CVPR 2022 | 北大&字节AI提出DA-WSOL:弱监督物体定位新框架
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心 | 作者:朱磊
将弱监督物体定位看作图像与像素特征域间的域自适应任务,北大、字节跳动提出新框架显著增强基于图像级标签的弱监督图像定位性能。
物体定位作为计算机视觉的基本问题,可以为场景理解、自动驾驶、智能诊疗等领域提供重要的目标位置信息。然而,物体定位模型的训练依赖于物体目标框或物体掩模等密集标注信息。这些密集标签的获取依赖于对图像中各像素的类别判断,因此极大地增加了标注过程所需的时间及人力。
为减轻标注工作的负担,弱监督物体定位 (WSOL) 通过利用图像级标签(如图像类别)作为监督信号进行物体定位模型的训练,以摆脱训练过程对像素级标注的需求。该类方法大多采用分类激活图 (CAM) 的流程训练一个图像级特征分类器,而后将该分类器作用于像素级特征得到物体定位结果。但是图像级特征通常保有充足的物体信息,仅识别其中具有鉴别性的物体特征即正确分类图像。因此,在将该分类器作用于在所含物体信息并不充足的像素级特征进行物体定位时,最终得到的定位图往往只能感知到部分物体区域而非整个物体。
为解决这一问题,本文将基于 CAM 的弱监督物体定位过程看作是一个特殊的域自适应任务,即在保证在源图像级特征域上训练的分类器应用在目标像素域时仍具有良好的分类表现,从而使其更好的在测试过程中进行目标定位。从这一视角来看,我们可以很自然的将域自适应方法迁移到弱监督物体定位任务中,使得仅依据图像标签训练的模型可以更为精准的定位目标物体。

Weakly Supervised Object Localization as Domain Adaption
文章地址:https://arxiv.org/abs/2203.01714
项目地址:https://github.com/zh460045050/DA-WSOL_CVPR2022
目前,这项研究已被 CVPR2022 接收,完整训练代码及模型均已开源。主要由北大分子影像/医学智能实验室朱磊和字节跳动佘琪参与讨论和开发,北大分子影像/医学智能实验室卢闫晔老师给予指导。
方法
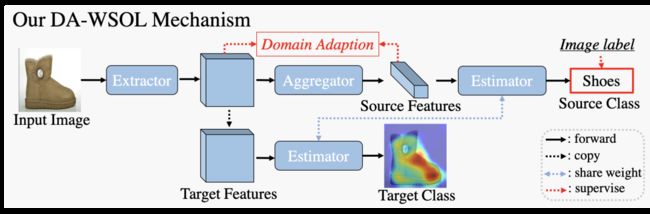
图 1 - 方法整体思想
弱监督物体定位实际上可以看作是在图像特征域(源域 S)中依据图像级标签(源域金标 Y^s)完全监督地训练模型 e(∙),并在测试过程中将该模型作用于像素特征域(目标域 T)以获取物体定位热力图。总的来看,我们的方法希望在此过程中引入域自适应方法进行辅助,以拉近源域 S 与目标域 T 的特征分布,从而增强在模型 e(∙)对于目标域 T 的分类效果,因此我们的损失函数可以表示为:
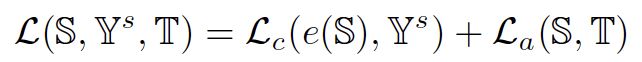
其中 L_c 为源域分类损失,而 L_a 则为域自适应损失。
由于弱监督定位中源域和目标域分别为图像域和像素域,我们所面临的域自适应任务具有一些独有的性质:①目标域样本与源域样本的数量并不平衡(目标域样本是源域的 N 倍,N 为图像像素数);②目标域中存在与源域标签不同的样本(背景像素不属于任何物体类别);③目标域样本与源域样本存在一定联系(图像特征由像素特征聚合而得到)。为了更好地考虑这三个特性,我们进而提出了一种域自适应定位损失(DAL Loss)作为 L_a (S,T)以拉近图像域 S 与像素域 T 的特征分布。
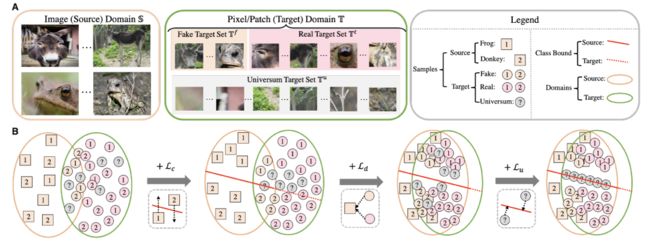
图 2 - 弱监督定位中源域目标域的划分以及其在弱监督定位中的作用
首先,如图 2-A,我们将目标域样本 T 进一步分为三个子集:①“伪源域样本集 T^f”表示与源域特征分布相似的目标域样本;②“未知类样本集 T^u”表示类别在源域中不存在的 l 目标域样本;③“真实目标域样本集 T^t”表示其余样本。依据这三个子集,我们提出的域自适应定位损失可以表示为:
![]()
从上述公式可以看到,在域自适应定位损失中,伪源域样本被看作源域样本的补充而非目标域样本,以解决样本不平衡问题。同时,为了减少具有源域未知类别的样本 T^U 对分类准确率的干扰,我们仅使用传统自适应损失 L_d(如最大均值差异 MMD)拉近扩增后的源域样本集 S∪T^f 与真实目标域样本集 T^t 的特征分布。而这些被排除在域自适应过程之外的样本 T^u,可以被用作 Universum 正则 L_u,以保证分类器所定义的类别边界也能更好的感应到目标域。
图 2-B 也形象地展示了源域分类损失及域自适应定位损失的预期效果,其中 L_c 保证不同类别源域样本可以被正确区分,L_d 将源域目标域分布进行拉近,而 L_u 将类别边界拉近到未知标签目标域样本处。

图 3 - 整体工作流及目标样本分配器结构
我们提出,域自适应定位损失可以很便捷地将域自适应方法嵌入到已有弱监督定位方法中大幅提升其性能。如图 3 所示,在已有弱监督定位模型上嵌入我们的方法仅需要引入一个目标样本分配器(Target Sample Assigner)进行目标域样本子集的划分,该分配器通过记忆矩阵 M 在训练过程中实时更新未知类目标域样本集 T^u 与真实目标域样本集 T^r 的锚点,并以将二者和源域特征作为聚类中心进行三路 K 均值聚类,得到每个目标域样本所属的子集。最后依此样本子集,我们可以得到域自适应损失 L_d、以及 Universum 正则 L_u 并利用二者与源域分类损失 L_c 一起对训练过程进行监督,使得在保证源域分类准确性的情况下,尽可能的拉近源域与目标域特征,并减少未知类别样本影响。这样一来,在将该模型应用于目标域(也就是像素特征)进行物体定位时,最终生成的定位热力图的质量将得到显著提升。
实验
图 3 - 物体定位热力图及最终定位 / 分割结果
我们在三个弱监督目标定位数据集上验证了我们方法的有效性:
从视觉效果来看,由于保证了图像与像素特征域的分布一致性,我们的方法可以更为全面的抓取物体区域。同时,由于 Universum 正则关注了背景像素对分类器的影响,我们的方法生成的定位热力图可以更好的贴近物体边缘并抑制类别相关背景的响应程度,如水面之于鸭子。
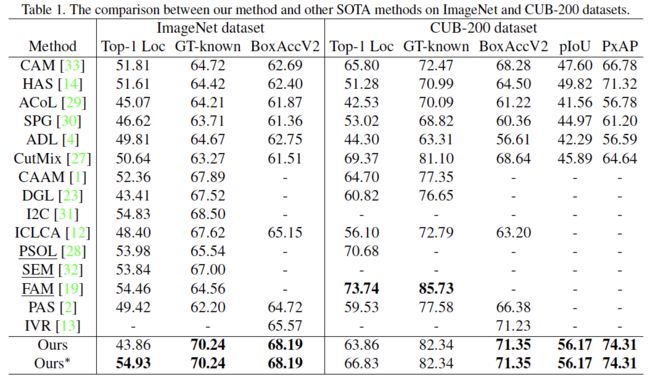
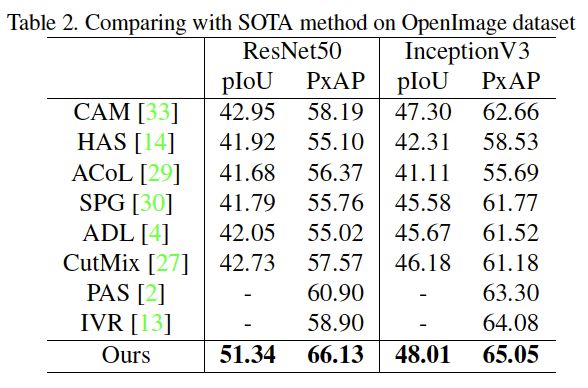
从定量结果中可以也看到,在目标定位性能方面,我们的方法在三个数据上均取得了非常好的效果,尤其是在对于非细粒度目标定位的情况(ImageNet 和 OpenImages 数据集),我们的方法均取得了最优的定位性能。而对于图像分类性能方面,由于引入域自适应会导致源域准确度的损失,但通过借鉴多阶段策略利用一个附加的分类模型(仅使用 L_c 训练)生成分类结果即可解决域自适应带来的副作用。
此外,我们也具备很好的泛化性,可以兼容多类域自适应及多种弱监督目标定位方法,以提升定位性能。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看