Pytorch学习-tensorboard的使用
Pytorch学习-tensorboard的使用
- 1 Tensorboard简介
-
- 运行机制
- 安装及测试
- 2 SummaryWriter实例的使用教程
-
- (1)初始化summaryWriter的方法
- (2)不同类型数据的记录
-
- 1)数字 scalar
- 使用样例
- 2) 直方图 histogram
- 使用样例
- 3) 运行图 graph !!
-
- 官方样例
- 4) 图片 image (pillow库支持)
- 5) 嵌入向量embedding
1 Tensorboard简介
参考链接1安装:
参考链接2使用:
TensorBoard:TensorFlow中强大的可视化工具;
支持标量、图像、文本、音频、视频和Embedding等多种数据可视化;
运行机制
- 在python脚本中记录可视化的数据;
- 记录的数据会以event file(事件文件)存放到硬盘中;
- 在终端使用TensorBoard读取event file,TensorBoard在网页端进行可视化;
安装及测试
- 安装
终端输入命令 pip install tensorboard 以及 pip install future,安装完成即可。 - 运行可视化
1) 先运行下面的代码,得到event 文件
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard') # 用于记录要可视化的数据
for x in range(100):
writer.add_scalar('y=2x', x * 2, x) # 'y=2x'是标量的名称, x*2是曲线的y轴,x是曲线的x轴
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
2)在terminal输入 命令 :
tensorboard --logdir=./runs
得到类似以下输出:
TensorBoard 2.1.1 at http://localhost:6006/ (Press CTRL+C to quit)
打开对应网站即可看到可视化界面
2 SummaryWriter实例的使用教程
(1)初始化summaryWriter的方法
- 提供一个路径,使用该路径保存日志
- 无参数,默认使用 “
runs/日期时间” 路径保存日志 - 提供一个comment参数,将使用 “
runs/日期时间-comment” 路径保存日志
使用过程:
对于每次实验建立一个路径不同的summaryWriter,也叫一个run
接下来,调用summaryWriter中的不同实例中的add_something方法向日志中写入文件
如果想要可视化这些数据,在命令行中开启tensorboard即可:tensorboard --logdir=
其中,runs/下面的不同次实验得到的数据的差异。
(2)不同类型数据的记录
1)数字 scalar
使用add_scalar 方法记录数字常量,如训练过程中的loss,accuracy、learning_rate等,监控训练过程
add_scalar(tag, scalar_value, global_step=None, walltime=None)
参数
- tag(string) 数据名称,不同名称的数据使用不同曲线展示
- scalar_value(float) 数字常量值 必须为float类型
- global_step(int,optional):训练的step
- walltime(float,optional) 记录发生的时间,默认为time.time()
注意:如果为pytorch scalar tensor 需要调用.item()方法获取其数值
使用样例
在’runs/scalar_example‘和‘runs/another_scalar_example’两个不同目录中记录名称相同但是参数不同的两个二次函数和指数函数数据,效果如下图。
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/scalar_example') # 写入的目录
for i in range(10):
writer.add_scalar('quadratic',i**2,global_step=i)
writer.add_scalar('exponential',2**i,global_step=i)
writer = SummaryWriter('runs/another_scalar_example') # 在另一个路径中写
for i in range(10):
writer.add_scalar('quadratic',i**3,global_step=i)
writer.add_scalar('exponential',3**i,global_step=i)
执行命令 tensorboard --logdir=./policy_save/runs/ 后打开网页 【定位到公共在一起的目录】
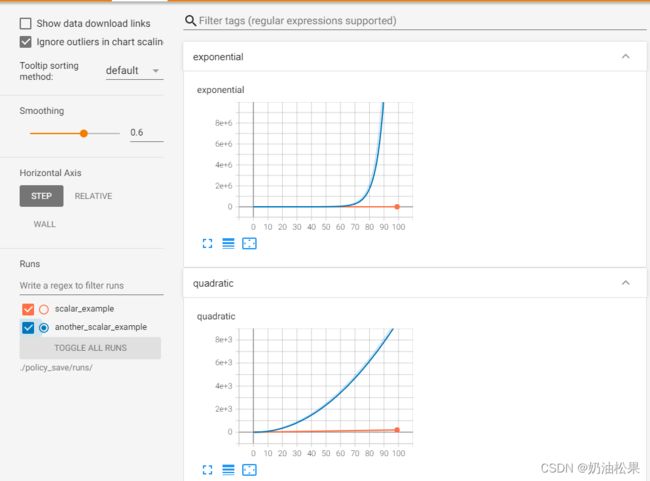
可以看到,两个名称相同的数据被放在同一张图中,便于对比观察。可以在左侧runs栏选择要查看哪些变量
2) 直方图 histogram
使用add_histogram方法记录一组数据的直方图
**add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)**
参数:
- tag(string) 数据名称,不同名称的数据使用不同曲线展示
- values(torch.Tensor,numpy.array, or string / blobname): 用来构建直方图的数据
- global_step(int,optional):训练的step
- bins(string,optional):取值有‘tensorflow’,‘auto’,’fd’等 该参数决定了分桶的方式??。
- walltime(float,optional) 记录发生的时间,默认为time.time()
- max_bins(int,optional):最大分桶数
使用样例
import numpy as np
writer = SummaryWriter('runs/embedding_example')
writer.add_histogram('normal_centered',np.random.normal(0,1,1000),global_step=1)
writer.add_histogram('normal_centered',np.random.normal(0,2,1000),global_step=50)
writer.add_histogram('normal_centered',np.random.normal(0,3,1000),global_step=100)
结果图:
可以看到有"DISTRIBUTIONS"和"HISTOGRAMS"两栏,它们都是用来观察数据分布的。其中在"HISTOGRAMS"中,同一数据不同 step 时候的直方图可以上下错位排布 (OFFSET) 也可重叠排布 (OVERLAY)。

3) 运行图 graph !!
使用add_graph方法来可视化一个神经网络
**add_graph(model, input_to_model=None, verbose=False, **kwargs)**
参数:
- model(torch.nn.Module):待可视化的网络模型
- input_to_model(torch.Tensor or list of torch.Tensor, optional):待输入神经网络的变量或一组变量
官方样例
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2),
nn.ReLU(), # (6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # (16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
dummy_input = torch.rand(13, 1, 28, 28) # 假设输入13张1*28*28的图片
model = LeNet()
with SummaryWriter('runs/graph') as w:
w.add_graph(model, dummy_input)
writer = SummaryWriter('policy_save/runs/scalar_example')
for i in range(100):
writer.add_scalar('quadratic', i * 2, global_step=i)
writer.add_scalar('exponential', 1.2 * i, global_step=i)
writer = SummaryWriter('policy_save/runs/another_scalar_example')
for i in range(100):
writer.add_scalar('quadratic', i**2, global_step=i)
writer.add_scalar('exponential', 1.2**i, global_step=i)
终端输入命令:tensorboard --logdir=./runs/graph 点击网页查看可视化界面