使用TensorFlow手写Transformer
原创:王稳钺
资料来源:张春阳
由于目前”调包“非常方便,往往让人忽略对于算法的深入理解。本文介绍使用TensorFlow从0实现Transformer,帮助从代码角度理解原理及其中的细节。
1. Self-attention
1.1 Self-attention原理
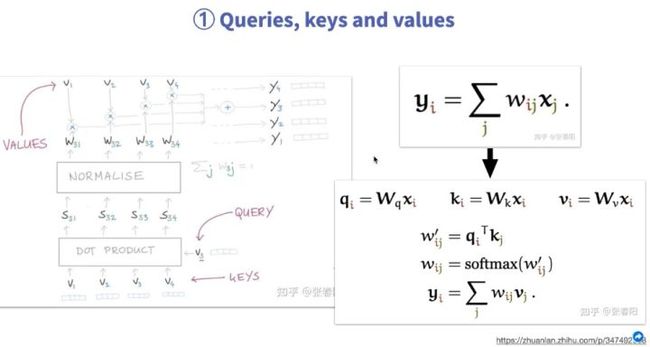
本文主要介绍代码实现,对于原理部分只做简单介绍。Self-attention主要想要实现的是句子中每一个token和其它token之间的相关性,将其融合起来的语义组成一个新的向量,计算过程如图。首先需要有QUERY和KEYS,在实际实现过程中,最开始就是两组随机的参数的向量。然后进行点乘,点乘后可以得到S值,点乘的过程就是在求相关性的过程。得到S后,经过softmax,得到权重W。之后再引入可学习参数VALUES,刚开始它也是一组随机值。用VALUES与W相乘,最终就可以得到新的向量。通过V1可以得到Y1,单纯使用V1表示时它只有自己的语意信息,而使用Y1时就包括了其与周边向量的关系。
1.2 Self-attention实现
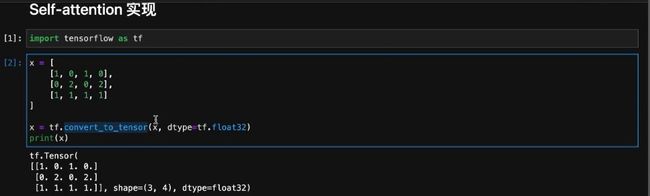
生成矩阵作为输入,用来模拟V1,V2,V3,值是随机写的并没有特殊的含义。为了后续可以传入到模型中,将矩阵转换成tensor。
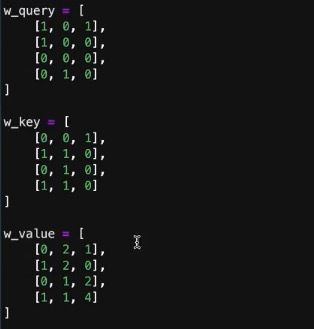

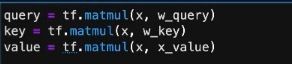
生成QUERY、KEYS、VALUES参数矩阵,与x点乘后就可以生成QUERY、KEYS、VALUE。它们都是随机的参数,可以自己设定,之后通过深度学习的学习能力来逐渐优化到一些合适的值。生成矩阵后,同样的,也需要转换成tensor。最后进行点乘操作,生成query、key、value。

![]()
计算得到S,即attn_score,计算时需要将key转置,利用transpose_b=True实现。再经过softmax,得到权重W。之后,将W与value相乘。

最终求出输出值,也就是新的向量,其中包含着上下文的信息。其实举例中X是随便写的数,它其实代表要转换的向量。实际中,做NLP时,x其实就应该是token对应的向量值。或者如果实现推荐系统的话,x可能就是推荐系统里每一个输入的序列向量的表示。
2. Positional Encoding
2.1 Positional Encoding作用及原理
一些序列模型,需要一步步执行,其中其实就隐藏了一些位置信息。但Transformer不同,它在做转换计算时是将所有输入一起进行计算,速度很快,但失去了位置信息。所以在Transformer中,使用Positional Encoding来表示位置信息,表示当前字符在句子中的第几个位置。具体所需函数如下图。
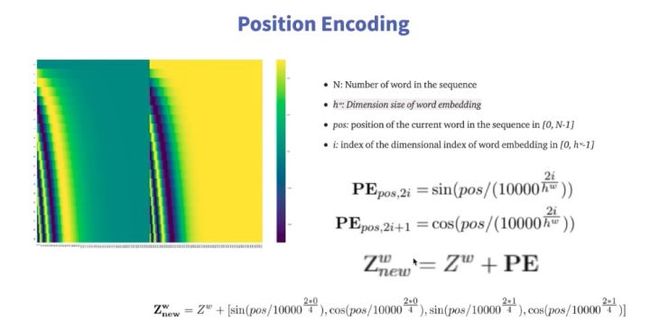
2.2 Positional Encoding实现
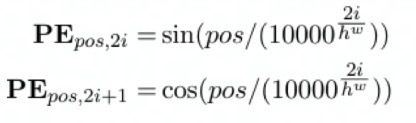
在实现过程中,主要是实现这两个公式。

因为会经常调用位置编码的计算,所以将它定义成一个函数。函数有两个参数——pos及model_size。pos代表当前要编码的位置。model_size指想把位置编码转化成多长的向量,这个长度和transformer的输入是有关系的,输入是150维,那位置编码也要是150维的。
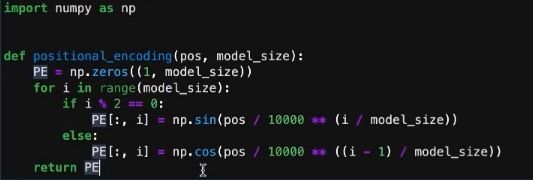
函数中,需要先生成指定大小的全0矩阵PE,用来占位。之后利用循环,判断i的奇偶,因为通过上面的公式,奇偶不同,采用不同的公式。注意,2i其实就表示偶数,在代码中用i就可以实现,特殊的在奇数时,需要减1。将计算出的值,切片填入PE中,最终函数返回PE矩阵。
3. Multi-head attention
3.1 Multi-head attention原理
在NLP中,其实某两个token之间,也许不仅仅有一种相关性。比如可以有语义层面的信息相关性的计算方法,但是可能在语法层面也有一定相关性,甚至从其它的,人类不太能够去理解的一些抽象的方面,也许也有一些相关性的计算方法。深度学习框架的好处就在于它能够自己去帮人类去发现一些没有关注到的方面。所以不能仅仅用Self-attention这一种计算相关性的方法,需要有更多的种类。所以Transformer的作者将其起名为Multi-head attention,其实是指需要更多的参数,利用更多的参数表示相关性的计算。
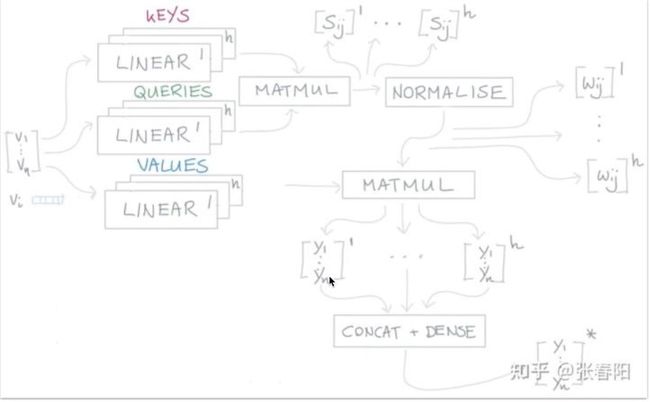
其实每一个head就是重复Self-attention中的计算过程,但是K、Q、V都是多维的,这样最终计算出的y也是多维的。为了降维,将最终的y进行拼接,变成一个n*h的向量。最后再进过全联接层,输出与输入长度一样的向量,利用全链接层再进行降维。
3.2 Multi-head attention实现
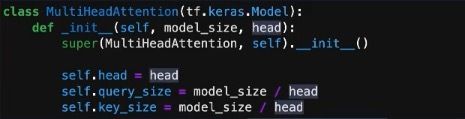
首先定义初始化方法,其中有两个参数——model_size和head。model_size与位置编码的维度对应,head是一个可变参数,也就是所需的head数。之后写入所需的变量。
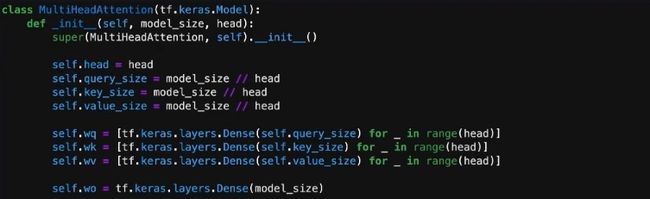
因为需要用到很多的参数,所以利用全链接层来定义QUERY、KEYS和VALUES中可学习的参数。由于有很多个head,可以利用循环来定义不同的head。因为还需要一层全连接层,所以定义self.wo。初始化完成。
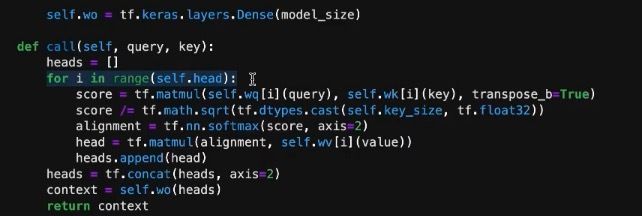
定义call来进行计算。这里大致的计算过程与Self-attention中相同,只是每一个head计算后利用concat进行拼接。同时在计算score时,除了根号k,这样可以防止梯度消失同时可以保证数据同分布。最后再利用wo全链接层降维,返回context。
4. Encoder过程实现
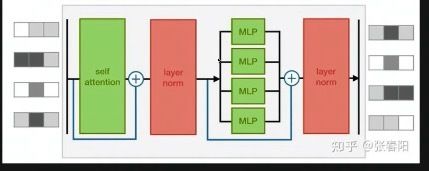
Encoder主要结构如图。
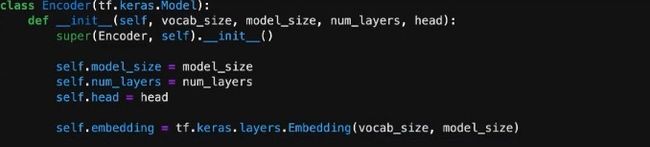
在实现整个Encoder过程中,会使用到很多层,首先需要用到Embedding层。

下面两层实现了图中的self attention以及layer norm结构。
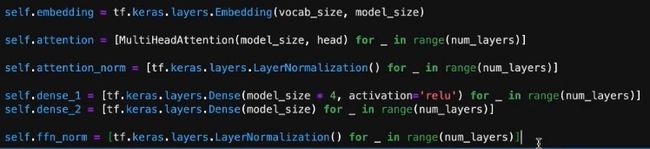
desen1,dense2实现了图中的全链接层,可以后面还接了layer norm,所以定义ffn_norm。dense中的参数是可以调整的,选择不同的值会有不同的效果,这也是值得研究的内容。
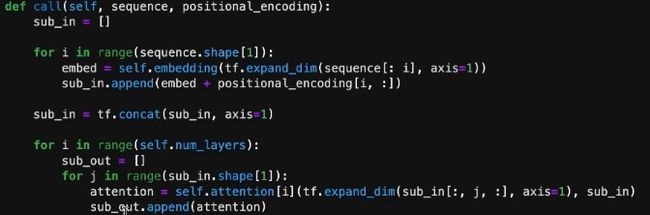

接下来就可以定义call来做具体计算。这一部分实现了结构图中self attention部分。注意图中有残差结构,具体实现就是将sub_in与sub_out直接相加,其实是很简单的操作。

这里对应结构图中第一个layer norm。
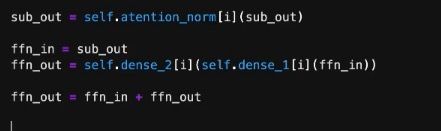
利用前面定义的两个全链接层实现图中的第二个橙色部分,为了明确实现残差,从新命名变量,最后还是进行简单的相加操作。

利用定义好的ffn_norm实现最后一个layer norm结构。
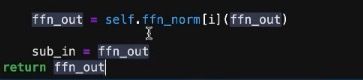
最后,考虑连贯性,需要将第一层的输出当作第二层的输入,所以需要将ffn_out再赋值给sub_in。最终返回ffn_out。这就实现了Encoder过程。
想要获取更多的训练代码或者对实现过程有任何问题,欢迎联系。