就完成了使用自定义数据集通过paddlehub的ERNIE进行训练和Fine-tuning。paddle的官网很难对dataset的具体修改进行说明,此处写下此文来说明这些小细节。综上,主要是修改继承的父类,数据的路径,数据所在的对应列以及找到适合自己模型的参数。由于模型较大,训练时间较长,可以在百度的AI Studio上进行自己的模型训练,里面有免费的cpu和gpu内核,可以极大的提高训练的速度。
此处贴出百度的AI Studio网站 :AI Studio网站