2021-10-11数据分析:练习
文章目录
-
-
- 1. 练习1--911
- 2.时间序列
- 3.练习2--911
-
- (1)重采样
- (2)代码
- 4.练习3--PM2.5
-
1. 练习1–911
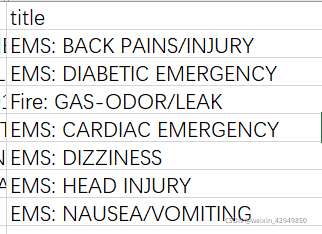
问题:统计911紧急电话中不同类型的紧急情况的次数?
部分类型数据:
可以按照字符串离散化的步骤,构造0数组,再赋值求和:
#coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'G:\\pytorch_learning\\数据分析资料\\day06\\code\\911.csv'
df = pd.read_csv(file_path)
#获取数据
data1 = df['title'].str.split(':').tolist()
cate_list = list(set([i[0] for i in data1]))
#构造全为0的数组
zero_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
#赋值
for cate in cate_list:
zero_df[cate][df['title'].str.contains(cate)]=1
'''或
for i in range(df.shape[0]):
zero_df.loc[i,data1[i][0]] = 1
'''
print(zero_df)
#统计求和
sum_set= zero_df.sum(axis=0)
print(sum_set)
或者,添加一列,分组计数:
#coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'G:\\pytorch_learning\\数据分析资料\\day06\\code\\911.csv'
df = pd.read_csv(file_path)
#获取数据
data1 = df['title'].str.split(':').tolist()
cate_list = [[i[0] for i in data1]]
df['cate'] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))#添加一列
#分组
cate_group = df.groupby(by='cate').count()['title']
print(cate_group)
2.时间序列

例:pd.date_range(start = ‘20170101’,end = ‘20170130’,fres = ‘10D’)
pd.date_range(start = ‘20170101’,periods =10,fres = ‘D’ )

pd.to_datetime():将时间字符串转为时间序列

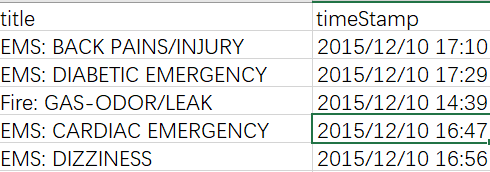
3.练习2–911
问题:统计911紧急电话中不同类型、不同月份的紧急情况的次数?
(1)重采样
![]()
t.resample('M).mean()–按月重采样,计算平均值
t.resample(‘10D’).count()–按10天重采样,计数
(2)代码
![]()
不同月份:
#coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'G:\\pytorch_learning\\数据分析资料\\day06\\code\\911.csv'
df = pd.read_csv(file_path)
#获取数据
df['timeStamp'] =pd.to_datetime(df['timeStamp'])
df.set_index('timeStamp',inplace = True) #重新创建一个index,而不是原地修改
#统计不同月份
count_by_month = df.resample('M').count()
#画图
_x = count_by_month.index
_y = count_by_month.values
#这里的—_x时间会显示时分秒,得改一下显示
_x = [i.strftime('%Y%m%d') for i in _x]
plt.figure(figsize=(20,8),dpi = 80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation = 45)
plt.show()
不同类型,不同月份:
#coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'G:\\pytorch_learning\\数据分析资料\\day06\\code\\911.csv'
df = pd.read_csv(file_path)
#把时间字符串转为时间类型并设置时间索引
df['timeStamp'] =pd.to_datetime(df['timeStamp']) #!!!这里不能先将索引换成时间 序列索引,因为后面的类型索引还是12345.....
#添加一列,表示分类
data1 = df['title'].str.split(':').tolist()
cate_list = [[i[0] for i in data1]]
df['cate'] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
df.set_index('timeStamp',inplace = True)
print(df.head(3))
#分组
group_by_cate = df.groupby(by='cate')
#画图
plt.figure(figsize=(20, 8), dpi=80)
for group_name,group_data in group_by_cate :
#对不同分类都绘图
count_by_month = group_data.resample('M').count()
# 画图
_x = count_by_month.index
_y = count_by_month.values
# 这里的_x时间会显示时分秒,得改一下显示
_x = [i.strftime('%Y%m%d') for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc='best')
plt.show()
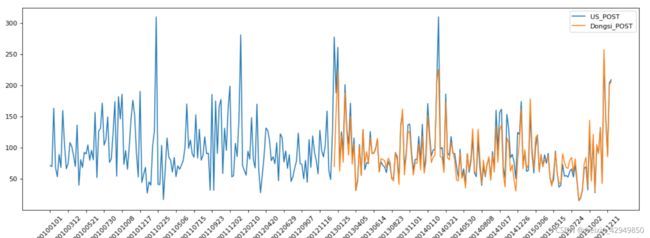
4.练习3–PM2.5
![]()
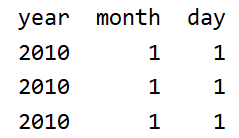
这里需要把时间放到一起
比较北京和美国的:
#coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'G:\\pytorch_learning\\数据分析资料\\day06\\code\\PM2.5\\BeijingPM20100101_20151231.csv'
df = pd.read_csv(file_path)
#把分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period = pd.PeriodIndex(year = df['year'],month = df['month'],day = df['day'],hour = df['hour'],freq='H')
df['datetime'] = period
#把datetime设置为索引
df.set_index('datetime',inplace=True)
#datetime降采样
df = df.resample('7D').mean()
#处理缺失数据,这里降采样了,没缺失
data =df['PM_US Post'] #单取这一列,索引是periodD
data_china = df['PM_Dongsi']#中国的数据
#画图
_x = data.index
_x = [i.strftime('%Y%m%d') for i in _x]
_x_china = data_china.index
_x_china = [i.strftime('%Y%m%d') for i in _x_china]
_y = data.values
_y_china = data_china.values
plt.figure(figsize=(20,8),dpi = 80)
plt.plot(range(len(_x)),_y,label = 'US_POST')
plt.plot(range(len(_x_china)),_y_china,label = 'Dongsi_POST')
plt.xticks(range(0,len(_x),10),list(_x)[::10],rotation = 45)
plt.legend(loc='best')
plt.show()
5.练习4–设置不等宽的组距
即使_x和xticks一样,也要把_x放在xticks里,让组距能够对应
#coding=utf-8
import numpy as np
from matplotlib import pyplot as plt
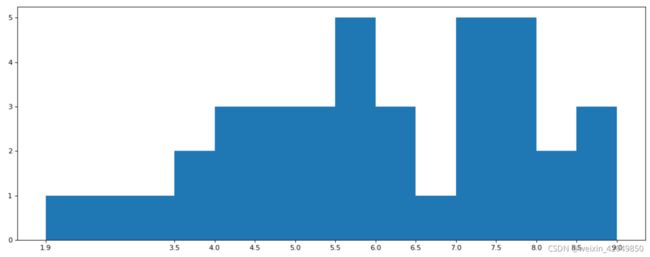
runtime_data = np.array([8.1,7.0,7.3,7.2,6.2,6.1,8.3,6.4,7.1,7.0,7.5,7.8,7.9,7.7,1.9,1.3,5.7,8.9,3.5,3.7,5.7,8.9,6.9,7.8,5.7,9.0,4.5,4.1,4.5,4.6,5.6,5.8,5.4,5.2,5.3,4.2,4.3])
max_runtime =runtime_data.max()
min_runtime = runtime_data.min()
print(max_runtime,min_runtime)
#设置不等宽的间距,hist方法中取到的会是一个左闭右开的区间[1.9,3.5)
num_bin_list=[1.9,3.5]
i = 3.5
while i <max_runtime:#这里小于等于,会多一个(9.0,9.5),小于的话则统计不到9.0,取舍
i += 0.5
num_bin_list.append(i)
#设置图形的大小
plt.figure(figsize=(16,6),dpi =80)
_x = num_bin_list
_y =runtime_data
plt.hist(runtime_data,num_bin_list)
#xticks让之前的组距能够对应上!!!!!!!!
plt.xticks(num_bin_list)
plt.show()