好用的数据建模工具,探索中完善
一、需求描述
DT时代,数据量呈指数级增长,信息资源爆炸式激增。各行业的决策者已经意识到了数据是的核心资产,并期望对数据进行存储和挖掘以达到资产保值甚至增值的目的。大多数企事业单位在面对海量、异构、实时的大数据时,往往没有足够的技术能力和经验,进行复杂的大数据处理,并支撑多元化的应用。数据分析工具和懂数据分析的人正在成为企事业单位稀缺资源,数据建模工具是数据分析过程中重要的一个环节,自助建模将是数据分析工作的未来趋势。在未来,人人都是数据分析师,人人都能分析数据。
二、产品说明
2.1、功能描述
数据建模平台系统是一站式全链路数据生命周期管家,帮助各个行业用户管理数据资产并挖掘价值。平台提供多源异构的数据采集模块、实时/离线计算框架,简洁易用的开发环境和平台接口,为政府机构、企业、科研机构、第三方软件服务商等客户,提供大数据管理、开发和计算的能力。让客户最大化的发现与分析行业内部核心业务数据价值,挖掘现有业务和应用系统的潜在商机,培育完好的业务创新产业链,实现数据应用的完整闭环,帮助客户实现商业价值。
2.2、用户群
数据建模系统主要行业及目标用户群体包括科研教育、电商零售、物联网、企业数字化、公安交管行业、智慧农业、桥梁监测、医疗行业等等。
- 科研教育:包括教学数据分析、科研数据分析、校园网物联网数据分析、面向校级宏观决策的数据分析等等。
- 医疗行业
1)通过对临床数据的分析,对患者进行更有前瞻性的治疗和照护,提高疾病的治疗效果;
2)通过对最新的数据库的分析提高对临床决策的支持;
3)通过对统计工具和算法的使用来改善临床试验的设计;
4)通过对大数据集的分析为个性化医疗提供支持;
5)通过优化业务决策支持,以确保医疗资源的适当分配;
- 金融行业
1)运营类:历史记录管理、多渠道数据整合分析、产品定位分析、客户洞察分析、客户全生命周期分析等。
2)服务类:个性化坐席分配、个性化产品推荐、个性化权益匹配、个性化产品定价、客户体验优化、客户流失预警与客户挽留等。
3)营销类:互联网获客、产品推广、交叉销售、社会化营销、渠道效果分析、差异化广告投放等。四、数据分析在风险管理领域可应用于实时反欺诈、反洗钱、实时风险识别、在线授信等场景。
- 物联网行业:物联网数据分析提供丰富的数据可视化组件、常用统计分析方法及大数据分析工具,致力于降低数据分析门槛,助力物联网行业应用,赋能行业。
- 公安交管:基于公安交管的人、车、物、手机、出行轨迹、住店数据等等,进行专业场景分析,构建业务数据模型。
- 企业数字化转型:助力企业内部多源异构数据有效整合、清洗与梳理,进行数据资产沉淀,形成可辅助决策的分析模型,构建企业大脑,通过可视化大屏进行展示。
- 智慧农业:农情环境监测设备(传感器、监测终端、传输终端)部署为基础,在各类种植区域内部署多个监测点,对多项重要的环境要素进行监测,通过对这些数据进行有效的数据建模分析,实现获取更多、更全、更实用的帮助农企、农户种植进一步优化的可靠数据。
- 桥梁监测:基于桥梁监测中的物联网数据,包括温湿度、风速、混凝土内部温度、桥梁受力、桥梁同行车辆数据等等,进行多维度挖掘分析,对桥梁进行有效实时监测。
电商零售:获取电商数据及关键指标,深入洞悉市场趋势,推动业务增长。
2.3、产品亮点
- 通过可视化拖拽图标的方式,就可以完成业务模型设计和数据分析工作,降低了技术门槛,大大提升了工作效率。
- 自助式可视化图标设计,拖拽图表模版,设置数据来源,两步生成科技感十足的可视化图标。
- 系统支持单机版(仅一台服务支持运行)、大数据版(多台集群),低使用成本,全场景渗透。
- 适配多种类型数据库的数据抽取和数据推送,面对各种情况都可以轻松解决。
- 分级用户管理,对原始数据、成果数据、和算法模型提供分级管控。
- 支持海量数据挖掘分析碰撞。
2.4、产品功能
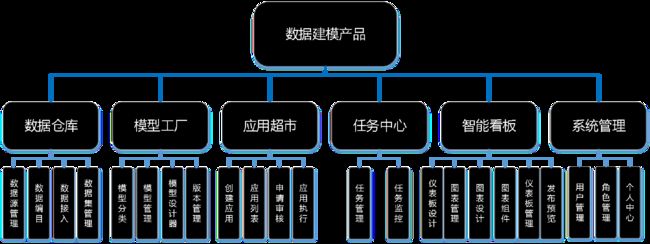
数据建模系统核心功能,主要包括数据源管理、数据治理、模型算法仓、数据资产、数据可视化等。
2.5、核心技术
采用基于J2EE技术的多层架构开发模式
系统的整体架构基于J2EE技术实现。在开发企业级应用系统方面采用J2EE技术实现具有明显优势:
- 平台无关性:可以轻松地移植到几乎任何操作系统和主机平台环境下
- 广泛的支持:技术路线的选择需要考虑到目前计算机技术的主流发展趋势。而J2EE技术获得了大多数国际和国内厂商的广泛支持,已经成为首选的主流技术
- 开放性和标准性:J2EE技术兼容和支持多数重要的技术规范和协议,如CORBA、Web Service、消息中间件、交易中间件、主流数据库存取,有利于系统对外提供服务接口、扩展服务功能
- 稳定的可用性:一个服务器端平台必须能全天候运转以满足用户的需要。J2EE部署到可靠的操作环境中,支持长期的可用性。
基于Docker容器的组件开发技术
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker核心解决的问题是利用LXC来实现类似VM的功能,从而利用更加节省的硬件资源提供给用户更多的计算资源。同VM的方式不同, LXC其并不是一套硬件虚拟化方法-无法归属到全虚拟化、部分虚拟化和半虚拟化中的任意一个,而是一个操作系统级虚拟化方法, 理解起来可能并不像VM那样直观。所以我们从虚拟化到docker要解决的问题出发,看看他是怎么满足用户虚拟化需求的。
大数据体系架构
Hadoop大数据技术是新兴的数据存储、处理系统,有别于关系型数据库,实现了对海量的数据存储、分析成为可能,利用大数据技术对海量数据产生关联关系、预测行为等挖掘价值信息,使数据产生更大的价值,大数据相关组件如下:
- HDFS
一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口。HDFS针对海量数据特点做了特别优化,包括:超大文件的访问、读操作比例远超过写操作、PC机极易发生故障造成节点失效等。HDFS把文件分成64MB的块,分布在集群的机器上,使用Linux的文件系统存放;同时每块文件至少有3份以上的冗余,中心是一个NameNode节点,根据文件索引,找寻文件块。
- Hive
基于Hadoop的大数据分布式数据仓库引擎。它可以将数据存放在分布式文件系统或分布式数据库中,并使用SQL语言进行海量数据统计、查询和分析操作。
- HBase
一个分布式的、按列存储的、多维表结构的实时分布式数据库。它可以提供大数据量结构化和非结构化数据的高速读写操作,为高速在线数据服务而设计。支持列式存储,可指定某列族的压缩方式和复制份数,做到可用性和复制冗余灵活调配。
- Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
- Zookeeper
针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。它可以维护系统配置、群组用户和命名等信息。
基于spring boot微服务架构体系
一套完整的微服务架构需要考虑许多问题,包括API Gateway、服务间调用、服务发现、服务容错、服务部署、数据调用等。基于SpringCloud构建微服务架构可以通过自动配置和绑定Spring环境和其他Spring编程模型来实现微服务。采用Spring Boot应用程序提供的集成功能,通过几个简单的注释,开发人员可以快速配置和启用应用程序中的常见功能模块,并使用久经考验的Netflix组件构建大型分布式系统。提供的微服务功能模块包括服务发现(Eureka),断路器(Hystrix),智能路由(Zuul)和客户端负载均衡(Ribbon)等。
Spring boot 多模块的架构模式。服务间通过restful接口进行数据访问。
基于H5、D3及angular的前端技术
- HTML5,
HTML5具有以下新特性:
语义特性:HTML5赋予网页更好的意义和结构。
本地存储特性:基于HTML5开发的网页APP拥有更短的启动时间,更快的联网速度,因为可以将一些常用、不常更新的内容存储在本地。
设备兼容特性 :HTML5提供了前所未有的数据与应用接入开放接口
连接特性:HTML5拥有更有效的服务器推送技术,Server-SentEvent和WebSockets就是其中的两个特性,这两个特性能够帮助实现服务器将数据“推送”到客户端的功能。更有效的连接工作效率,可以实现基于页面的实时聊天,更快速的网页游戏体验,更优化的在线交流。
网页多媒体特性:支持网页端的Audio、Video等多媒体功能。三维、图形及特效特性(Class: 3D, Graphics & Effects),基于SVG、Canvas、WebGL及CSS3的3D功能,视觉效果将大大增强,在线3D网游就是最典型的例子。
性能与集成特性:HTML5会通过XMLHttpRequest2等技术,帮助Web应用和网站在多样化的环境中更快速的工作。最直观的就是加载会更快。
CSS3特性:如果把网页比喻成舞台,文字图片视频这些比喻成演员,那么CSS3就是化妆师和舞美,它控制着网页所有元素的视觉和动作效果。相对于旧的CSS版本,HTML5所支持的CSS3中提供了更多的风格和更强的效果,也提供了更高的灵活性和控制性。
- Angular.js的使用
AngularJS是一款优秀的前端JS框架,已经被用于Google的多款产品当中。AngularJS有着诸多特性,最为核心的是:MVC、模块化、自动化双向数据绑定、语义化标签、依赖注入等等。
良好的应用程序结构通过MVC(模型 - 视图 - 控制器)或MVVM (模型 - 视图 - 视图模型)模式来组织源代码。AngularJS 是一个 MVW 框架,其中W代表可以用于任何项目。你可以组织你的代码模块,它可显著提高应用程序的可测试性和可维护性。具有以下优点:
双向数据绑定:数据绑定肯定是AngularJS 最佳功能之一。你可以声明绑定的模型到HTML元素。当模型发生变化时,视图会自动更新,反之亦然。这可以减少大量的传统样板代码,保持模型和视图同步。
指令:AngularJS 指令让你使用HTML新语法快速的构建应用程序。您可以创建可重用的自定义组件与指令的API。例如,如果你想自定义日期选择器小部件,你可以创建一个
- D3.js
D3是Data-Driven Documents(数据驱动文档)的简称。D3 (或D3.js) 是一个用来使用Web标准做数据可视化的JavaScript库。 D3帮助我们使用SVG, Canvas 和 HTML技术让数据生动有趣。 D3将强大的可视化,动态交互和数据驱动的DOM操作方法完美结合,让我们可以充分发挥现代浏览器的功能,自由的设计正确的可视化界面。
Codis 内存数据库
内存数据库,是将数据放在内存中直接操作的数据库。相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能。内存数据库系统带来的优越性能不仅仅在于对内存读写比对磁盘读写快上,更重要的是,从根本上抛弃了磁盘数据管理的许多传统方式,基于全部数据都在内存中管理进行了新的体系结构的设计,并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,从而使数据处理速度一般比传统数据库的数据处理速度快很多,一般都在10倍以上,理想情况甚至可以达到1000倍。
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有显著区别, 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务。
Redis获得动态扩容/缩容的能力,增减redis实例对client完全透明、不需要重启服务,不需要业务方担心 Redis 内存爆掉的问题. 也不用担心申请太大, 造成浪费. 业务方也不需要自己维护 Redis。
Codis支持水平扩容/缩容,扩容可以直接界面的 "Auto Rebalance" 按钮,缩容只需要将要下线的实例拥有的slot迁移到其它实例,然后在界面上删除下线的group即可。
Spark Streaming
Spark Streaming是一个准实时流处理框架,处理响应时间一般以分钟为单位,处理实时数据的延迟时间是秒级别的;Storm是一个实时流处理框架,处理响应是毫秒级的。SparkStreaming优点:
1、提供了丰富的API,企业中能快速实现各种复杂的业务逻辑。
2、流入Spark Streaming的数据流通过和机器学习算法结合,完成机器模拟和图计算。
3、Spark Streaming基于Spark优秀的血统。
本项目利用Spark流计算,接收kafka的数据,并按照协议解析数据,同时按照部门产品定制的需求对外提供订阅服务,产品层通过浏览器rest接口向kafka订阅topic发送订阅指令,spark streaming根据kafka订阅信息计算订阅结果,然后将结果存入到kafka结果topic中,然后websocket根据获取的订阅编号、IP端口、订阅结果与浏览器连接,向浏览器实时推送订阅的结果。
kafka技术
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
本平台利用kafka技术作为数据输送的管道,把海量数据高效的输送到各类型数据库中。
三、应用场景
3.1 简单数据分析工作
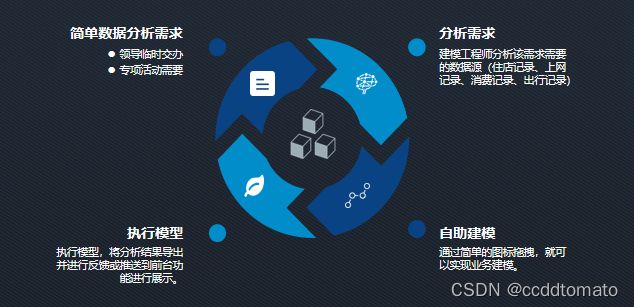
简单数据分析工作是指分析工作的需求数据源明确,建模逻辑清晰,无需复杂算法就能实现的数据分析和统计工作。主要包括如下场景:
- 领导临时交办的数据分析统计任务;
- 某些专项活动中需要的数据分析统计任务;
- 业务中出现的数据分析统计需求;
- 工作中出现的数据分析统计需求。
3.2 复杂业务专题研判

复杂业务专题研判是指分析工作的数据来源多,相关工作业务复杂,需要根据业务特点选择相应的算法模型才能实现的数据挖掘和研判工作。针对这类复杂需求,需要先进行一下步骤:需求分析、业务梳理、数据准备、模型算法升级、生成结果,数据推送。
3.3 日常数据统计

日常工作分析工作是指固定时间周期性重复进行的分析工作,可以对分析工作进行建模后,设置模型定期执行并结果推送至前台功能进行展示。
3.4 数据可视化设计及展示
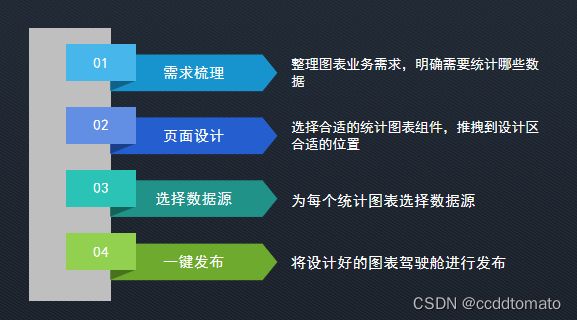
近百种组件特效任意组合即可制作酷炫灵动的大屏驾驶舱,用户可以根据工作需要,自己设计科技感十足的可视化报表,通过简单的图表组件拖拽和数据来源点选,就可以快速完成可视化报表的设计。